 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Few-shot Relation Classification: Evaluation Data and Classification Schemes
Apr 17, 2021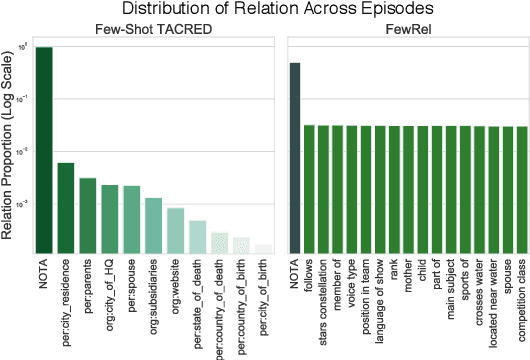
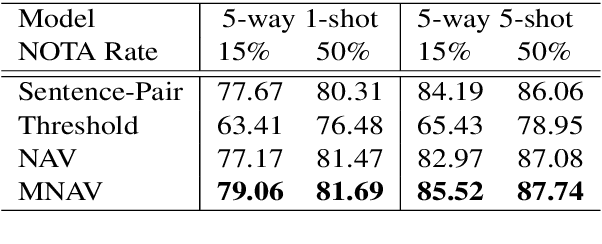
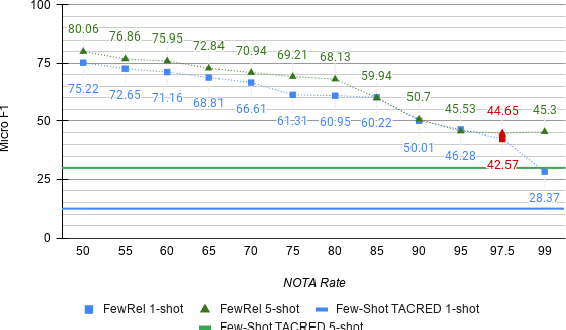
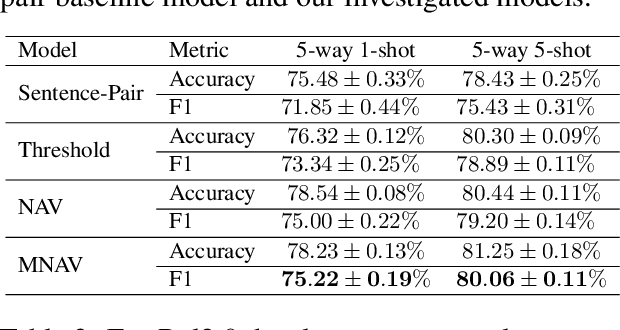
We explore Few-Shot Learning (FSL) for Relation Classification (RC). Focusing on the realistic scenario of FSL, in which a test instance might not belong to any of the target categories (none-of-the-above, aka NOTA), we first revisit the recent popular dataset structure for FSL, pointing out its unrealistic data distribution. To remedy this, we propose a novel methodology for deriving more realistic few-shot test data from available datasets for supervised RC, and apply it to the TACRED dataset. This yields a new challenging benchmark for FSL RC, on which state of the art models show poor performance. Next, we analyze classification schemes within the popular embedding-based nearest-neighbor approach for FSL, with respect to constraints they impose on the embedding space. Triggered by this analysis we propose a novel classification scheme, in which the NOTA category is represented as learned vectors, shown empirically to be an appealing option for FSL.
