 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LSTM Learn to Capture Agreement? The Case of Basque
Sep 21, 2018
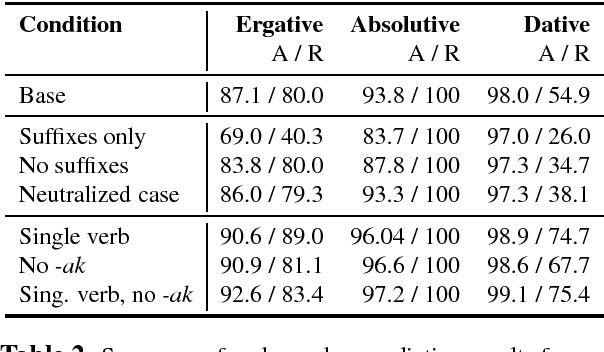

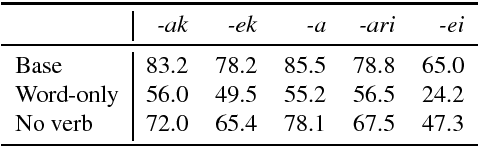
Sequential neural networks models are powerful tools in a variety of Natural Language Processing (NLP) tasks. The sequential nature of these models raises the questions: to what extent can these models implicitly learn hierarchical structures typical to human language, and what kind of grammatical phenomena can they acquire? We focus on the task of agreement prediction in Basque, as a case study for a task that requires implicit understanding of sentence structure and the acquisition of a complex but consistent morphological system. Analyzing experimental results from two syntactic prediction tasks - verb number prediction and suffix recovery - we find that sequential models perform worse on agreement prediction in Basque than one might expect on the basis of a previous agreement prediction work in English. Tentative findings based on diagnostic classifiers suggest the network makes use of local heuristics as a proxy for the hierarchical structure of the sentence. We propose the Basque agreement prediction task as challenging benchmark for models that attempt to learn regularities in human language.
Adversarial Removal of Demographic Attributes from Text Data
Sep 02, 2018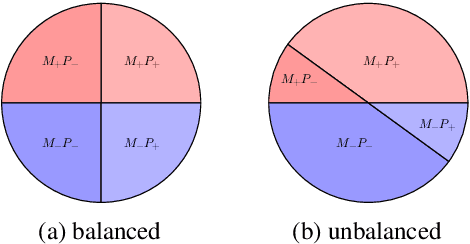
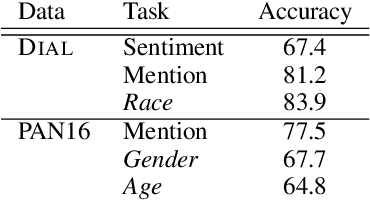

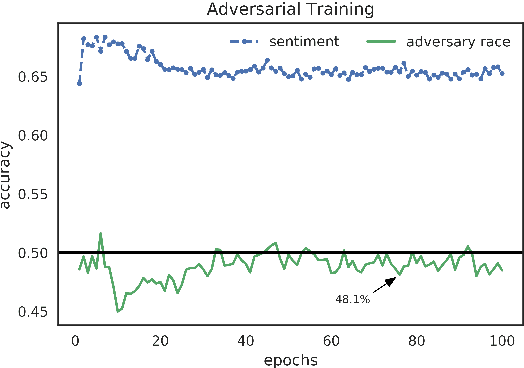
Recent advances in Representation Learning and Adversarial Training seem to succeed in removing unwanted features from the learned representation. We show that demographic information of authors is encoded in -- and can be recovered from -- the intermediate representations learned by text-based neural classifiers. The implication is that decisions of classifiers trained on textual data are not agnostic to -- and likely condition on -- demographic attributes. When attempting to remove such demographic information using adversarial training, we find that while the adversarial component achieves chance-level development-set accuracy during training, a post-hoc classifier, trained on the encoded sentences from the first part, still manages to reach substantially higher classification accuracies on the same data. This behavior is consistent across several tasks, demographic properties and datasets. We explore several techniques to improve the effectiveness of the adversarial component. Our main conclusion is a cautionary one: do not rely on the adversarial training to achieve invariant representation to sensitive features.
