 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal and Local Texture Randomization for Synthetic-to-Real Semantic Segmentation
Aug 06, 2021
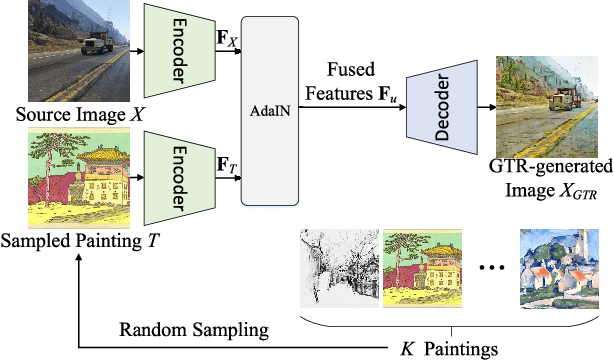
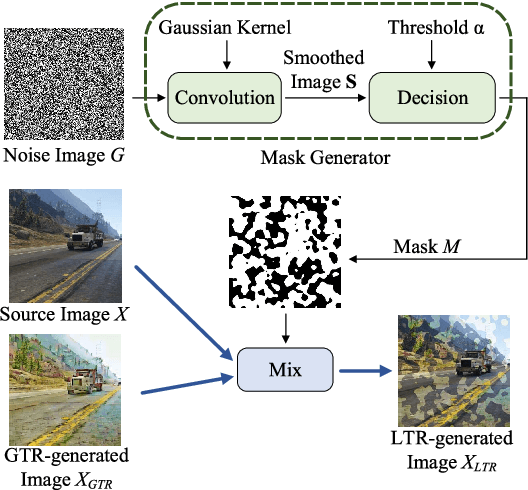
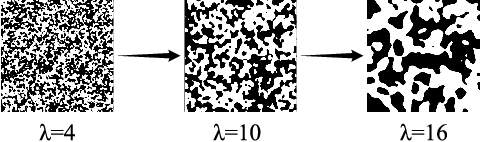
Semantic segmentation is a crucial image understanding task, where each pixel of image is categorized into a corresponding label. Since the pixel-wise labeling for ground-truth is tedious and labor intensive, in practical applications, many works exploit the synthetic images to train the model for real-word image semantic segmentation, i.e., Synthetic-to-Real Semantic Segmentation (SRSS). However, Deep Convolutional Neural Networks (CNNs) trained on the source synthetic data may not generalize well to the target real-world data. In this work, we propose two simple yet effective texture randomization mechanisms, Global Texture Randomization (GTR) and Local Texture Randomization (LTR), for Domain Generalization based SRSS. GTR is proposed to randomize the texture of source images into diverse unreal texture styles. It aims to alleviate the reliance of the network on texture while promoting the learning of the domain-invariant cues. In addition, we find the texture difference is not always occurred in entire image and may only appear in some local areas. Therefore, we further propose a LTR mechanism to generate diverse local regions for partially stylizing the source images. Finally, we implement a regularization of Consistency between GTR and LTR (CGL) aiming to harmonize the two proposed mechanisms during training. Extensive experiments on five publicly available datasets (i.e., GTA5, SYNTHIA, Cityscapes, BDDS and Mapillary) with various SRSS settings (i.e., GTA5/SYNTHIA to Cityscapes/BDDS/Mapillary) demonstrate that the proposed method is superior to the state-of-the-art methods for domain generalization based SRSS.
