 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonte Carlo Linear Clustering with Single-Point Supervision is Enough for Infrared Small Target Detection
Apr 10, 2023



Single-frame infrared small target (SIRST) detection aims at separating small targets from clutter backgrounds on infrared images. Recently, deep learning based methods have achieved promising performance on SIRST detection, but at the cost of a large amount of training data with expensive pixel-level annotations. To reduce the annotation burden, we propose the first method to achieve SIRST detection with single-point supervision. The core idea of this work is to recover the per-pixel mask of each target from the given single point label by using clustering approaches, which looks simple but is indeed challenging since targets are always insalient and accompanied with background clutters. To handle this issue, we introduce randomness to the clustering process by adding noise to the input images, and then obtain much more reliable pseudo masks by averaging the clustered results. Thanks to this "Monte Carlo" clustering approach, our method can accurately recover pseudo masks and thus turn arbitrary fully supervised SIRST detection networks into weakly supervised ones with only single point annotation. Experiments on four datasets demonstrate that our method can be applied to existing SIRST detection networks to achieve comparable performance with their fully supervised counterparts, which reveals that single-point supervision is strong enough for SIRST detection. Our code will be available at: https://github.com/YeRen123455/SIRST-Single-Point-Supervision.
Mapping Degeneration Meets Label Evolution: Learning Infrared Small Target Detection with Single Point Supervision
Apr 04, 2023



Training a convolutional neural network (CNN) to detect infrared small targets in a fully supervised manner has gained remarkable research interests in recent years, but is highly labor expensive since a large number of per-pixel annotations are required. To handle this problem, in this paper, we make the first attempt to achieve infrared small target detection with point-level supervision. Interestingly, during the training phase supervised by point labels, we discover that CNNs first learn to segment a cluster of pixels near the targets, and then gradually converge to predict groundtruth point labels. Motivated by this "mapping degeneration" phenomenon, we propose a label evolution framework named label evolution with single point supervision (LESPS) to progressively expand the point label by leveraging the intermediate predictions of CNNs. In this way, the network predictions can finally approximate the updated pseudo labels, and a pixel-level target mask can be obtained to train CNNs in an end-to-end manner. We conduct extensive experiments with insightful visualizations to validate the effectiveness of our method. Experimental results show that CNNs equipped with LESPS can well recover the target masks from corresponding point labels, {and can achieve over 70% and 95% of their fully supervised performance in terms of pixel-level intersection over union (IoU) and object-level probability of detection (Pd), respectively. Code is available at https://github.com/XinyiYing/LESPS.
You Only Train Once: Learning a General Anomaly Enhancement Network with Random Masks for Hyperspectral Anomaly Detection
Mar 31, 2023



In this paper, we introduce a new approach to address the challenge of generalization in hyperspectral anomaly detection (AD). Our method eliminates the need for adjusting parameters or retraining on new test scenes as required by most existing methods. Employing an image-level training paradigm, we achieve a general anomaly enhancement network for hyperspectral AD that only needs to be trained once. Trained on a set of anomaly-free hyperspectral images with random masks, our network can learn the spatial context characteristics between anomalies and background in an unsupervised way. Additionally, a plug-and-play model selection module is proposed to search for a spatial-spectral transform domain that is more suitable for AD task than the original data. To establish a unified benchmark to comprehensively evaluate our method and existing methods, we develop a large-scale hyperspectral AD dataset (HAD100) that includes 100 real test scenes with diverse anomaly targets. In comparison experiments, we combine our network with a parameter-free detector and achieve the optimal balance between detection accuracy and inference speed among state-of-the-art AD methods. Experimental results also show that our method still achieves competitive performance when the training and test set are captured by different sensor devices. Our code is available at https://github.com/ZhaoxuLi123/AETNet.
