 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Cross-Domain Speech Recognition with Self-Supervision
Jun 20, 2022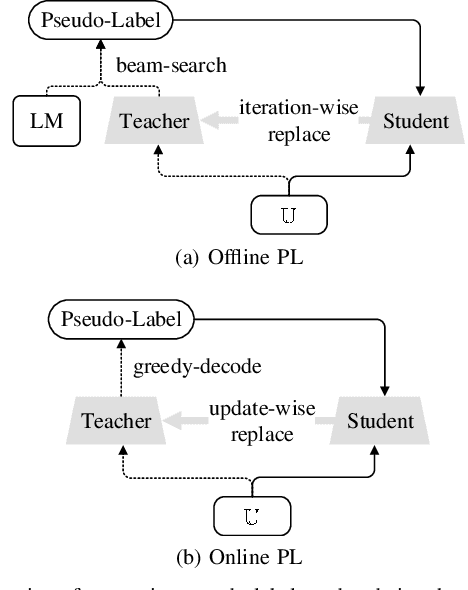
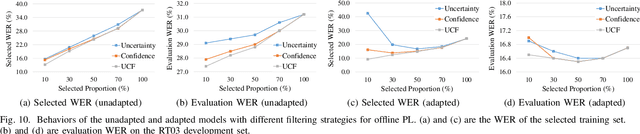
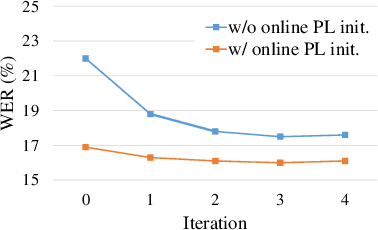
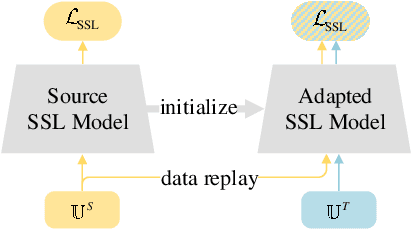
The cross-domain performance of automatic speech recognition (ASR) could be severely hampered due to the mismatch between training and testing distributions. Since the target domain usually lacks labeled data, and domain shifts exist at acoustic and linguistic levels, it is challenging to perform unsupervised domain adaptation (UDA) for ASR. Previous work has shown that self-supervised learning (SSL) or pseudo-labeling (PL) is effective in UDA by exploiting the self-supervisions of unlabeled data. However, these self-supervisions also face performance degradation in mismatched domain distributions, which previous work fails to address. This work presents a systematic UDA framework to fully utilize the unlabeled data with self-supervision in the pre-training and fine-tuning paradigm. On the one hand, we apply continued pre-training and data replay techniques to mitigate the domain mismatch of the SSL pre-trained model. On the other hand, we propose a domain-adaptive fine-tuning approach based on the PL technique with three unique modifications: Firstly, we design a dual-branch PL method to decrease the sensitivity to the erroneous pseudo-labels; Secondly, we devise an uncertainty-aware confidence filtering strategy to improve pseudo-label correctness; Thirdly, we introduce a two-step PL approach to incorporate target domain linguistic knowledge, thus generating more accurate target domain pseudo-labels. Experimental results on various cross-domain scenarios demonstrate that the proposed approach could effectively boost the cross-domain performance and significantly outperform previous approaches.