Back to Square One: Bias Detection, Training and Commonsense Disentanglement in the Winograd Schema
Apr 16, 2021
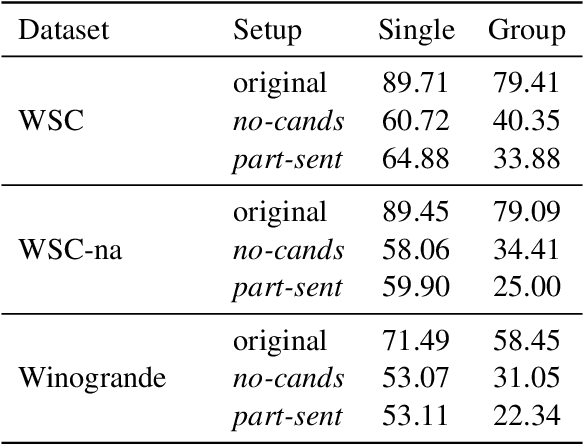

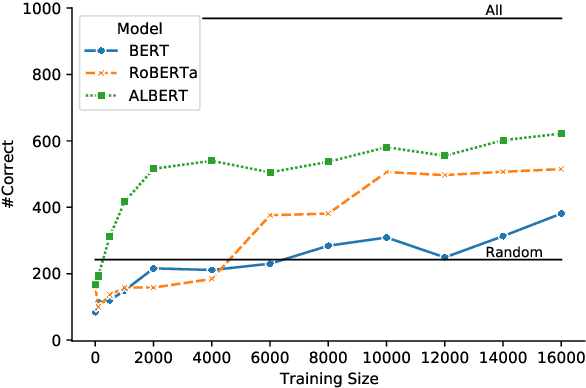
The Winograd Schema (WS) has been proposed as a test for measuring commonsense capabilities of models. Recently, pre-trained language model-based approaches have boosted performance on some WS benchmarks but the source of improvement is still not clear. We begin by showing that the current evaluation method of WS is sub-optimal and propose a modification that makes use of twin sentences for evaluation. We also propose two new baselines that indicate the existence of biases in WS benchmarks. Finally, we propose a method for evaluating WS-like sentences in a zero-shot setting and observe that popular language models perform randomly in this setting. We conclude that much of the apparent progress on WS may not necessarily reflect progress in commonsense reasoning, but much of it comes from supervised data, which is not likely to account for all the required commonsense reasoning skills and knowledge.
Contrastive Explanations for Model Interpretability
Mar 02, 2021

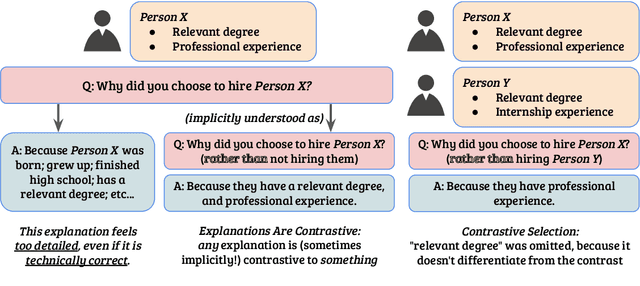
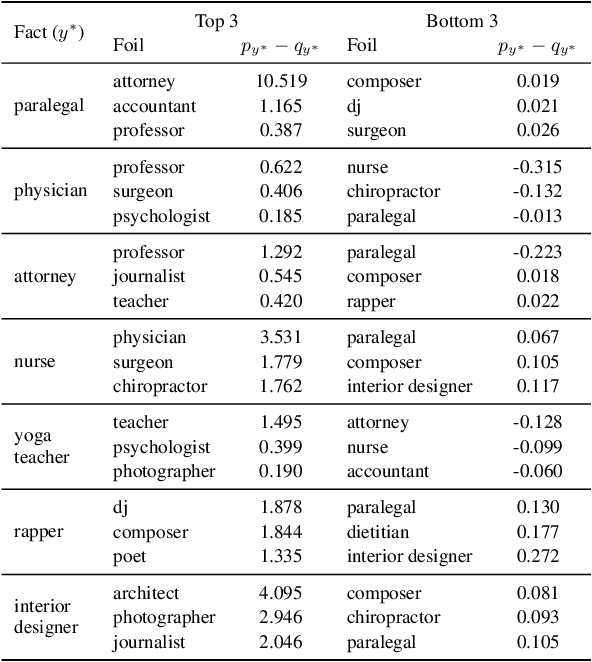
Contrastive explanations clarify why an event occurred in contrast to another. They are more inherently intuitive to humans to both produce and comprehend. We propose a methodology to produce contrastive explanations for classification models by modifying the representation to disregard non-contrastive information, and modifying model behavior to only be based on contrastive reasoning. Our method is based on projecting model representation to a latent space that captures only the features that are useful (to the model) to differentiate two potential decisions. We demonstrate the value of contrastive explanations by analyzing two different scenarios, using both high-level abstract concept attribution and low-level input token/span attribution, on two widely used text classification tasks. Specifically, we produce explanations for answering: for which label, and against which alternative label, is some aspect of the input useful? And which aspects of the input are useful for and against particular decisions? Overall, our findings shed light on the ability of label-contrastive explanations to provide a more accurate and finer-grained interpretability of a model's decision.
