 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowVal: A Knowledge-Augmented and Value-Guided Autonomous Driving System
Dec 23, 2025Visual-language reasoning, driving knowledge, and value alignment are essential for advanced autonomous driving systems. However, existing approaches largely rely on data-driven learning, making it difficult to capture the complex logic underlying decision-making through imitation or limited reinforcement rewards. To address this, we propose KnowVal, a new autonomous driving system that enables visual-language reasoning through the synergistic integration of open-world perception and knowledge retrieval. Specifically, we construct a comprehensive driving knowledge graph that encodes traffic laws, defensive driving principles, and ethical norms, complemented by an efficient LLM-based retrieval mechanism tailored for driving scenarios. Furthermore, we develop a human-preference dataset and train a Value Model to guide interpretable, value-aligned trajectory assessment. Experimental results show that our method substantially improves planning performance while remaining compatible with existing architectures. Notably, KnowVal achieves the lowest collision rate on nuScenes and state-of-the-art results on Bench2Drive.
HENet++: Hybrid Encoding and Multi-task Learning for 3D Perception and End-to-end Autonomous Driving
Nov 10, 2025Three-dimensional feature extraction is a critical component of autonomous driving systems, where perception tasks such as 3D object detection, bird's-eye-view (BEV) semantic segmentation, and occupancy prediction serve as important constraints on 3D features. While large image encoders, high-resolution images, and long-term temporal inputs can significantly enhance feature quality and deliver remarkable performance gains, these techniques are often incompatible in both training and inference due to computational resource constraints. Moreover, different tasks favor distinct feature representations, making it difficult for a single model to perform end-to-end inference across multiple tasks while maintaining accuracy comparable to that of single-task models. To alleviate these issues, we present the HENet and HENet++ framework for multi-task 3D perception and end-to-end autonomous driving. Specifically, we propose a hybrid image encoding network that uses a large image encoder for short-term frames and a small one for long-term frames. Furthermore, our framework simultaneously extracts both dense and sparse features, providing more suitable representations for different tasks, reducing cumulative errors, and delivering more comprehensive information to the planning module. The proposed architecture maintains compatibility with various existing 3D feature extraction methods and supports multimodal inputs. HENet++ achieves state-of-the-art end-to-end multi-task 3D perception results on the nuScenes benchmark, while also attaining the lowest collision rate on the nuScenes end-to-end autonomous driving benchmark.
InsFusion: Rethink Instance-level LiDAR-Camera Fusion for 3D Object Detection
Sep 10, 2025Three-dimensional Object Detection from multi-view cameras and LiDAR is a crucial component for autonomous driving and smart transportation. However, in the process of basic feature extraction, perspective transformation, and feature fusion, noise and error will gradually accumulate. To address this issue, we propose InsFusion, which can extract proposals from both raw and fused features and utilizes these proposals to query the raw features, thereby mitigating the impact of accumulated errors. Additionally, by incorporating attention mechanisms applied to the raw features, it thereby mitigates the impact of accumulated errors. Experiments on the nuScenes dataset demonstrate that InsFusion is compatible with various advanced baseline methods and delivers new state-of-the-art performance for 3D object detection.
RegCL: Continual Adaptation of Segment Anything Model via Model Merging
Jul 16, 2025



To address the performance limitations of the Segment Anything Model (SAM) in specific domains, existing works primarily adopt adapter-based one-step adaptation paradigms. However, some of these methods are specific developed for specific domains. If used on other domains may lead to performance degradation. This issue of catastrophic forgetting severely limits the model's scalability. To address this issue, this paper proposes RegCL, a novel non-replay continual learning (CL) framework designed for efficient multi-domain knowledge integration through model merging. Specifically, RegCL incorporates the model merging algorithm into the continual learning paradigm by merging the parameters of SAM's adaptation modules (e.g., LoRA modules) trained on different domains. The merging process is guided by weight optimization, which minimizes prediction discrepancies between the merged model and each of the domain-specific models. RegCL effectively consolidates multi-domain knowledge while maintaining parameter efficiency, i.e., the model size remains constant regardless of the number of tasks, and no historical data storage is required. Experimental results demonstrate that RegCL achieves favorable continual learning performance across multiple downstream datasets, validating its effectiveness in dynamic scenarios.
