 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Set Functions Under the Optimal Subset Oracle via Equivariant Variational Inference
Mar 03, 2022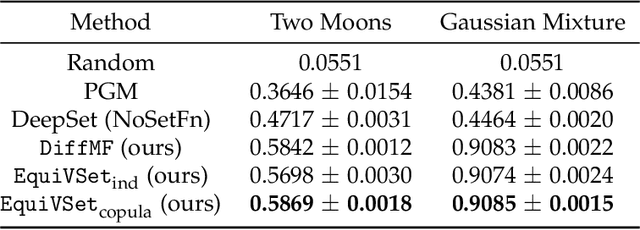
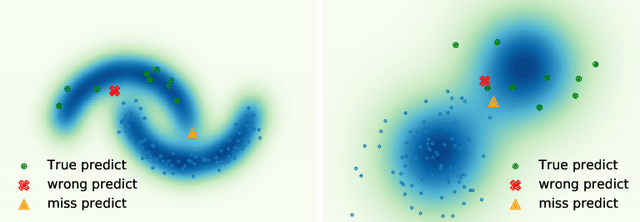
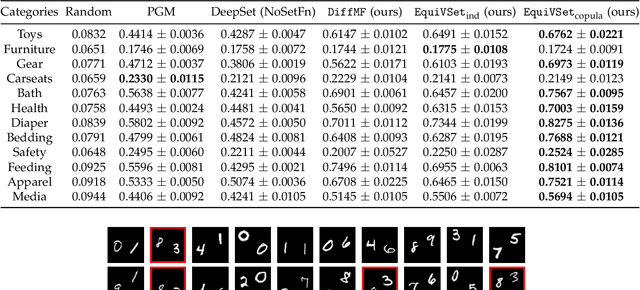

Learning set functions becomes increasingly more important in many applications like product recommendation and compound selection in AI-aided drug discovery. The majority of existing works study methodologies of set function learning under the function value oracle, which, however, requires expensive supervision signals. This renders it impractical for applications with only weak supervisions under the Optimal Subset (OS) oracle, the study of which is surprisingly overlooked. In this work, we present a principled yet practical maximum likelihood learning framework, termed as EquiVSet, that simultaneously meets the following desiderata of learning set functions under the OS oracle: i) permutation invariance of the set mass function being modeled; ii) permission of varying ground set; iii) fully differentiability; iv) minimum prior; and v) scalability. The main components of our framework involve: an energy-based treatment of the set mass function, DeepSet-style architectures to handle permutation invariance, mean-field variational inference, and its amortized variants. Although the framework is embarrassingly simple, empirical studies on three real-world applications (including Amazon product recommendation, set anomaly detection and compound selection for virtual screening) demonstrate that EquiVSet outperforms the baselines by a large margin.
A Principled Approach to Failure Analysis and Model Repairment: Demonstration in Medical Imaging
Sep 25, 2021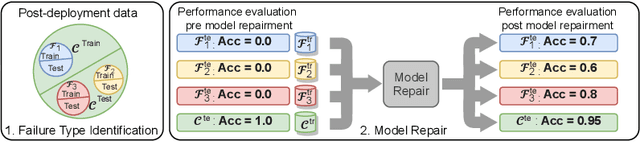
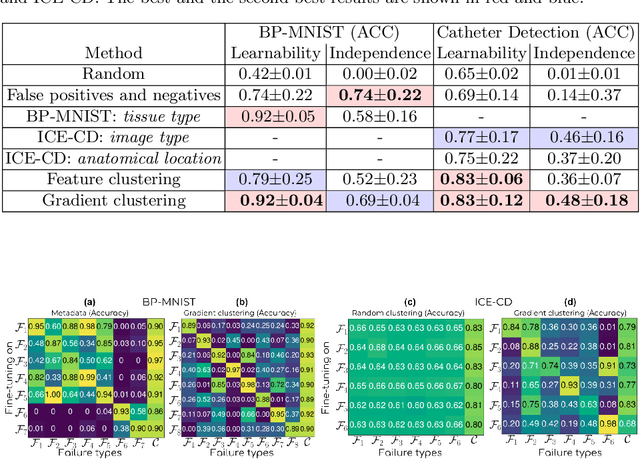
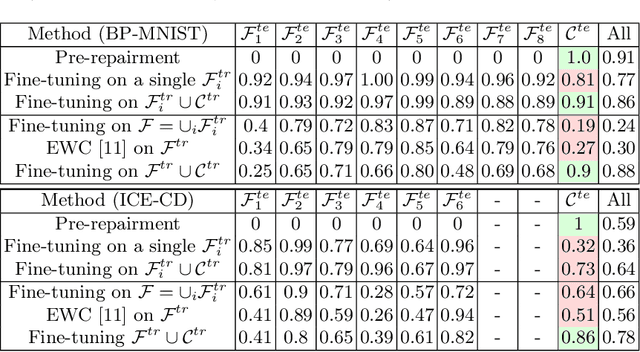
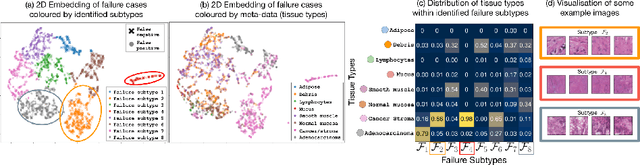
