 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategic Polysemy in AI Discourse: A Philosophical Analysis of Language, Hype, and Power
Apr 22, 2026This paper examines the strategic use of language in contemporary artificial intelligence (AI) discourse, focusing on the widespread adoption of metaphorical or colloquial terms like "hallucination", "chain-of-thought", "introspection", "language model", "alignment", and "agent". We argue that many such terms exhibit strategic polysemy: they sustain multiple interpretations simultaneously, combining narrow technical definitions with broader anthropomorphic or common-sense associations. In contemporary AI research and deployment contexts, this semantic flexibility produces significant institutional and discursive effects, shaping how AI systems are understood by researchers, policymakers, funders, and the public. To analyse this phenomenon, we introduce the concept of glosslighting: the practice of using technically redefined terms to evoke intuitive -- often anthropomorphic or misleading -- associations while preserving plausible deniability through restricted technical definitions. Glosslighting enables actors to benefit from the persuasive force of familiar language while maintaining the ability to retreat to narrower definitions when challenged. We argue that this practice contributes to AI hype cycles, facilitates the mobilisation of investment and institutional support, and influences public and policy perceptions of AI systems, while often deflecting epistemic and ethical scrutiny. By examining the linguistic dynamics of glosslighting and strategic polysemy, the paper highlights how language itself functions as a sociotechnical mechanism shaping the development and governance of AI.
Relative Principals, Pluralistic Alignment, and the Structural Value Alignment Problem
Apr 22, 2026The value alignment problem for artificial intelligence (AI) is often framed as a purely technical or normative challenge, sometimes focused on hypothetical future systems. I argue that the problem is better understood as a structural question about governance: not whether an AI system is aligned in the abstract, but whether it is aligned enough, for whom, and at what cost. Drawing on the principal-agent framework from economics, this paper reconceptualises misalignment as arising along three interacting axes: objectives, information, and principals. The three-axis framework provides a systematic way of diagnosing why misalignment arises in real-world systems and clarifies that alignment cannot be treated as a single technical property of models but an outcome shaped by how objectives are specified, how information is distributed, and whose interests count in practice. The core contribution of this paper is to show that the three-axis decomposition implies that alignment is fundamentally a problem of governance rather than engineering alone. From this perspective, alignment is inherently pluralistic and context-dependent, and resolving misalignment involves trade-offs among competing values. Because misalignment can occur along each axis -- and affect stakeholders differently -- the structural description shows that alignment cannot be "solved" through technical design alone, but must be managed through ongoing institutional processes that determine how objectives are set, how systems are evaluated, and how affected communities can contest or reshape those decisions.
Ethics and Deep Learning
May 24, 2023


This article appears as chapter 21 of Prince (2023, Understanding Deep Learning); a complete draft of the textbook is available here: http://udlbook.com. This chapter considers potential harms arising from the design and use of AI systems. These include algorithmic bias, lack of explainability, data privacy violations, militarization, fraud, and environmental concerns. The aim is not to provide advice on being more ethical. Instead, the goal is to express ideas and start conversations in key areas that have received attention in philosophy, political science, and the broader social sciences.