Word Sense Induction with Neural biLM and Symmetric Patterns
Aug 30, 2018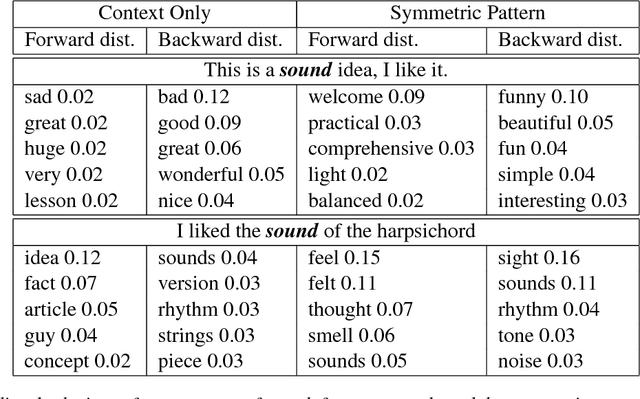
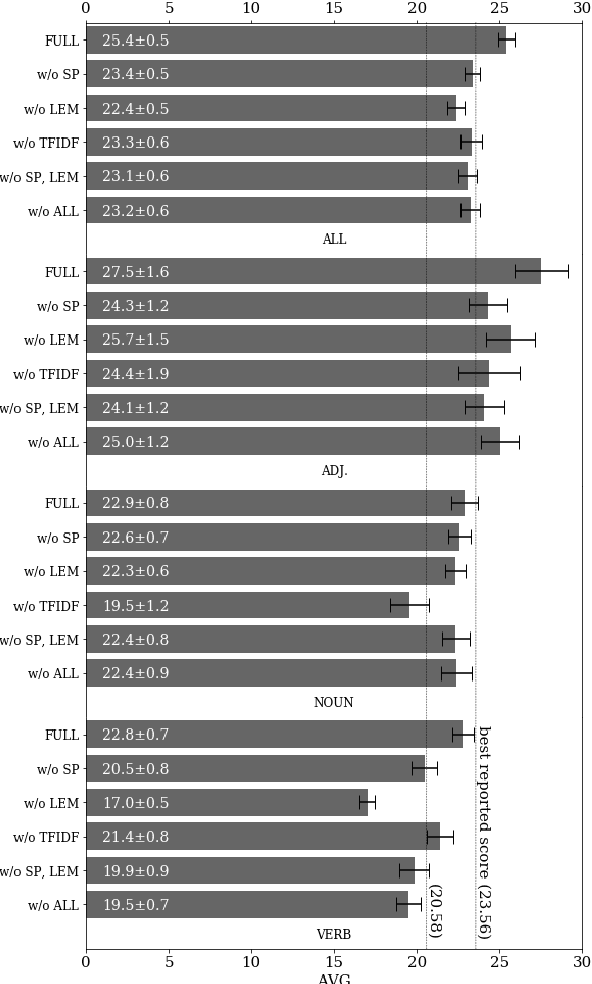
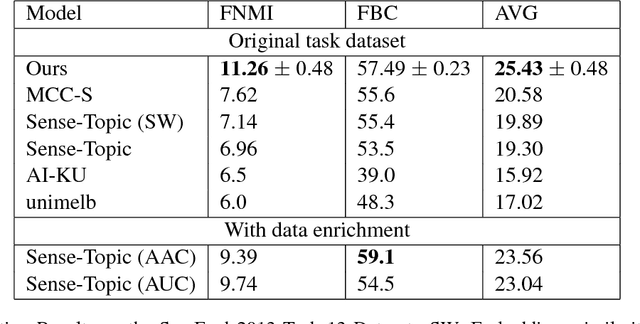
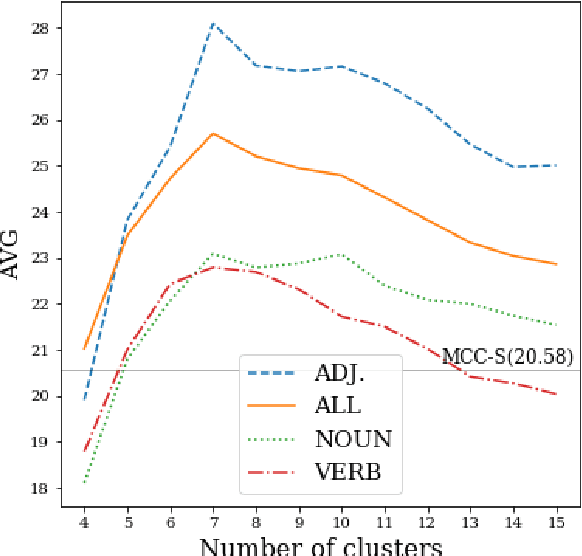
An established method for Word Sense Induction (WSI) uses a language model to predict probable substitutes for target words, and induces senses by clustering these resulting substitute vectors. We replace the ngram-based language model (LM) with a recurrent one. Beyond being more accurate, the use of the recurrent LM allows us to effectively query it in a creative way, using what we call dynamic symmetric patterns. The combination of the RNN-LM and the dynamic symmetric patterns results in strong substitute vectors for WSI, allowing to surpass the current state-of-the-art on the SemEval 2013 WSI shared task by a large margin.
Term Set Expansion based on Multi-Context Term Embeddings: an End-to-end Workflow