Decoupled Federated Learning for ASR with Non-IID Data
Jun 18, 2022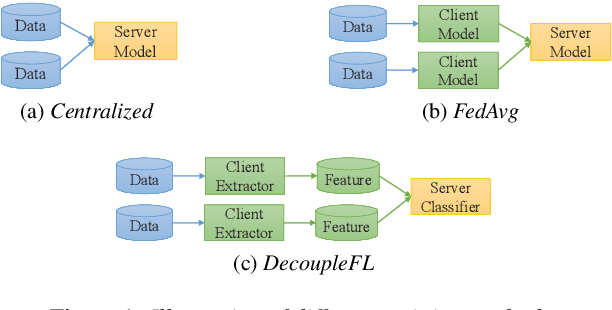
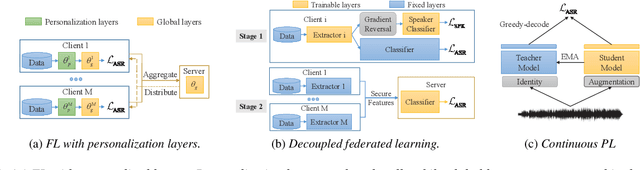
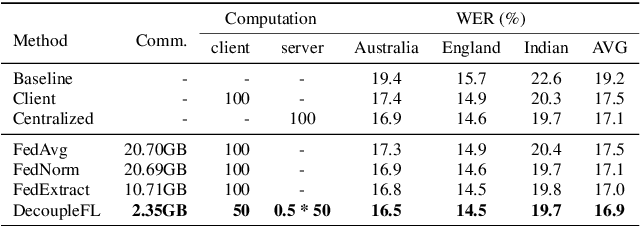
Automatic speech recognition (ASR) with federated learning (FL) makes it possible to leverage data from multiple clients without compromising privacy. The quality of FL-based ASR could be measured by recognition performance, communication and computation costs. When data among different clients are not independently and identically distributed (non-IID), the performance could degrade significantly. In this work, we tackle the non-IID issue in FL-based ASR with personalized FL, which learns personalized models for each client. Concretely, we propose two types of personalized FL approaches for ASR. Firstly, we adapt the personalization layer based FL for ASR, which keeps some layers locally to learn personalization models. Secondly, to reduce the communication and computation costs, we propose decoupled federated learning (DecoupleFL). On one hand, DecoupleFL moves the computation burden to the server, thus decreasing the computation on clients. On the other hand, DecoupleFL communicates secure high-level features instead of model parameters, thus reducing communication cost when models are large. Experiments demonstrate two proposed personalized FL-based ASR approaches could reduce WER by 2.3% - 3.4% compared with FedAvg. Among them, DecoupleFL has only 11.4% communication and 75% computation cost compared with FedAvg, which is also significantly less than the personalization layer based FL.
Open Source MagicData-RAMC: A Rich Annotated Mandarin Conversational Speech Dataset
Mar 31, 2022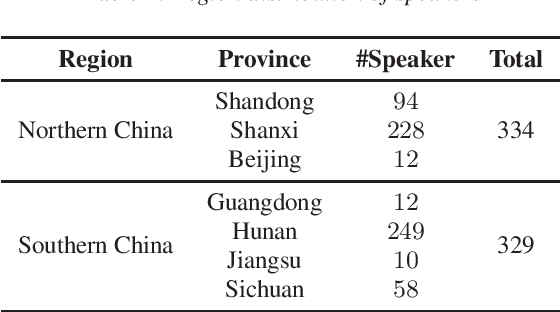
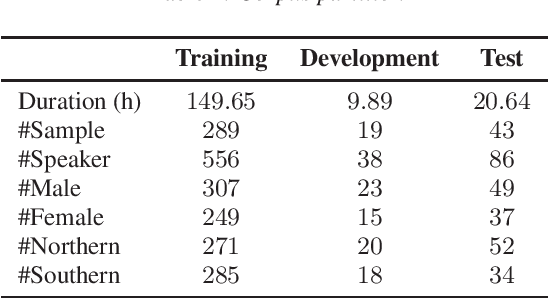
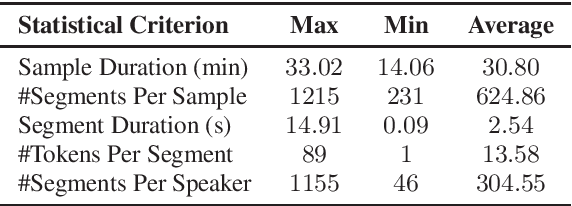
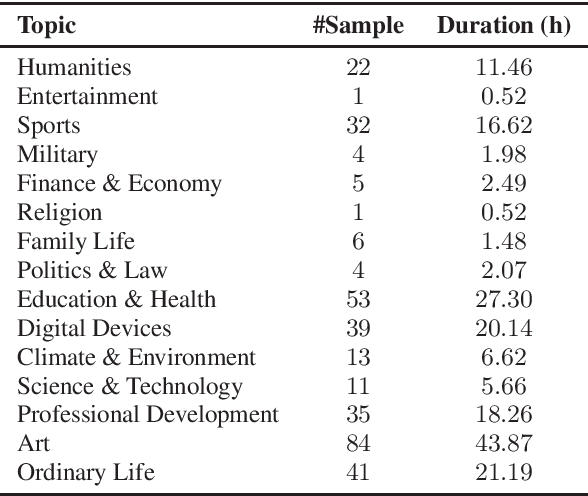