Machine learning models commonly exhibit unexpected failures post-deployment due to either data shifts or uncommon situations in the training environment. Domain experts typically go through the tedious process of inspecting the failure cases manually, identifying failure modes and then attempting to fix the model. In this work, we aim to standardise and bring principles to this process through answering two critical questions: (i) how do we know that we have identified meaningful and distinct failure types?; (ii) how can we validate that a model has, indeed, been repaired? We suggest that the quality of the identified failure types can be validated through measuring the intra- and inter-type generalisation after fine-tuning and introduce metrics to compare different subtyping methods. Furthermore, we argue that a model can be considered repaired if it achieves high accuracy on the failure types while retaining performance on the previously correct data. We combine these two ideas into a principled framework for evaluating the quality of both the identified failure subtypes and model repairment. We evaluate its utility on a classification and an object detection tasks. Our code is available at https://github.com/Rokken-lab6/Failure-Analysis-and-Model-Repairment
Interpreting diffusion score matching using normalizing flow
Jul 21, 2021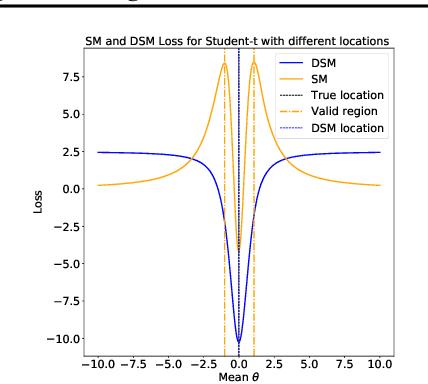
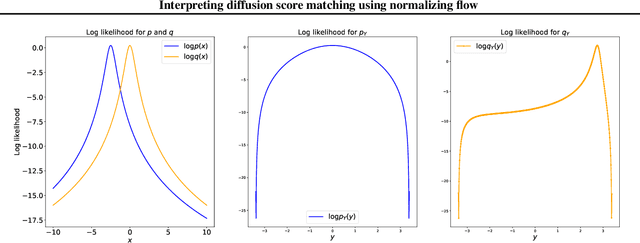
Scoring matching (SM), and its related counterpart, Stein discrepancy (SD) have achieved great success in model training and evaluations. However, recent research shows their limitations when dealing with certain types of distributions. One possible fix is incorporating the original score matching (or Stein discrepancy) with a diffusion matrix, which is called diffusion score matching (DSM) (or diffusion Stein discrepancy (DSD)). However, the lack of interpretation of the diffusion limits its usage within simple distributions and manually chosen matrix. In this work, we plan to fill this gap by interpreting the diffusion matrix using normalizing flows. Specifically, we theoretically prove that DSM (or DSD) is equivalent to the original score matching (or Stein discrepancy) evaluated in the transformed space defined by the normalizing flow, where the diffusion matrix is the inverse of the flow's Jacobian matrix. In addition, we also build its connection to Riemannian manifolds and further extend it to continuous flows, where the change of DSM is characterized by an ODE.