Jul 26, 2018

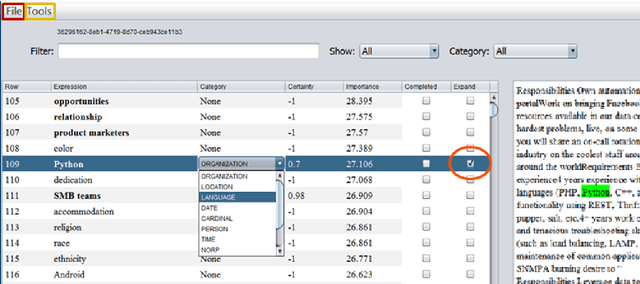
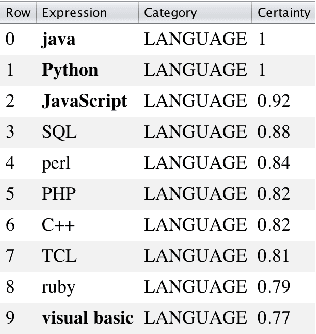
We present SetExpander, a corpus-based system for expanding a seed set of terms into a more complete set of terms that belong to the same semantic class. SetExpander implements an iterative end-to end workflow for term set expansion. It enables users to easily select a seed set of terms, expand it, view the expanded set, validate it, re-expand the validated set and store it, thus simplifying the extraction of domain-specific fine-grained semantic classes. SetExpander has been used for solving real-life use cases including integration in an automated recruitment system and an issues and defects resolution system. A video demo of SetExpander is available at https://drive.google.com/open?id=1e545bB87Autsch36DjnJHmq3HWfSd1Rv (some images were blurred for privacy reasons).
