 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple, Interpretable and Stable Method for Detecting Words with Usage Change across Corpora
Dec 28, 2021
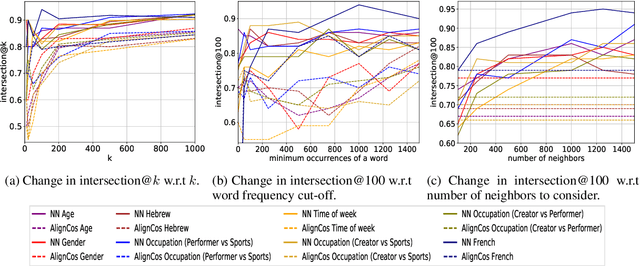
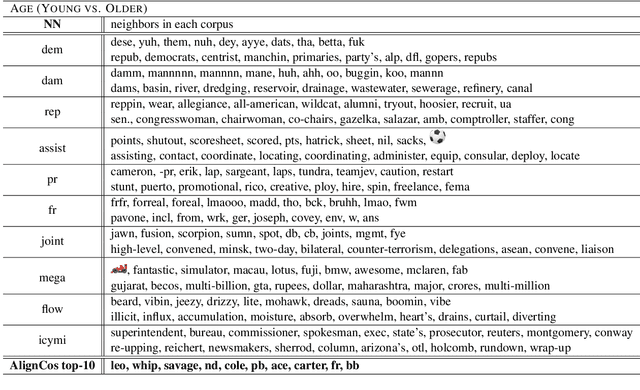
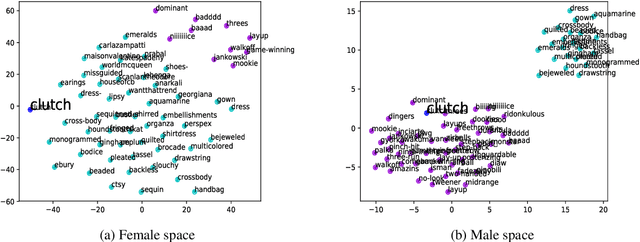
The problem of comparing two bodies of text and searching for words that differ in their usage between them arises often in digital humanities and computational social science. This is commonly approached by training word embeddings on each corpus, aligning the vector spaces, and looking for words whose cosine distance in the aligned space is large. However, these methods often require extensive filtering of the vocabulary to perform well, and - as we show in this work - result in unstable, and hence less reliable, results. We propose an alternative approach that does not use vector space alignment, and instead considers the neighbors of each word. The method is simple, interpretable and stable. We demonstrate its effectiveness in 9 different setups, considering different corpus splitting criteria (age, gender and profession of tweet authors, time of tweet) and different languages (English, French and Hebrew).
Large Scale Substitution-based Word Sense Induction
Oct 14, 2021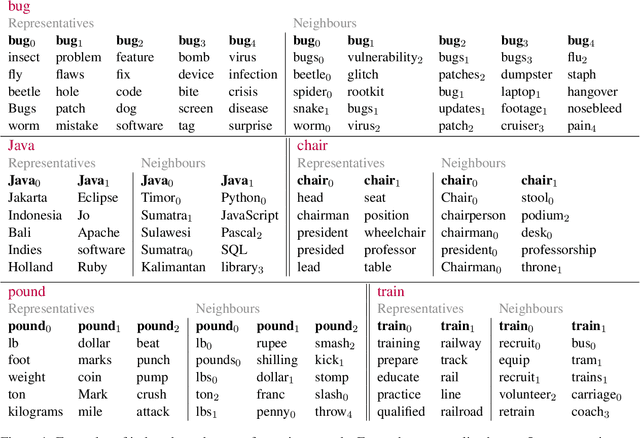


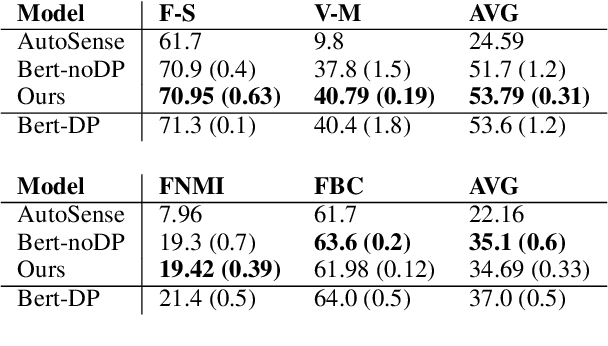
We present a word-sense induction method based on pre-trained masked language models (MLMs), which can cheaply scale to large vocabularies and large corpora. The result is a corpus which is sense-tagged according to a corpus-derived sense inventory and where each sense is associated with indicative words. Evaluation on English Wikipedia that was sense-tagged using our method shows that both the induced senses, and the per-instance sense assignment, are of high quality even compared to WSD methods, such as Babelfy. Furthermore, by training a static word embeddings algorithm on the sense-tagged corpus, we obtain high-quality static senseful embeddings. These outperform existing senseful embeddings techniques on the WiC dataset and on a new outlier detection dataset we developed. The data driven nature of the algorithm allows to induce corpora-specific senses, which may not appear in standard sense inventories, as we demonstrate using a case study on the scientific domain.