The Linguistic Blind Spot of Value-Aligned Agency, Natural and Artificial
Jul 02, 2022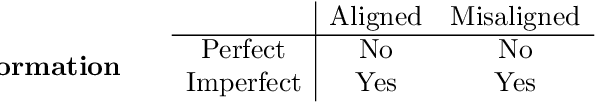
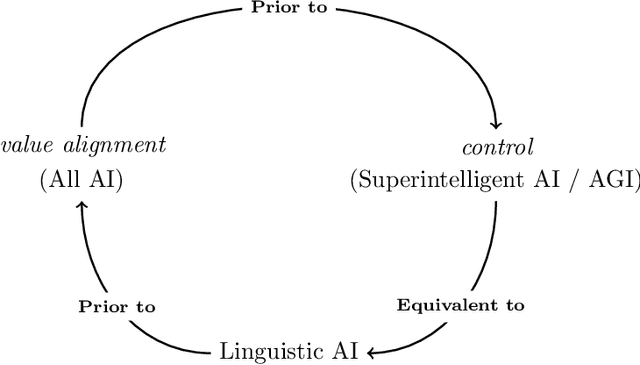
The value-alignment problem for artificial intelligence (AI) asks how we can ensure that the 'values' (i.e., objective functions) of artificial systems are aligned with the values of humanity. In this paper, I argue that linguistic communication (natural language) is a necessary condition for robust value alignment. I discuss the consequences that the truth of this claim would have for research programmes that attempt to ensure value alignment for AI systems; or, more loftily, designing robustly beneficial or ethical artificial agents.
Metaethical Perspectives on 'Benchmarking' AI Ethics
Apr 11, 2022Benchmarks are seen as the cornerstone for measuring technical progress in Artificial Intelligence (AI) research and have been developed for a variety of tasks ranging from question answering to facial recognition. An increasingly prominent research area in AI is ethics, which currently has no set of benchmarks nor commonly accepted way for measuring the 'ethicality' of an AI system. In this paper, drawing upon research in moral philosophy and metaethics, we argue that it is impossible to develop such a benchmark. As such, alternative mechanisms are necessary for evaluating whether an AI system is 'ethical'. This is especially pressing in light of the prevalence of applied, industrial AI research. We argue that it makes more sense to talk about 'values' (and 'value alignment') rather than 'ethics' when considering the possible actions of present and future AI systems. We further highlight that, because values are unambiguously relative, focusing on values forces us to consider explicitly what the values are and whose values they are. Shifting the emphasis from ethics to values therefore gives rise to several new ways of understanding how researchers might advance research programmes for robustly safe or beneficial AI. We conclude by highlighting a number of possible ways forward for the field as a whole, and we advocate for different approaches towards more value-aligned AI research.
Moral Dilemmas for Moral Machines
Mar 11, 2022Autonomous systems are being developed and deployed in situations that may require some degree of ethical decision-making ability. As a result, research in machine ethics has proliferated in recent years. This work has included using moral dilemmas as validation mechanisms for implementing decision-making algorithms in ethically-loaded situations. Using trolley-style problems in the context of autonomous vehicles as a case study, I argue (1) that this is a misapplication of philosophical thought experiments because (2) it fails to appreciate the purpose of moral dilemmas, and (3) this has potentially catastrophic consequences; however, (4) there are uses of moral dilemmas in machine ethics that are appropriate and the novel situations that arise in a machine-learning context can shed some light on philosophical work in ethics.
Est-ce que vous compute? Code-switching, cultural identity, and AI
Dec 15, 2021Cultural code-switching concerns how we adjust our overall behaviours, manners of speaking, and appearance in response to a perceived change in our social environment. We defend the need to investigate cultural code-switching capacities in artificial intelligence systems. We explore a series of ethical and epistemic issues that arise when bringing cultural code-switching to bear on artificial intelligence. Building upon Dotson's (2014) analysis of testimonial smothering, we discuss how emerging technologies in AI can give rise to epistemic oppression, and specifically, a form of self-silencing that we call 'cultural smothering'. By leaving the socio-dynamic features of cultural code-switching unaddressed, AI systems risk negatively impacting already-marginalised social groups by widening opportunity gaps and further entrenching social inequalities.