Transfer Learning for Related Reinforcement Learning Tasks via Image-to-Image Translation
Jun 26, 2018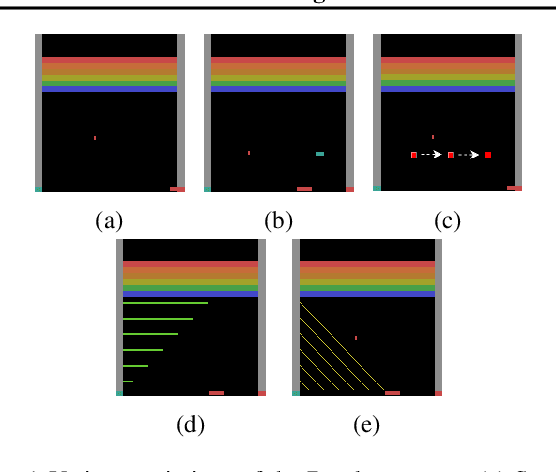
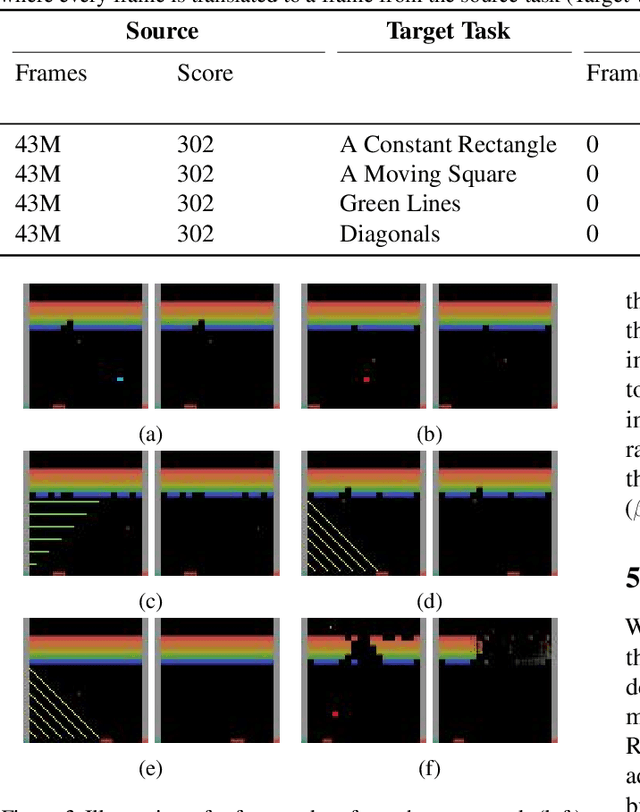
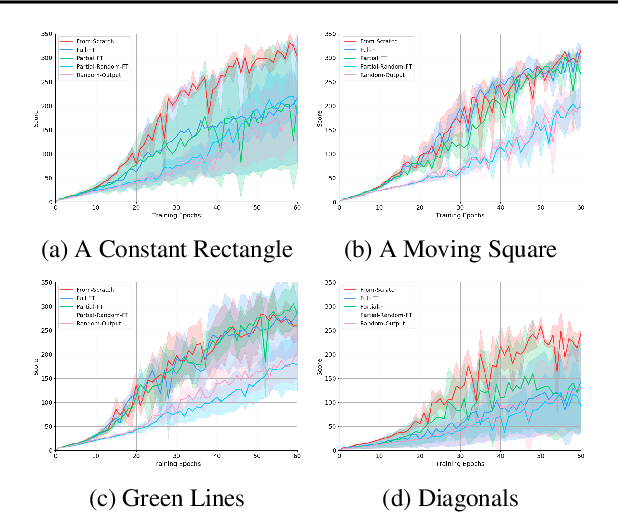
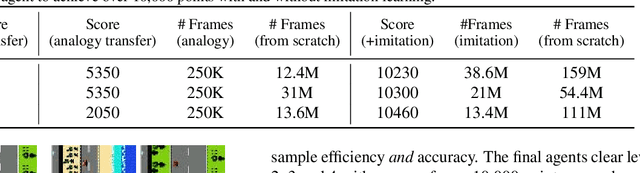
Deep Reinforcement Learning has managed to achieve state-of-the-art results in learning control policies directly from raw pixels. However, despite its remarkable success, it fails to generalize, a fundamental component required in a stable Artificial Intelligence system. Using the Atari game Breakout, we demonstrate the difficulty of a trained agent in adjusting to simple modifications in the raw image, ones that a human could adapt to trivially. In transfer learning, the goal is to use the knowledge gained from the source task to make the training of the target task faster and better. We show that using various forms of fine-tuning, a common method for transfer learning, is not effective for adapting to such small visual changes. In fact, it is often easier to re-train the agent from scratch than to fine-tune a trained agent. We suggest that in some cases transfer learning can be improved by adding a dedicated component whose goal is to learn to visually map between the known domain and the new one. Concretely, we use Generative Adversarial Networks (GANs) to create a mapping function to translate images in the target task to corresponding images in the source task, allowing us to transform between the different tasks. We show that learning this mapping is substantially more efficient than re-training. A visualization of a trained agent playing in a modified condition, with and without the GAN transfer, can be seen in https://youtu.be/e2TwjduPT8g .