Text-based NP Enrichment
Sep 24, 2021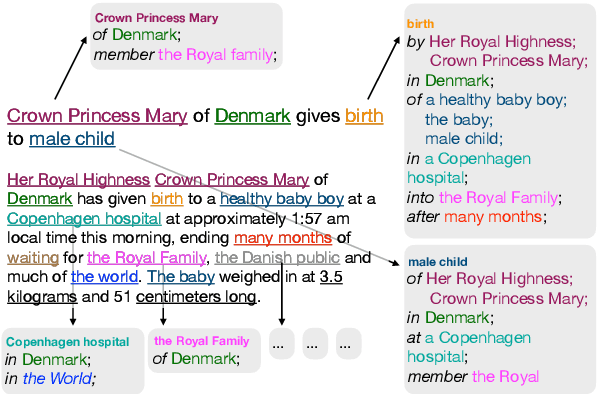
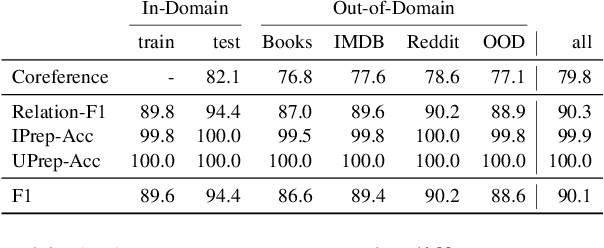

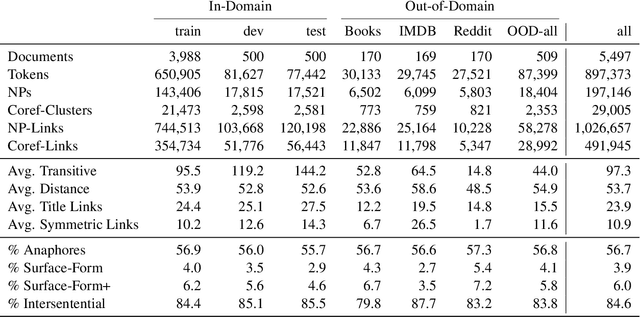
Understanding the relations between entities denoted by NPs in text is a critical part of human-like natural language understanding. However, only a fraction of such relations is covered by NLP tasks and models nowadays. In this work, we establish the task of text-based NP enrichment (TNE), that is, enriching each NP with all the preposition-mediated relations that hold between this and the other NPs in the text. The relations are represented as triplets, each denoting two NPs linked via a preposition. Humans recover such relations seamlessly, while current state-of-the-art models struggle with them due to the implicit nature of the problem. We build the first large-scale dataset for the problem, provide the formal framing and scope of annotation, analyze the data, and report the result of fine-tuned neural language models on the task, demonstrating the challenge it poses to current technology. We created a webpage with the data, data-exploration UI, code, models, and demo to foster further research into this challenging text understanding problem at yanaiela.github.io/TNE/.
