 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFiner-Grained Correlations: Location Priors for Unseen Object Pose Estimation
Nov 29, 2022



We present a new method which provides object location priors for previously unseen object 6D pose estimation. Existing approaches build upon a template matching strategy and convolve a set of reference images with the query. Unfortunately, their performance is affected by the object scale mismatches between the references and the query. To address this issue, we present a finer-grained correlation estimation module, which handles the object scale mismatches by computing correlations with adjustable receptive fields. We also propose to decouple the correlations into scale-robust and scale-aware representations to estimate the object location and size, respectively. Our method achieves state-of-the-art unseen object localization and 6D pose estimation results on LINEMOD and GenMOP. We further construct a challenging synthetic dataset, where the results highlight the better robustness of our method to varying backgrounds, illuminations, and object sizes, as well as to the reference-query domain gap.
Knowledge Distillation for 6D Pose Estimation by Keypoint Distribution Alignment
May 30, 2022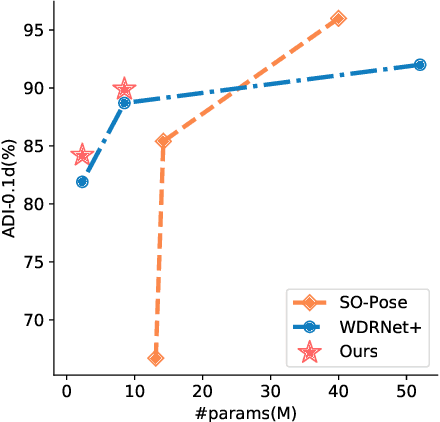
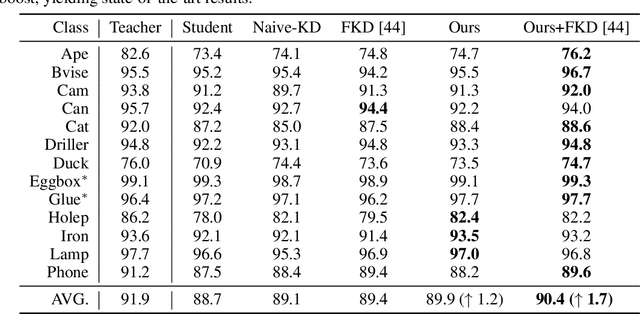

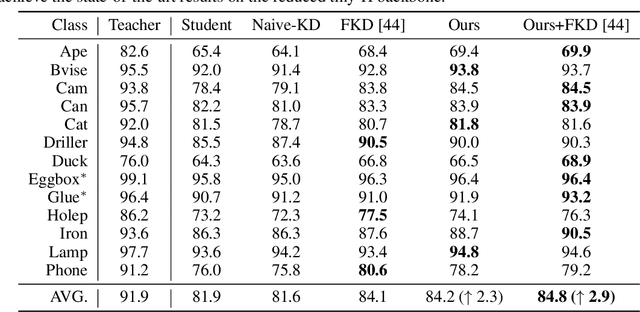
Knowledge distillation facilitates the training of a compact student network by using a deep teacher one. While this has achieved great success in many tasks, it remains completely unstudied for image-based 6D object pose estimation. In this work, we introduce the first knowledge distillation method for 6D pose estimation. Specifically, we follow a standard approach to 6D pose estimation, consisting of predicting the 2D image locations of object keypoints. In this context, we observe the compact student network to struggle predicting precise 2D keypoint locations. Therefore, to address this, instead of training the student with keypoint-to-keypoint supervision, we introduce a strategy based the optimal transport theory that distills the teacher's keypoint \emph{distribution} into the student network, facilitating its training. Our experiments on several benchmarks show that our distillation method yields state-of-the-art results with different compact student models.