Sparse Uncertainty Representation in Deep Learning with Inducing Weights
May 30, 2021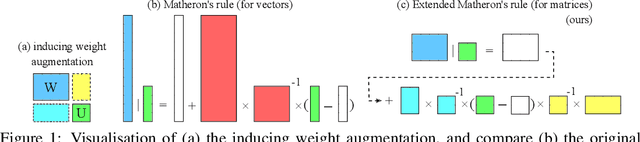

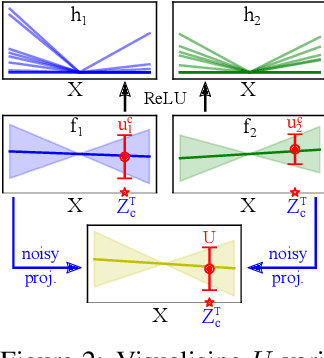
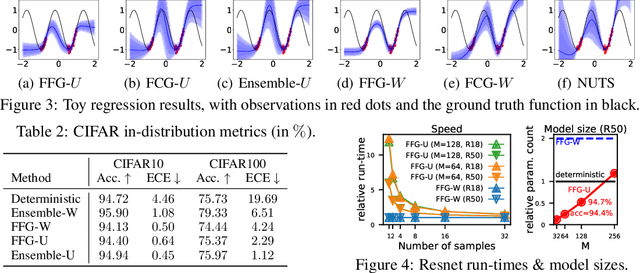
Bayesian neural networks and deep ensembles represent two modern paradigms of uncertainty quantification in deep learning. Yet these approaches struggle to scale mainly due to memory inefficiency issues, since they require parameter storage several times higher than their deterministic counterparts. To address this, we augment the weight matrix of each layer with a small number of inducing weights, thereby projecting the uncertainty quantification into such low dimensional spaces. We further extend Matheron's conditional Gaussian sampling rule to enable fast weight sampling, which enables our inference method to maintain reasonable run-time as compared with ensembles. Importantly, our approach achieves competitive performance to the state-of-the-art in prediction and uncertainty estimation tasks with fully connected neural networks and ResNets, while reducing the parameter size to $\leq 24.3\%$ of that of a $single$ neural network.
Contextual HyperNetworks for Novel Feature Adaptation
Apr 12, 2021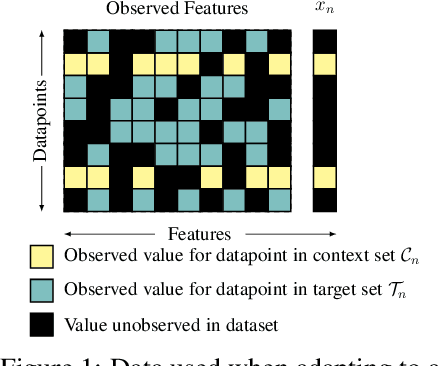
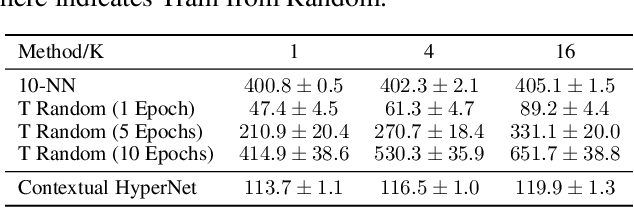
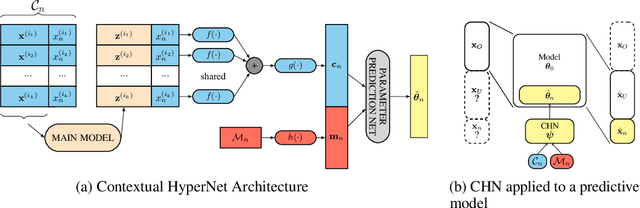
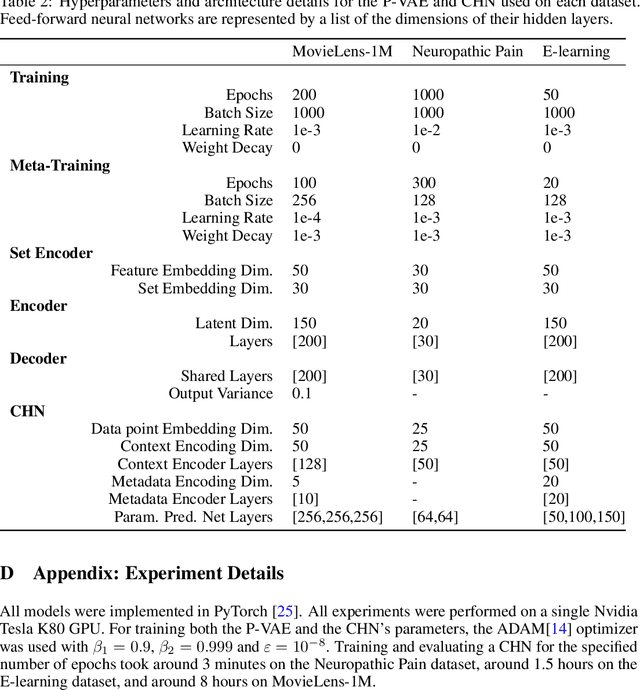
While deep learning has obtained state-of-the-art results in many applications, the adaptation of neural network architectures to incorporate new output features remains a challenge, as neural networks are commonly trained to produce a fixed output dimension. This issue is particularly severe in online learning settings, where new output features, such as items in a recommender system, are added continually with few or no associated observations. As such, methods for adapting neural networks to novel features which are both time and data-efficient are desired. To address this, we propose the Contextual HyperNetwork (CHN), an auxiliary model which generates parameters for extending the base model to a new feature, by utilizing both existing data