A Generalized Framework for Edge-preserving and Structure-preserving Image Smoothing
Aug 04, 2021
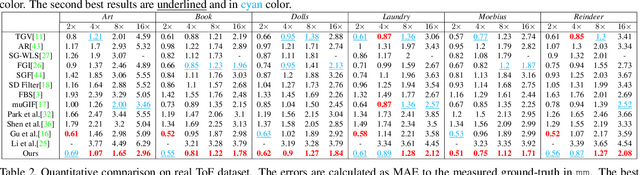
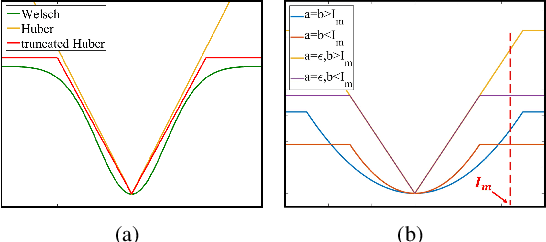

Image smoothing is a fundamental procedure in applications of both computer vision and graphics. The required smoothing properties can be different or even contradictive among different tasks. Nevertheless, the inherent smoothing nature of one smoothing operator is usually fixed and thus cannot meet the various requirements of different applications. In this paper, we first introduce the truncated Huber penalty function which shows strong flexibility under different parameter settings. A generalized framework is then proposed with the introduced truncated Huber penalty function. When combined with its strong flexibility, our framework is able to achieve diverse smoothing natures where contradictive smoothing behaviors can even be achieved. It can also yield the smoothing behavior that can seldom be achieved by previous methods, and superior performance is thus achieved in challenging cases. These together enable our framework capable of a range of applications and able to outperform the state-of-the-art approaches in several tasks, such as image detail enhancement, clip-art compression artifacts removal, guided depth map restoration, image texture removal, etc. In addition, an efficient numerical solution is provided and its convergence is theoretically guaranteed even the optimization framework is non-convex and non-smooth. A simple yet effective approach is further proposed to reduce the computational cost of our method while maintaining its performance. The effectiveness and superior performance of our approach are validated through comprehensive experiments in a range of applications. Our code is available at https://github.com/wliusjtu/Generalized-Smoothing-Framework.
Contextualize Knowledge Bases with Transformer for End-to-end Task-Oriented Dialogue Systems
Oct 22, 2020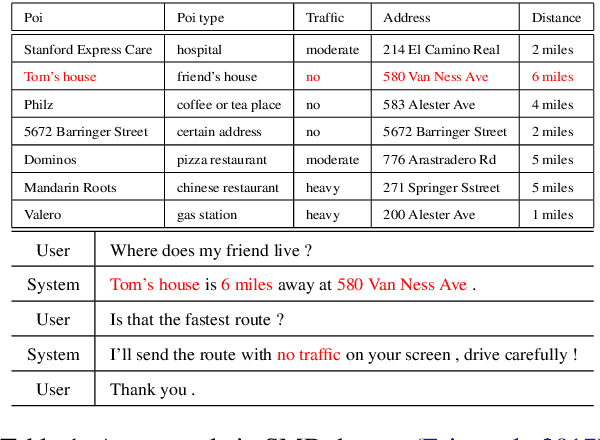
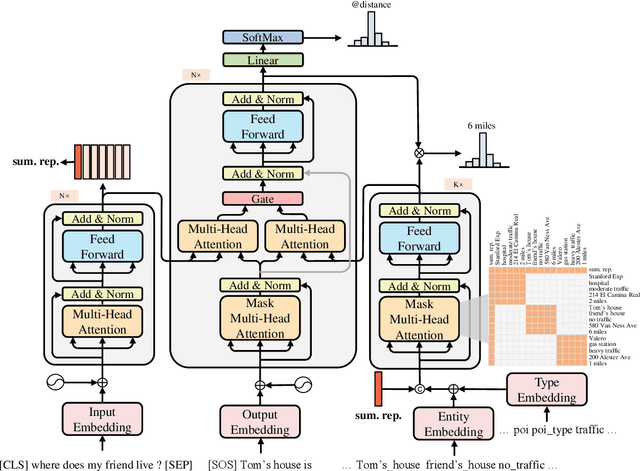
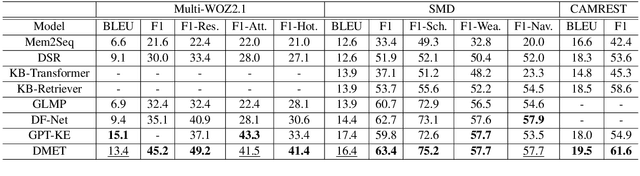
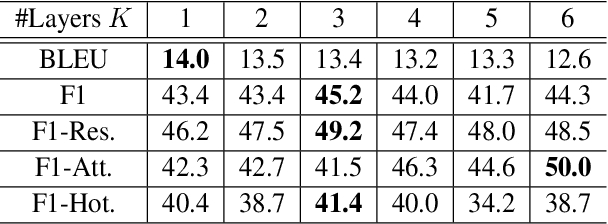
Recent studies try to build task-oriented dialogue systems in an end-to-end manner and the existing works make great progress on this task. However, there is still an issue need to be further considered, i.e., how to effectively represent the knowledge bases and incorporate that into dialogue systems. To solve this issue, we design a novel Transformer-based Context-aware Memory Generator to model the entities in knowledge bases, which can produce entity representations with perceiving all the relevant entities and dialogue history. Furthermore, we propose Context-aware Memory Enhanced Transformer (CMET), which can effectively aggregate information from the dialogue history and knowledge bases to generate more accurate responses. Through extensive experiments, our method can achieve superior performance over the state-of-the-art methods.
