 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Content is Goliath and Algorithm is David: The Style and Semantic Effects of Generative Search Engine
Sep 17, 2025



Generative search engines (GEs) leverage large language models (LLMs) to deliver AI-generated summaries with website citations, establishing novel traffic acquisition channels while fundamentally altering the search engine optimization landscape. To investigate the distinctive characteristics of GEs, we collect data through interactions with Google's generative and conventional search platforms, compiling a dataset of approximately ten thousand websites across both channels. Our empirical analysis reveals that GEs exhibit preferences for citing content characterized by significantly higher predictability for underlying LLMs and greater semantic similarity among selected sources. Through controlled experiments utilizing retrieval augmented generation (RAG) APIs, we demonstrate that these citation preferences emerge from intrinsic LLM tendencies to favor content aligned with their generative expression patterns. Motivated by applications of LLMs to optimize website content, we conduct additional experimentation to explore how LLM-based content polishing by website proprietors alters AI summaries, finding that such polishing paradoxically enhances information diversity within AI summaries. Finally, to assess the user-end impact of LLM-induced information increases, we design a generative search engine and recruit Prolific participants to conduct a randomized controlled experiment involving an information-seeking and writing task. We find that higher-educated users exhibit minimal changes in their final outputs' information diversity but demonstrate significantly reduced task completion time when original sites undergo polishing. Conversely, lower-educated users primarily benefit through enhanced information density in their task outputs while maintaining similar completion times across experimental groups.
Towards Data Valuation via Asymmetric Data Shapley
Nov 01, 2024As data emerges as a vital driver of technological and economic advancements, a key challenge is accurately quantifying its value in algorithmic decision-making. The Shapley value, a well-established concept from cooperative game theory, has been widely adopted to assess the contribution of individual data sources in supervised machine learning. However, its symmetry axiom assumes all players in the cooperative game are homogeneous, which overlooks the complex structures and dependencies present in real-world datasets. To address this limitation, we extend the traditional data Shapley framework to asymmetric data Shapley, making it flexible enough to incorporate inherent structures within the datasets for structure-aware data valuation. We also introduce an efficient $k$-nearest neighbor-based algorithm for its exact computation. We demonstrate the practical applicability of our framework across various machine learning tasks and data market contexts. The code is available at: https://github.com/xzheng01/Asymmetric-Data-Shapley.
Modeling Reference-dependent Choices with Graph Neural Networks
Aug 21, 2024



While the classic Prospect Theory has highlighted the reference-dependent and comparative nature of consumers' product evaluation processes, few models have successfully integrated this theoretical hypothesis into data-driven preference quantification, particularly in the realm of recommender systems development. To bridge this gap, we propose a new research problem of modeling reference-dependent preferences from a data-driven perspective, and design a novel deep learning-based framework named Attributed Reference-dependent Choice Model for Recommendation (ArcRec) to tackle the inherent challenges associated with this problem. ArcRec features in building a reference network from aggregated historical purchase records for instantiating theoretical reference points, which is then decomposed into product attribute specific sub-networks and represented through Graph Neural Networks. In this way, the reference points of a consumer can be encoded at the attribute-level individually from her past experiences but also reflect the crowd influences. ArcRec also makes novel contributions to quantifying consumers' reference-dependent preferences using a deep neural network-based utility function that integrates both interest-inspired and price-inspired preferences, with their complex interaction effects captured by an attribute-aware price sensitivity mechanism. Most importantly, ArcRec introduces a novel Attribute-level Willingness-To-Pay measure to the reference-dependent utility function, which captures a consumer's heterogeneous salience of product attributes via observing her attribute-level price tolerance to a product. Empirical evaluations on both synthetic and real-world online shopping datasets demonstrate ArcRec's superior performances over fourteen state-of-the-art baselines.
Crafting Knowledge: Exploring the Creative Mechanisms of Chat-Based Search Engines
Feb 29, 2024