Bootstrapping Relation Extractors using Syntactic Search by Examples
Feb 09, 2021
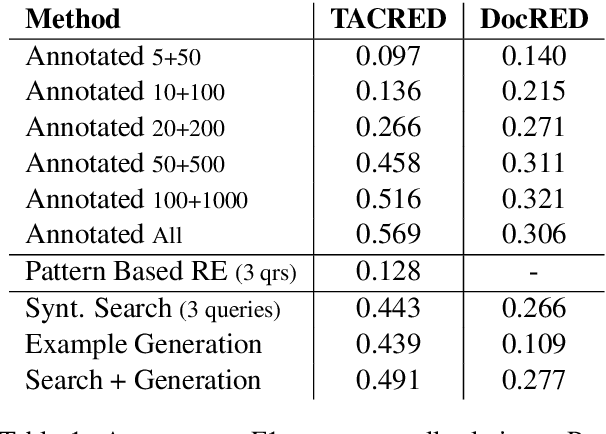
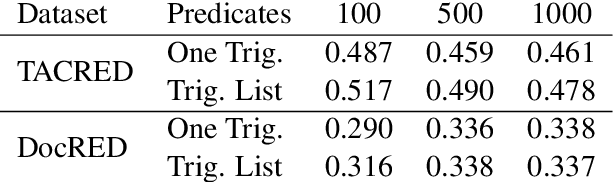
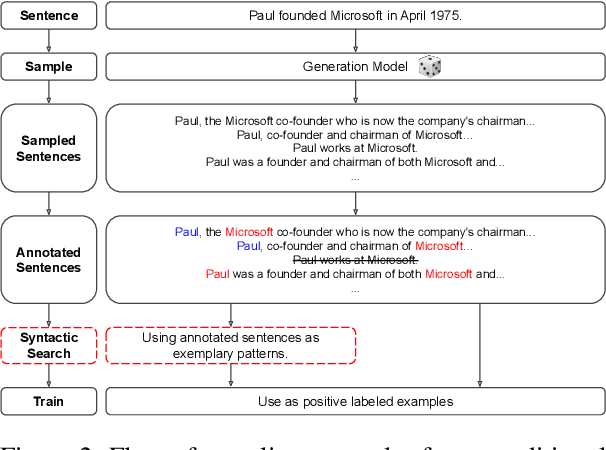
The advent of neural-networks in NLP brought with it substantial improvements in supervised relation extraction. However, obtaining a sufficient quantity of training data remains a key challenge. In this work we propose a process for bootstrapping training datasets which can be performed quickly by non-NLP-experts. We take advantage of search engines over syntactic-graphs (Such as Shlain et al. (2020)) which expose a friendly by-example syntax. We use these to obtain positive examples by searching for sentences that are syntactically similar to user input examples. We apply this technique to relations from TACRED and DocRED and show that the resulting models are competitive with models trained on manually annotated data and on data obtained from distant supervision. The models also outperform models trained using NLG data augmentation techniques. Extending the search-based approach with the NLG method further improves the results.
