 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Principled Approach to Failure Analysis and Model Repairment: Demonstration in Medical Imaging
Sep 25, 2021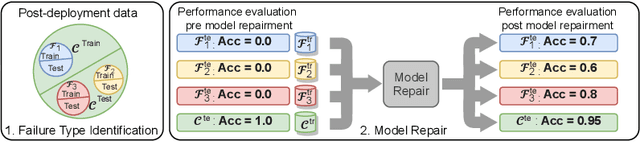
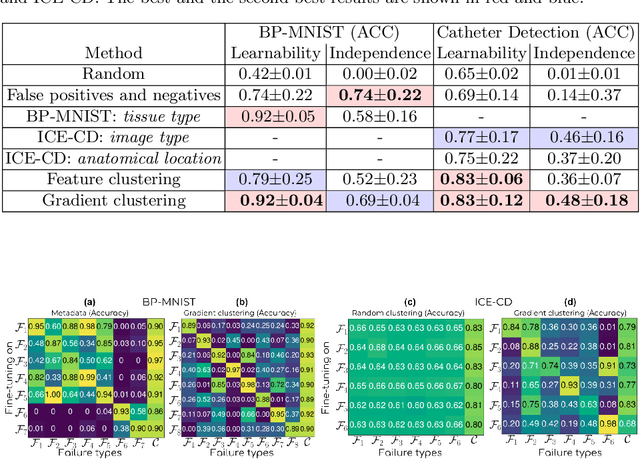
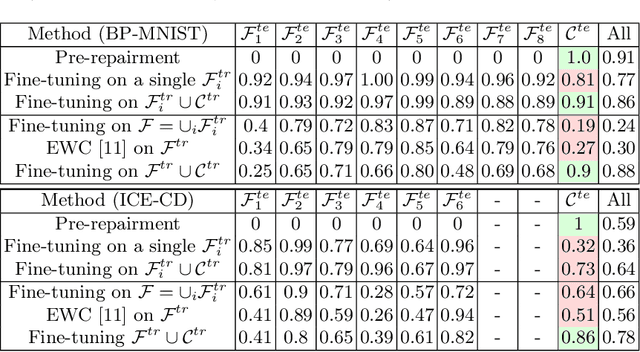
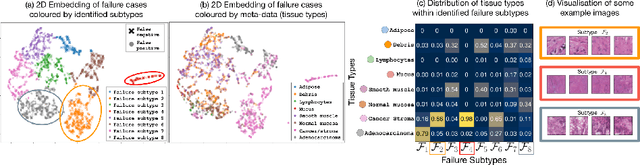
Machine learning models commonly exhibit unexpected failures post-deployment due to either data shifts or uncommon situations in the training environment. Domain experts typically go through the tedious process of inspecting the failure cases manually, identifying failure modes and then attempting to fix the model. In this work, we aim to standardise and bring principles to this process through answering two critical questions: (i) how do we know that we have identified meaningful and distinct failure types?; (ii) how can we validate that a model has, indeed, been repaired? We suggest that the quality of the identified failure types can be validated through measuring the intra- and inter-type generalisation after fine-tuning and introduce metrics to compare different subtyping methods. Furthermore, we argue that a model can be considered repaired if it achieves high accuracy on the failure types while retaining performance on the previously correct data. We combine these two ideas into a principled framework for evaluating the quality of both the identified failure subtypes and model repairment. We evaluate its utility on a classification and an object detection tasks. Our code is available at https://github.com/Rokken-lab6/Failure-Analysis-and-Model-Repairment
Apparel Recommender System based on Bilateral image shape features
May 04, 2021


Probabilistic matrix factorization (PMF) is a well-known model of recommender systems. With the development of image recognition technology, some PMF recommender systems that combine images have emerged. Some of these systems use the image shape features of the recommended products to achieve better results compared to those of the traditional PMF. However, in the existing methods, no PMF recommender system can combine the image features of products previously purchased by customers and of recommended products. Thus, this study proposes a novel probabilistic model that integrates double convolutional neural networks (CNNs) into PMF. For apparel goods, two trained CNNs from the image shape features of users and items are combined, and the latent variables of users and items are optimized based on the vectorized features of CNNs and ratings. Extensive experiments show that our model predicts outcome more accurately than do other recommender models.