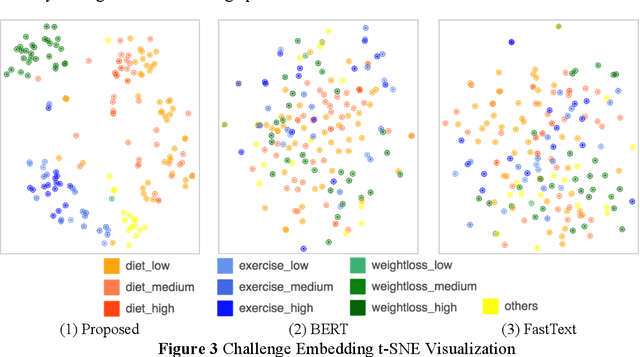
In the domain of digital information dissemination, search engines act as pivotal conduits linking information seekers with providers. The advent of chat-based search engines utilizing Large Language Models (LLMs) and Retrieval Augmented Generation (RAG), exemplified by Bing Chat, marks an evolutionary leap in the search ecosystem. They demonstrate metacognitive abilities in interpreting web information and crafting responses with human-like understanding and creativity. Nonetheless, the intricate nature of LLMs renders their "cognitive" processes opaque, challenging even their designers' understanding. This research aims to dissect the mechanisms through which an LLM-powered chat-based search engine, specifically Bing Chat, selects information sources for its responses. To this end, an extensive dataset has been compiled through engagements with New Bing, documenting the websites it cites alongside those listed by the conventional search engine. Employing natural language processing (NLP) techniques, the research reveals that Bing Chat exhibits a preference for content that is not only readable and formally structured, but also demonstrates lower perplexity levels, indicating a unique inclination towards text that is predictable by the underlying LLM. Further enriching our analysis, we procure an additional dataset through interactions with the GPT-4 based knowledge retrieval API, unveiling a congruent text preference between the RAG API and Bing Chat. This consensus suggests that these text preferences intrinsically emerge from the underlying language models, rather than being explicitly crafted by Bing Chat's developers. Moreover, our investigation documents a greater similarity among websites cited by RAG technologies compared to those ranked highest by conventional search engines.
Algorithmic Collusion or Competition: the Role of Platforms' Recommender Systems
Sep 25, 2023



Recent academic research has extensively examined algorithmic collusion resulting from the utilization of artificial intelligence (AI)-based dynamic pricing algorithms. Nevertheless, e-commerce platforms employ recommendation algorithms to allocate exposure to various products, and this important aspect has been largely overlooked in previous studies on algorithmic collusion. Our study bridges this important gap in the literature and examines how recommendation algorithms can determine the competitive or collusive dynamics of AI-based pricing algorithms. Specifically, two commonly deployed recommendation algorithms are examined: (i) a recommender system that aims to maximize the sellers' total profit (profit-based recommender system) and (ii) a recommender system that aims to maximize the demand for products sold on the platform (demand-based recommender system). We construct a repeated game framework that incorporates both pricing algorithms adopted by sellers and the platform's recommender system. Subsequently, we conduct experiments to observe price dynamics and ascertain the final equilibrium. Experimental results reveal that a profit-based recommender system intensifies algorithmic collusion among sellers due to its congruence with sellers' profit-maximizing objectives. Conversely, a demand-based recommender system fosters price competition among sellers and results in a lower price, owing to its misalignment with sellers' goals. Extended analyses suggest the robustness of our findings in various market scenarios. Overall, we highlight the importance of platforms' recommender systems in delineating the competitive structure of the digital marketplace, providing important insights for market participants and corresponding policymakers.
"Generate" the Future of Work through AI: Empirical Evidence from Online Labor Markets
Aug 09, 2023



