 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrITTI: Primitive-based Generation of Controllable and Editable 3D Semantic Scenes
Jun 23, 2025Large-scale 3D semantic scene generation has predominantly relied on voxel-based representations, which are memory-intensive, bound by fixed resolutions, and challenging to edit. In contrast, primitives represent semantic entities using compact, coarse 3D structures that are easy to manipulate and compose, making them an ideal representation for this task. In this paper, we introduce PrITTI, a latent diffusion-based framework that leverages primitives as the main foundational elements for generating compositional, controllable, and editable 3D semantic scene layouts. Our method adopts a hybrid representation, modeling ground surfaces in a rasterized format while encoding objects as vectorized 3D primitives. This decomposition is also reflected in a structured latent representation that enables flexible scene manipulation of ground and object components. To overcome the orientation ambiguities in conventional encoding methods, we introduce a stable Cholesky-based parameterization that jointly encodes object size and orientation. Experiments on the KITTI-360 dataset show that PrITTI outperforms a voxel-based baseline in generation quality, while reducing memory requirements by up to $3\times$. In addition, PrITTI enables direct instance-level manipulation of objects in the scene and supports a range of downstream applications, including scene inpainting, outpainting, and photo-realistic street-view synthesis.
Orientation Matters: Making 3D Generative Models Orientation-Aligned
Jun 10, 2025Humans intuitively perceive object shape and orientation from a single image, guided by strong priors about canonical poses. However, existing 3D generative models often produce misaligned results due to inconsistent training data, limiting their usability in downstream tasks. To address this gap, we introduce the task of orientation-aligned 3D object generation: producing 3D objects from single images with consistent orientations across categories. To facilitate this, we construct Objaverse-OA, a dataset of 14,832 orientation-aligned 3D models spanning 1,008 categories. Leveraging Objaverse-OA, we fine-tune two representative 3D generative models based on multi-view diffusion and 3D variational autoencoder frameworks to produce aligned objects that generalize well to unseen objects across various categories. Experimental results demonstrate the superiority of our method over post-hoc alignment approaches. Furthermore, we showcase downstream applications enabled by our aligned object generation, including zero-shot object orientation estimation via analysis-by-synthesis and efficient arrow-based object rotation manipulation.
GIFStream: 4D Gaussian-based Immersive Video with Feature Stream
May 12, 2025Immersive video offers a 6-Dof-free viewing experience, potentially playing a key role in future video technology. Recently, 4D Gaussian Splatting has gained attention as an effective approach for immersive video due to its high rendering efficiency and quality, though maintaining quality with manageable storage remains challenging. To address this, we introduce GIFStream, a novel 4D Gaussian representation using a canonical space and a deformation field enhanced with time-dependent feature streams. These feature streams enable complex motion modeling and allow efficient compression by leveraging temporal correspondence and motion-aware pruning. Additionally, we incorporate both temporal and spatial compression networks for end-to-end compression. Experimental results show that GIFStream delivers high-quality immersive video at 30 Mbps, with real-time rendering and fast decoding on an RTX 4090. Project page: https://xdimlab.github.io/GIFStream
Vivid4D: Improving 4D Reconstruction from Monocular Video by Video Inpainting
Apr 15, 2025



Reconstructing 4D dynamic scenes from casually captured monocular videos is valuable but highly challenging, as each timestamp is observed from a single viewpoint. We introduce Vivid4D, a novel approach that enhances 4D monocular video synthesis by augmenting observation views - synthesizing multi-view videos from a monocular input. Unlike existing methods that either solely leverage geometric priors for supervision or use generative priors while overlooking geometry, we integrate both. This reformulates view augmentation as a video inpainting task, where observed views are warped into new viewpoints based on monocular depth priors. To achieve this, we train a video inpainting model on unposed web videos with synthetically generated masks that mimic warping occlusions, ensuring spatially and temporally consistent completion of missing regions. To further mitigate inaccuracies in monocular depth priors, we introduce an iterative view augmentation strategy and a robust reconstruction loss. Experiments demonstrate that our method effectively improves monocular 4D scene reconstruction and completion.
