 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Review for MRF and CRF Approaches in Pathology Image Analysis
Sep 29, 2020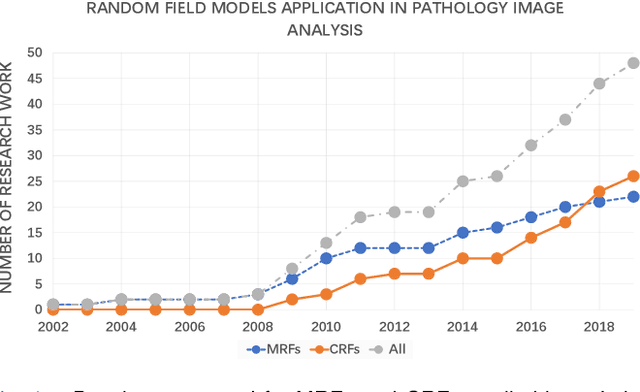
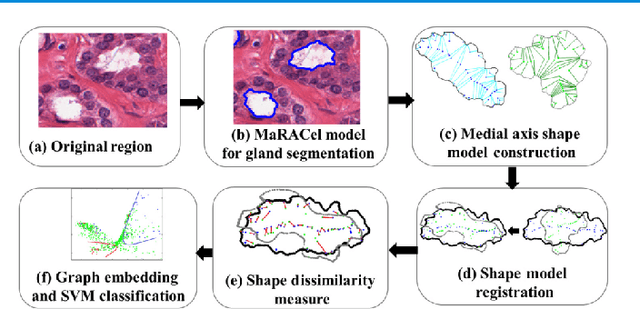
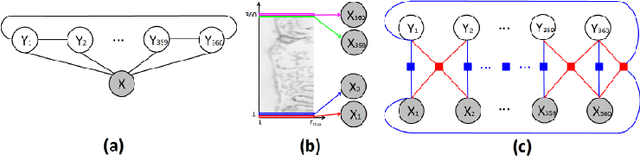

Pathology image analysis is an essential procedure for clinical diagnosis of many diseases. To boost the accuracy and objectivity of detection, nowadays, an increasing number of computer-aided diagnosis (CAD) system is proposed. Among these methods, random field models play an indispensable role in improving the analysis performance. In this review, we present a comprehensive overview of pathology image analysis based on the markov random fields (MRFs) and conditional random fields (CRFs), which are two popular random field models. Firstly, we introduce the background of two random fields and pathology images. Secondly, we summarize the basic mathematical knowledge of MRFs and CRFs from modelling to optimization. Then, a thorough review of the recent research on the MRFs and CRFs of pathology images analysis is presented. Finally, we investigate the popular methodologies in the related works and discuss the method migration among CAD field.
Global Data Science Project for COVID-19 Summary Report
Jun 10, 2020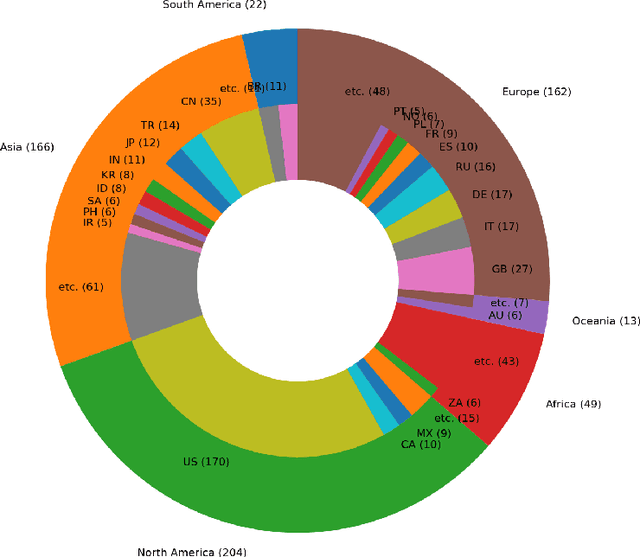
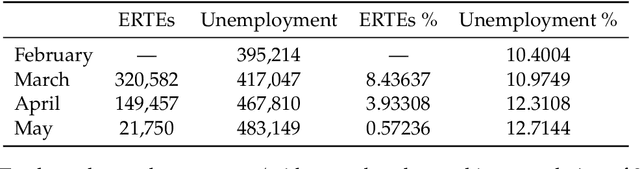
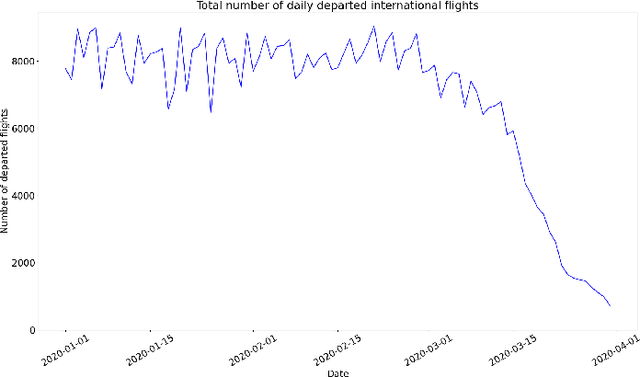
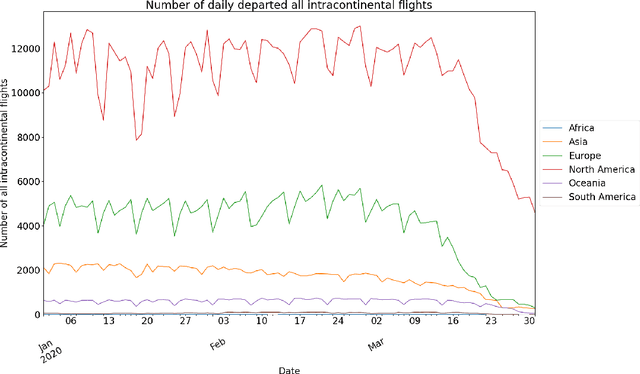
This paper aims at providing the summary of the Global Data Science Project (GDSC) for COVID-19. as on May 31 2020. COVID-19 has largely impacted on our societies through both direct and indirect effects transmitted by the policy measures to counter the spread of viruses. We quantitatively analysed the multifaceted impacts of the COVID-19 pandemic on our societies including people's mobility, health, and social behaviour changes. People's mobility has changed significantly due to the implementation of travel restriction and quarantine measurements. Indeed, the physical distance has widened at international (cross-border), national and regional level. At international level, due to the travel restrictions, the number of international