RFTF: Reinforcement Fine-tuning for Embodied Agents with Temporal Feedback
May 26, 2025Vision-Language-Action (VLA) models have demonstrated significant potential in the field of embodied intelligence, enabling agents to follow human instructions to complete complex tasks in physical environments. Existing embodied agents are often trained through behavior cloning, which requires expensive data and computational resources and is constrained by human demonstrations. To address this issue, many researchers explore the application of reinforcement fine-tuning to embodied agents. However, typical reinforcement fine-tuning methods for embodied agents usually rely on sparse, outcome-based rewards, which struggle to provide fine-grained feedback for specific actions within an episode, thus limiting the model's manipulation capabilities and generalization performance. In this paper, we propose RFTF, a novel reinforcement fine-tuning method that leverages a value model to generate dense rewards in embodied scenarios. Specifically, our value model is trained using temporal information, eliminating the need for costly robot action labels. In addition, RFTF incorporates a range of techniques, such as GAE and sample balance to enhance the effectiveness of the fine-tuning process. By addressing the sparse reward problem in reinforcement fine-tuning, our method significantly improves the performance of embodied agents, delivering superior generalization and adaptation capabilities across diverse embodied tasks. Experimental results show that embodied agents fine-tuned with RFTF achieve new state-of-the-art performance on the challenging CALVIN ABC-D with an average success length of 4.296. Moreover, RFTF enables rapid adaptation to new environments. After fine-tuning in the D environment of CALVIN for a few episodes, RFTF achieved an average success length of 4.301 in this new environment.
VL-SAM-V2: Open-World Object Detection with General and Specific Query Fusion
May 25, 2025



Current perception models have achieved remarkable success by leveraging large-scale labeled datasets, but still face challenges in open-world environments with novel objects. To address this limitation, researchers introduce open-set perception models to detect or segment arbitrary test-time user-input categories. However, open-set models rely on human involvement to provide predefined object categories as input during inference. More recently, researchers have framed a more realistic and challenging task known as open-ended perception that aims to discover unseen objects without requiring any category-level input from humans at inference time. Nevertheless, open-ended models suffer from low performance compared to open-set models. In this paper, we present VL-SAM-V2, an open-world object detection framework that is capable of discovering unseen objects while achieving favorable performance. To achieve this, we combine queries from open-set and open-ended models and propose a general and specific query fusion module to allow different queries to interact. By adjusting queries from open-set models, we enable VL-SAM-V2 to be evaluated in the open-set or open-ended mode. In addition, to learn more diverse queries, we introduce ranked learnable queries to match queries with proposals from open-ended models by sorting. Moreover, we design a denoising point training strategy to facilitate the training process. Experimental results on LVIS show that our method surpasses the previous open-set and open-ended methods, especially on rare objects.
T2VUnlearning: A Concept Erasing Method for Text-to-Video Diffusion Models
May 23, 2025Recent advances in text-to-video (T2V) diffusion models have significantly enhanced the quality of generated videos. However, their ability to produce explicit or harmful content raises concerns about misuse and potential rights violations. Inspired by the success of unlearning techniques in erasing undesirable concepts from text-to-image (T2I) models, we extend unlearning to T2V models and propose a robust and precise unlearning method. Specifically, we adopt negatively-guided velocity prediction fine-tuning and enhance it with prompt augmentation to ensure robustness against LLM-refined prompts. To achieve precise unlearning, we incorporate a localization and a preservation regularization to preserve the model's ability to generate non-target concepts. Extensive experiments demonstrate that our method effectively erases a specific concept while preserving the model's generation capability for all other concepts, outperforming existing methods. We provide the unlearned models in \href{https://github.com/VDIGPKU/T2VUnlearning.git}{https://github.com/VDIGPKU/T2VUnlearning.git}.
