 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet's Put Ourselves in Sally's Shoes: Shoes-of-Others Prefixing Improves Theory of Mind in Large Language Models
Jun 06, 2025Recent studies have shown that Theory of Mind (ToM) in large language models (LLMs) has not reached human-level performance yet. Since fine-tuning LLMs on ToM datasets often degrades their generalization, several inference-time methods have been proposed to enhance ToM in LLMs. However, existing inference-time methods for ToM are specialized for inferring beliefs from contexts involving changes in the world state. In this study, we present a new inference-time method for ToM, Shoes-of-Others (SoO) prefixing, which makes fewer assumptions about contexts and is applicable to broader scenarios. SoO prefixing simply specifies the beginning of LLM outputs with ``Let's put ourselves in A's shoes.'', where A denotes the target character's name. We evaluate SoO prefixing on two benchmarks that assess ToM in conversational and narrative contexts without changes in the world state and find that it consistently improves ToM across five categories of mental states. Our analysis suggests that SoO prefixing elicits faithful thoughts, thereby improving the ToM performance.
Stabilizing Reasoning in Medical LLMs with Continued Pretraining and Reasoning Preference Optimization
Apr 25, 2025



Large Language Models (LLMs) show potential in medicine, yet clinical adoption is hindered by concerns over factual accuracy, language-specific limitations (e.g., Japanese), and critically, their reliability when required to generate reasoning explanations -- a prerequisite for trust. This paper introduces Preferred-MedLLM-Qwen-72B, a 72B-parameter model optimized for the Japanese medical domain to achieve both high accuracy and stable reasoning. We employ a two-stage fine-tuning process on the Qwen2.5-72B base model: first, Continued Pretraining (CPT) on a comprehensive Japanese medical corpus instills deep domain knowledge. Second, Reasoning Preference Optimization (RPO), a preference-based method, enhances the generation of reliable reasoning pathways while preserving high answer accuracy. Evaluations on the Japanese Medical Licensing Exam benchmark (IgakuQA) show Preferred-MedLLM-Qwen-72B achieves state-of-the-art performance (0.868 accuracy), surpassing strong proprietary models like GPT-4o (0.866). Crucially, unlike baseline or CPT-only models which exhibit significant accuracy degradation (up to 11.5\% and 3.8\% respectively on IgakuQA) when prompted for explanations, our model maintains its high accuracy (0.868) under such conditions. This highlights RPO's effectiveness in stabilizing reasoning generation. This work underscores the importance of optimizing for reliable explanations alongside accuracy. We release the Preferred-MedLLM-Qwen-72B model weights to foster research into trustworthy LLMs for specialized, high-stakes applications.
ToMATO: Verbalizing the Mental States of Role-Playing LLMs for Benchmarking Theory of Mind
Jan 15, 2025



Existing Theory of Mind (ToM) benchmarks diverge from real-world scenarios in three aspects: 1) they assess a limited range of mental states such as beliefs, 2) false beliefs are not comprehensively explored, and 3) the diverse personality traits of characters are overlooked. To address these challenges, we introduce ToMATO, a new ToM benchmark formulated as multiple-choice QA over conversations. ToMATO is generated via LLM-LLM conversations featuring information asymmetry. By employing a prompting method that requires role-playing LLMs to verbalize their thoughts before each utterance, we capture both first- and second-order mental states across five categories: belief, intention, desire, emotion, and knowledge. These verbalized thoughts serve as answers to questions designed to assess the mental states of characters within conversations. Furthermore, the information asymmetry introduced by hiding thoughts from others induces the generation of false beliefs about various mental states. Assigning distinct personality traits to LLMs further diversifies both utterances and thoughts. ToMATO consists of 5.4k questions, 753 conversations, and 15 personality trait patterns. Our analysis shows that this dataset construction approach frequently generates false beliefs due to the information asymmetry between role-playing LLMs, and effectively reflects diverse personalities. We evaluate nine LLMs on ToMATO and find that even GPT-4o mini lags behind human performance, especially in understanding false beliefs, and lacks robustness to various personality traits.
Correntropy-Based Improper Likelihood Model for Robust Electrophysiological Source Imaging
Aug 27, 2024