UnIRe: Unsupervised Instance Decomposition for Dynamic Urban Scene Reconstruction
Apr 01, 2025Reconstructing and decomposing dynamic urban scenes is crucial for autonomous driving, urban planning, and scene editing. However, existing methods fail to perform instance-aware decomposition without manual annotations, which is crucial for instance-level scene editing.We propose UnIRe, a 3D Gaussian Splatting (3DGS) based approach that decomposes a scene into a static background and individual dynamic instances using only RGB images and LiDAR point clouds. At its core, we introduce 4D superpoints, a novel representation that clusters multi-frame LiDAR points in 4D space, enabling unsupervised instance separation based on spatiotemporal correlations. These 4D superpoints serve as the foundation for our decomposed 4D initialization, i.e., providing spatial and temporal initialization to train a dynamic 3DGS for arbitrary dynamic classes without requiring bounding boxes or object templates.Furthermore, we introduce a smoothness regularization strategy in both 2D and 3D space, further improving the temporal stability.Experiments on benchmark datasets show that our method outperforms existing methods in decomposed dynamic scene reconstruction while enabling accurate and flexible instance-level editing, making it a practical solution for real-world applications.
EVolSplat: Efficient Volume-based Gaussian Splatting for Urban View Synthesis
Mar 26, 2025



Novel view synthesis of urban scenes is essential for autonomous driving-related applications.Existing NeRF and 3DGS-based methods show promising results in achieving photorealistic renderings but require slow, per-scene optimization. We introduce EVolSplat, an efficient 3D Gaussian Splatting model for urban scenes that works in a feed-forward manner. Unlike existing feed-forward, pixel-aligned 3DGS methods, which often suffer from issues like multi-view inconsistencies and duplicated content, our approach predicts 3D Gaussians across multiple frames within a unified volume using a 3D convolutional network. This is achieved by initializing 3D Gaussians with noisy depth predictions, and then refining their geometric properties in 3D space and predicting color based on 2D textures. Our model also handles distant views and the sky with a flexible hemisphere background model. This enables us to perform fast, feed-forward reconstruction while achieving real-time rendering. Experimental evaluations on the KITTI-360 and Waymo datasets show that our method achieves state-of-the-art quality compared to existing feed-forward 3DGS- and NeRF-based methods.
Leverage Cross-Attention for End-to-End Open-Vocabulary Panoptic Reconstruction
Jan 02, 2025



Open-vocabulary panoptic reconstruction offers comprehensive scene understanding, enabling advances in embodied robotics and photorealistic simulation. In this paper, we propose PanopticRecon++, an end-to-end method that formulates panoptic reconstruction through a novel cross-attention perspective. This perspective models the relationship between 3D instances (as queries) and the scene's 3D embedding field (as keys) through their attention map. Unlike existing methods that separate the optimization of queries and keys or overlook spatial proximity, PanopticRecon++ introduces learnable 3D Gaussians as instance queries. This formulation injects 3D spatial priors to preserve proximity while maintaining end-to-end optimizability. Moreover, this query formulation facilitates the alignment of 2D open-vocabulary instance IDs across frames by leveraging optimal linear assignment with instance masks rendered from the queries. Additionally, we ensure semantic-instance segmentation consistency by fusing query-based instance segmentation probabilities with semantic probabilities in a novel panoptic head supervised by a panoptic loss. During training, the number of instance query tokens dynamically adapts to match the number of objects. PanopticRecon++ shows competitive performance in terms of 3D and 2D segmentation and reconstruction performance on both simulation and real-world datasets, and demonstrates a user case as a robot simulator. Our project website is at: https://yuxuan1206.github.io/panopticrecon_pp/
Prometheus: 3D-Aware Latent Diffusion Models for Feed-Forward Text-to-3D Scene Generation