RobuRCDet: Enhancing Robustness of Radar-Camera Fusion in Bird's Eye View for 3D Object Detection
Feb 18, 2025While recent low-cost radar-camera approaches have shown promising results in multi-modal 3D object detection, both sensors face challenges from environmental and intrinsic disturbances. Poor lighting or adverse weather conditions degrade camera performance, while radar suffers from noise and positional ambiguity. Achieving robust radar-camera 3D object detection requires consistent performance across varying conditions, a topic that has not yet been fully explored. In this work, we first conduct a systematic analysis of robustness in radar-camera detection on five kinds of noises and propose RobuRCDet, a robust object detection model in BEV. Specifically, we design a 3D Gaussian Expansion (3DGE) module to mitigate inaccuracies in radar points, including position, Radar Cross-Section (RCS), and velocity. The 3DGE uses RCS and velocity priors to generate a deformable kernel map and variance for kernel size adjustment and value distribution. Additionally, we introduce a weather-adaptive fusion module, which adaptively fuses radar and camera features based on camera signal confidence. Extensive experiments on the popular benchmark, nuScenes, show that our model achieves competitive results in regular and noisy conditions.
OccGS: Zero-shot 3D Occupancy Reconstruction with Semantic and Geometric-Aware Gaussian Splatting
Feb 07, 2025
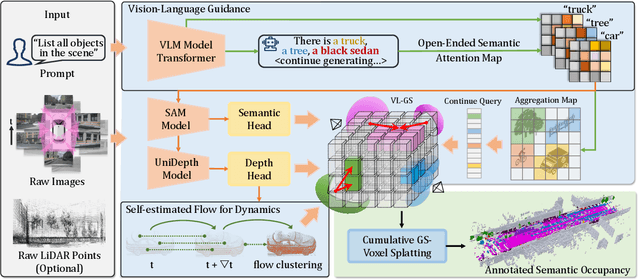
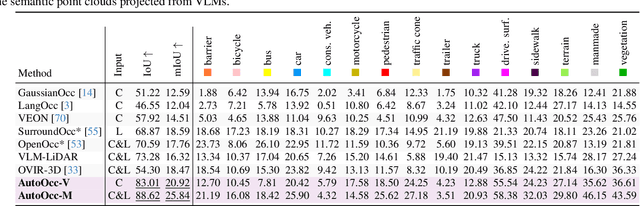
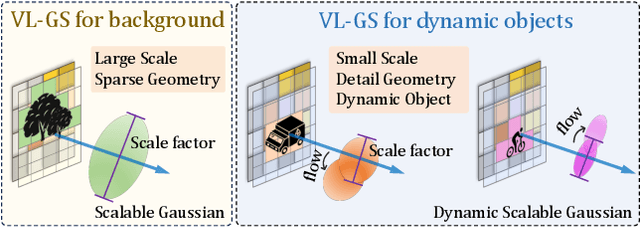
Obtaining semantic 3D occupancy from raw sensor data without manual annotations remains an essential yet challenging task. While prior works have approached this as a perception prediction problem, we formulate it as scene-aware 3D occupancy reconstruction with geometry and semantics. In this work, we propose OccGS, a novel 3D Occupancy reconstruction framework utilizing Semantic and Geometric-Aware Gaussian Splatting in a zero-shot manner. Leveraging semantics extracted from vision-language models and geometry guided by LiDAR points, OccGS constructs Semantic and Geometric-Aware Gaussians from raw multisensor data. We also develop a cumulative Gaussian-to-3D voxel splatting method for reconstructing occupancy from the Gaussians. OccGS performs favorably against self-supervised methods in occupancy prediction, achieving comparable performance to fully supervised approaches and achieving state-of-the-art performance on zero-shot semantic 3D occupancy estimation.
OpenAD: Open-World Autonomous Driving Benchmark for 3D Object Detection
Nov 26, 2024



Open-world autonomous driving encompasses domain generalization and open-vocabulary. Domain generalization refers to the capabilities of autonomous driving systems across different scenarios and sensor parameter configurations. Open vocabulary pertains to the ability to recognize various semantic categories not encountered during training. In this paper, we introduce OpenAD, the first real-world open-world autonomous driving benchmark for 3D object detection. OpenAD is built on a corner case discovery and annotation pipeline integrating with a multimodal large language model (MLLM). The proposed pipeline annotates corner case objects in a unified format for five autonomous driving perception datasets with 2000 scenarios. In addition, we devise evaluation methodologies and evaluate various 2D and 3D open-world and specialized models. Moreover, we propose a vision-centric 3D open-world object detection baseline and further introduce an ensemble method by fusing general and specialized models to address the issue of lower precision in existing open-world methods for the OpenAD benchmark. Annotations, toolkit code, and all evaluation codes will be released.