Bayesian learning provides a unified skeleton to solve the electrophysiological source imaging task. From this perspective, existing source imaging algorithms utilize the Gaussian assumption for the observation noise to build the likelihood function for Bayesian inference. However, the electromagnetic measurements of brain activity are usually affected by miscellaneous artifacts, leading to a potentially non-Gaussian distribution for the observation noise. Hence the conventional Gaussian likelihood model is a suboptimal choice for the real-world source imaging task. In this study, we aim to solve this problem by proposing a new likelihood model which is robust with respect to non-Gaussian noises. Motivated by the robust maximum correntropy criterion, we propose a new improper distribution model concerning the noise assumption. This new noise distribution is leveraged to structure a robust likelihood function and integrated with hierarchical prior distributions to estimate source activities by variational inference. In particular, the score matching is adopted to determine the hyperparameters for the improper likelihood model. A comprehensive performance evaluation is performed to compare the proposed noise assumption to the conventional Gaussian model. Simulation results show that, the proposed method can realize more precise source reconstruction by designing known ground-truth. The real-world dataset also demonstrates the superiority of our new method with the visual perception task. This study provides a new backbone for Bayesian source imaging, which would facilitate its application using real-world noisy brain signal.
End-to-End Joint Target and Non-Target Speakers ASR
Jun 04, 2023


This paper proposes a novel automatic speech recognition (ASR) system that can transcribe individual speaker's speech while identifying whether they are target or non-target speakers from multi-talker overlapped speech. Target-speaker ASR systems are a promising way to only transcribe a target speaker's speech by enrolling the target speaker's information. However, in conversational ASR applications, transcribing both the target speaker's speech and non-target speakers' ones is often required to understand interactive information. To naturally consider both target and non-target speakers in a single ASR model, our idea is to extend autoregressive modeling-based multi-talker ASR systems to utilize the enrollment speech of the target speaker. Our proposed ASR is performed by recursively generating both textual tokens and tokens that represent target or non-target speakers. Our experiments demonstrate the effectiveness of our proposed method.
On the Use of Modality-Specific Large-Scale Pre-Trained Encoders for Multimodal Sentiment Analysis
Oct 28, 2022