Emergent Communication under Competition
Jan 25, 2021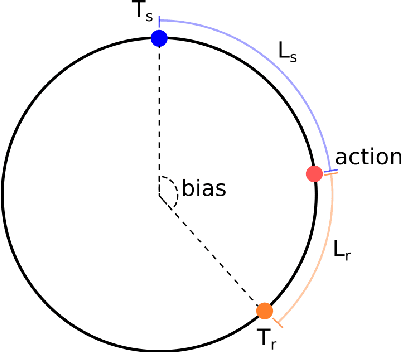
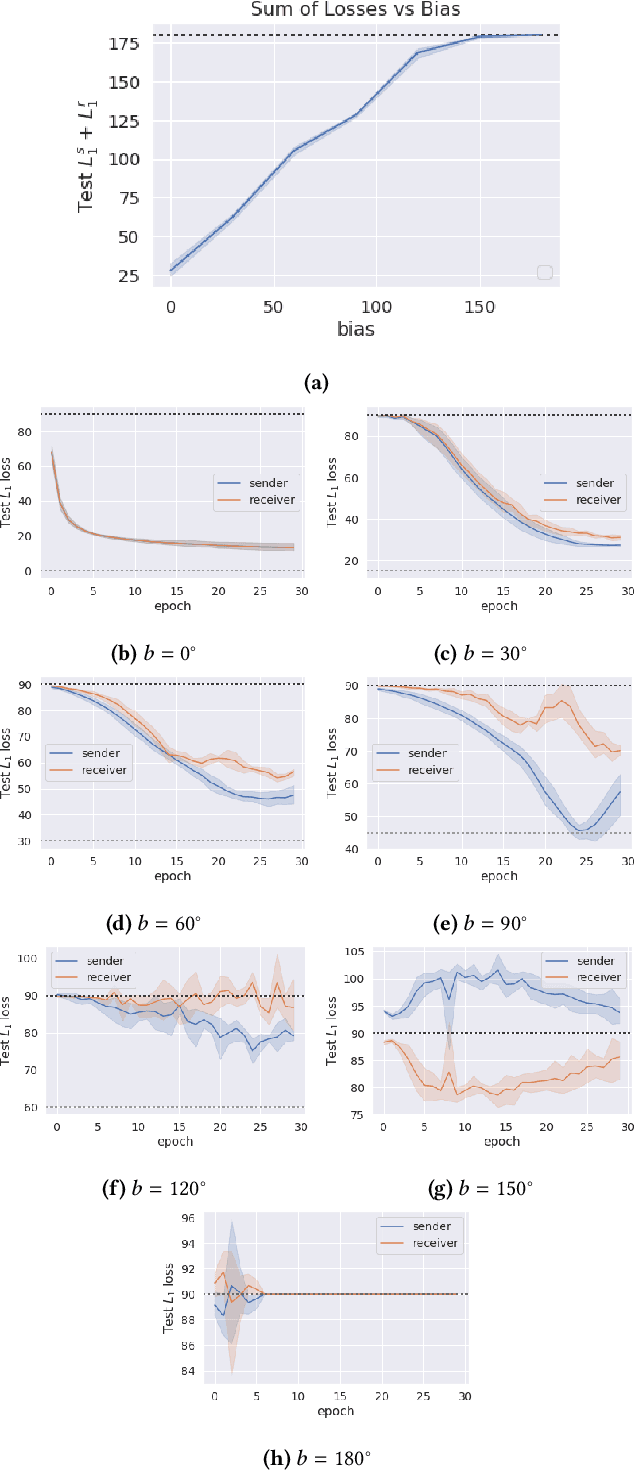
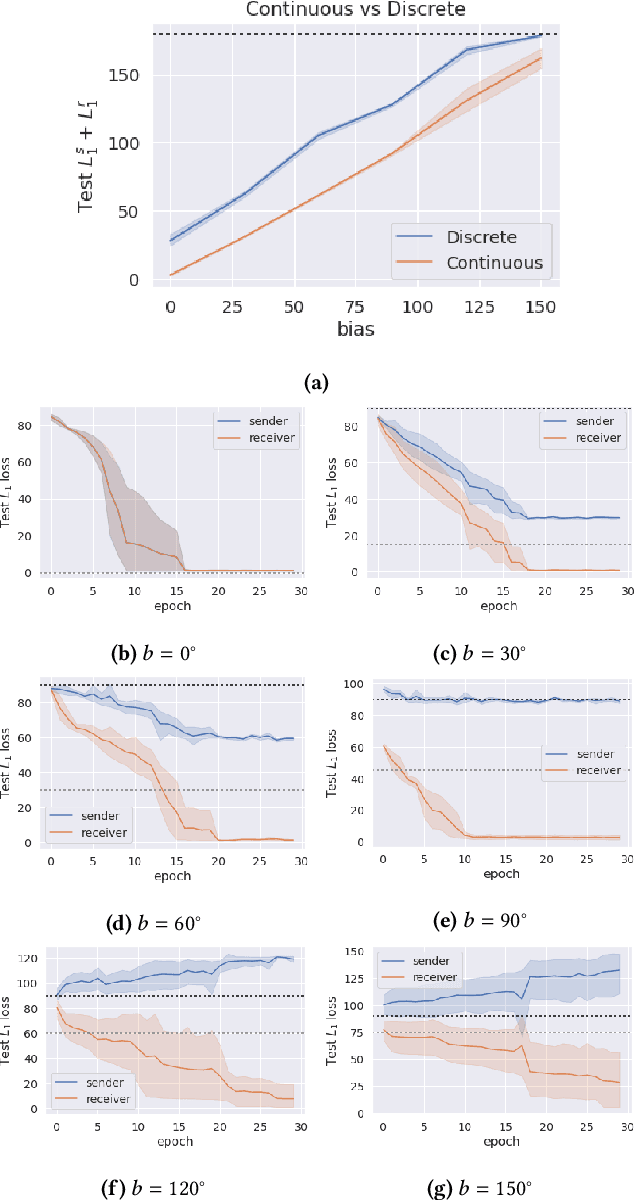
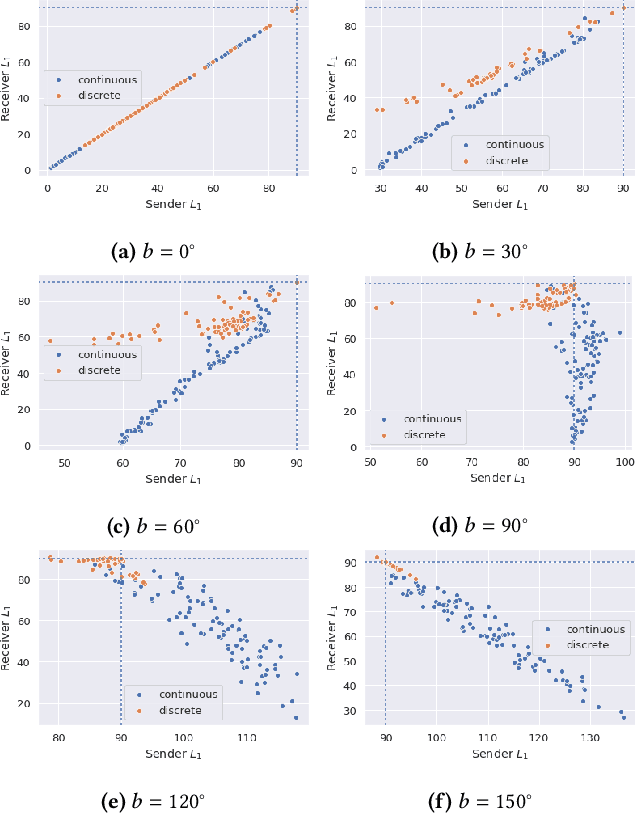
The literature in modern machine learning has only negative results for learning to communicate between competitive agents using standard RL. We introduce a modified sender-receiver game to study the spectrum of partially-competitive scenarios and show communication can indeed emerge in a competitive setting. We empirically demonstrate three key takeaways for future research. First, we show that communication is proportional to cooperation, and it can occur for partially competitive scenarios using standard learning algorithms. Second, we highlight the difference between communication and manipulation and extend previous metrics of communication to the competitive case. Third, we investigate the negotiation game where previous work failed to learn communication between independent agents (Cao et al., 2018). We show that, in this setting, both agents must benefit from communication for it to emerge; and, with a slight modification to the game, we demonstrate successful communication between competitive agents. We hope this work overturns misconceptions and inspires more research in competitive emergent communication.