Learning Non-Local Spatial-Angular Correlation for Light Field Image Super-Resolution
Feb 18, 2023



Exploiting spatial-angular correlation is crucial to light field (LF) image super-resolution (SR), but is highly challenging due to its non-local property caused by the disparities among LF images. Although many deep neural networks (DNNs) have been developed for LF image SR and achieved continuously improved performance, existing methods cannot well leverage the long-range spatial-angular correlation and thus suffer a significant performance drop when handling scenes with large disparity variations. In this paper, we propose a simple yet effective method to learn the non-local spatial-angular correlation for LF image SR. In our method, we adopt the epipolar plane image (EPI) representation to project the 4D spatial-angular correlation onto multiple 2D EPI planes, and then develop a Transformer network with repetitive self-attention operations to learn the spatial-angular correlation by modeling the dependencies between each pair of EPI pixels. Our method can fully incorporate the information from all angular views while achieving a global receptive field along the epipolar line. We conduct extensive experiments with insightful visualizations to validate the effectiveness of our method. Comparative results on five public datasets show that our method not only achieves state-of-the-art SR performance, but also performs robust to disparity variations. Code is publicly available at https://github.com/ZhengyuLiang24/EPIT.
MTU-Net: Multi-level TransUNet for Space-based Infrared Tiny Ship Detection
Sep 28, 2022
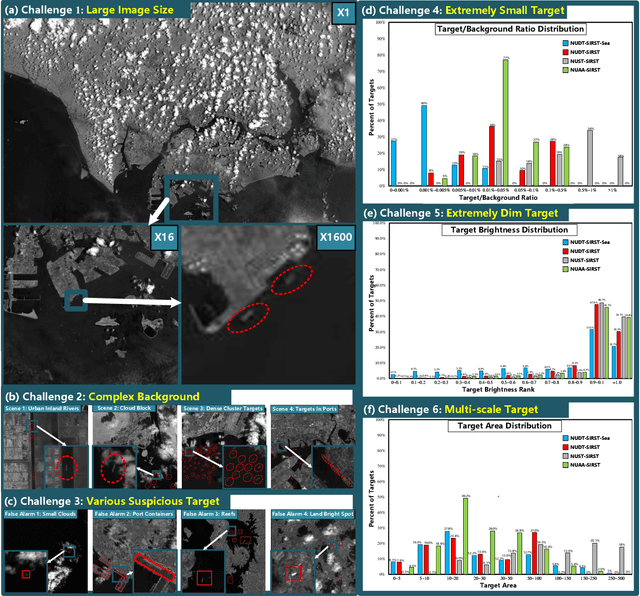
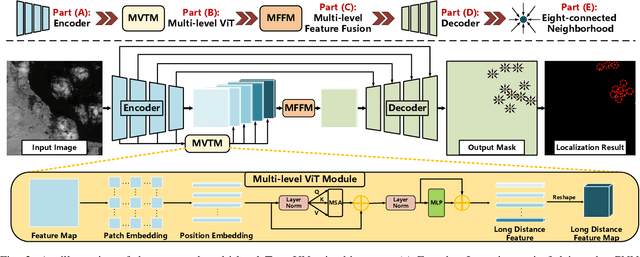
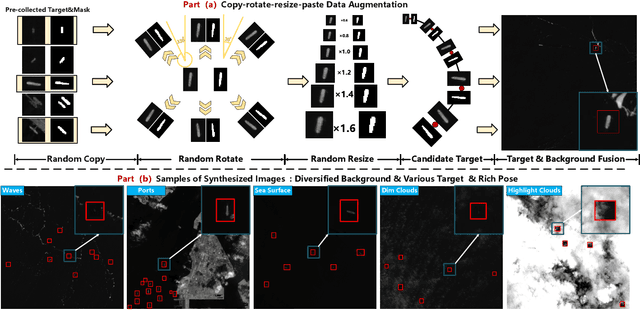
Space-based infrared tiny ship detection aims at separating tiny ships from the images captured by earth orbiting satellites. Due to the extremely large image coverage area (e.g., thousands square kilometers), candidate targets in these images are much smaller, dimer, more changeable than those targets observed by aerial-based and land-based imaging devices. Existing short imaging distance-based infrared datasets and target detection methods cannot be well adopted to the space-based surveillance task. To address these problems, we develop a space-based infrared tiny ship detection dataset (namely, NUDT-SIRST-Sea) with 48 space-based infrared images and 17598 pixel-level tiny ship annotations. Each image covers about 10000 square kilometers of area with 10000X10000 pixels. Considering the extreme characteristics (e.g., small, dim, changeable) of those tiny ships in such challenging scenes, we propose a multi-level TransUNet (MTU-Net) in this paper. Specifically, we design a Vision Transformer (ViT) Convolutional Neural Network (CNN) hybrid encoder to extract multi-level features. Local feature maps are first extracted by several convolution layers and then fed into the multi-level feature extraction module (MVTM) to capture long-distance dependency. We further propose a copy-rotate-resize-paste (CRRP) data augmentation approach to accelerate the training phase, which effectively alleviates the issue of sample imbalance between targets and background. Besides, we design a FocalIoU loss to achieve both target localization and shape description. Experimental results on the NUDT-SIRST-Sea dataset show that our MTU-Net outperforms traditional and existing deep learning based SIRST methods in terms of probability of detection, false alarm rate and intersection over union.