Templates for 3D Object Pose Estimation Revisited: Generalization to New Objects and Robustness to Occlusions
Mar 31, 2022


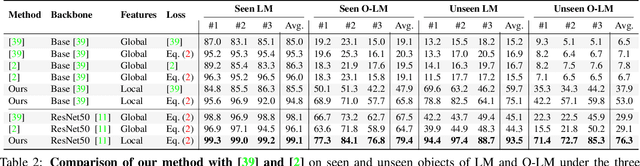
We present a method that can recognize new objects and estimate their 3D pose in RGB images even under partial occlusions. Our method requires neither a training phase on these objects nor real images depicting them, only their CAD models. It relies on a small set of training objects to learn local object representations, which allow us to locally match the input image to a set of "templates", rendered images of the CAD models for the new objects. In contrast with the state-of-the-art methods, the new objects on which our method is applied can be very different from the training objects. As a result, we are the first to show generalization without retraining on the LINEMOD and Occlusion-LINEMOD datasets. Our analysis of the failure modes of previous template-based approaches further confirms the benefits of local features for template matching. We outperform the state-of-the-art template matching methods on the LINEMOD, Occlusion-LINEMOD and T-LESS datasets. Our source code and data are publicly available at https://github.com/nv-nguyen/template-pose
Perspective Flow Aggregation for Data-Limited 6D Object Pose Estimation
Mar 18, 2022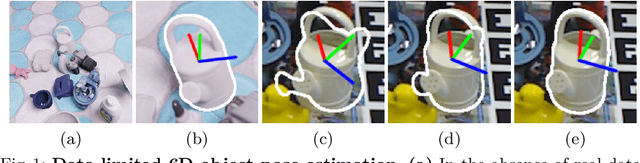

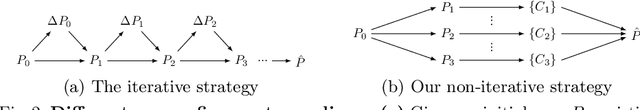
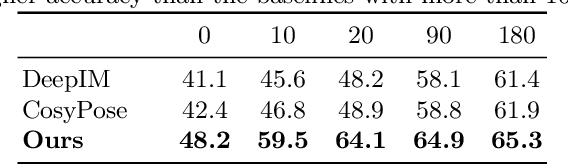
Most recent 6D object pose estimation methods, including unsupervised ones, require many real training images. Unfortunately, for some applications, such as those in space or deep under water, acquiring real images, even unannotated, is virtually impossible. In this paper, we propose a method that can be trained solely on synthetic images, or optionally using a few additional real ones. Given a rough pose estimate obtained from a first network, it uses a second network to predict a dense 2D correspondence field between the image rendered using the rough pose and the real image and infers the required pose correction. This approach is much less sensitive to the domain shift between synthetic and real images than state-of-the-art methods. It performs on par with methods that require annotated real images for training when not using any, and outperforms them considerably when using as few as twenty real images.
Fusing Local Similarities for Retrieval-based 3D Orientation Estimation of Unseen Objects
Mar 16, 2022
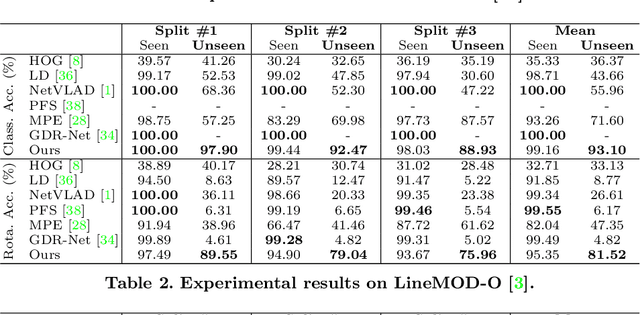
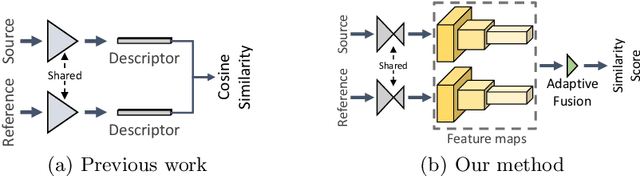
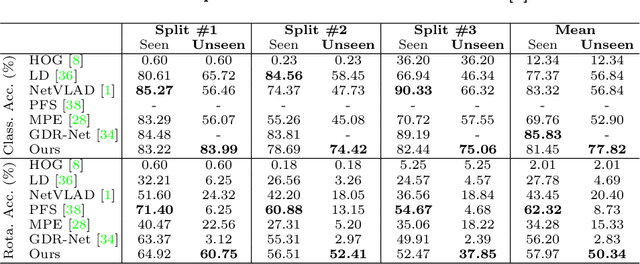
In this paper, we tackle the task of estimating the 3D orientation of previously-unseen objects from monocular images. This task contrasts with the one considered by most existing deep learning methods which typically assume that the testing objects have been observed during training. To handle the unseen objects, we follow a retrieval-based strategy and prevent the network from learning object-specific features by computing multi-scale local similarities between the query image and synthetically-generated reference images. We then introduce an adaptive fusion module that robustly aggregates the local similarities into a global similarity score of pairwise images. Furthermore, we speed up the retrieval process by developing a fast clustering-based retrieval strategy. Our experiments on the LineMOD, LineMOD-Occluded, and T-LESS datasets show that our method yields a significantly better generalization to unseen objects than previous works.