Measuring and Improving Consistency in Pretrained Language Models
Feb 01, 2021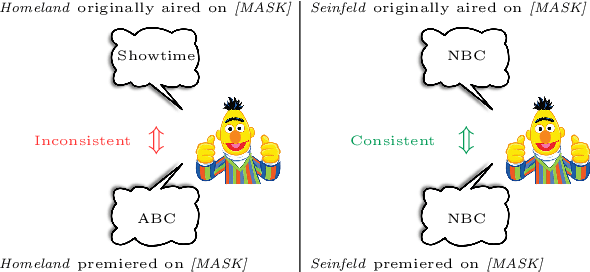
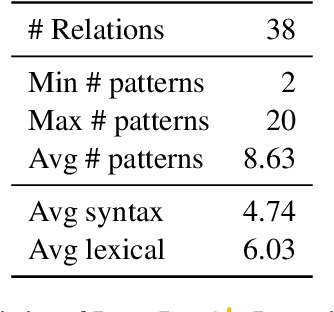
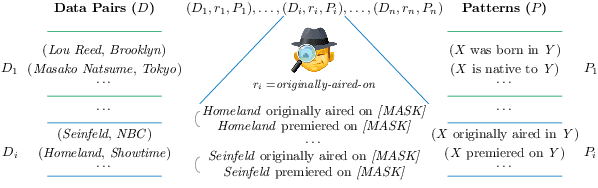
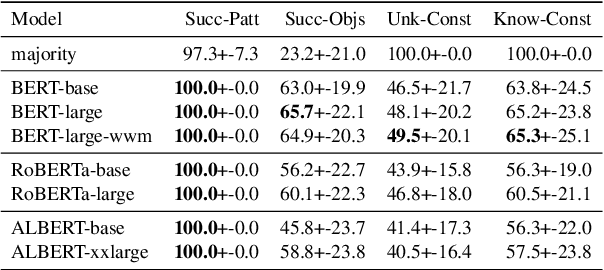
Consistency of a model -- that is, the invariance of its behavior under meaning-preserving alternations in its input -- is a highly desirable property in natural language processing. In this paper we study the question: Are Pretrained Language Models (PLMs) consistent with respect to factual knowledge? To this end, we create ParaRel, a high-quality resource of cloze-style query English paraphrases. It contains a total of 328 paraphrases for thirty-eight relations. Using ParaRel, we show that the consistency of all PLMs we experiment with is poor -- though with high variance between relations. Our analysis of the representational spaces of PLMs suggests that they have a poor structure and are currently not suitable for representing knowledge in a robust way. Finally, we propose a method for improving model consistency and experimentally demonstrate its effectiveness.
A simple geometric proof for the benefit of depth in ReLU networks
Jan 18, 2021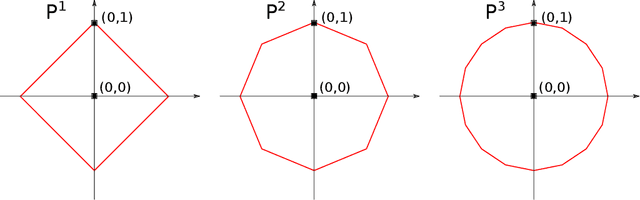
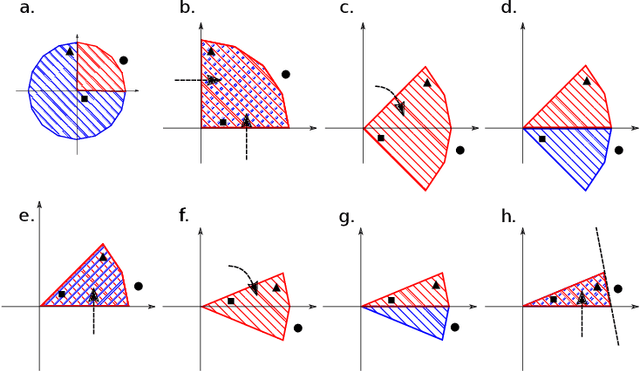
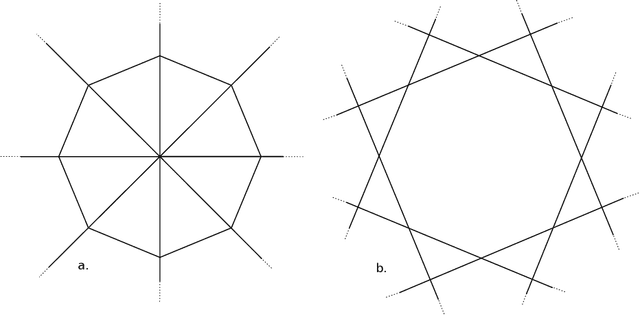
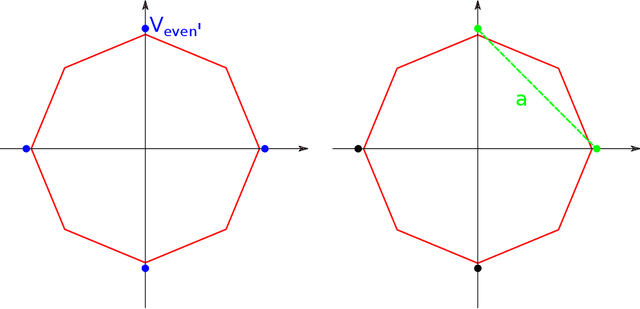
We present a simple proof for the benefit of depth in multi-layer feedforward network with rectified activation ("depth separation"). Specifically we present a sequence of classification problems indexed by $m$ such that (a) for any fixed depth rectified network there exist an $m$ above which classifying