With the advent of general-purpose Generative AI, the interest in discerning its impact on the labor market escalates. In an attempt to bridge the extant empirical void, we interpret the launch of ChatGPT as an exogenous shock, and implement a Difference-in-Differences (DID) approach to quantify its influence on text-related jobs and freelancers within an online labor marketplace. Our results reveal a significant decrease in transaction volume for gigs and freelancers directly exposed to ChatGPT. Additionally, this decline is particularly marked in units of relatively higher past transaction volume or lower quality standards. Yet, the negative effect is not universally experienced among service providers. Subsequent analyses illustrate that freelancers proficiently adapting to novel advancements and offering services that augment AI technologies can yield substantial benefits amidst this transformative period. Consequently, even though the advent of ChatGPT could conceivably substitute existing occupations, it also unfolds immense opportunities and carries the potential to reconfigure the future of work. This research contributes to the limited empirical repository exploring the profound influence of LLM-based generative AI on the labor market, furnishing invaluable insights for workers, job intermediaries, and regulatory bodies navigating this evolving landscape.
SR-Affine: High-quality 3D hand model reconstruction from UV Maps
Feb 07, 2021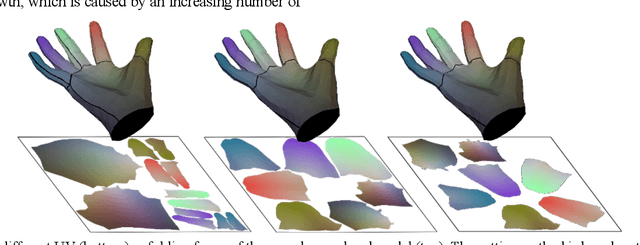

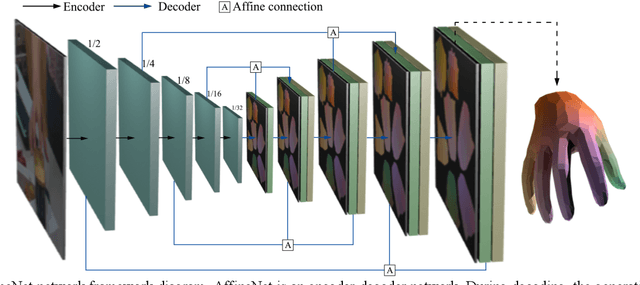

Under various poses and heavy occlusions,3D hand model reconstruction based on a single monocular RGB image has been a challenging problem in computer vision field for many years. In this paper, we propose a SR-Affine approach for high-quality 3D hand model reconstruction. First, we propose an encoder-decoder network architecture (AffineNet) for MANO hand reconstruction. Since MANO hand is not detailed, we further propose SRNet to up-sampling point-clouds by image super-resolution on the UV map. Many experiments demonstrate that our approach is robust and outperforms the state-of-the-art methods on standard benchmarks, including the FreiHAND and HO3D datasets.
Spoiled for Choice? Personalized Recommendation for Healthcare Decisions: A Multi-Armed Bandit Approach
Sep 13, 2020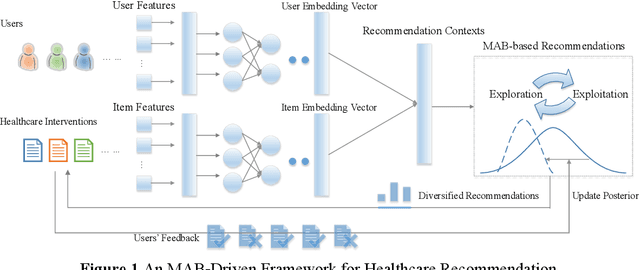