Asking It All: Generating Contextualized Questions for any Semantic Role
Sep 10, 2021

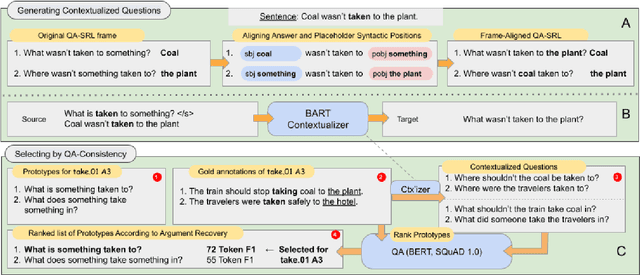
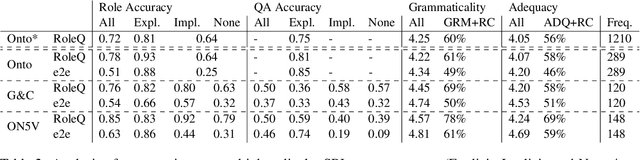
Asking questions about a situation is an inherent step towards understanding it. To this end, we introduce the task of role question generation, which, given a predicate mention and a passage, requires producing a set of questions asking about all possible semantic roles of the predicate. We develop a two-stage model for this task, which first produces a context-independent question prototype for each role and then revises it to be contextually appropriate for the passage. Unlike most existing approaches to question generation, our approach does not require conditioning on existing answers in the text. Instead, we condition on the type of information to inquire about, regardless of whether the answer appears explicitly in the text, could be inferred from it, or should be sought elsewhere. Our evaluation demonstrates that we generate diverse and well-formed questions for a large, broad-coverage ontology of predicates and roles.
On the Power of Saturated Transformers: A View from Circuit Complexity
Jun 30, 2021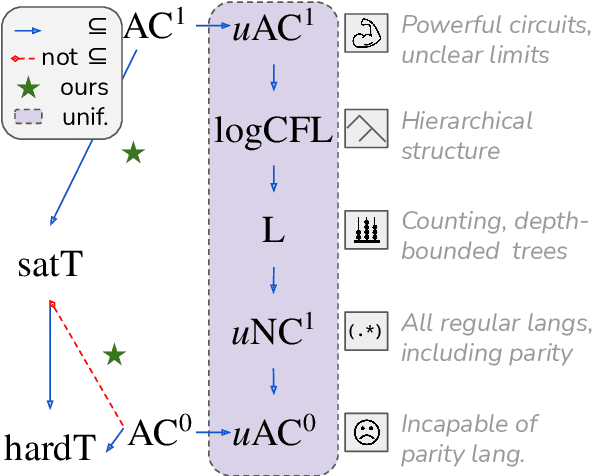

Transformers have become a standard architecture for many NLP problems. This has motivated theoretically analyzing their capabilities as models of language, in order to understand what makes them successful, and what their potential weaknesses might be. Recent work has shown that transformers with hard attention are quite limited in capacity, and in fact can be simulated by constant-depth circuits. However, hard attention is a restrictive assumption, which may complicate the relevance of these results for practical transformers. In this work, we analyze the circuit complexity of transformers with saturated attention: a generalization of hard attention that more closely captures the attention patterns learnable in practical transformers. We show that saturated transformers transcend the limitations of hard-attention transformers. With some minor assumptions, we prove that the number of bits needed to represent a saturated transformer memory vector is $O(\log n)$, which implies saturated transformers can be simulated by log-depth circuits. Thus, the jump from hard to saturated attention can be understood as increasing the transformer's effective circuit depth by a factor of $O(\log n)$.
BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models
Jun 22, 2021
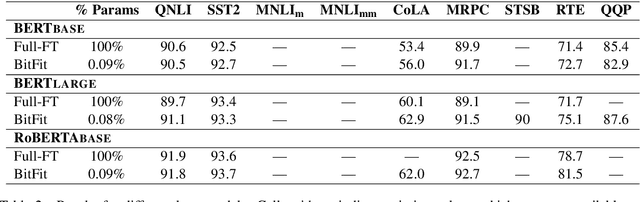

We show that with small-to-medium training data, fine-tuning only the bias terms (or a subset of the bias terms) of pre-trained BERT models is competitive with (and sometimes better than) fine-tuning the entire model. For larger data, bias-only fine-tuning is competitive with other sparse fine-tuning methods. Besides their practical utility, these findings are relevant for the question of understanding the commonly-used process of finetuning: they support the hypothesis that finetuning is mainly about exposing knowledge induced by language-modeling training, rather than learning new task-specific linguistic knowledge.