problem $m$ correctly requires exponential number of parameters (in $m$); and (b) for any problem in the sequence, we present a concrete neural network with linear depth (in $m$) and small constant width ($\leq 4$) that classifies the problem with zero error. The constructive proof is based on geometric arguments and a space folding construction. While stronger bounds and results exist, our proof uses substantially simpler tools and techniques, and should be accessible to undergraduate students in computer science and people with similar backgrounds.
Facts2Story: Controlling Text Generation by Key Facts
Dec 08, 2020
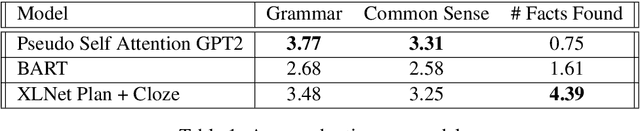

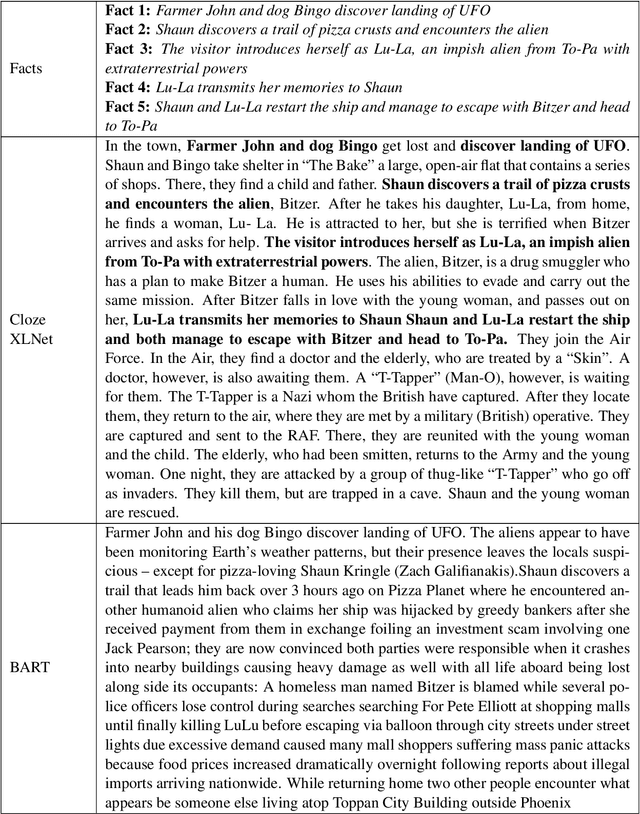
Recent advancements in self-attention neural network architectures have raised the bar for open-ended text generation. Yet, while current methods are capable of producing a coherent text which is several hundred words long, attaining control over the content that is being generated -- as well as evaluating it -- are still open questions. We propose a controlled generation task which is based on expanding a sequence of facts, expressed in natural language, into a longer narrative. We introduce human-based evaluation metrics for this task, as well as a method for deriving a large training dataset. We evaluate three methods on this task, based on fine-tuning pre-trained models. We show that while auto-regressive, unidirectional Language Models such as GPT2 produce better fluency, they struggle to adhere to the requested facts. We propose a plan-and-cloze model (using fine-tuned XLNet) which produces competitive fluency while adhering to the requested content.