Dec 30, 2024In this work, we introduce Prometheus, a 3D-aware latent diffusion model for text-to-3D generation at both object and scene levels in seconds. We formulate 3D scene generation as multi-view, feed-forward, pixel-aligned 3D Gaussian generation within the latent diffusion paradigm. To ensure generalizability, we build our model upon pre-trained text-to-image generation model with only minimal adjustments, and further train it using a large number of images from both single-view and multi-view datasets. Furthermore, we introduce an RGB-D latent space into 3D Gaussian generation to disentangle appearance and geometry information, enabling efficient feed-forward generation of 3D Gaussians with better fidelity and geometry. Extensive experimental results demonstrate the effectiveness of our method in both feed-forward 3D Gaussian reconstruction and text-to-3D generation. Project page: https://freemty.github.io/project-prometheus/
HUGSIM: A Real-Time, Photo-Realistic and Closed-Loop Simulator for Autonomous Driving
Dec 02, 2024

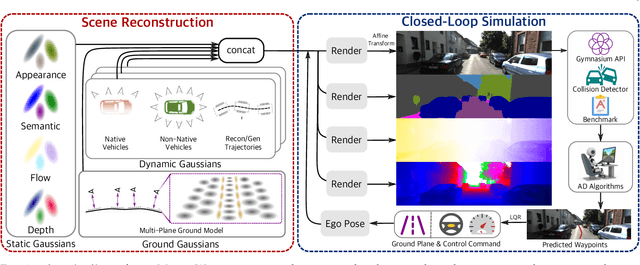
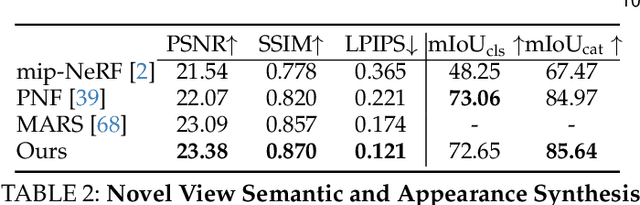
In the past few decades, autonomous driving algorithms have made significant progress in perception, planning, and control. However, evaluating individual components does not fully reflect the performance of entire systems, highlighting the need for more holistic assessment methods. This motivates the development of HUGSIM, a closed-loop, photo-realistic, and real-time simulator for evaluating autonomous driving algorithms. We achieve this by lifting captured 2D RGB images into the 3D space via 3D Gaussian Splatting, improving the rendering quality for closed-loop scenarios, and building the closed-loop environment. In terms of rendering, We tackle challenges of novel view synthesis in closed-loop scenarios, including viewpoint extrapolation and 360-degree vehicle rendering. Beyond novel view synthesis, HUGSIM further enables the full closed simulation loop, dynamically updating the ego and actor states and observations based on control commands. Moreover, HUGSIM offers a comprehensive benchmark across more than 70 sequences from KITTI-360, Waymo, nuScenes, and PandaSet, along with over 400 varying scenarios, providing a fair and realistic evaluation platform for existing autonomous driving algorithms. HUGSIM not only serves as an intuitive evaluation benchmark but also unlocks the potential for fine-tuning autonomous driving algorithms in a photorealistic closed-loop setting.
UrbanCAD: Towards Highly Controllable and Photorealistic 3D Vehicles for Urban Scene Simulation
Nov 28, 2024Photorealistic 3D vehicle models with high controllability are essential for autonomous driving simulation and data augmentation. While handcrafted CAD models provide flexible controllability, free CAD libraries often lack the high-quality materials necessary for photorealistic rendering. Conversely, reconstructed 3D models offer high-fidelity rendering but lack controllability. In this work, we introduce UrbanCAD, a framework that pushes the frontier of the photorealism-controllability trade-off by generating highly controllable and photorealistic 3D vehicle digital twins from a single urban image and a collection of free 3D CAD models and handcrafted materials. These digital twins enable realistic 360-degree rendering, vehicle insertion, material transfer, relighting, and component manipulation such as opening doors and rolling down windows, supporting the construction of long-tail scenarios. To achieve this, we propose a novel pipeline that operates in a retrieval-optimization manner, adapting to observational data while preserving flexible controllability and fine-grained handcrafted details. Furthermore, given multi-view background perspective and fisheye images, we approximate environment lighting using fisheye images and reconstruct the background with 3DGS, enabling the photorealistic insertion of optimized CAD models into rendered novel view backgrounds. Experimental results demonstrate that UrbanCAD outperforms baselines based on reconstruction and retrieval in terms of photorealism. Additionally, we show that various perception models maintain their accuracy when evaluated on UrbanCAD with in-distribution configurations but degrade when applied to realistic out-of-distribution data generated by our method. This suggests that UrbanCAD is a significant advancement in creating photorealistic, safety-critical driving scenarios for downstream applications.