 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Models Inherit Value Biases from Pretraining
Jan 28, 2026Reward models (RMs) are central to aligning large language models (LLMs) with human values but have received less attention than pre-trained and post-trained LLMs themselves. Because RMs are initialized from LLMs, they inherit representations that shape their behavior, but the nature and extent of this influence remain understudied. In a comprehensive study of 10 leading open-weight RMs using validated psycholinguistic corpora, we show that RMs exhibit significant differences along multiple dimensions of human value as a function of their base model. Using the "Big Two" psychological axes, we show a robust preference of Llama RMs for "agency" and a corresponding robust preference of Gemma RMs for "communion." This phenomenon holds even when the preference data and finetuning process are identical, and we trace it back to the logits of the respective instruction-tuned and pre-trained models. These log-probability differences themselves can be formulated as an implicit RM; we derive usable implicit reward scores and show that they exhibit the very same agency/communion difference. We run experiments training RMs with ablations for preference data source and quantity, which demonstrate that this effect is not only repeatable but surprisingly durable. Despite RMs being designed to represent human preferences, our evidence shows that their outputs are influenced by the pretrained LLMs on which they are based. This work underscores the importance of safety and alignment efforts at the pretraining stage, and makes clear that open-source developers' choice of base model is as much a consideration of values as of performance.
Reward Model Interpretability via Optimal and Pessimal Tokens
Jun 08, 2025



Reward modeling has emerged as a crucial component in aligning large language models with human values. Significant attention has focused on using reward models as a means for fine-tuning generative models. However, the reward models themselves -- which directly encode human value judgments by turning prompt-response pairs into scalar rewards -- remain relatively understudied. We present a novel approach to reward model interpretability through exhaustive analysis of their responses across their entire vocabulary space. By examining how different reward models score every possible single-token response to value-laden prompts, we uncover several striking findings: (i) substantial heterogeneity between models trained on similar objectives, (ii) systematic asymmetries in how models encode high- vs low-scoring tokens, (iii) significant sensitivity to prompt framing that mirrors human cognitive biases, and (iv) overvaluation of more frequent tokens. We demonstrate these effects across ten recent open-source reward models of varying parameter counts and architectures. Our results challenge assumptions about the interchangeability of reward models, as well as their suitability as proxies of complex and context-dependent human values. We find that these models can encode concerning biases toward certain identity groups, which may emerge as unintended consequences of harmlessness training -- distortions that risk propagating through the downstream large language models now deployed to millions.
The effect of task and training on intermediate representations in convolutional neural networks revealed with modified RV similarity analysis
Dec 04, 2019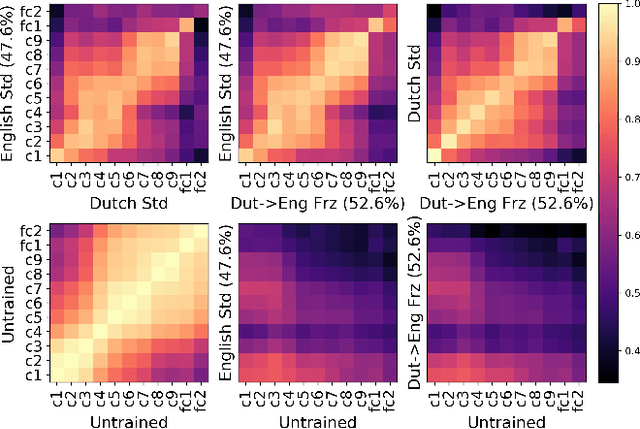
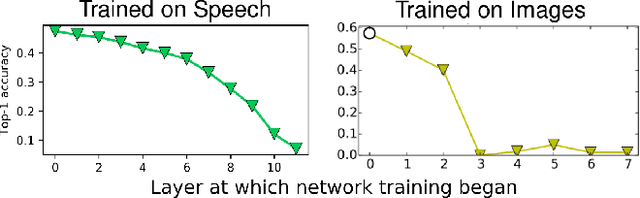
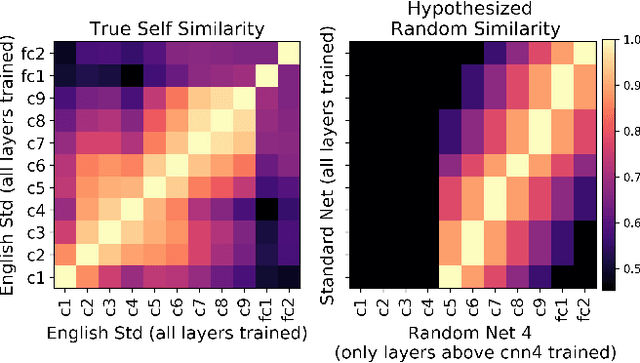
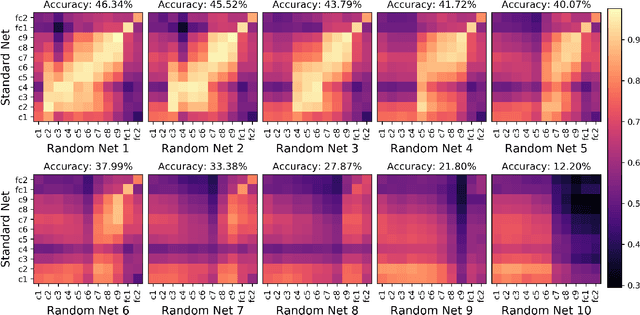
Centered Kernel Alignment (CKA) was recently proposed as a similarity metric for comparing activation patterns in deep networks. Here we experiment with the modified RV-coefficient (RV2), which has very similar properties as CKA while being less sensitive to dataset size. We compare the representations of networks that received varying amounts of training on different layers: a standard trained network (all parameters updated at every step), a freeze trained network (layers gradually frozen during training), random networks (only some layers trained), and a completely untrained network. We found that RV2 was able to recover expected similarity patterns and provide interpretable similarity matrices that suggested hypotheses about how representations are affected by different training recipes. We propose that the superior performance achieved by freeze training can be attributed to representational differences in the penultimate layer. Our comparisons of random networks suggest that the inputs and targets serve as anchors on the representations in the lowest and highest layers.
How can deep learning advance computational modeling of sensory information processing?
Sep 25, 2018Deep learning, computational neuroscience, and cognitive science have overlapping goals related to understanding intelligence such that perception and behaviour can be simulated in computational systems. In neuroimaging, machine learning methods have been used to test computational models of sensory information processing. Recently, these model comparison techniques have been used to evaluate deep neural networks (DNNs) as models of sensory information processing. However, the interpretation of such model evaluations is muddied by imprecise statistical conclusions. Here, we make explicit the types of conclusions that can be drawn from these existing model comparison techniques and how these conclusions change when the model in question is a DNN. We discuss how DNNs are amenable to new model comparison techniques that allow for stronger conclusions to be made about the computational mechanisms underlying sensory information processing.