flights has plunged overall at around 88 percent during March. In particular, the number of flights connecting Europe dropped drastically in mid of March after the United States announced travel restrictions to Europe and the EU and participating countries agreed to close borders, at 84 percent decline compared to March 10th. Similarly, we examined the impacts of quarantine measures in the major city: Tokyo (Japan), New York City (the United States), and Barcelona (Spain). Within all three cities, we found the significant decline in traffic volume. We also identified the increased concern for mental health through the analysis of posts on social networking services such as Twitter and Instagram. Notably, in the beginning of April 2020, the number of post with #depression on Instagram doubled, which might reflect the rise in mental health awareness among Instagram users. Besides, we identified the changes in a wide range of people's social behaviors, as well as economic impacts through the analysis of Instagram data and primary survey data.
What are We Depressed about When We Talk about COVID19: Mental Health Analysis on Tweets Using Natural Language Processing
Apr 29, 2020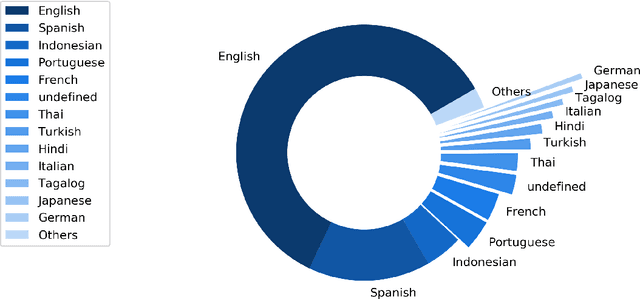
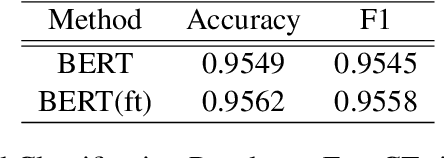

The outbreak of coronavirus disease 2019 (COVID-19) recently has affected human life to a great extent. Besides direct physical and economic threats, the pandemic also indirectly impact people's mental health conditions, which can be overwhelming but difficult to measure. The problem may come from various reasons such as unemployment status, stay-at-home policy, fear for the virus, and so forth. In this work, we focus on applying natural language processing (NLP) techniques to analyze tweets in terms of mental health. We trained deep models that classify each tweet into the following emotions: anger, anticipation, disgust, fear, joy, sadness, surprise and trust. We build the EmoCT (Emotion-Covid19-Tweet) dataset for the training purpose by manually labeling 1,000 English tweets. Furthermore, we propose and compare two methods to find out the reasons that are causing sadness and fear.