Learning Sub-Pixel Disparity Distribution for Light Field Depth Estimation
Aug 20, 2022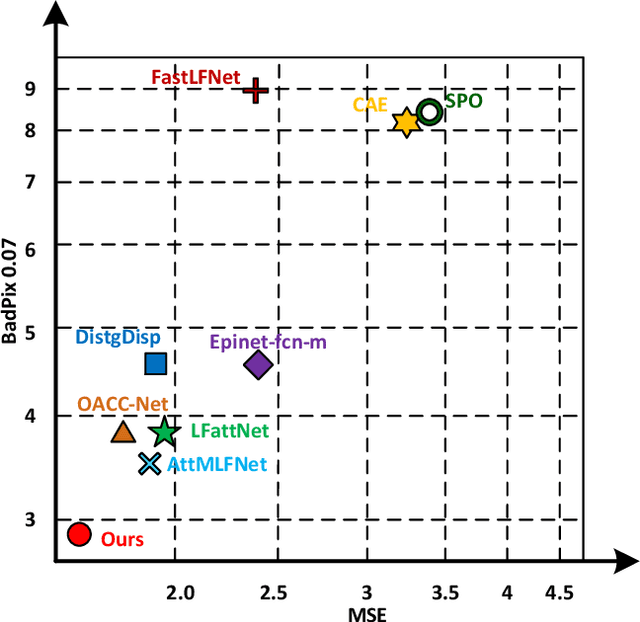
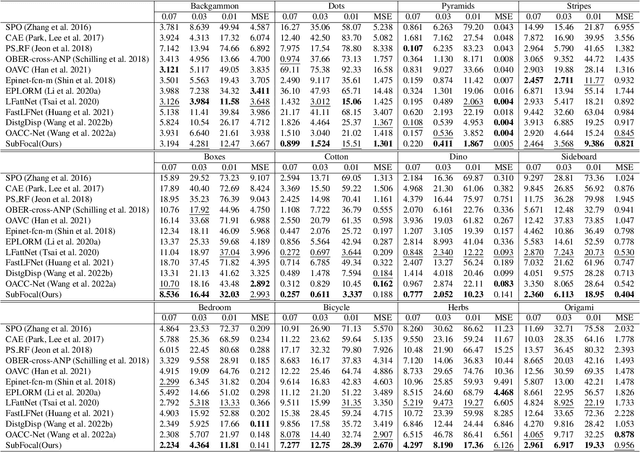
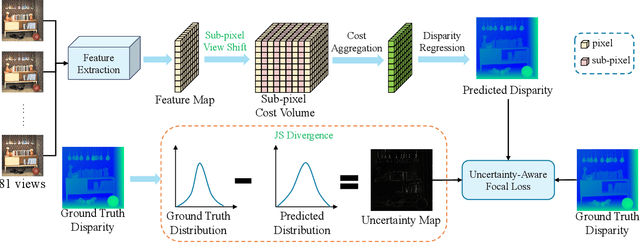
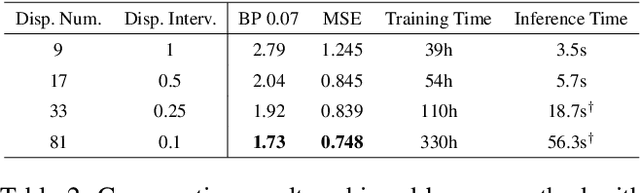
Existing light field (LF) depth estimation methods generally consider depth estimation as a regression problem, supervised by a pixel-wise L1 loss between the regressed disparity map and the groundtruth one. However, the disparity map is only a sub-space projection (i.e., an expectation) of the disparity distribution, while the latter one is more essential for models to learn. In this paper, we propose a simple yet effective method to learn the sub-pixel disparity distribution by fully utilizing the power of deep networks. In our method, we construct the cost volume at sub-pixel level to produce a finer depth distribution and design an uncertainty-aware focal loss to supervise the disparity distribution to be close to the groundtruth one. Extensive experimental results demonstrate the effectiveness of our method. Our method, called SubFocal, ranks the first place among 99 submitted algorithms on the HCI 4D LF Benchmark in terms of all the five accuracy metrics (i.e., BadPix0.01, BadPix0.03, BadPix0.07, MSE and Q25), and significantly outperforms recent state-of-the-art LF depth methods such as OACC-Net and AttMLFNet. Code and model are available at https://github.com/chaowentao/SubFocal.
Learning a Degradation-Adaptive Network for Light Field Image Super-Resolution
Jun 13, 2022