Parameter Norm Growth During Training of Transformers
Nov 11, 2020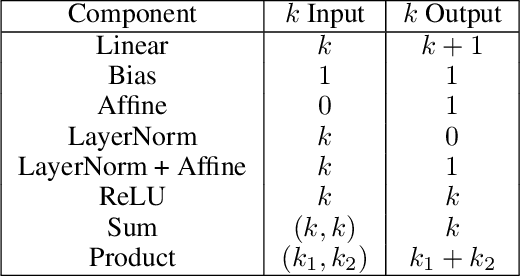
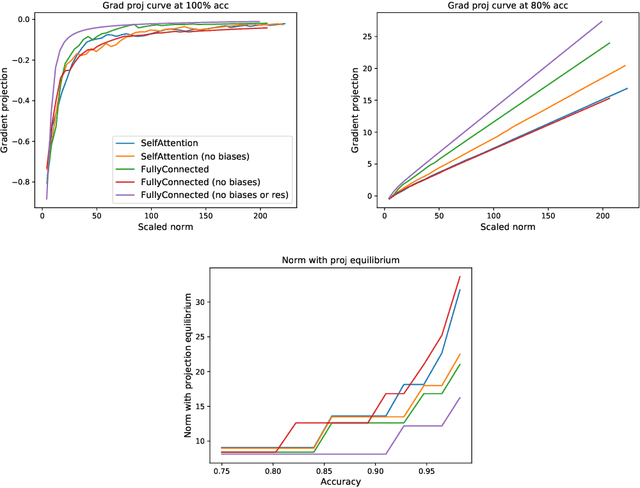
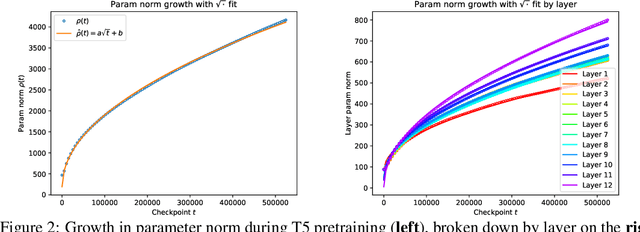
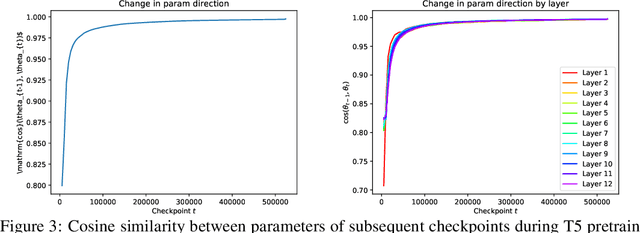
The capacity of neural networks like the widely adopted transformer is known to be very high. Evidence is emerging that they learn successfully due to inductive bias in the training routine, typically some variant of gradient descent (GD). To better understand this bias, we study the tendency of transformer parameters to grow in magnitude during training. We find, both theoretically and empirically, that, in certain contexts, GD increases the parameter $L_2$ norm up to a threshold that itself increases with training-set accuracy. This means increasing training accuracy over time enables the norm to increase. Empirically, we show that the norm grows continuously over pretraining for T5 (Raffel et al., 2019). We show that pretrained T5 approximates a semi-discretized network with saturated activation functions. Such "saturated" networks are known to have a reduced capacity compared to the original network family that can be described in automata-theoretic terms. This suggests saturation is a new characterization of an inductive bias implicit in GD that is of particular interest for NLP. While our experiments focus on transformers, our theoretical analysis extends to other architectures with similar formal properties, such as feedforward ReLU networks.