Robust Differentiable SVD
Apr 08, 2021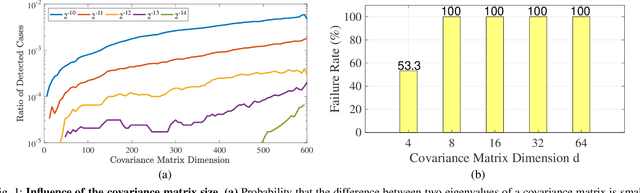



Eigendecomposition of symmetric matrices is at the heart of many computer vision algorithms. However, the derivatives of the eigenvectors tend to be numerically unstable, whether using the SVD to compute them analytically or using the Power Iteration (PI) method to approximate them. This instability arises in the presence of eigenvalues that are close to each other. This makes integrating eigendecomposition into deep networks difficult and often results in poor convergence, particularly when dealing with large matrices. While this can be mitigated by partitioning the data into small arbitrary groups, doing so has no theoretical basis and makes it impossible to exploit the full power of eigendecomposition. In previous work, we mitigated this using SVD during the forward pass and PI to compute the gradients during the backward pass. However, the iterative deflation procedure required to compute multiple eigenvectors using PI tends to accumulate errors and yield inaccurate gradients. Here, we show that the Taylor expansion of the SVD gradient is theoretically equivalent to the gradient obtained using PI without relying in practice on an iterative process and thus yields more accurate gradients. We demonstrate the benefits of this increased accuracy for image classification and style transfer.
* IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) PREPRINT 2021
Wide-Depth-Range 6D Object Pose Estimation in Space
Apr 01, 2021
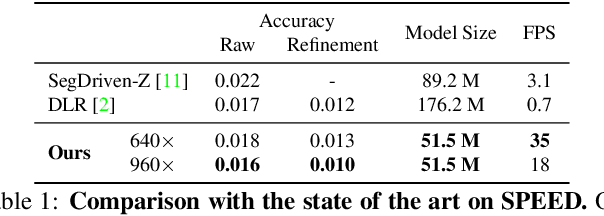
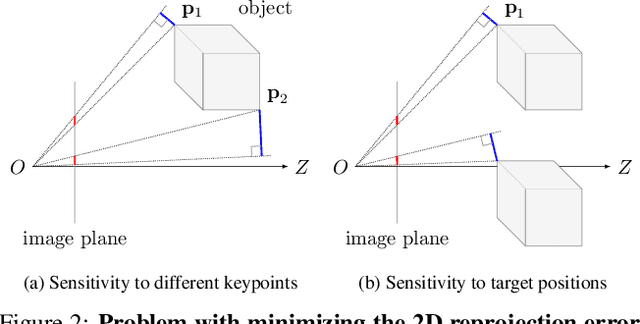
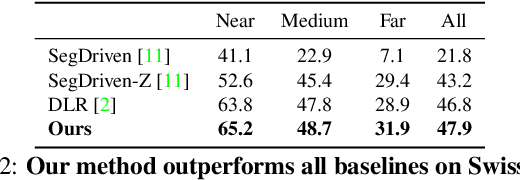
6D pose estimation in space poses unique challenges that are not commonly encountered in the terrestrial setting. One of the most striking differences is the lack of atmospheric scattering, allowing objects to be visible from a great distance while complicating illumination conditions. Currently available benchmark datasets do not place a sufficient emphasis on this aspect and mostly depict the target in close proximity. Prior work tackling pose estimation under large scale variations relies on a two-stage approach to first estimate scale, followed by pose estimation on a resized image patch. We instead propose a single-stage hierarchical end-to-end trainable network that is more robust to scale variations. We demonstrate that it outperforms existing approaches not only on images synthesized to resemble images taken in space but also on standard benchmarks.