Recent years have witnessed the great advances of deep neural networks (DNNs) in light field (LF) image super-resolution (SR). However, existing DNN-based LF image SR methods are developed on a single fixed degradation (e.g., bicubic downsampling), and thus cannot be applied to super-resolve real LF images with diverse degradations. In this paper, we propose the first method to handle LF image SR with multiple degradations. In our method, a practical LF degradation model that considers blur and noise is developed to approximate the degradation process of real LF images. Then, a degradation-adaptive network (LF-DAnet) is designed to incorporate the degradation prior into the SR process. By training on LF images with multiple synthetic degradations, our method can learn to adapt to different degradations while incorporating the spatial and angular information. Extensive experiments on both synthetically degraded and real-world LFs demonstrate the effectiveness of our method. Compared with existing state-of-the-art single and LF image SR methods, our method achieves superior SR performance under a wide range of degradations, and generalizes better to real LF images. Codes and models are available at https://github.com/YingqianWang/LF-DAnet.
NTIRE 2022 Challenge on Stereo Image Super-Resolution: Methods and Results
Apr 20, 2022
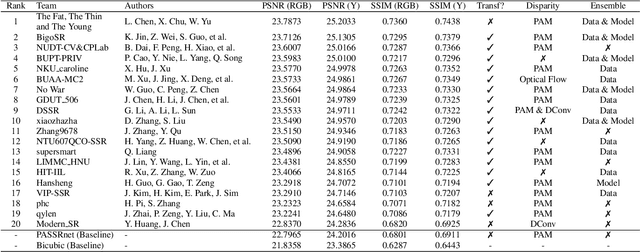
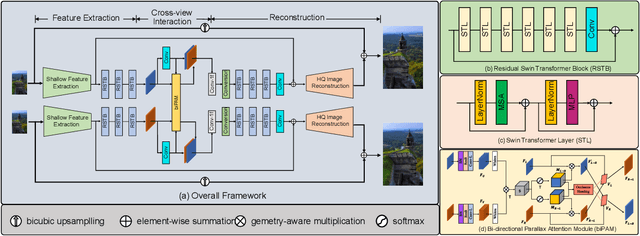
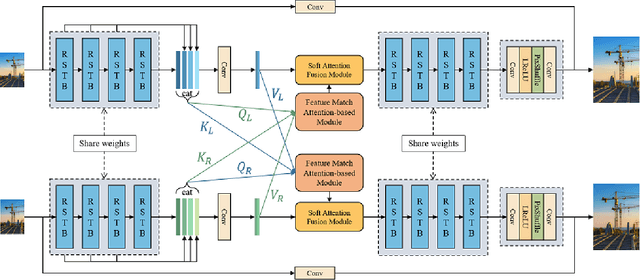
In this paper, we summarize the 1st NTIRE challenge on stereo image super-resolution (restoration of rich details in a pair of low-resolution stereo images) with a focus on new solutions and results. This challenge has 1 track aiming at the stereo image super-resolution problem under a standard bicubic degradation. In total, 238 participants were successfully registered, and 21 teams competed in the final testing phase. Among those participants, 20 teams successfully submitted results with PSNR (RGB) scores better than the baseline. This challenge establishes a new benchmark for stereo image SR.