The Tragedy of the AI Commons
Jun 09, 2020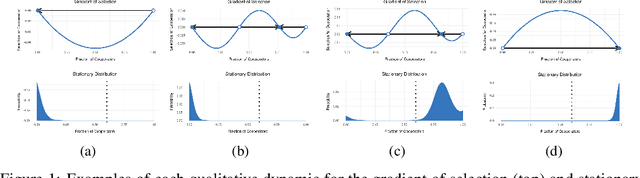
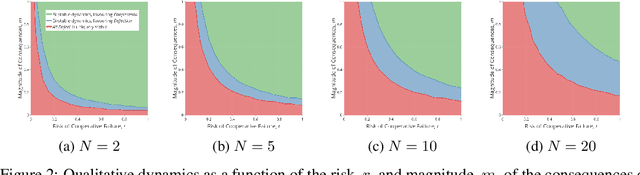
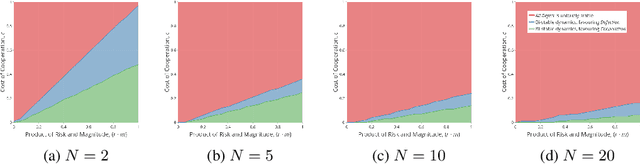
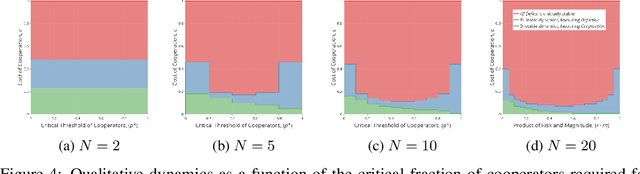
Policy and guideline proposals for ethical artificial-intelligence research have proliferated in recent years. These are supposed to guide the socially-responsible development of AI for the common good. However, there typically exist incentives for non-cooperation (i.e., non-adherence to such policies and guidelines); and, these proposals often lack effective mechanisms to enforce their own normative claims. The situation just described constitutes a social dilemma---namely, a situation where no one has an individual incentive to cooperate, though mutual cooperation would lead to the best outcome for all involved. In this paper, we use stochastic evolutionary game dynamics to model this social dilemma in the context of the ethical development of artificial intelligence. This formalism allows us to isolate variables that may be intervened upon, thus providing actionable suggestions for increased cooperation amongst numerous stakeholders in AI. Our results show how stochastic effects can help make cooperation viable in such a scenario. They suggest that coordination for a common good should be attempted in smaller groups in which the cost for cooperation is low, and the perceived risk of failure is high. This provides insight into the conditions under which we should expect such ethics proposals to be successful with regard to their scope, scale, and content.
Learning from Learning Machines: Optimisation, Rules, and Social Norms
Dec 29, 2019
There is an analogy between machine learning systems and economic entities in that they are both adaptive, and their behaviour is specified in a more-or-less explicit way. It appears that the area of AI that is most analogous to the behaviour of economic entities is that of morally good decision-making, but it is an open question as to how precisely moral behaviour can be achieved in an AI system. This paper explores the analogy between these two complex systems, and we suggest that a clearer understanding of this apparent analogy may help us forward in both the socio-economic domain and the AI domain: known results in economics may help inform feasible solutions in AI safety, but also known results in AI may inform economic policy. If this claim is correct, then the recent successes of deep learning for AI suggest that more implicit specifications work better than explicit ones for solving such problems.