Thinking Like Transformers
Jun 13, 2021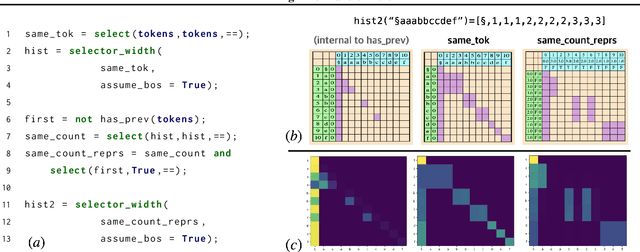
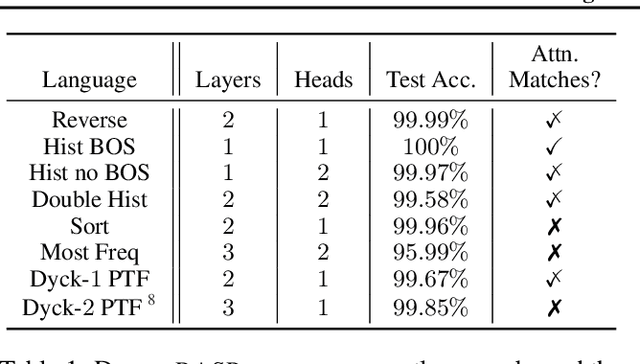
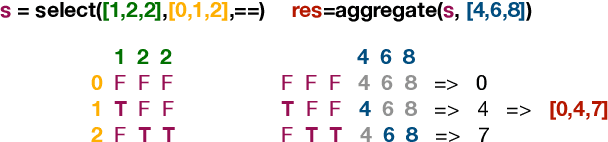
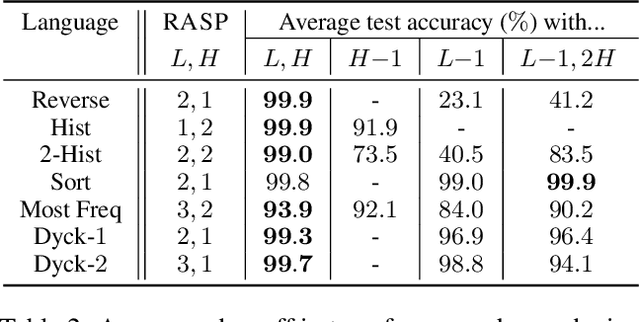
What is the computational model behind a Transformer? Where recurrent neural networks have direct parallels in finite state machines, allowing clear discussion and thought around architecture variants or trained models, Transformers have no such familiar parallel. In this paper we aim to change that, proposing a computational model for the transformer-encoder in the form of a programming language. We map the basic components of a transformer-encoder -- attention and feed-forward computation -- into simple primitives, around which we form a programming language: the Restricted Access Sequence Processing Language (RASP). We show how RASP can be used to program solutions to tasks that could conceivably be learned by a Transformer, and how a Transformer can be trained to mimic a RASP solution. In particular, we provide RASP programs for histograms, sorting, and Dyck-languages. We further use our model to relate their difficulty in terms of the number of required layers and attention heads: analyzing a RASP program implies a maximum number of heads and layers necessary to encode a task in a transformer. Finally, we see how insights gained from our abstraction might be used to explain phenomena seen in recent works.
Neural Extractive Search
Jun 08, 2021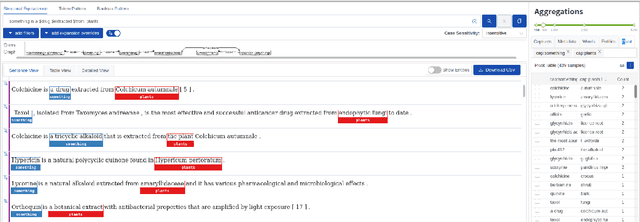
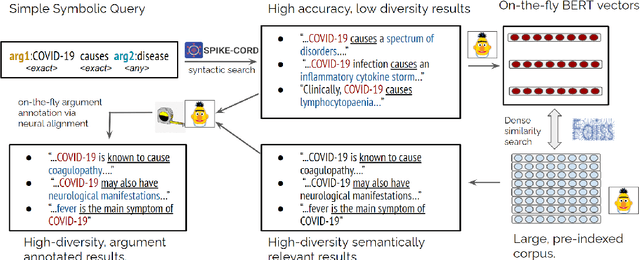

Domain experts often need to extract structured information from large corpora. We advocate for a search paradigm called ``extractive search'', in which a search query is enriched with capture-slots, to allow for such rapid extraction. Such an extractive search system can be built around syntactic structures, resulting in high-precision, low-recall results. We show how the recall can be improved using neural retrieval and alignment. The goals of this paper are to concisely introduce the extractive-search paradigm; and to demonstrate a prototype neural retrieval system for extractive search and its benefits and potential. Our prototype is available at \url{https://spike.neural-sim.apps.allenai.org/} and a video demonstration is available at \url{https://vimeo.com/559586687}.