Online healthcare communities provide users with various healthcare interventions to promote healthy behavior and improve adherence. When faced with too many intervention choices, however, individuals may find it difficult to decide which option to take, especially when they lack the experience or knowledge to evaluate different options. The choice overload issue may negatively affect users' engagement in health management. In this study, we take a design-science perspective to propose a recommendation framework that helps users to select healthcare interventions. Taking into account that users' health behaviors can be highly dynamic and diverse, we propose a multi-armed bandit (MAB)-driven recommendation framework, which enables us to adaptively learn users' preference variations while promoting recommendation diversity in the meantime. To better adapt an MAB to the healthcare context, we synthesize two innovative model components based on prominent health theories. The first component is a deep-learning-based feature engineering procedure, which is designed to learn crucial recommendation contexts in regard to users' sequential health histories, health-management experiences, preferences, and intrinsic attributes of healthcare interventions. The second component is a diversity constraint, which structurally diversifies recommendations in different dimensions to provide users with well-rounded support. We apply our approach to an online weight management context and evaluate it rigorously through a series of experiments. Our results demonstrate that each of the design components is effective and that our recommendation design outperforms a wide range of state-of-the-art recommendation systems. Our study contributes to the research on the application of business intelligence and has implications for multiple stakeholders, including online healthcare platforms, policymakers, and users.
Social Media Would Not Lie: Prediction of the 2016 Taiwan Election via Online Heterogeneous Data
Apr 04, 2018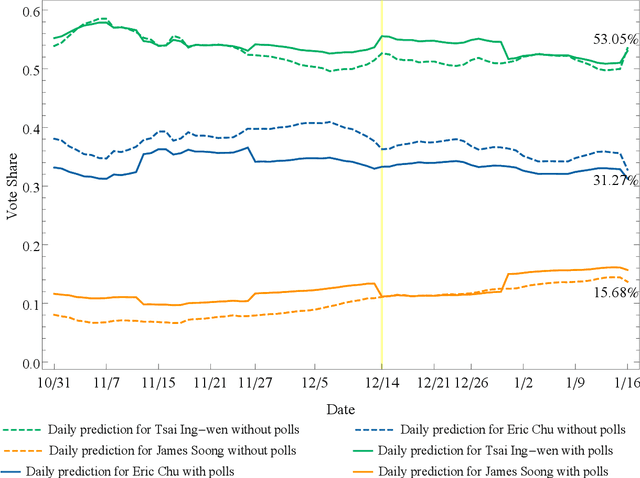
The prevalence of online media has attracted researchers from various domains to explore human behavior and make interesting predictions. In this research, we leverage heterogeneous social media data collected from various online platforms to predict Taiwan's 2016 presidential election. In contrast to most existing research, we take a "signal" view of heterogeneous information and adopt the Kalman filter to fuse multiple signals into daily vote predictions for the candidates. We also consider events that influenced the election in a quantitative manner based on the so-called event study model that originated in the field of financial research. We obtained the following interesting findings. First, public opinions in online media dominate traditional polls in Taiwan election prediction in terms of both predictive power and timeliness. But offline polls can still function on alleviating the sample bias of online opinions. Second, although online signals converge as election day approaches, the simple Facebook "Like" is consistently the strongest indicator of the election result. Third, most influential events have a strong connection to cross-strait relations, and the Chou Tzu-yu flag incident followed by the apology video one day before the election increased the vote share of Tsai Ing-Wen by 3.66%. This research justifies the predictive power of online media in politics and the advantages of information fusion. The combined use of the Kalman filter and the event study method contributes to the data-driven political analytics paradigm for both prediction and attribution purposes.
Generic and Efficient Solution Solves the Shortest Paths Problem in Square Runtime
Nov 29, 2016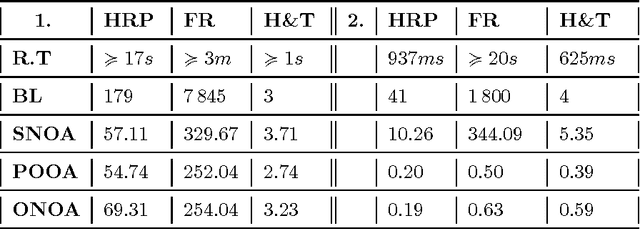
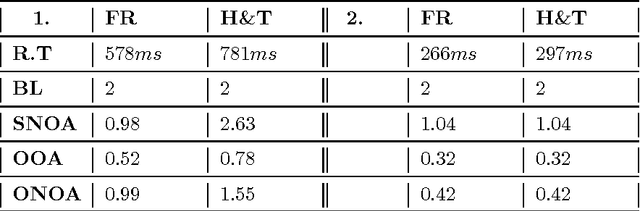
We study a group of new methods to solve an open problem that is the shortest paths problem on a given fix-weighted instance. It is the real significance at a considerable altitude to reach our aim to meet these qualities of generic, efficiency, precision which we generally require to a methodology. Besides our proof to guarantee our measures might work normally, we pay more interest to root out the vital theory about calculation and logic in favor of our extension to range over a wide field about decision, operator, economy, management, robot, AI and etc.