This paper introduces a high-quality rich annotated Mandarin conversational (RAMC) speech dataset called MagicData-RAMC. The MagicData-RAMC corpus contains 180 hours of conversational speech data recorded from native speakers of Mandarin Chinese over mobile phones with a sampling rate of 16 kHz. The dialogs in MagicData-RAMC are classified into 15 diversified domains and tagged with topic labels, ranging from science and technology to ordinary life. Accurate transcription and precise speaker voice activity timestamps are manually labeled for each sample. Speakers' detailed information is also provided. As a Mandarin speech dataset designed for dialog scenarios with high quality and rich annotations, MagicData-RAMC enriches the data diversity in the Mandarin speech community and allows extensive research on a series of speech-related tasks, including automatic speech recognition, speaker diarization, topic detection, keyword search, text-to-speech, etc. We also conduct several relevant tasks and provide experimental results to help evaluate the dataset.
Decomposing Complex Questions Makes Multi-Hop QA Easier and More Interpretable
Oct 26, 2021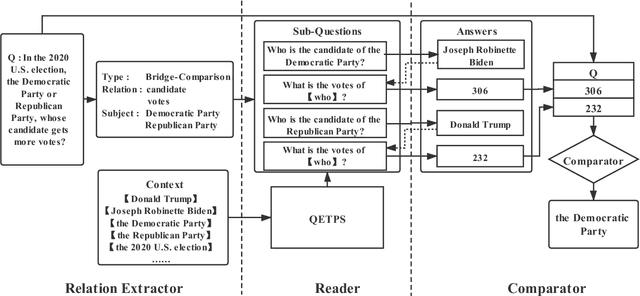
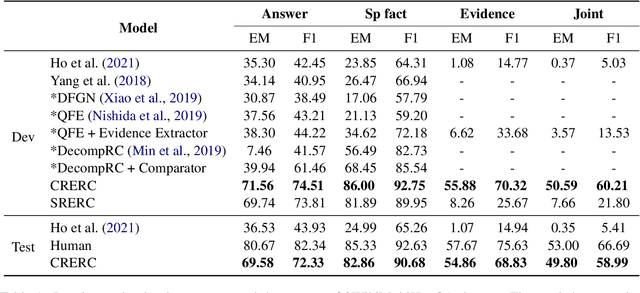
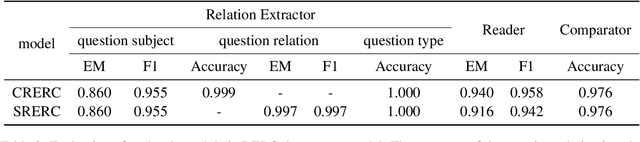
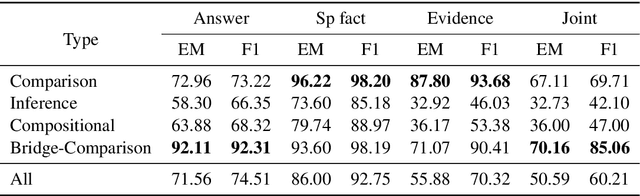
Multi-hop QA requires the machine to answer complex questions through finding multiple clues and reasoning, and provide explanatory evidence to demonstrate the machine reasoning process. We propose Relation Extractor-Reader and Comparator (RERC), a three-stage framework based on complex question decomposition, which is the first work that the RERC model has been proposed and applied in solving the multi-hop QA challenges. The Relation Extractor decomposes the complex question, and then the Reader answers the sub-questions in turn, and finally the Comparator performs numerical comparison and summarizes all to get the final answer, where the entire process itself constitutes a complete reasoning evidence path. In the 2WikiMultiHopQA dataset, our RERC model has achieved the most advanced performance, with a winning joint F1 score of 53.58 on the leaderboard. All indicators of our RERC are close to human performance, with only 1.95 behind the human level in F1 score of support fact. At the same time, the evidence path provided by our RERC framework has excellent readability and faithfulness.