Occlusion-Aware Cost Constructor for Light Field Depth Estimation
Mar 03, 2022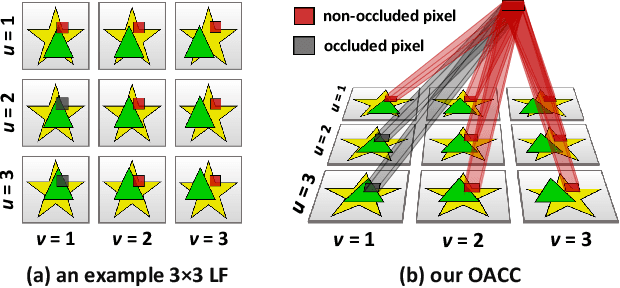

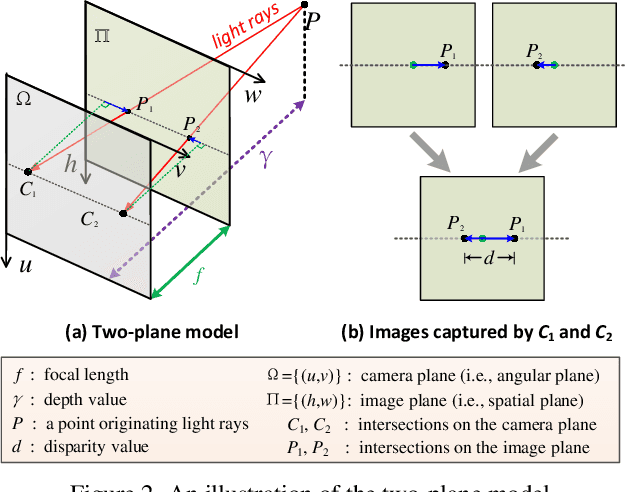
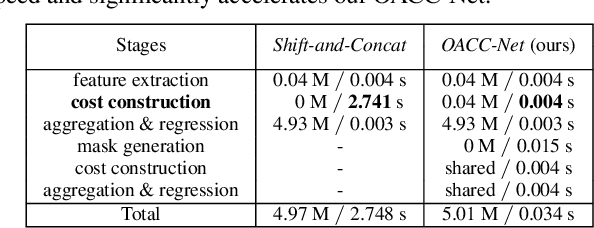
Matching cost construction is a key step in light field (LF) depth estimation, but was rarely studied in the deep learning era. Recent deep learning-based LF depth estimation methods construct matching cost by sequentially shifting each sub-aperture image (SAI) with a series of predefined offsets, which is complex and time-consuming. In this paper, we propose a simple and fast cost constructor to construct matching cost for LF depth estimation. Our cost constructor is composed by a series of convolutions with specifically designed dilation rates. By applying our cost constructor to SAI arrays, pixels under predefined disparities can be integrated and matching cost can be constructed without using any shifting operation. More importantly, the proposed cost constructor is occlusion-aware and can handle occlusions by dynamically modulating pixels from different views. Based on the proposed cost constructor, we develop a deep network for LF depth estimation. Our network ranks first on the commonly used 4D LF benchmark in terms of the mean square error (MSE), and achieves a faster running time than other state-of-the-art methods.
