 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition Dependent Prediction Combination For Intra-Frame Video Coding
May 29, 2025



Intra-frame prediction in the High Efficiency Video Coding (HEVC) standard can be empirically improved by applying sets of recursive two-dimensional filters to the predicted values. However, this approach does not allow (or complicates significantly) the parallel computation of pixel predictions. In this work we analyze why the recursive filters are effective, and use the results to derive sets of non-recursive predictors that have superior performance. We present an extension to HEVC intra prediction that combines values predicted using non-filtered and filtered (smoothed) reference samples, depending on the prediction mode, and block size. Simulations using the HEVC common test conditions show that a 2.0% bit rate average reduction can be achieved compared to HEVC, for All Intra (AI) configurations.
Highly Efficient Non-Separable Transforms for Next Generation Video Coding
May 27, 2025For the last few decades, the application of signal-adaptive transform coding to video compression has been stymied by the large computational complexity of matrix-based solutions. In this paper, we propose a novel parametric approach to greatly reduce the complexity without degrading the compression performance. In our approach, instead of following the conventional technique of identifying full transform matrices that yield best compression efficiency, we look for the best transform parameters defining a new class of transforms, called HyGTs, which have low complexity implementations that are easy to parallelize. The proposed HyGTs are implemented as an extension of High Efficiency Video Coding (HEVC), and our comprehensive experimental results demonstrate that proposed HyGTs improve average coding gain by 6% bit rate reduction, while using 6.8 times less memory than KLT matrices.
A Combined Deep Learning based End-to-End Video Coding Architecture for YUV Color Space
Apr 01, 2021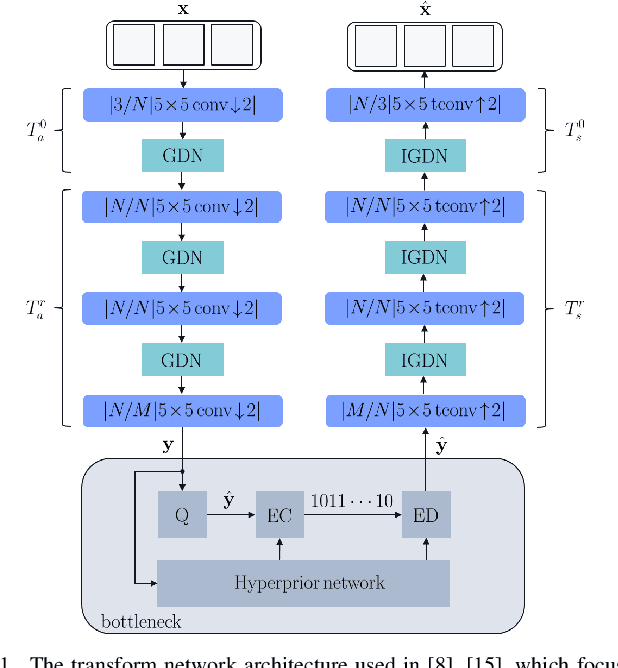
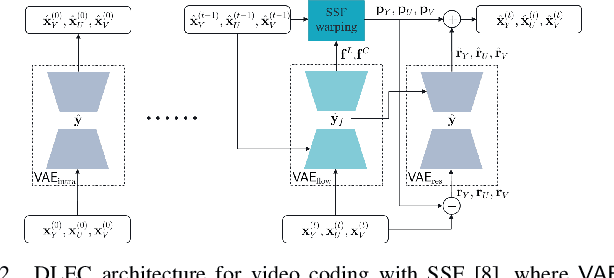
Most of the existing deep learning based end-to-end video coding (DLEC) architectures are designed specifically for RGB color format, yet the video coding standards, including H.264/AVC, H.265/HEVC and H.266/VVC developed over past few decades, have been designed primarily for YUV 4:2:0 format, where the chrominance (U and V) components are subsampled to achieve superior compression performances considering the human visual system. While a broad number of papers on DLEC compare these two distinct coding schemes in RGB domain, it is ideal to have a common evaluation framework in YUV 4:2:0 domain for a more fair comparison. This paper introduces a new DLEC architecture for video coding to effectively support YUV 4:2:0 and compares its performance against the HEVC standard under a common evaluation framework. The experimental results on YUV 4:2:0 video sequences show that the proposed architecture can outperform HEVC in intra-frame coding, however inter-frame coding is not as efficient on contrary to the RGB coding results reported in recent papers.