as well as any observations and/or metadata associated with the new feature. At prediction time, the CHN requires only a single forward pass through a neural network, yielding a significant speed-up when compared to re-training and fine-tuning approaches. To assess the performance of CHNs, we use a CHN to augment a partial variational autoencoder (P-VAE), a deep generative model which can impute the values of missing features in sparsely-observed data. We show that this system obtains improved few-shot learning performance for novel features over existing imputation and meta-learning baselines across recommender systems, e-learning, and healthcare tasks.
Active Slices for Sliced Stein Discrepancy
Feb 08, 2021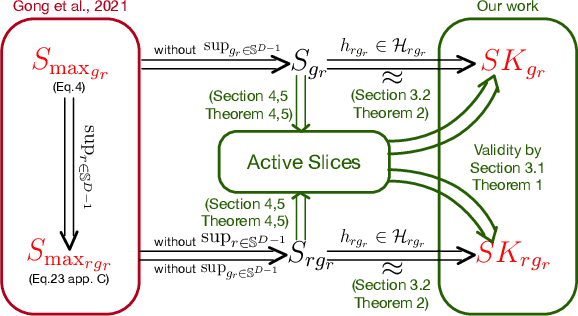
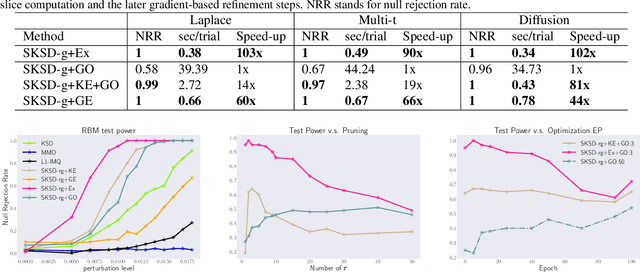
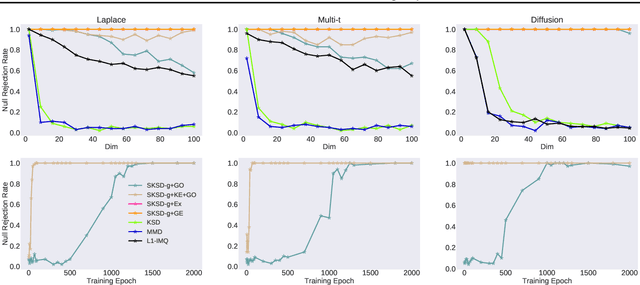

Sliced Stein discrepancy (SSD) and its kernelized variants have demonstrated promising successes in goodness-of-fit tests and model learning in high dimensions. Despite their theoretical elegance, their empirical performance depends crucially on the search of optimal slicing directions to discriminate between two distributions. Unfortunately, previous gradient-based optimisation approaches for this task return sub-optimal results: they are computationally expensive, sensitive to initialization, and they lack theoretical guarantees for convergence. We address these issues in two steps. First, we provide theoretical results stating that the requirement of using optimal slicing directions in the kernelized version of SSD can be relaxed, validating the resulting discrepancy with finite random slicing directions. Second, given that good slicing directions are crucial for practical performance, we propose a fast algorithm for finding such slicing directions based on ideas of active sub-space construction and spectral decomposition. Experiments on goodness-of-fit tests and model learning show that our approach achieves both improved performance and faster convergence. Especially, we demonstrate a 14-80x speed-up in goodness-of-fit tests when comparing with gradient-based alternatives.
