 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter Norm Growth During Training of Transformers
Paper and Code
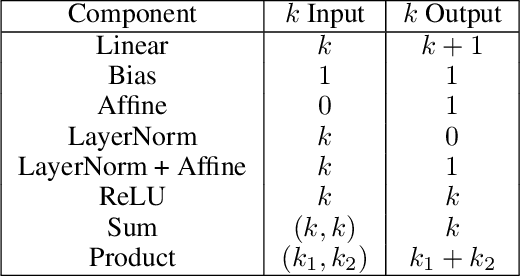
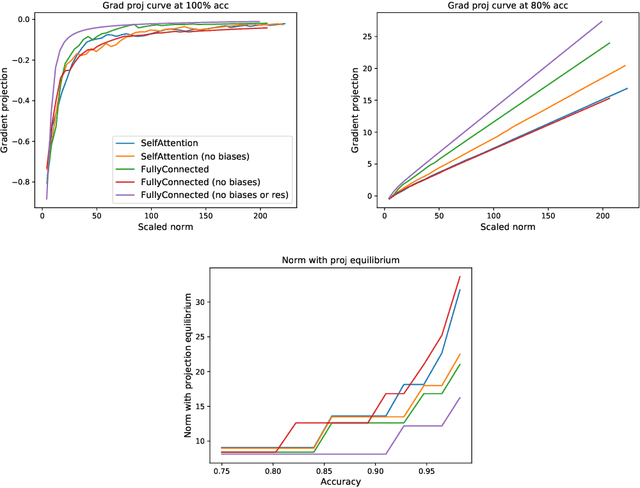
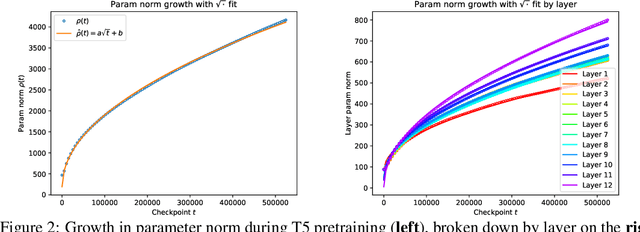
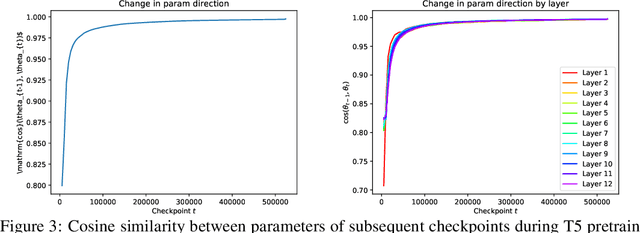
The capacity of neural networks like the widely adopted transformer is known to be very high. Evidence is emerging that they learn successfully due to inductive bias in the training routine, typically some variant of gradient descent (GD). To better understand this bias, we study the tendency of transformer parameters to grow in magnitude during training. We find, both theoretically and empirically, that, in certain contexts, GD increases the parameter $L_2$ norm up to a threshold that itself increases with training-set accuracy. This means increasing training accuracy over time enables the norm to increase. Empirically, we show that the norm grows continuously over pretraining for T5 (Raffel et al., 2019). We show that pretrained T5 approximates a semi-discretized network with saturated activation functions. Such "saturated" networks are known to have a reduced capacity compared to the original network family that can be described in automata-theoretic terms. This suggests saturation is a new characterization of an inductive bias implicit in GD that is of particular interest for NLP. While our experiments focus on transformers, our theoretical analysis extends to other architectures with similar formal properties, such as feedforward ReLU networks.