Transform Network Architectures for Deep Learning based End-to-End Image/Video Coding in Subsampled Color Spaces
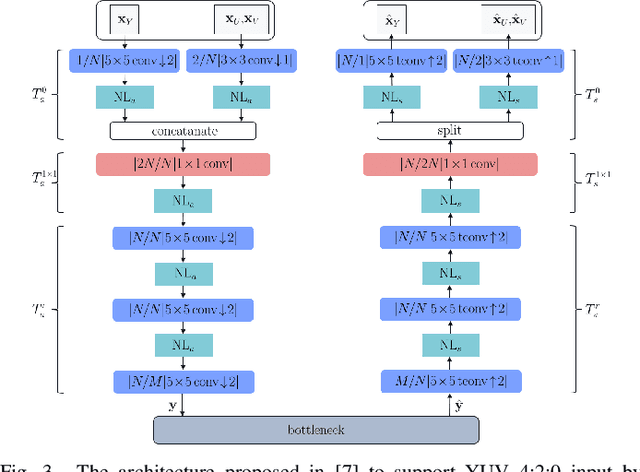
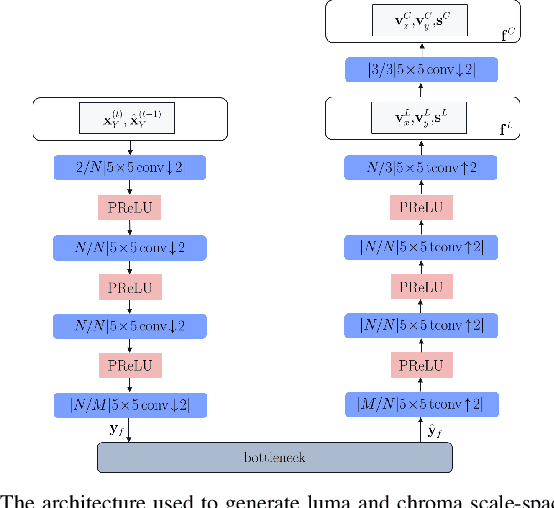
Feb 27, 2021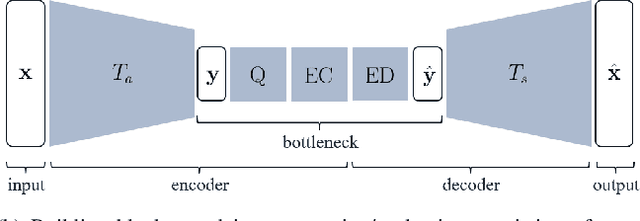
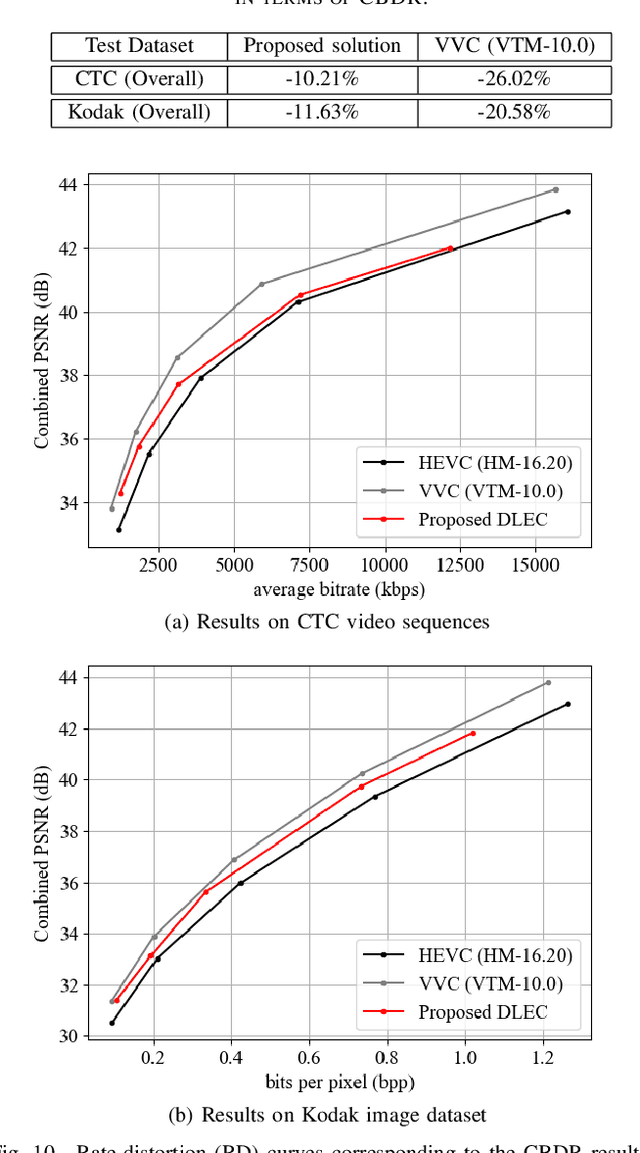
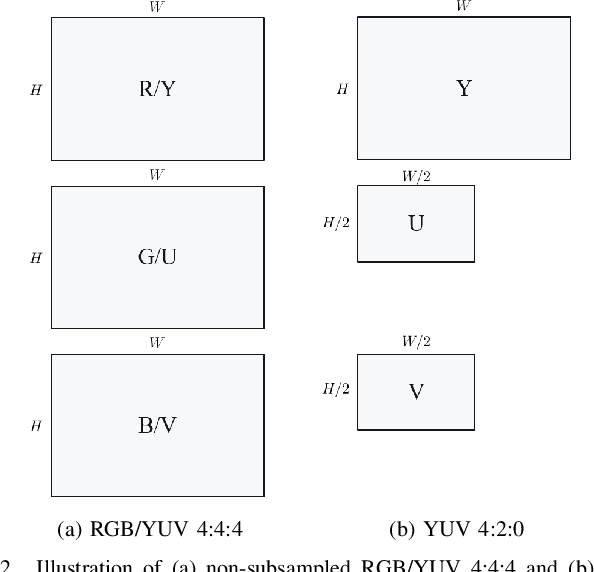

Most of the existing deep learning based end-to-end image/video coding (DLEC) architectures are designed for non-subsampled RGB color format. However, in order to achieve a superior coding performance, many state-of-the-art block-based compression standards such as High Efficiency Video Coding (HEVC/H.265) and Versatile Video Coding (VVC/H.266) are designed primarily for YUV 4:2:0 format, where U and V components are subsampled by considering the human visual system. This paper investigates various DLEC designs to support YUV 4:2:0 format by comparing their performance against the main profiles of HEVC and VVC standards under a common evaluation framework. Moreover, a new transform network architecture is proposed to improve the efficiency of coding YUV 4:2:0 data. The experimental results on YUV 4:2:0 datasets show that the proposed architecture significantly outperforms naive extensions of existing architectures designed for RGB format and achieves about 10% average BD-rate improvement over the intra-frame coding in HEVC.