Combining Deep Generative Models and Multi-lingual Pretraining for Semi-supervised Document Classification
Jan 26, 2021
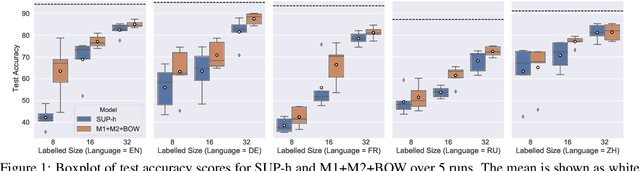
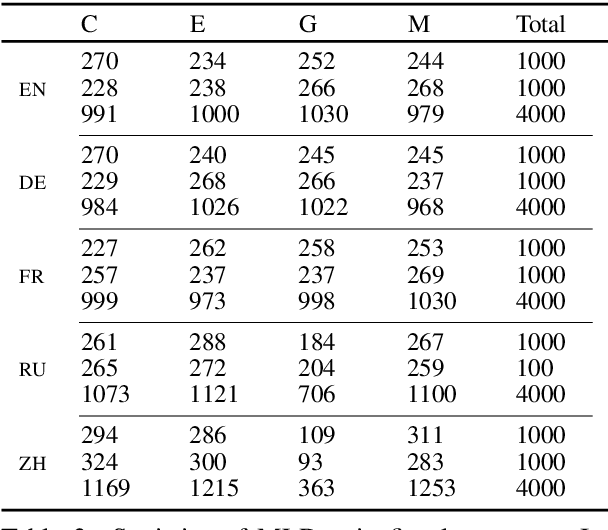
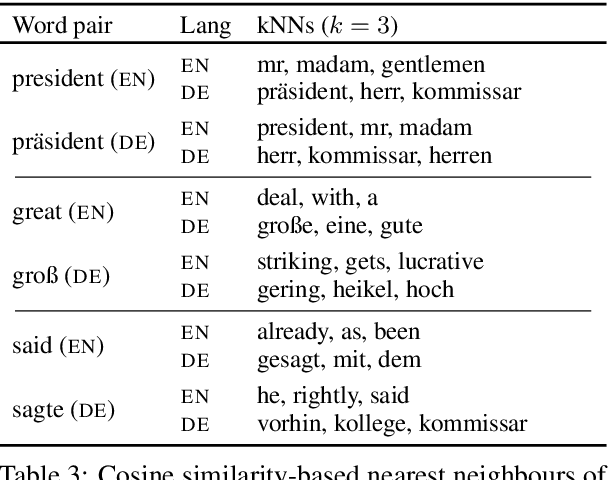
Semi-supervised learning through deep generative models and multi-lingual pretraining techniques have orchestrated tremendous success across different areas of NLP. Nonetheless, their development has happened in isolation, while the combination of both could potentially be effective for tackling task-specific labelled data shortage. To bridge this gap, we combine semi-supervised deep generative models and multi-lingual pretraining to form a pipeline for document classification task. Compared to strong supervised learning baselines, our semi-supervised classification framework is highly competitive and outperforms the state-of-the-art counterparts in low-resource settings across several languages.