Disentangling Light Fields for Super-Resolution and Disparity Estimation
Feb 22, 2022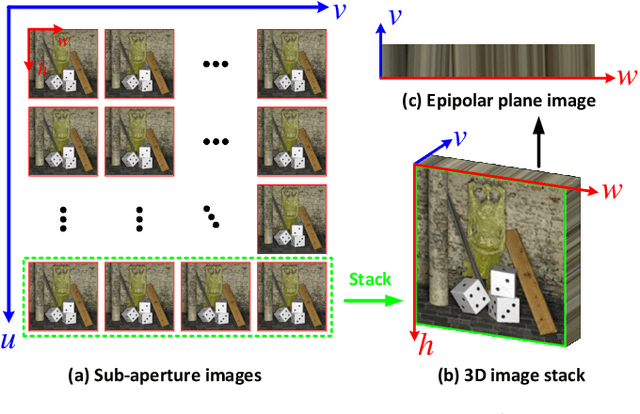
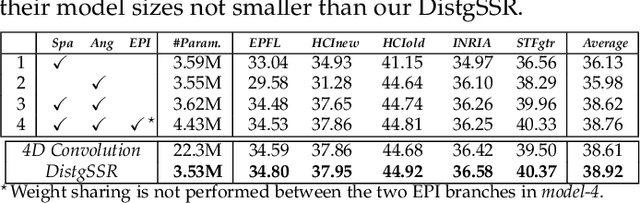
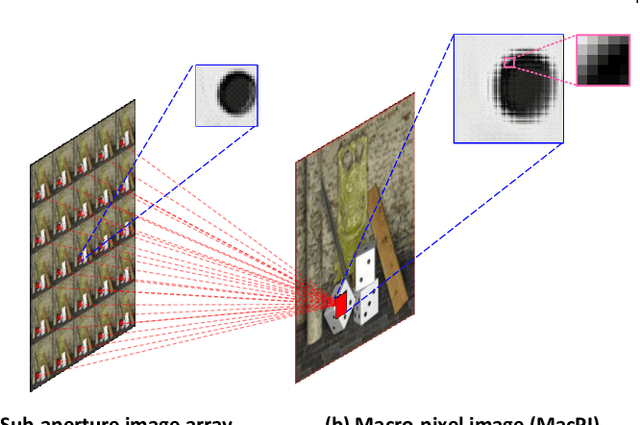
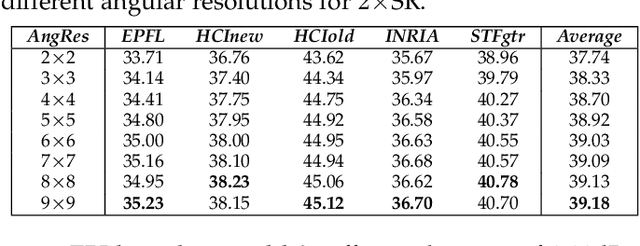
Light field (LF) cameras record both intensity and directions of light rays, and encode 3D scenes into 4D LF images. Recently, many convolutional neural networks (CNNs) have been proposed for various LF image processing tasks. However, it is challenging for CNNs to effectively process LF images since the spatial and angular information are highly inter-twined with varying disparities. In this paper, we propose a generic mechanism to disentangle these coupled information for LF image processing. Specifically, we first design a class of domain-specific convolutions to disentangle LFs from different dimensions, and then leverage these disentangled features by designing task-specific modules. Our disentangling mechanism can well incorporate the LF structure prior and effectively handle 4D LF data. Based on the proposed mechanism, we develop three networks (i.e., DistgSSR, DistgASR and DistgDisp) for spatial super-resolution, angular super-resolution and disparity estimation. Experimental results show that our networks achieve state-of-the-art performance on all these three tasks, which demonstrates the effectiveness, efficiency, and generality of our disentangling mechanism. Project page: https://yingqianwang.github.io/DistgLF/.