Hierarchical Paired Channel Fusion Network for Street Scene Change Detection
Oct 19, 2020



Street Scene Change Detection (SSCD) aims to locate the changed regions between a given street-view image pair captured at different times, which is an important yet challenging task in the computer vision community. The intuitive way to solve the SSCD task is to fuse the extracted image feature pairs, and then directly measure the dissimilarity parts for producing a change map. Therefore, the key for the SSCD task is to design an effective feature fusion method that can improve the accuracy of the corresponding change maps. To this end, we present a novel Hierarchical Paired Channel Fusion Network (HPCFNet), which utilizes the adaptive fusion of paired feature channels. Specifically, the features of a given image pair are jointly extracted by a Siamese Convolutional Neural Network (SCNN) and hierarchically combined by exploring the fusion of channel pairs at multiple feature levels. In addition, based on the observation that the distribution of scene changes is diverse, we further propose a Multi-Part Feature Learning (MPFL) strategy to detect diverse changes. Based on the MPFL strategy, our framework achieves a novel approach to adapt to the scale and location diversities of the scene change regions. Extensive experiments on three public datasets (i.e., PCD, VL-CMU-CD and CDnet2014) demonstrate that the proposed framework achieves superior performance which outperforms other state-of-the-art methods with a considerable margin.
Semi-Supervised Crowd Counting via Self-Training on Surrogate Tasks
Jul 07, 2020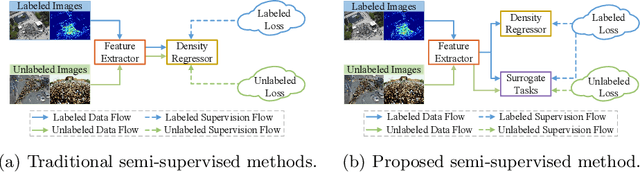
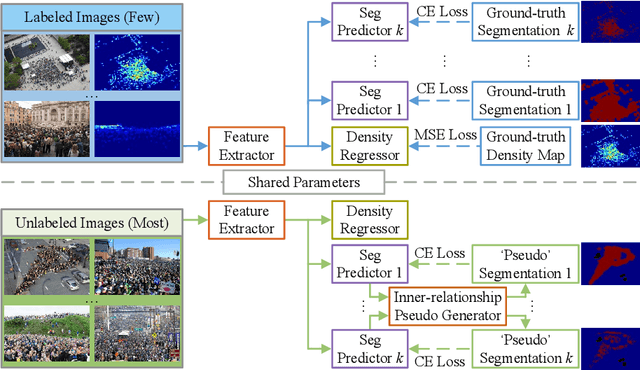

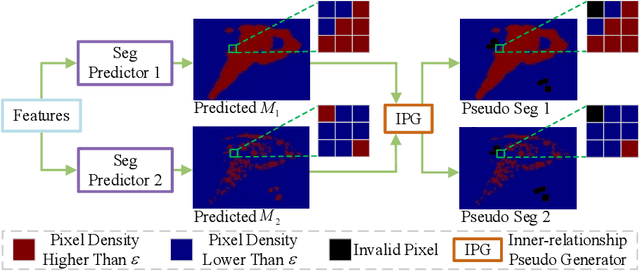
Most existing crowd counting systems rely on the availability of the object location annotation which can be expensive to obtain. To reduce the annotation cost, one attractive solution is to leverage a large number of unlabeled images to build a crowd counting model in semi-supervised fashion. This paper tackles the semi-supervised crowd counting problem from the perspective of feature learning. Our key idea is to leverage the unlabeled images to train a generic feature extractor rather than the entire network of a crowd counter. The rationale of this design is that learning the feature extractor can be more reliable and robust towards the inevitable noisy supervision generated from the unlabeled