Extracting Automata from Recurrent Neural Networks Using Queries and Counterexamples
Jun 24, 2018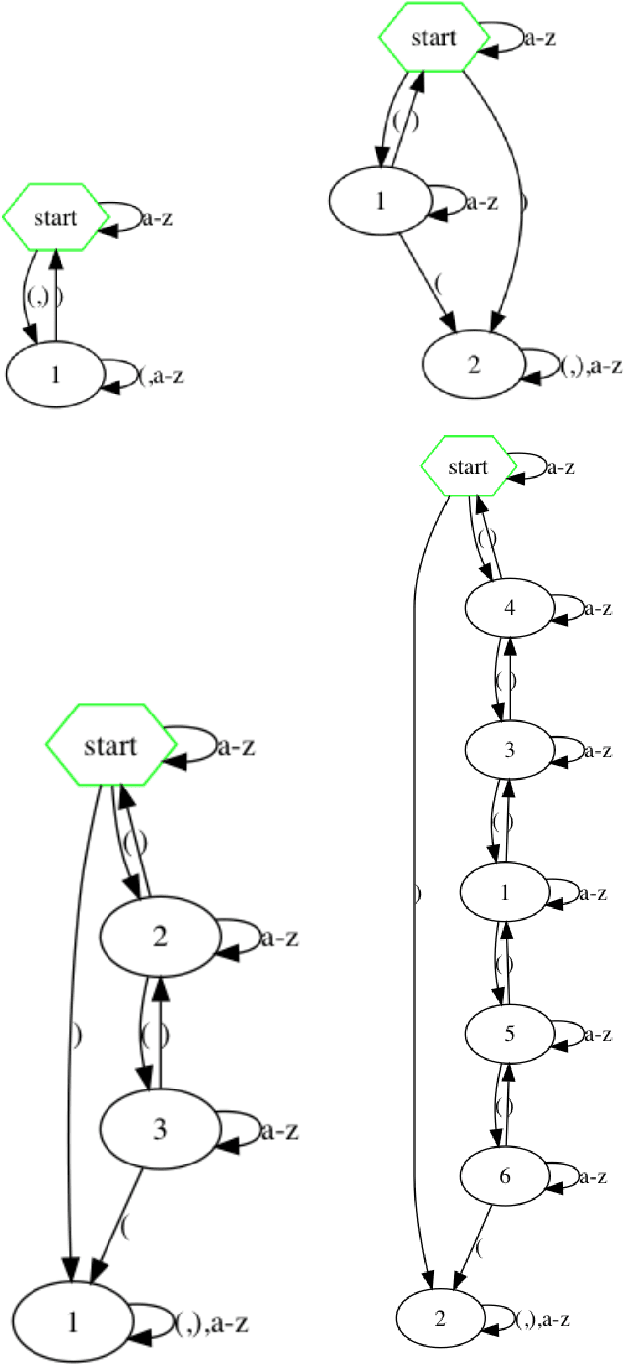


We present a novel algorithm that uses exact learning and abstraction to extract a deterministic finite automaton describing the state dynamics of a given trained RNN. We do this using Angluin's L* algorithm as a learner and the trained RNN as an oracle. Our technique efficiently extracts accurate automata from trained RNNs, even when the state vectors are large and require fine differentiation.