Hard-Aware Fashion Attribute Classification
Jul 25, 2019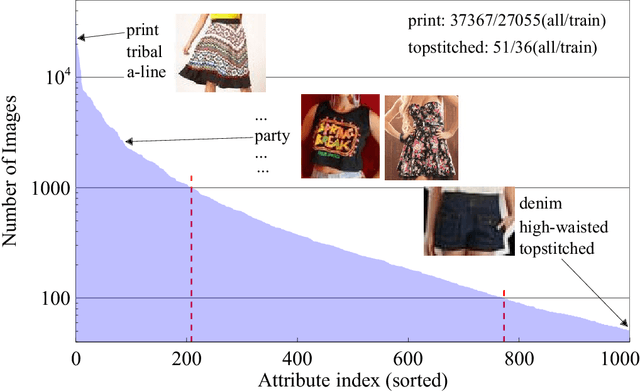
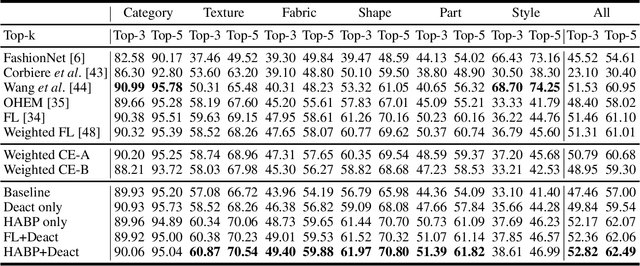
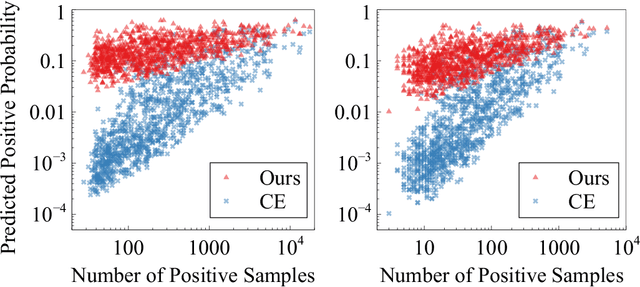
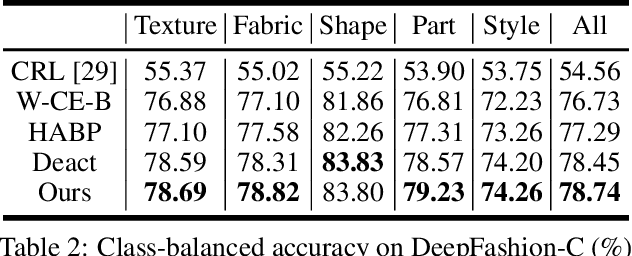
Fashion attribute classification is of great importance to many high-level tasks such as fashion item search, fashion trend analysis, fashion recommendation, etc. The task is challenging due to the extremely imbalanced data distribution, particularly the attributes with only a few positive samples. In this paper, we introduce a hard-aware pipeline to make full use of "hard" samples/attributes. We first propose Hard-Aware BackPropagation (HABP) to efficiently and adaptively focus on training "hard" data. Then for the identified hard labels, we propose to synthesize more complementary samples for training. To stabilize training, we extend semi-supervised GAN by directly deactivating outputs for synthetic complementary samples (Deact). In general, our method is more effective in addressing "hard" cases. HABP weights more on "hard" samples. For "hard" attributes with insufficient training data, Deact brings more stable synthetic samples for training and further improve the performance. Our method is verified on large scale fashion dataset, outperforming other state-of-the-art without any additional supervisions.