data. Also, on top of a good feature extractor, it is possible to build a density map regressor with much fewer density map annotations. Specifically, we proposed a novel semi-supervised crowd counting method which is built upon two innovative components: (1) a set of inter-related binary segmentation tasks are derived from the original density map regression task as the surrogate prediction target; (2) the surrogate target predictors are learned from both labeled and unlabeled data by utilizing a proposed self-training scheme which fully exploits the underlying constraints of these binary segmentation tasks. Through experiments, we show that the proposed method is superior over the existing semisupervised crowd counting method and other representative baselines.
Towards Using Count-level Weak Supervision for Crowd Counting
Feb 29, 2020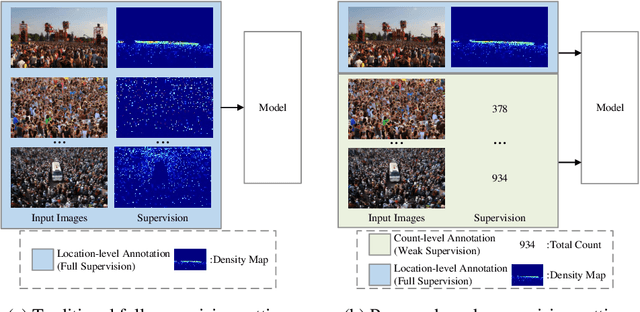

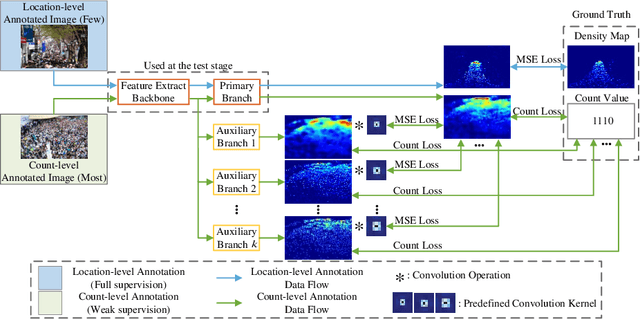
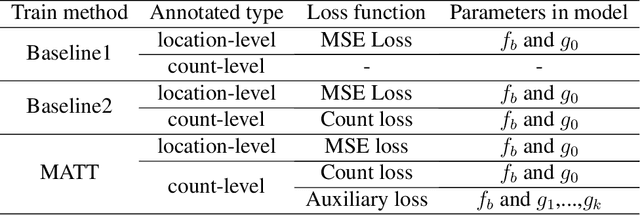
Most existing crowd counting methods require object location-level annotation, i.e., placing a dot at the center of an object. While being simpler than the bounding-box or pixel-level annotation, obtaining this annotation is still labor-intensive and time-consuming especially for images with highly crowded scenes. On the other hand, weaker annotations that only know the total count of objects can be almost effortless in many practical scenarios. Thus, it is desirable to develop a learning method that can effectively train models from count-level annotations. To this end, this paper studies the problem of weakly-supervised crowd counting which learns a model from only a small amount of location-level annotations (fully-supervised) but a large amount of count-level annotations (weakly-supervised). To perform effective training in this scenario, we observe that the direct solution of regressing the integral of density map to the object count is not sufficient and it is beneficial to introduce stronger regularizations on the predicted density map of weakly-annotated images. We devise a simple-yet-effective training strategy, namely Multiple Auxiliary Tasks Training (MATT), to construct regularizes for restricting the freedom of the generated density maps. Through extensive experiments on existing datasets and a newly proposed dataset, we validate the effectiveness of the proposed weakly-supervised method and demonstrate its superior performance over existing solutions.