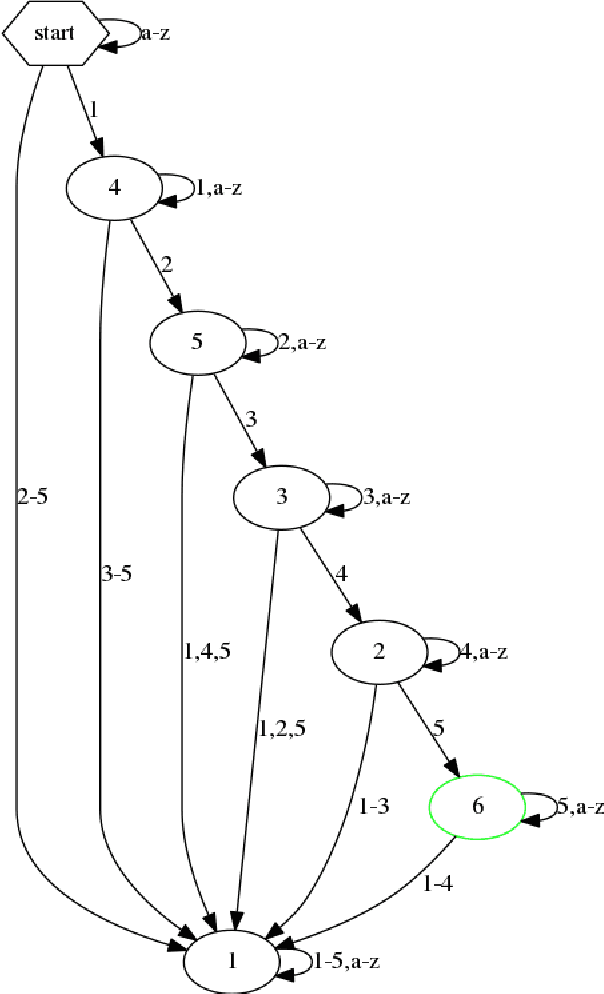
On the Practical Computational Power of Finite Precision RNNs for Language Recognition
May 13, 2018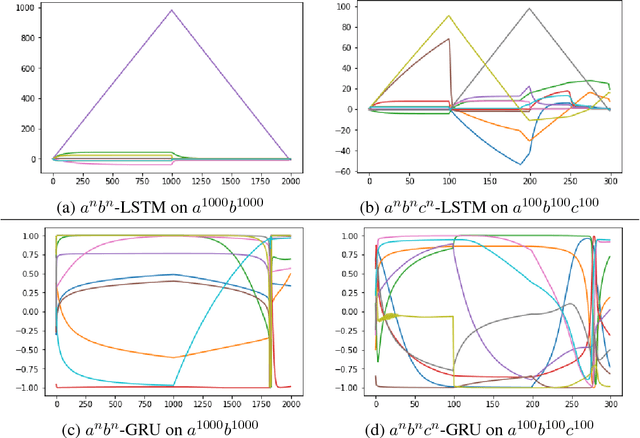
While Recurrent Neural Networks (RNNs) are famously known to be Turing complete, this relies on infinite precision in the states and unbounded computation time. We consider the case of RNNs with finite precision whose computation time is linear in the input length. Under these limitations, we show that different RNN variants have different computational power. In particular, we show that the LSTM and the Elman-RNN with ReLU activation are strictly stronger than the RNN with a squashing activation and the GRU. This is achieved because LSTMs and ReLU-RNNs can easily implement counting behavior. We show empirically that the LSTM does indeed learn to effectively use the counting mechanism.