Spatial-Aware Non-Local Attention for Fashion Landmark Detection
Mar 11, 2019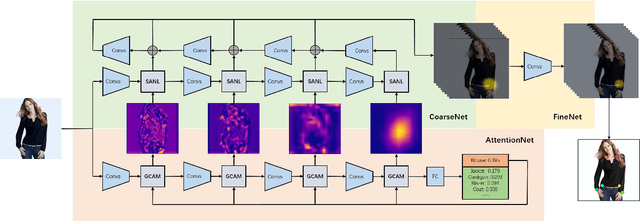
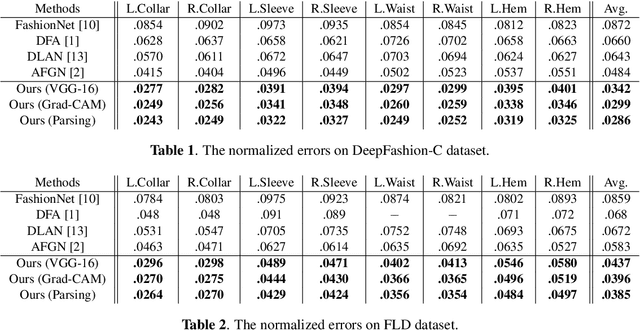
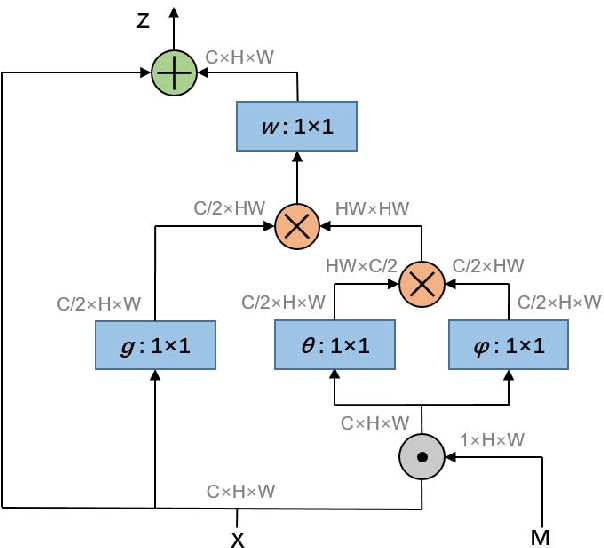

Fashion landmark detection is a challenging task even using the current deep learning techniques, due to the large variation and non-rigid deformation of clothes. In order to tackle these problems, we propose Spatial-Aware Non-Local (SANL) block, an attentive module in deep neural network which can utilize spatial information while capturing global dependency. Actually, the SANL block is constructed from the non-local block in the residual manner which can learn the spatial related representation by taking a spatial attention map from Grad-CAM. We then establish our fashion landmark detection framework on feature pyramid network, equipped with four SANL blocks in the backbone. It is demonstrated by the experimental results on two large-scale fashion datasets that our proposed fashion landmark detection approach with the SANL blocks outperforms the current state-of-the-art methods considerably. Some supplementary experiments on fine-grained image classification also show the effectiveness of the proposed SANL block.
AI Challenger : A Large-scale Dataset for Going Deeper in Image Understanding
Nov 17, 2017
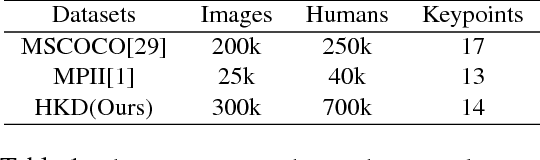
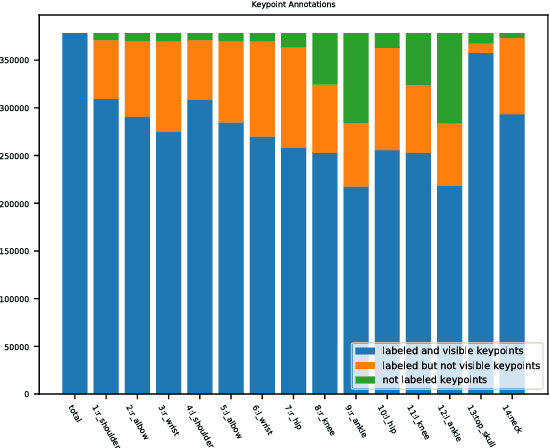
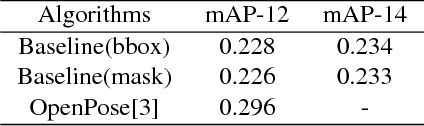
Significant progress has been achieved in Computer Vision by leveraging large-scale image datasets. However, large-scale datasets for complex Computer Vision tasks beyond classification are still limited. This paper proposed a large-scale dataset named AIC (AI Challenger) with three sub-datasets, human keypoint detection (HKD), large-scale attribute dataset (LAD) and image Chinese captioning (ICC). In this dataset, we annotate class labels (LAD), keypoint coordinate (HKD), bounding box (HKD and LAD), attribute (LAD) and caption (ICC). These rich annotations bridge the semantic gap between low-level images and high-level concepts. The proposed dataset is an effective benchmark to evaluate and improve different computational methods. In addition, for related tasks, others can also use our dataset as a new resource to pre-train their models.