Counterfactual Interventions Reveal the Causal Effect of Relative Clause Representations on Agreement Prediction
May 19, 2021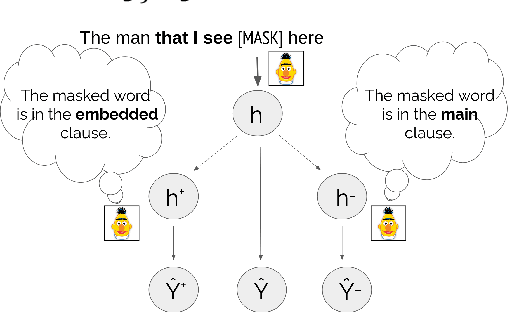

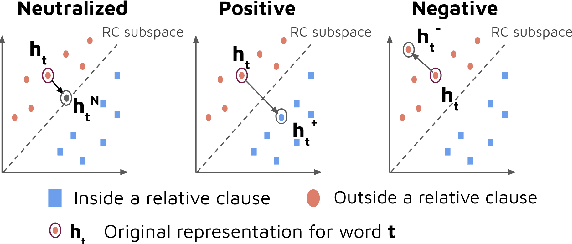
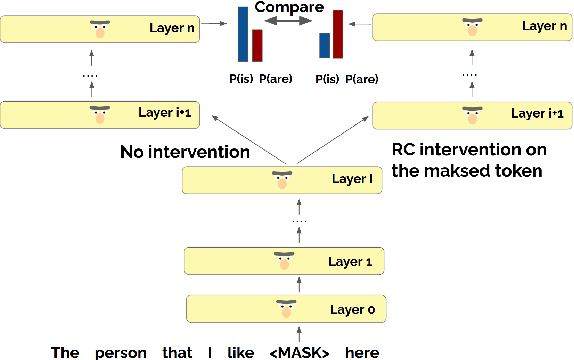
When language models process syntactically complex sentences, do they use abstract syntactic information present in these sentences in a manner that is consistent with the grammar of English, or do they rely solely on a set of heuristics? We propose a method to tackle this question, AlterRep. For any linguistic feature in the sentence, AlterRep allows us to generate counterfactual representations by altering how this feature is encoded, while leaving all other aspects of the original representation intact. Then, by measuring the change in a models' word prediction with these counterfactual representations in different sentences, we can draw causal conclusions about the contexts in which the model uses the linguistic feature (if any). Applying this method to study how BERT uses relative clause (RC) span information, we found that BERT uses information about RC spans during agreement prediction using the linguistically correct strategy. We also found that counterfactual representations generated for a specific RC subtype influenced the number prediction in sentences with other RC subtypes, suggesting that information about RC boundaries was encoded abstractly in BERT's representation.
Data Augmentation for Sign Language Gloss Translation
May 16, 2021

Sign language translation (SLT) is often decomposed into video-to-gloss recognition and gloss-to-text translation, where a gloss is a sequence of transcribed spoken-language words in the order in which they are signed. We focus here on gloss-to-text translation, which we treat as a low-resource neural machine translation (NMT) problem. However, unlike traditional low-resource NMT, gloss-to-text translation differs because gloss-text pairs often have a higher lexical overlap and lower syntactic overlap than pairs of spoken languages. We exploit this lexical overlap and handle syntactic divergence by proposing two rule-based heuristics that generate pseudo-parallel gloss-text pairs from monolingual spoken language text. By pre-training on the thus obtained synthetic data, we improve translation from American Sign Language (ASL) to English and German Sign Language (DGS) to German by up to 3.14 and 2.20 BLEU, respectively.