Overcoming Long-term Catastrophic Forgetting through Adversarial Neural Pruning and Synaptic Consolidation
Dec 19, 2019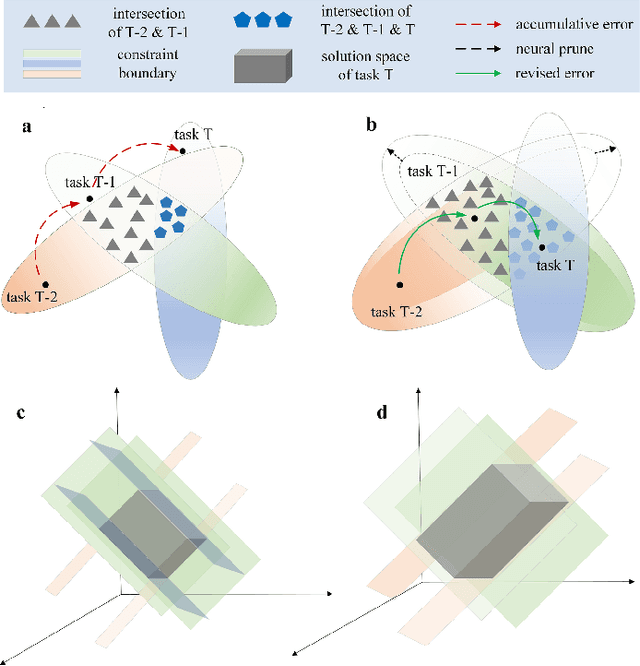

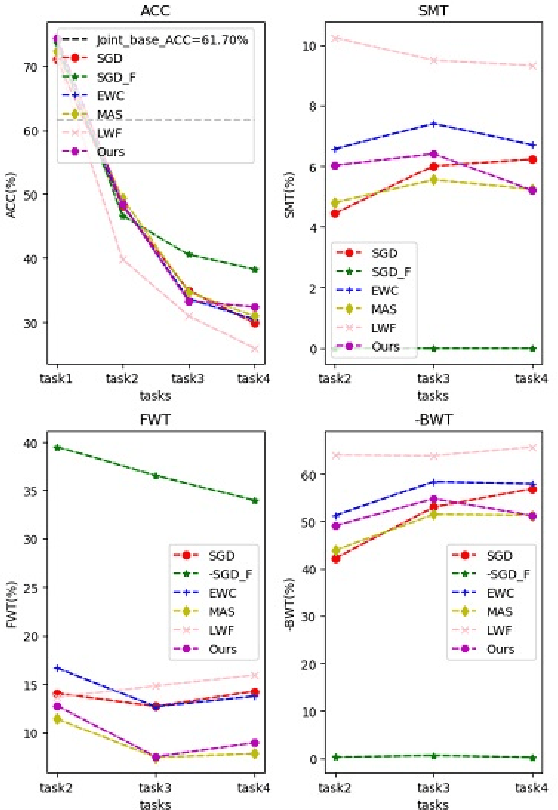
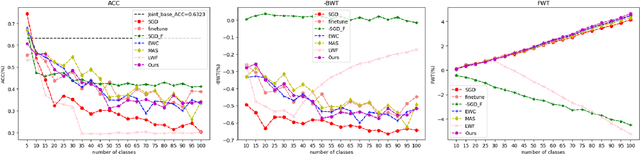
Enabling a neural network to sequentially learn multiple tasks is of great significance for expanding the applicability of neural networks in realistic human application scenarios. However, as the task sequence increases, the model quickly forgets previously learned skills; we refer to this loss of memory of long sequences as long-term catastrophic forgetting. There are two main reasons for the long-term forgetting: first, as the tasks increase, the intersection of the low-error parameter subspace satisfying these tasks will become smaller and smaller or even non-existent; The second is the cumulative error in the process of protecting the knowledge of previous tasks. This paper, we propose a confrontation mechanism in which neural pruning and synaptic consolidation are used to overcome long-term catastrophic forgetting. This mechanism distills task-related knowledge into a small number of parameters, and retains the old knowledge by consolidating a small number of parameters, while sparing most parameters to learn the follow-up tasks, which not only avoids forgetting but also can learn a large number of tasks. Specifically, the neural pruning iteratively relaxes the parameter conditions of the current task to expand the common parameter subspace of tasks; The modified synaptic consolidation strategy is comprised of two components, a novel network structure information considered measurement is proposed to calculate the parameter importance, and a element-wise parameter updating strategy that is designed to prevent significant parameters being overridden in subsequent learning. We verified the method on image classification, and the results showed that our proposed ANPSC approach outperforms the state-of-the-art methods. The hyperparametric sensitivity test further demonstrates the robustness of our proposed approach.