Reinforcement Learning with Efficient Active Feature Acquisition
Nov 02, 2020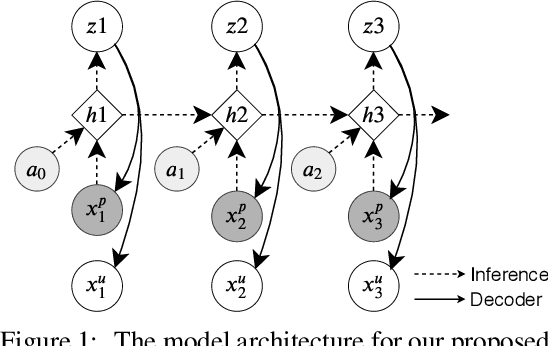
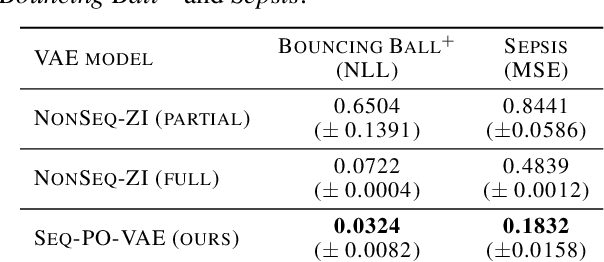
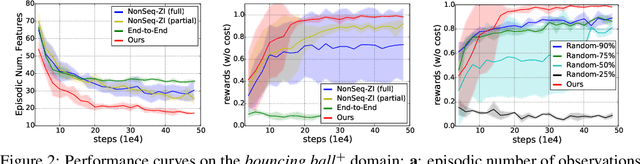

Solving real-life sequential decision making problems under partial observability involves an exploration-exploitation problem. To be successful, an agent needs to efficiently gather valuable information about the state of the world for making rewarding decisions. However, in real-life, acquiring valuable information is often highly costly, e.g., in the medical domain, information acquisition might correspond to performing a medical test on a patient. This poses a significant challenge for the agent to perform optimally for the task while reducing the cost for information acquisition. In this paper, we propose a model-based reinforcement learning framework that learns an active feature acquisition policy to solve the exploration-exploitation problem during its execution. Key to the success is a novel sequential variational auto-encoder that learns high-quality representations from partially observed states, which are then used by the policy to maximize the task reward in a cost efficient manner. We demonstrate the efficacy of our proposed framework in a control domain as well as using a medical simulator. In both tasks, our proposed method outperforms conventional baselines and results in policies with greater cost efficiency.
A Study on Efficiency in Continual Learning Inspired by Human Learning
Oct 28, 2020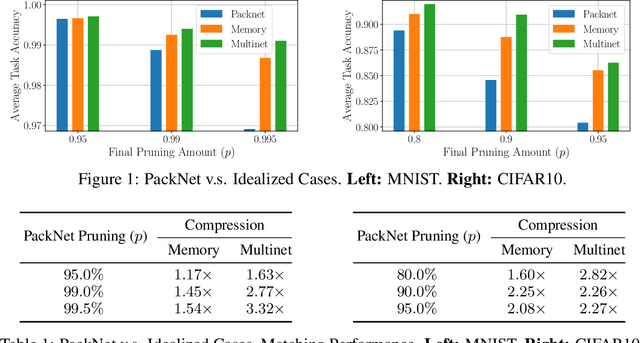

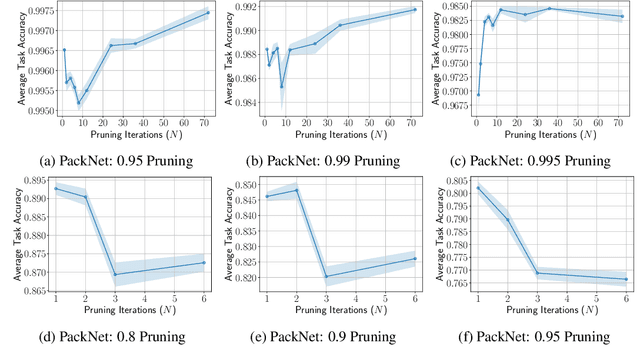
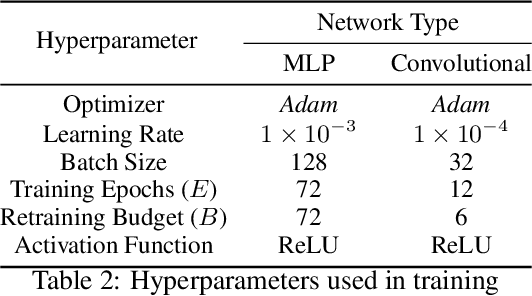