It's not Greek to mBERT: Inducing Word-Level Translations from Multilingual BERT
Oct 16, 2020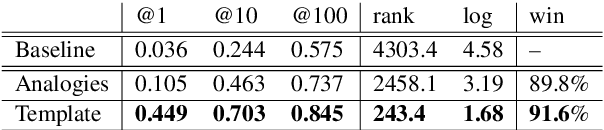
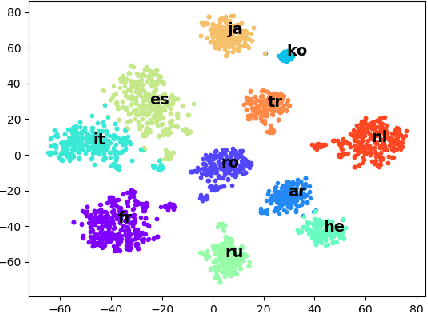
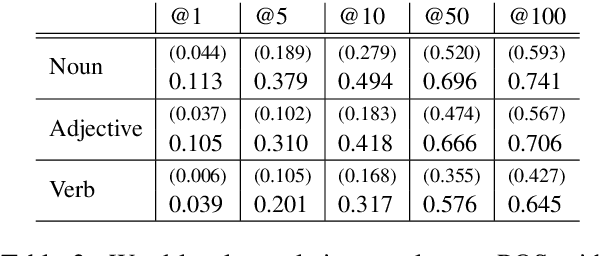
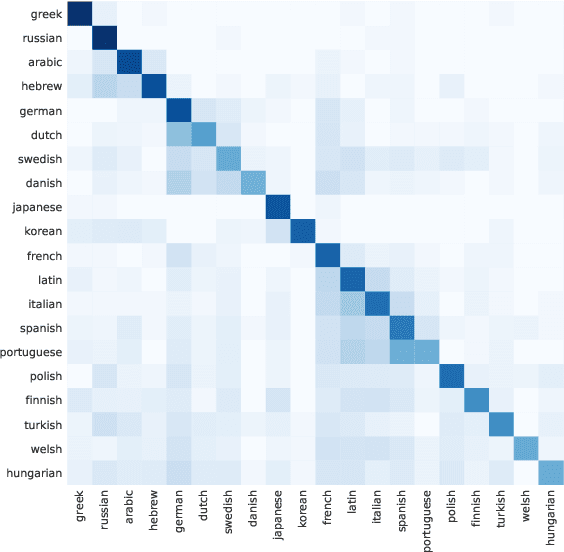
Recent works have demonstrated that multilingual BERT (mBERT) learns rich cross-lingual representations, that allow for transfer across languages. We study the word-level translation information embedded in mBERT and present two simple methods that expose remarkable translation capabilities with no fine-tuning. The results suggest that most of this information is encoded in a non-linear way, while some of it can also be recovered with purely linear tools. As part of our analysis, we test the hypothesis that mBERT learns representations which contain both a language-encoding component and an abstract, cross-lingual component, and explicitly identify an empirical language-identity subspace within mBERT representations.