Robust RGB-based 6-DoF Pose Estimation without Real Pose Annotations
Aug 19, 2020
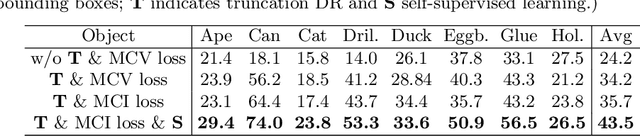
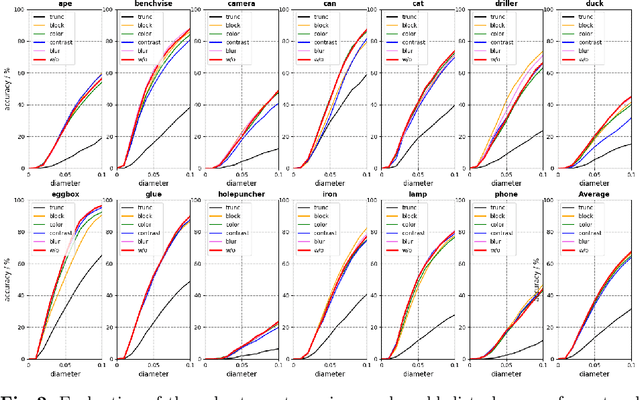

While much progress has been made in 6-DoF object pose estimation from a single RGB image, the current leading approaches heavily rely on real-annotation data. As such, they remain sensitive to severe occlusions, because covering all possible occlusions with annotated data is intractable. In this paper, we introduce an approach to robustly and accurately estimate the 6-DoF pose in challenging conditions and without using any real pose annotations. To this end, we leverage the intuition that the poses predicted by a network from an image and from its counterpart synthetically altered to mimic occlusion should be consistent, and translate this to a self-supervised loss function. Our experiments on LINEMOD, Occluded-LINEMOD, YCB and new Randomization LINEMOD dataset evidence the robustness of our approach. We achieve state of the art performance on LINEMOD, and OccludedLINEMOD in without real-pose setting, even outperforming methods that rely on real annotations during training on Occluded-LINEMOD.
Eigendecomposition-Free Training of Deep Networks for Linear Least-Square Problems
Apr 15, 2020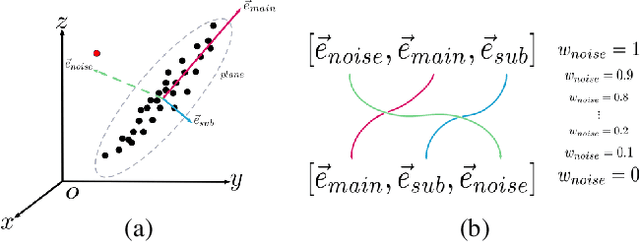
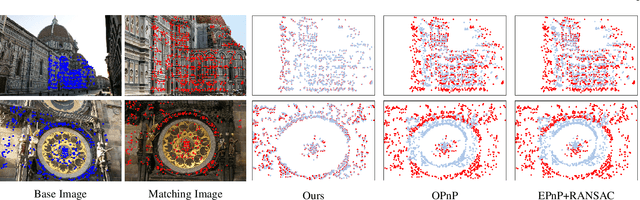


Many classical Computer Vision problems, such as essential matrix computation and pose estimation from 3D to 2D correspondences, can be tackled by solving a linear least-square problem, which can be done by finding the eigenvector corresponding to the smallest, or zero, eigenvalue of a matrix representing a linear system. Incorporating this in deep learning frameworks would allow us to explicitly encode known notions of geometry, instead of having the network implicitly learn them from data. However, performing eigendecomposition within a network requires the ability to differentiate this operation. While theoretically doable, this introduces numerical instability in the optimization process in practice. In this paper, we introduce an eigendecomposition-free approach to training a deep network whose loss depends on the eigenvector corresponding to a zero eigenvalue of a matrix predicted by the network. We demonstrate that our approach is much more robust than explicit differentiation of the eigendecomposition using two general tasks, outlier rejection and denoising, with several practical examples including wide-baseline stereo, the perspective-n-point problem, and ellipse fitting. Empirically, our method has better convergence properties and yields state-of-the-art results.