This paper investigates the effectiveness and implementation of modality-specific large-scale pre-trained encoders for multimodal sentiment analysis~(MSA). Although the effectiveness of pre-trained encoders in various fields has been reported, conventional MSA methods employ them for only linguistic modality, and their application has not been investigated. This paper compares the features yielded by large-scale pre-trained encoders with conventional heuristic features. One each of the largest pre-trained encoders publicly available for each modality are used; CLIP-ViT, WavLM, and BERT for visual, acoustic, and linguistic modalities, respectively. Experiments on two datasets reveal that methods with domain-specific pre-trained encoders attain better performance than those with conventional features in both unimodal and multimodal scenarios. We also find it better to use the outputs of the intermediate layers of the encoders than those of the output layer. The codes are available at https://github.com/ando-hub/MSA_Pretrain.
Global Data Science Project for COVID-19 Summary Report
Jun 10, 2020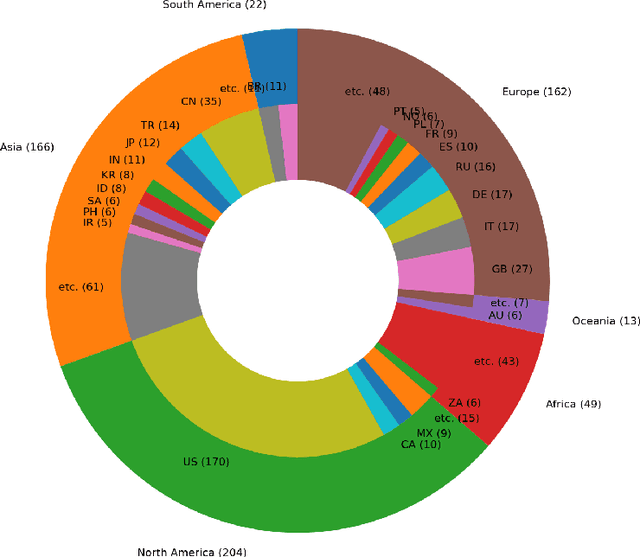
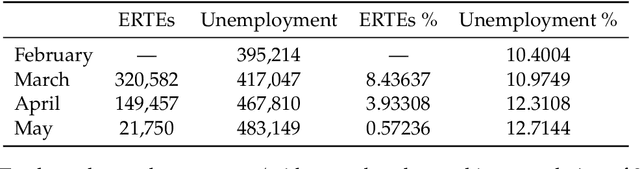
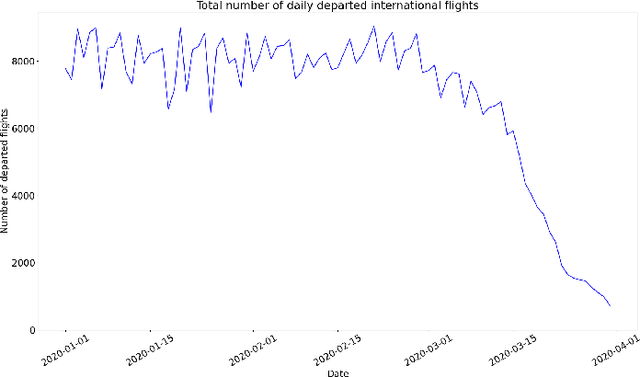
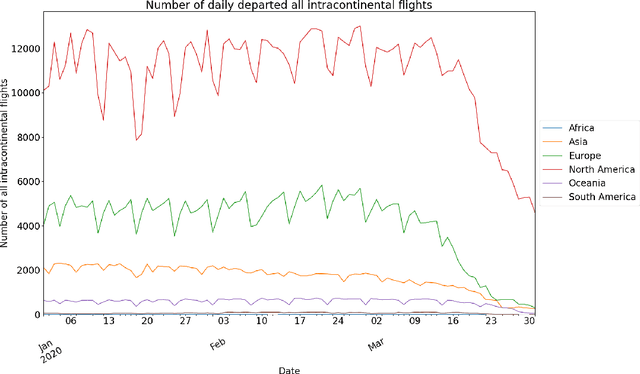
This paper aims at providing the summary of the Global Data Science Project (GDSC) for COVID-19. as on May 31 2020. COVID-19 has largely impacted on our societies through both direct and indirect effects transmitted by the policy measures to counter the spread of viruses. We quantitatively analysed the multifaceted impacts of the COVID-19 pandemic on our societies including people's mobility, health, and social behaviour changes. People's mobility has changed significantly due to the implementation of travel restriction and quarantine measurements. Indeed, the physical distance has widened at international (cross-border), national and regional level. At international level, due to the travel restrictions, the number of international flights has plunged overall at around 88 percent during March. In particular, the number of flights connecting Europe dropped drastically in mid of March after the United States announced travel restrictions to Europe and the EU and participating countries agreed to close borders, at 84 percent decline compared to March 10th. Similarly, we examined the impacts of quarantine measures in the major city: Tokyo (Japan), New York City (the United States), and Barcelona (Spain). Within all three cities, we found the significant decline in traffic volume. We also identified the increased concern for mental health through the analysis of posts on social networking services such as Twitter and Instagram. Notably, in the beginning of April 2020, the number of post with #depression on Instagram doubled, which might reflect the rise in mental health awareness among Instagram users. Besides, we identified the changes in a wide range of people's social behaviors, as well as economic impacts through the analysis of Instagram data and primary survey data.