Formalizing Trust in Artificial Intelligence: Prerequisites, Causes and Goals of Human Trust in AI
Oct 15, 2020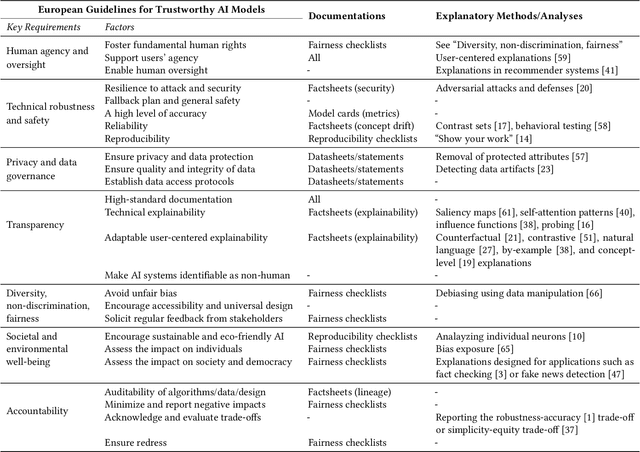
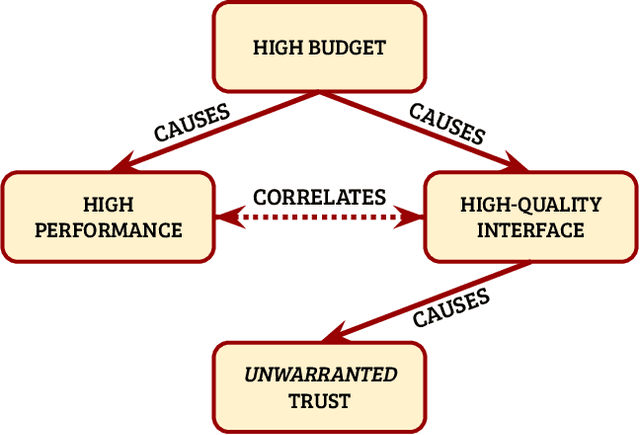
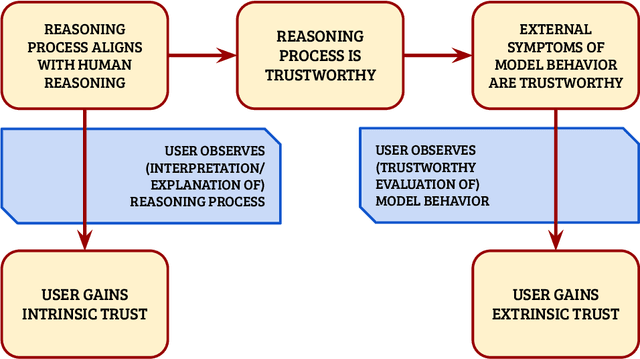
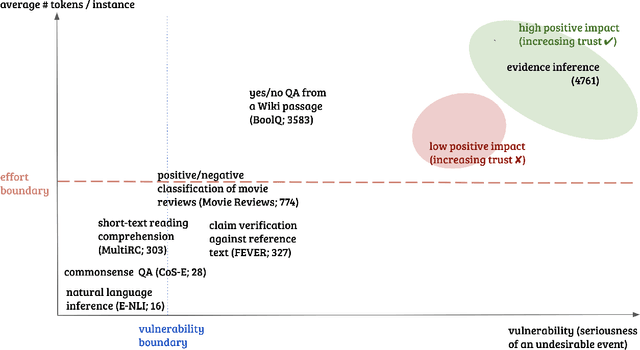
Trust is a central component of the interaction between people and AI, in that 'incorrect' levels of trust may cause misuse, abuse or disuse of the technology. But what, precisely, is the nature of trust in AI? What are the prerequisites and goals of the cognitive mechanism of trust, and how can we cause these prerequisites and goals, or assess whether they are being satisfied in a given interaction? This work aims to answer these questions. We discuss a model of trust inspired by, but not identical to, sociology's interpersonal trust (i.e., trust between people). This model rests on two key properties of the vulnerability of the user and the ability to anticipate the impact of the AI model's decisions. We incorporate a formalization of 'contractual trust', such that trust between a user and an AI is trust that some implicit or explicit contract will hold, and a formalization of 'trustworthiness' (which detaches from the notion of trustworthiness in sociology), and with it concepts of 'warranted' and 'unwarranted' trust. We then present the possible causes of warranted trust as intrinsic reasoning and extrinsic behavior, and discuss how to design trustworthy AI, how to evaluate whether trust has manifested, and whether it is warranted. Finally, we elucidate the connection between trust and XAI using our formalization.