Single-Stage 6D Object Pose Estimation
Nov 19, 2019
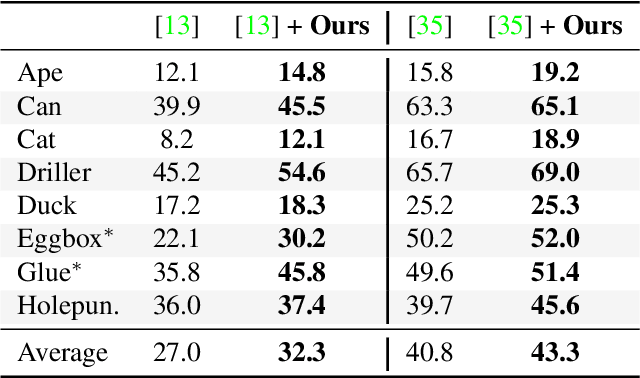
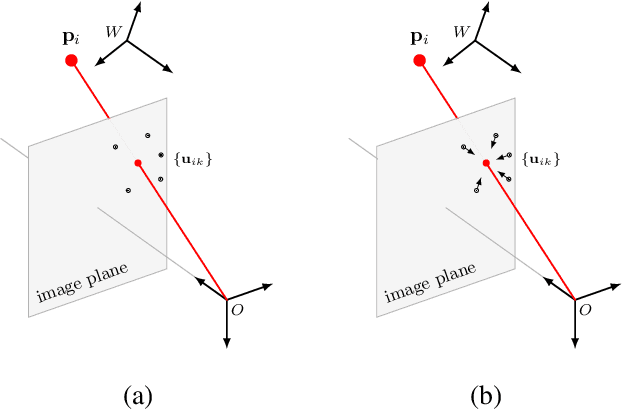
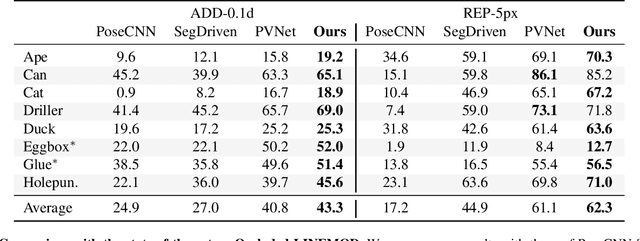
Most recent 6D pose estimation frameworks first rely on a deep network to establish correspondences between 3D object keypoints and 2D image locations and then use a variant of a RANSAC-based Perspective-n-Point (PnP) algorithm. This two-stage process, however, is suboptimal: First, it is not end-to-end trainable. Second, training the deep network relies on a surrogate loss that does not directly reflect the final 6D pose estimation task. In this work, we introduce a deep architecture that directly regresses 6D poses from correspondences. It takes as input a group of candidate correspondences for each 3D keypoint and accounts for the fact that the order of the correspondences within each group is irrelevant, while the order of the groups, that is, of the 3D keypoints, is fixed. Our architecture is generic and can thus be exploited in conjunction with existing correspondence-extraction networks so as to yield single-stage 6D pose estimation frameworks. Our experiments demonstrate that these single-stage frameworks consistently outperform their two-stage counterparts in terms of both accuracy and speed.