Improving Distant Supervised Relation Extraction by Dynamic Neural Network
Dec 13, 2019

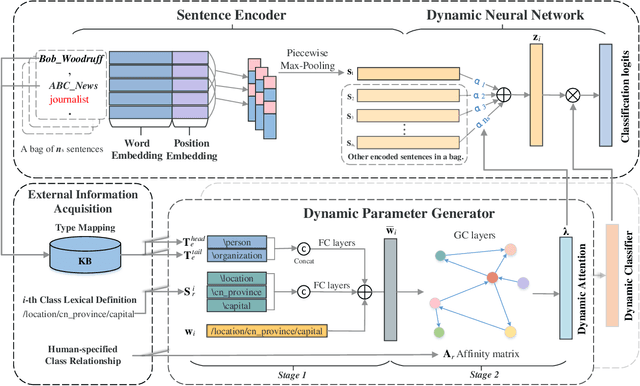
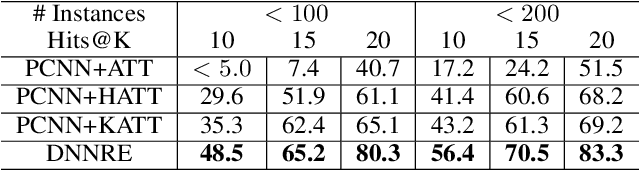
Distant Supervised Relation Extraction (DSRE) is usually formulated as a problem of classifying a bag of sentences that contain two query entities, into the predefined relation classes. Most existing methods consider those relation classes as distinct semantic categories while ignoring their potential connection to query entities. In this paper, we propose to leverage this connection to improve the relation extraction accuracy. Our key ideas are twofold: (1) For sentences belonging to the same relation class, the expression style, i.e. words choice, can vary according to the query entities. To account for this style shift, the model should adjust its parameters in accordance with entity types. (2) Some relation classes are semantically similar, and the entity types appear in one relation may also appear in others. Therefore, it can be trained cross different relation classes and further enhance those classes with few samples, i.e., long-tail classes. To unify these two arguments, we developed a novel Dynamic Neural Network for Relation Extraction (DNNRE). The network adopts a novel dynamic parameter generator that dynamically generates the network parameters according to the query entity types and relation classes. By using this mechanism, the network can simultaneously handle the style shift problem and enhance the prediction accuracy for long-tail classes. Through our experimental study, we demonstrate the effectiveness of the proposed method and show that it can achieve superior performance over the state-of-the-art methods.