Reminding the Incremental Language Model via Data-Free Self-Distillation
Oct 17, 2021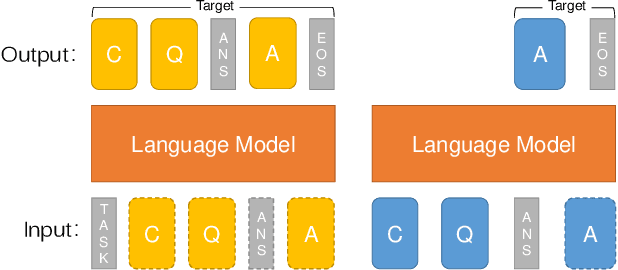
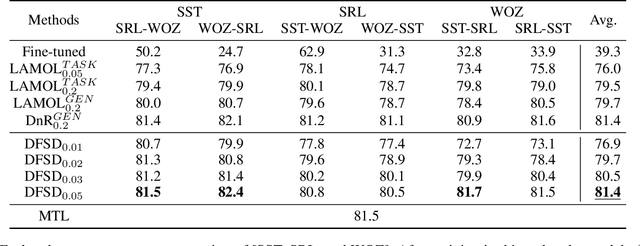
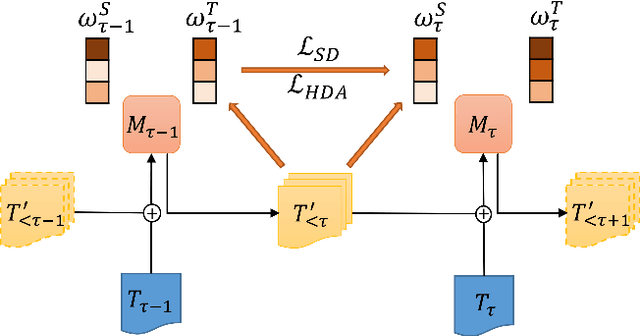
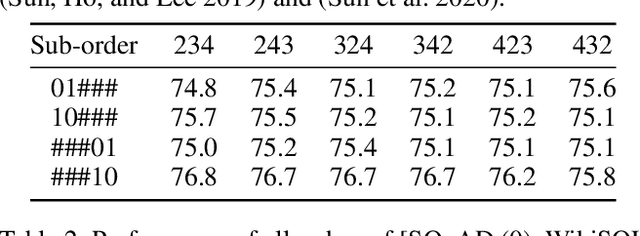
Incremental language learning with pseudo-data can alleviate catastrophic forgetting in neural networks. However, to obtain better performance, former methods have higher demands for pseudo-data of the previous tasks. The performance dramatically decreases when fewer pseudo-data are employed. In addition, the distribution of pseudo-data gradually deviates from the real data with the sequential learning of different tasks. The deviation will be greater with more tasks learned, which results in more serious catastrophic forgetting. To address these issues, we propose reminding incremental language model via data-free self-distillation (DFSD), which includes self-distillation based on the Earth Mover's Distance and hidden data augmentation. By estimating the knowledge distribution in all layers of GPT-2 and transforming it from teacher model to student model, the Self-distillation based on the Earth Mover's Distance can significantly reduce the demand for pseudo-data. Hidden data augmentation can greatly alleviate the catastrophic forgetting caused by deviations via modeling the generation of pseudo-data as a hidden data augmentation process, where each sample is a mixture of all trained task data. The experimental results demonstrate that our DFSD can exceed the previous state-of-the-art methods even if the maximum decrease in pseudo-data is 90%.