Breaking NLI Systems with Sentences that Require Simple Lexical Inferences
May 06, 2018
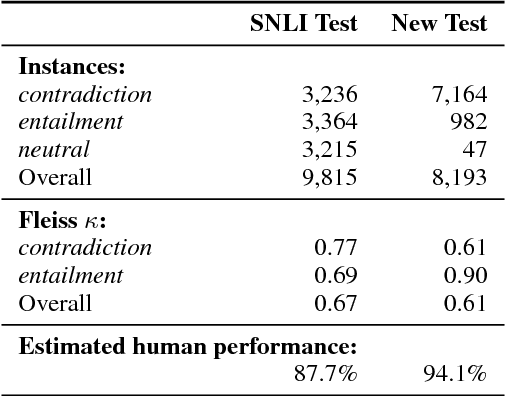
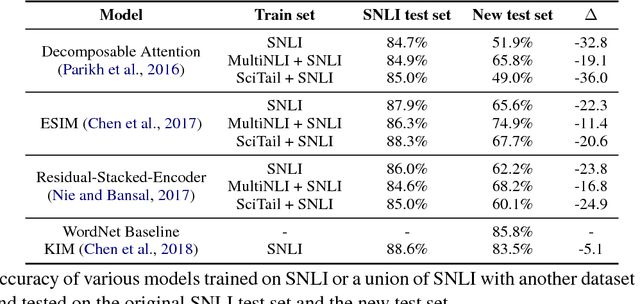
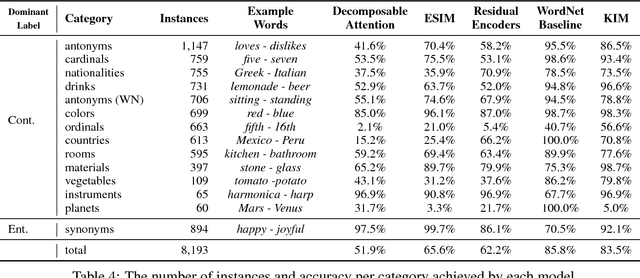
We create a new NLI test set that shows the deficiency of state-of-the-art models in inferences that require lexical and world knowledge. The new examples are simpler than the SNLI test set, containing sentences that differ by at most one word from sentences in the training set. Yet, the performance on the new test set is substantially worse across systems trained on SNLI, demonstrating that these systems are limited in their generalization ability, failing to capture many simple inferences.
Split and Rephrase: Better Evaluation and a Stronger Baseline
May 02, 2018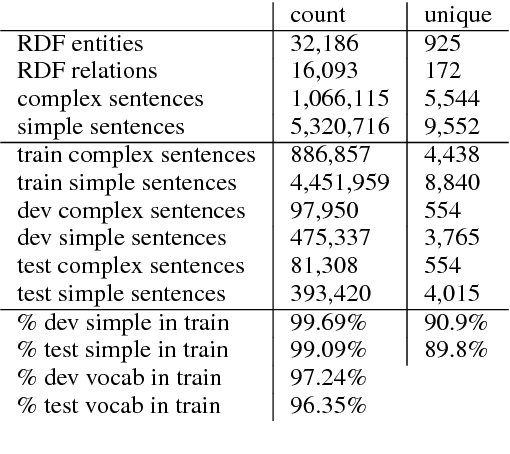
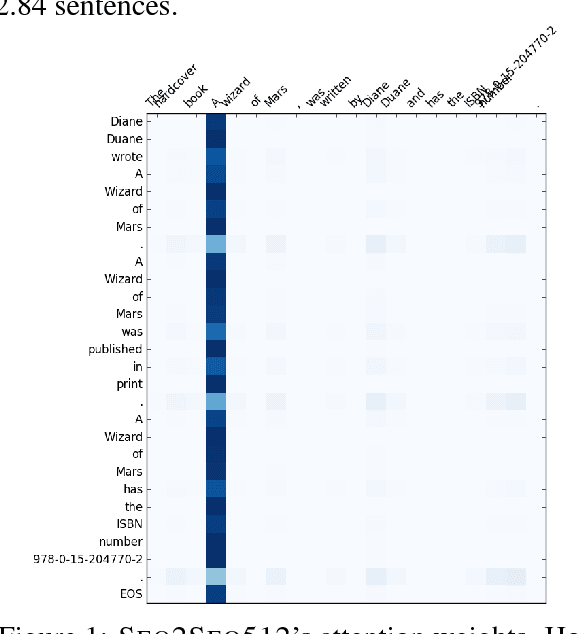
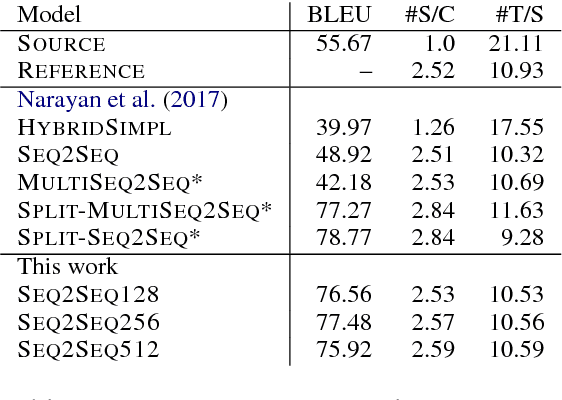
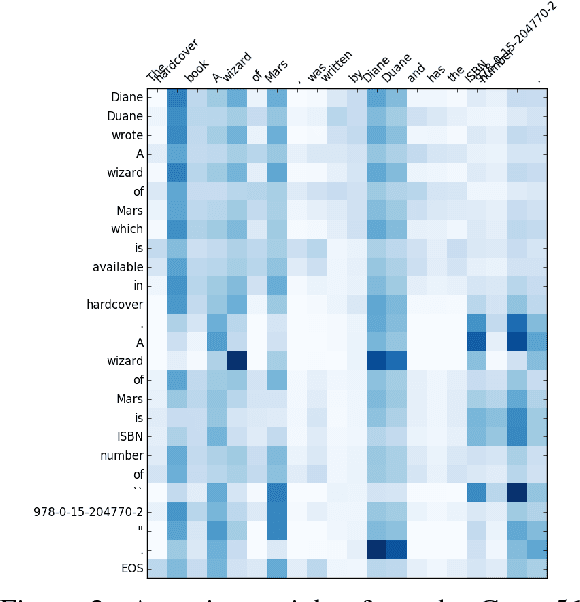
Splitting and rephrasing a complex sentence into several shorter sentences that convey the same meaning is a challenging problem in NLP. We show that while vanilla seq2seq models can