Deep Multiphase Level Set for Scene Parsing
Oct 13, 2019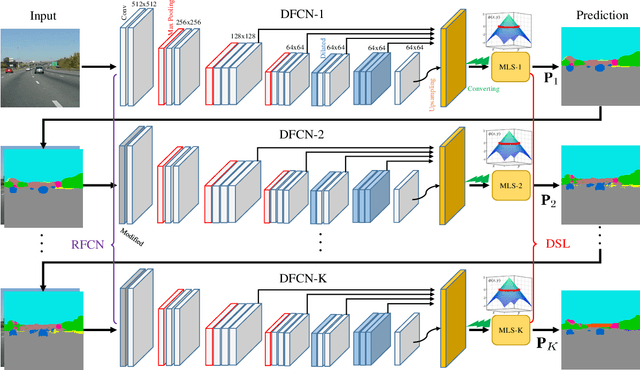
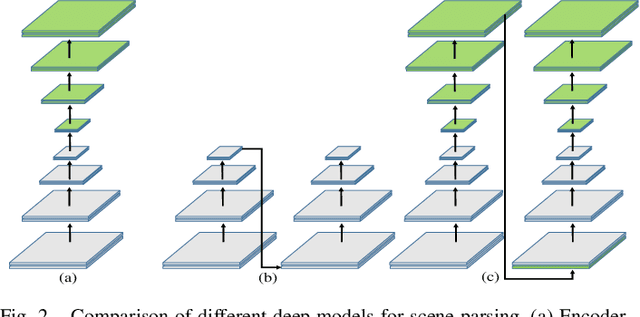
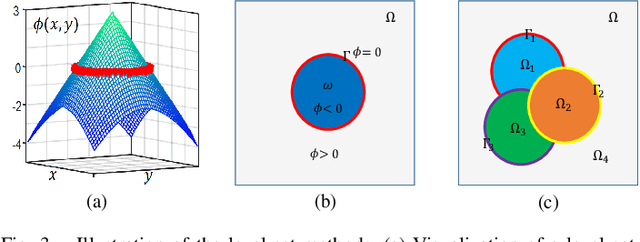
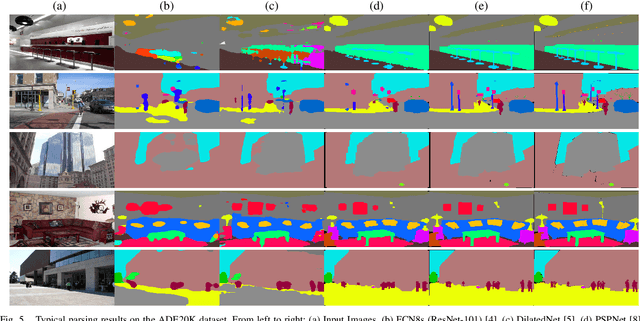
Recently, Fully Convolutional Network (FCN) seems to be the go-to architecture for image segmentation, including semantic scene parsing. However, it is difficult for a generic FCN to discriminate pixels around the object boundaries, thus FCN based methods may output parsing results with inaccurate boundaries. Meanwhile, level set based active contours are superior to the boundary estimation due to the sub-pixel accuracy that they achieve. However, they are quite sensitive to initial settings. To address these limitations, in this paper we propose a novel Deep Multiphase Level Set (DMLS) method for semantic scene parsing, which efficiently incorporates multiphase level sets into deep neural networks. The proposed method consists of three modules, i.e., recurrent FCNs, adaptive multiphase level set, and deeply supervised learning. More specifically, recurrent FCNs learn multi-level representations of input images with different contexts. Adaptive multiphase level set drives the discriminative contour for each semantic class, which makes use of the advantages of both global and local information. In each time-step of the recurrent FCNs, deeply supervised learning is incorporated for model training. Extensive experiments on three public benchmarks have shown that our proposed method achieves new state-of-the-art performances.