Wav2vec-S: Semi-Supervised Pre-Training for Speech Recognition
Oct 09, 2021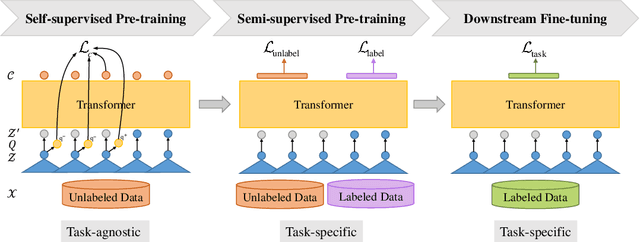
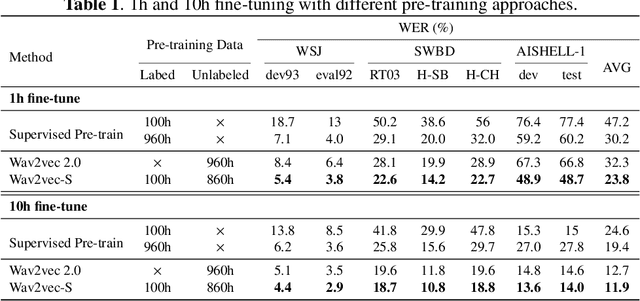
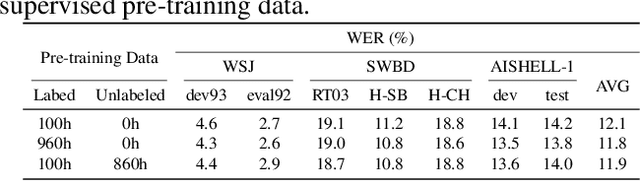
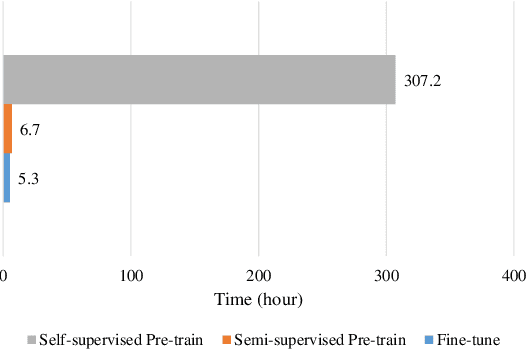
Self-supervised pre-training has dramatically improved the performance of automatic speech recognition (ASR). However, most existing self-supervised pre-training approaches are task-agnostic, i.e., could be applied to various downstream tasks. And there is a gap between the task-agnostic pre-training and the task-specific downstream fine-tuning, which may degrade the downstream performance. In this work, we propose a novel pre-training paradigm called wav2vec-S, where we use task-specific semi-supervised pre-training to bridge this gap. Specifically, the semi-supervised pre-training is conducted on the basis of self-supervised pre-training such as wav2vec 2.0. Experiments on ASR show that compared to wav2vec 2.0, wav2vec-S only requires marginal increment of pre-training time but could significantly improve ASR performance on in-domain, cross-domain and cross-lingual datasets. The average relative WER reductions are 26.3% and 6.3% for 1h and 10h fine-tuning, respectively.