Humans are efficient continual learning systems; we continually learn new skills from birth with finite cells and resources. Our learning is highly optimized both in terms of capacity and time while not suffering from catastrophic forgetting. In this work we study the efficiency of continual learning systems, taking inspiration from human learning. In particular, inspired by the mechanisms of sleep, we evaluate popular pruning-based continual learning algorithms, using PackNet as a case study. First, we identify that weight freezing, which is used in continual learning without biological justification, can result in over $2\times$ as many weights being used for a given level of performance. Secondly, we note the similarity in human day and night time behaviors to the training and pruning phases respectively of PackNet. We study a setting where the pruning phase is given a time budget, and identify connections between iterative pruning and multiple sleep cycles in humans. We show there exists an optimal choice of iteration v.s. epochs given different tasks.
Hierarchical Sparse Variational Autoencoder for Text Encoding
Sep 25, 2020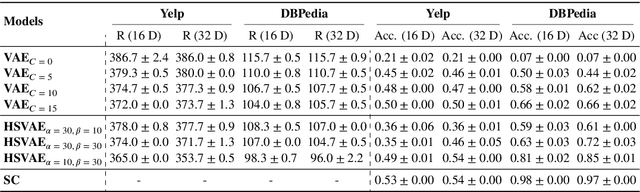
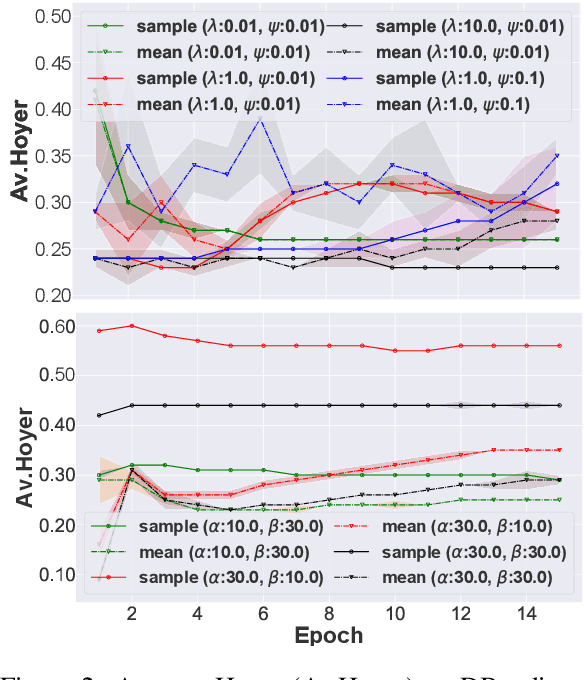

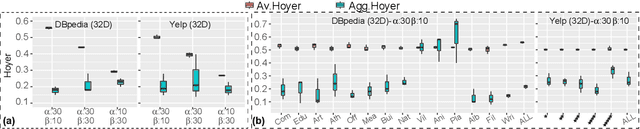
In this paper we focus on unsupervised representation learning and propose a novel framework, Hierarchical Sparse Variational Autoencoder (HSVAE), that imposes sparsity on sentence representations via direct optimisation of Evidence Lower Bound (ELBO). Our experimental results illustrate that HSVAE is flexible and adapts nicely to the underlying characteristics of the corpus which is reflected by the level of sparsity and its distributional patterns.