Parametric Graph-based Separable Transforms for Video Coding
Nov 16, 2019
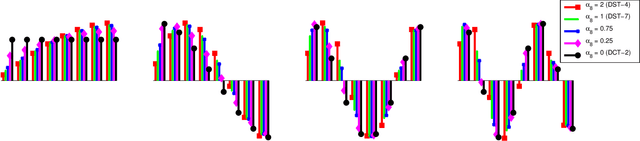
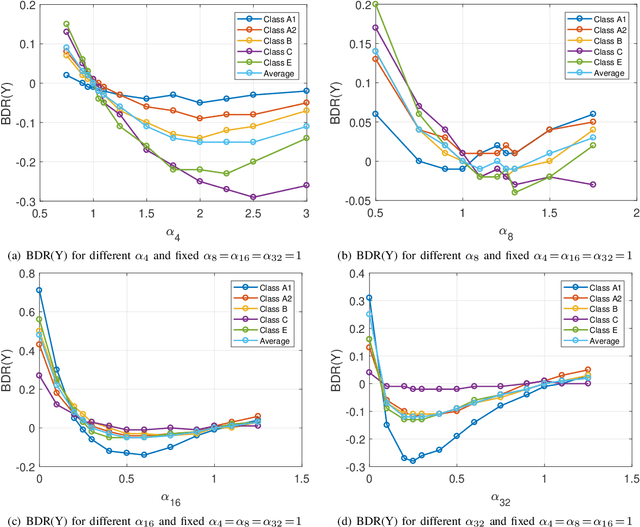
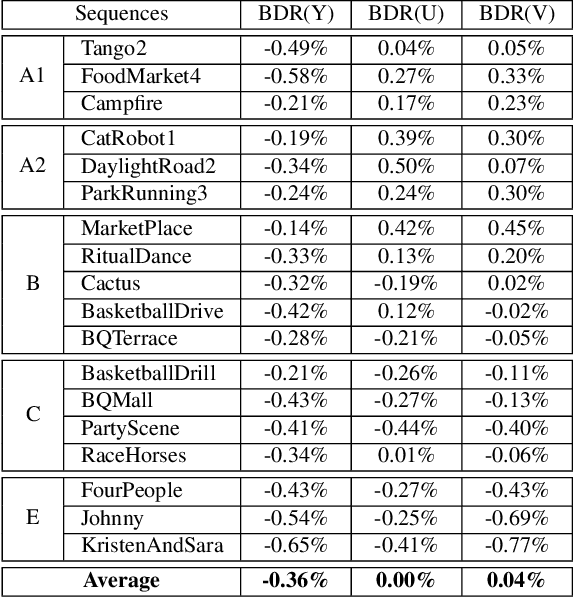
In many video coding systems, separable transforms (such as two-dimensional DCT-2) have been used to code block residual signals obtained after prediction. This paper proposes a parametric approach to build graph-based separable transforms (GBSTs) for video coding. Specifically, a GBST is derived from a pair of line graphs, whose weights are determined based on two non-negative parameters. As certain choices of those parameters correspond to the discrete sine and cosine transform types used in recent video coding standards (including DCT-2, DST-7 and DCT-8), this paper further optimizes these graph parameters to better capture residual block statistics and improve video coding efficiency. The proposed GBSTs are tested on the Versatile Video Coding (VVC) reference software, and the experimental results show that about 0.4\% average coding gain is achieved over the existing set of separable transforms constructed based on DCT-2, DST-7 and DCT-8 in VVC.