The HCCL Speaker Verification System for Far-Field Speaker Verification Challenge
Jul 03, 2021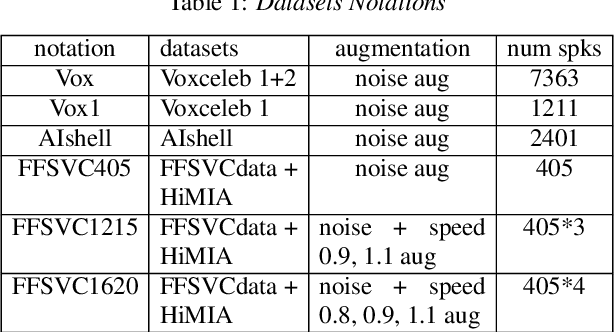
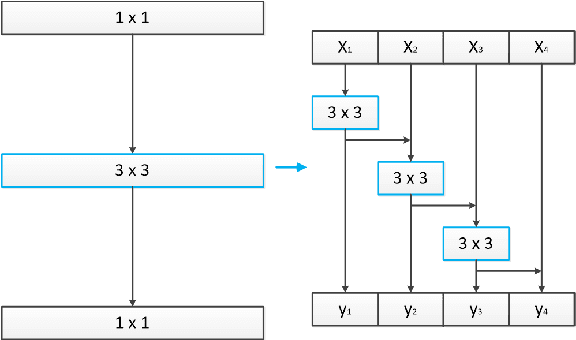
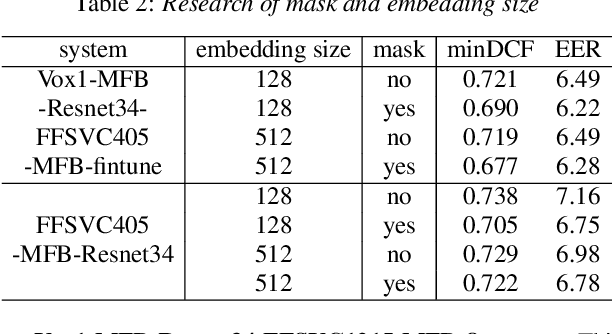
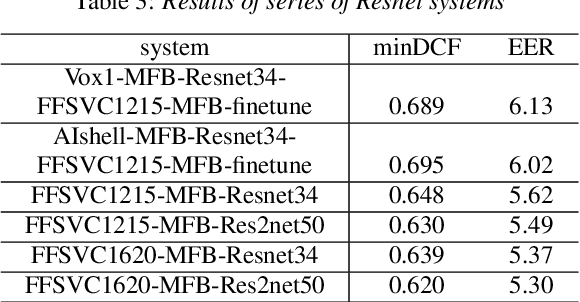
This paper describes the systems submitted by team HCCL to the Far-Field Speaker Verification Challenge. Our previous work in the AIshell Speaker Verification Challenge 2019 shows that the powerful modeling abilities of Neural Network architectures can provide exceptional performance for this kind of task. Therefore, in this challenge, we focus on constructing deep Neural Network architectures based on TDNN, Resnet and Res2net blocks. Most of the developed systems consist of Neural Network embeddings are applied with PLDA backend. Firstly, the speed perturbation method is applied to augment data and significant performance improvements are achieved. Then, we explore the use of AMsoftmax loss function and propose to join a CE-loss branch when we train model using AMsoftmax loss. In addition, the impact of score normalization on performance is also investigated. The final system, a fusion of four systems, achieves minDCF 0.5342, EER 5.05\% on task1 eval set, and achieves minDCF 0.5193, EER 5.47\% on task3 eval set.
Improved Conformer-based End-to-End Speech Recognition Using Neural Architecture Search
Apr 13, 2021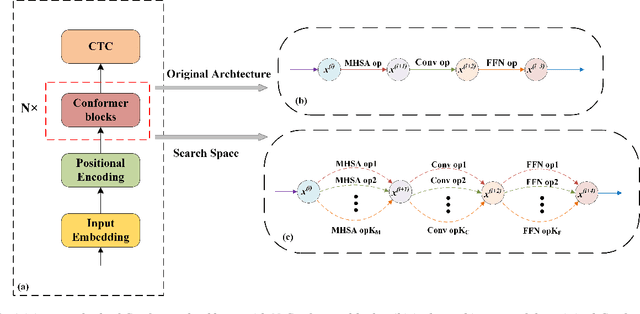

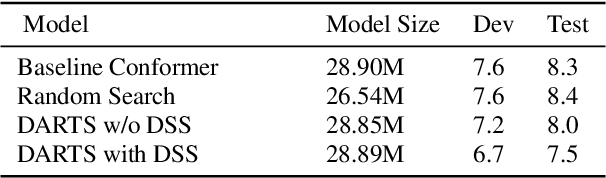
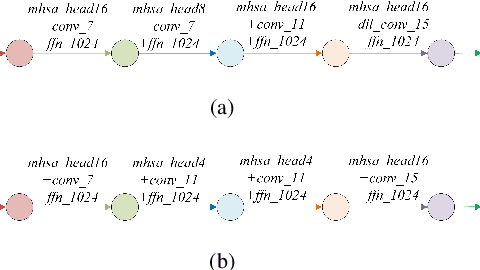
Recently neural architecture search(NAS) has been successfully used in image classification, natural language processing, and automatic speech recognition(ASR) tasks for finding the state-of-the-art(SOTA) architectures than those human-designed architectures. NAS can derive a SOTA and data-specific architecture over validation data from a pre-defined search space with a search algorithm. Inspired by the success of NAS in ASR tasks, we propose a NAS-based ASR framework containing one search space and one differentiable search algorithm called Differentiable Architecture Search(DARTS). Our search space follows the convolution-augmented transformer(Conformer) backbone, which is a more expressive ASR architecture than those used in existing NAS-based ASR frameworks. To improve the performance of our method, a regulation method called Dynamic Search Schedule(DSS) is employed. On a widely used Mandarin benchmark AISHELL-1, our best-searched architecture outperforms the baseline Conform model significantly with about 11% CER relative improvement, and our method is proved to be pretty efficient by the search cost comparisons.