reach high scores on the proposed benchmark (Narayan et al., 2017), they suffer from memorization of the training set which contains more than 89% of the unique simple sentences from the validation and test sets. To aid this, we present a new train-development-test data split and neural models augmented with a copy-mechanism, outperforming the best reported baseline by 8.68 BLEU and fostering further progress on the task.
LaVAN: Localized and Visible Adversarial Noise
Mar 01, 2018
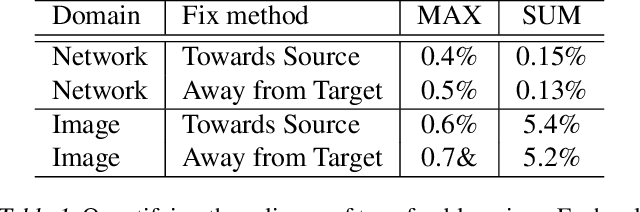


Most works on adversarial examples for deep-learning based image classifiers use noise that, while small, covers the entire image. We explore the case where the noise is allowed to be visible but confined to a small, localized patch of the image, without covering any of the main object(s) in the image. We show that it is possible to generate localized adversarial noises that cover only 2% of the pixels in the image, none of them over the main object, and that are transferable across images and locations, and successfully fool a state-of-the-art Inception v3 model with very high success rates.