Cascaded Context Pyramid for Full-Resolution 3D Semantic Scene Completion
Aug 01, 2019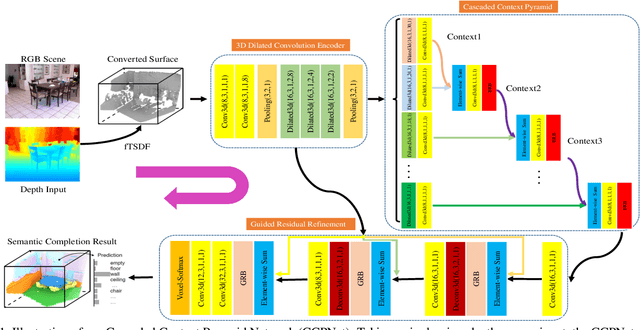
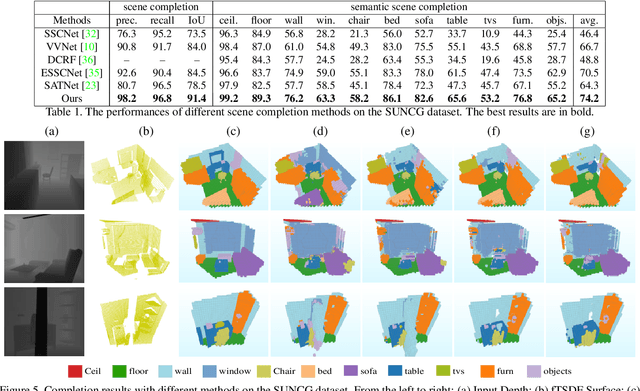
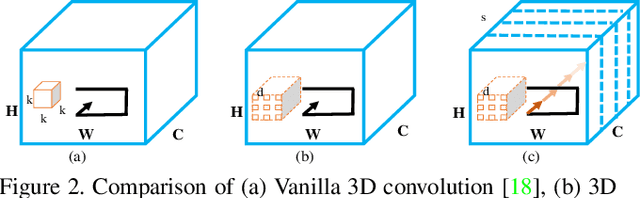
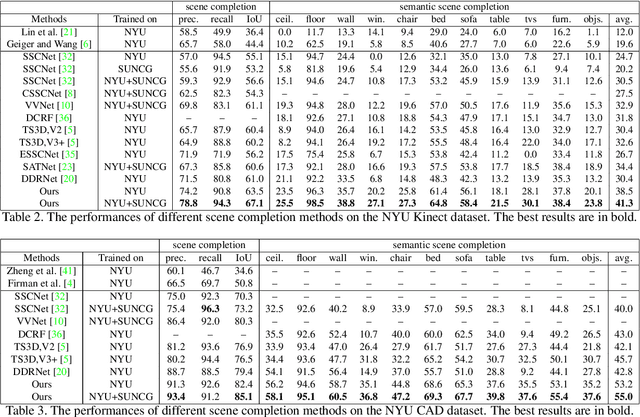
Semantic Scene Completion (SSC) aims to simultaneously predict the volumetric occupancy and semantic category of a 3D scene. It helps intelligent devices to understand and interact with the surrounding scenes. Due to the high-memory requirement, current methods only produce low-resolution completion predictions, and generally lose the object details. Furthermore, they also ignore the multi-scale spatial contexts, which play a vital role for the 3D inference. To address these issues, in this work we propose a novel deep learning framework, named Cascaded Context Pyramid Network (CCPNet), to jointly infer the occupancy and semantic labels of a volumetric 3D scene from a single depth image. The proposed CCPNet improves the labeling coherence with a cascaded context pyramid. Meanwhile, based on the low-level features, it progressively restores the fine-structures of objects with Guided Residual Refinement (GRR) modules. Our proposed framework has three outstanding advantages: (1) it explicitly models the 3D spatial context for performance improvement; (2) full-resolution 3D volumes are produced with structure-preserving details; (3) light-weight models with low-memory requirements are captured with a good extensibility. Extensive experiments demonstrate that in spite of taking a single-view depth map, our proposed framework can generate high-quality SSC results, and outperforms state-of-the-art approaches on both the synthetic SUNCG and real NYU datasets.