Multi-Accent Adaptation based on Gate Mechanism
Nov 05, 2020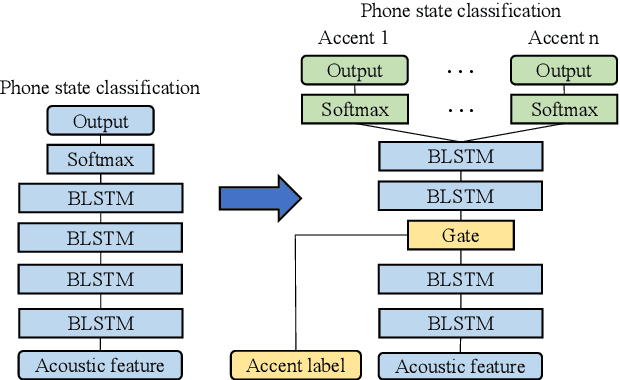
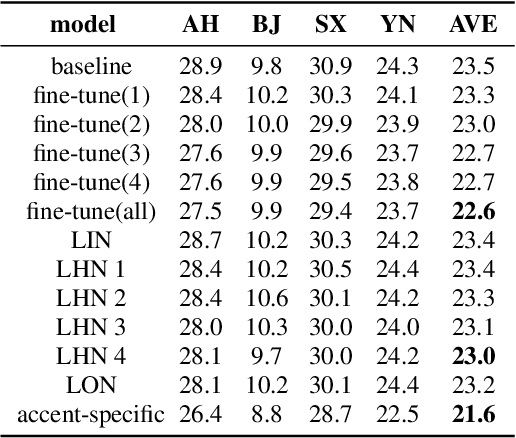
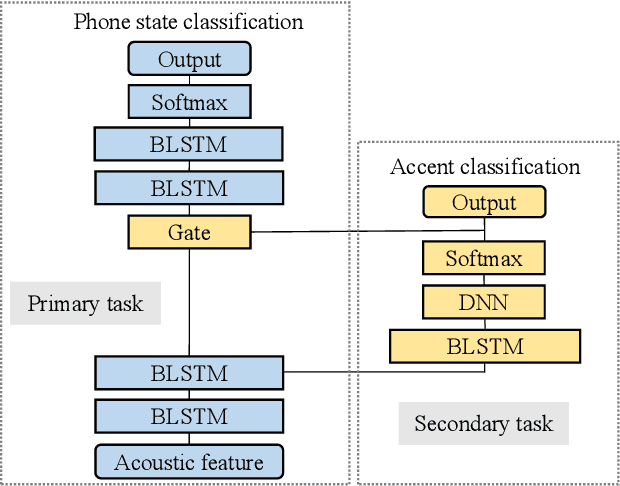
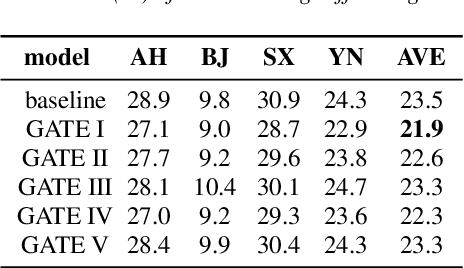
When only a limited amount of accented speech data is available, to promote multi-accent speech recognition performance, the conventional approach is accent-specific adaptation, which adapts the baseline model to multiple target accents independently. To simplify the adaptation procedure, we explore adapting the baseline model to multiple target accents simultaneously with multi-accent mixed data. Thus, we propose using accent-specific top layer with gate mechanism (AST-G) to realize multi-accent adaptation. Compared with the baseline model and accent-specific adaptation, AST-G achieves 9.8% and 1.9% average relative WER reduction respectively. However, in real-world applications, we can't obtain the accent category label for inference in advance. Therefore, we apply using an accent classifier to predict the accent label. To jointly train the acoustic model and the accent classifier, we propose the multi-task learning with gate mechanism (MTL-G). As the accent label prediction could be inaccurate, it performs worse than the accent-specific adaptation. Yet, in comparison with the baseline model, MTL-G achieves 5.1% average relative WER reduction.
A Model Compression Method with Matrix Product Operators for Speech Enhancement
Oct 10, 2020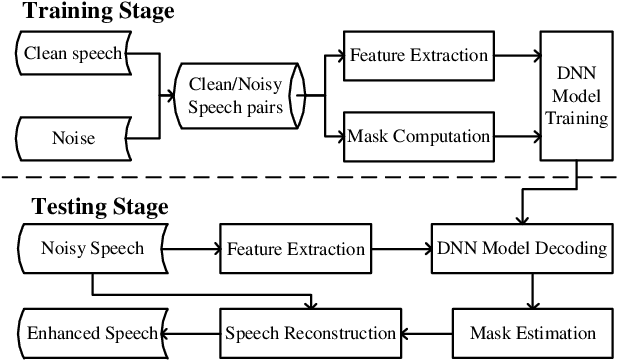

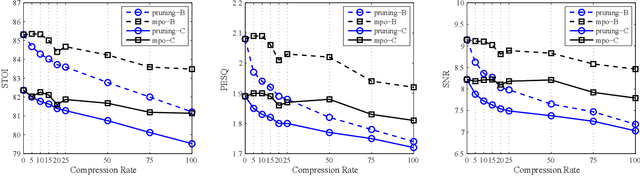
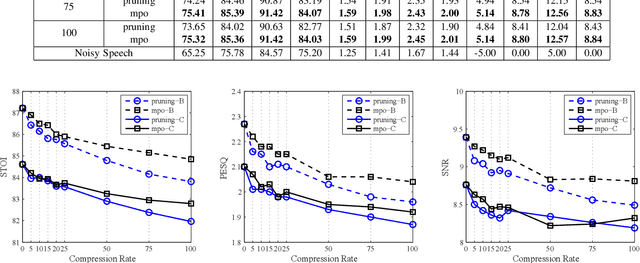
The deep neural network (DNN) based speech enhancement approaches have achieved promising performance. However, the number of parameters involved in these methods is usually enormous for the real applications of speech enhancement on the device with the limited resources. This seriously restricts the applications. To deal with this issue, model compression techniques are being widely studied. In this paper, we propose a model compression method based on matrix product operators (MPO) to substantially reduce the number of parameters in DNN models for speech enhancement. In this method, the weight matrices in the linear transformations of neural network model are replaced by the MPO decomposition format before training. In experiment, this process is applied to the causal neural network models, such as the feedforward multilayer perceptron (MLP) and long short-term memory (LSTM) models. Both MLP and LSTM models with/without compression are then utilized to estimate the ideal ratio mask for monaural speech enhancement. The experimental results show that our proposed MPO-based method outperforms the widely-used pruning method for speech enhancement under various compression rates, and further improvement can be achieved with respect to low compression rates. Our proposal provides an effective model compression method for speech enhancement, especially in cloud-free application.
* 11 pages, 6 figures, 7 tables