 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatch Before You Answer: Learning from Visually Grounded Post-Training
Apr 06, 2026It is critical for vision-language models (VLMs) to comprehensively understand visual, temporal, and textual cues. However, despite rapid progress in multimodal modeling, video understanding performance still lags behind text-based reasoning. In this work, we find that progress is even worse than previously assumed: commonly reported long video understanding benchmarks contain 40-60% of questions that can be answered using text cues alone. Furthermore, we find that these issues are also pervasive in widely used post-training datasets, potentially undercutting the ability of post-training to improve VLM video understanding performance. Guided by this observation, we introduce VidGround as a simple yet effective solution: using only the actual visually grounded questions without any linguistic biases for post-training. When used in tandem with RL-based post-training algorithms, this simple technique improves performance by up to 6.2 points relative to using the full dataset, while using only 69.1% of the original post-training data. Moreover, we show that data curation with a simple post-training algorithm outperforms several more complex post-training techniques, highlighting that data quality is a major bottleneck for improving video understanding in VLMs. These results underscore the importance of curating post-training data and evaluation benchmarks that truly require visual grounding to advance the development of more capable VLMs. Project page: http://vidground.etuagi.com.
Nanbeige4.1-3B: A Small General Model that Reasons, Aligns, and Acts
Feb 13, 2026We present Nanbeige4.1-3B, a unified generalist language model that simultaneously achieves strong agentic behavior, code generation, and general reasoning with only 3B parameters. To the best of our knowledge, it is the first open-source small language model (SLM) to achieve such versatility in a single model. To improve reasoning and preference alignment, we combine point-wise and pair-wise reward modeling, ensuring high-quality, human-aligned responses. For code generation, we design complexity-aware rewards in Reinforcement Learning, optimizing both correctness and efficiency. In deep search, we perform complex data synthesis and incorporate turn-level supervision during training. This enables stable long-horizon tool interactions, allowing Nanbeige4.1-3B to reliably execute up to 600 tool-call turns for complex problem-solving. Extensive experimental results show that Nanbeige4.1-3B significantly outperforms prior models of similar scale, such as Nanbeige4-3B-2511 and Qwen3-4B, even achieving superior performance compared to much larger models, such as Qwen3-30B-A3B. Our results demonstrate that small models can achieve both broad competence and strong specialization simultaneously, redefining the potential of 3B parameter models.
PACE: Prefix-Protected and Difficulty-Aware Compression for Efficient Reasoning
Feb 12, 2026Language Reasoning Models (LRMs) achieve strong performance by scaling test-time computation but often suffer from ``overthinking'', producing excessively long reasoning traces that increase latency and memory usage. Existing LRMs typically enforce conciseness with uniform length penalties, which over-compress crucial early deduction steps at the sequence level and indiscriminately penalize all queries at the group level. To solve these limitations, we propose \textbf{\model}, a dual-level framework for prefix-protected and difficulty-aware compression under hierarchical supervision. At the sequence level, prefix-protected optimization employs decaying mixed rollouts to maintain valid reasoning paths while promoting conciseness. At the group level, difficulty-aware penalty dynamically scales length constraints based on query complexity, maintaining exploration for harder questions while curbing redundancy on easier ones. Extensive experiments on DeepSeek-R1-Distill-Qwen (1.5B/7B) demonstrate that \model achieves a substantial reduction in token usage (up to \textbf{55.7\%}) while simultaneously improving accuracy (up to \textbf{4.1\%}) on math benchmarks, with generalization ability to code, science, and general domains.
StructEval: Benchmarking LLMs' Capabilities to Generate Structural Outputs
May 26, 2025



As Large Language Models (LLMs) become integral to software development workflows, their ability to generate structured outputs has become critically important. We introduce StructEval, a comprehensive benchmark for evaluating LLMs' capabilities in producing both non-renderable (JSON, YAML, CSV) and renderable (HTML, React, SVG) structured formats. Unlike prior benchmarks, StructEval systematically evaluates structural fidelity across diverse formats through two paradigms: 1) generation tasks, producing structured output from natural language prompts, and 2) conversion tasks, translating between structured formats. Our benchmark encompasses 18 formats and 44 types of task, with novel metrics for format adherence and structural correctness. Results reveal significant performance gaps, even state-of-the-art models like o1-mini achieve only 75.58 average score, with open-source alternatives lagging approximately 10 points behind. We find generation tasks more challenging than conversion tasks, and producing correct visual content more difficult than generating text-only structures.
VideoEval-Pro: Robust and Realistic Long Video Understanding Evaluation
May 20, 2025Large multimodal models (LMMs) have recently emerged as a powerful tool for long video understanding (LVU), prompting the development of standardized LVU benchmarks to evaluate their performance. However, our investigation reveals a rather sober lesson for existing LVU benchmarks. First, most existing benchmarks rely heavily on multiple-choice questions (MCQs), whose evaluation results are inflated due to the possibility of guessing the correct answer; Second, a significant portion of questions in these benchmarks have strong priors to allow models to answer directly without even reading the input video. For example, Gemini-1.5-Pro can achieve over 50\% accuracy given a random frame from a long video on Video-MME. We also observe that increasing the number of frames does not necessarily lead to improvement on existing benchmarks, which is counterintuitive. As a result, the validity and robustness of current LVU benchmarks are undermined, impeding a faithful assessment of LMMs' long-video understanding capability. To tackle this problem, we propose VideoEval-Pro, a realistic LVU benchmark containing questions with open-ended short-answer, which truly require understanding the entire video. VideoEval-Pro assesses both segment-level and full-video understanding through perception and reasoning tasks. By evaluating 21 proprietary and open-source video LMMs, we conclude the following findings: (1) video LMMs show drastic performance ($>$25\%) drops on open-ended questions compared with MCQs; (2) surprisingly, higher MCQ scores do not lead to higher open-ended scores on VideoEval-Pro; (3) compared to other MCQ benchmarks, VideoEval-Pro benefits more from increasing the number of input frames. Our results show that VideoEval-Pro offers a more realistic and reliable measure of long video understanding, providing a clearer view of progress in this domain.
VisualWebInstruct: Scaling up Multimodal Instruction Data through Web Search
Mar 13, 2025



Vision-Language Models have made significant progress on many perception-focused tasks, however, their progress on reasoning-focused tasks seem to be limited due to the lack of high-quality and diverse training data. In this work, we aim to address the scarcity issue of reasoning-focused multimodal datasets. We propose VisualWebInstruct - a novel approach that leverages search engine to create a diverse, and high-quality dataset spanning multiple disciplines like math, physics, finance, chemistry, etc. Starting with meticulously selected 30,000 seed images, we employ Google Image search to identify websites containing similar images. We collect and process the HTMLs from over 700K unique URL sources. Through a pipeline of content extraction, filtering and synthesis, we build a dataset of approximately 900K question-answer pairs, with 40% being visual QA pairs and the rest as text QA pairs. Models fine-tuned on VisualWebInstruct demonstrate significant performance gains: (1) training from Llava-OV-mid shows 10-20% absolute point gains across benchmarks, (2) training from MAmmoTH-VL shows 5% absoluate gain. Our best model MAmmoTH-VL2 shows state-of-the-art performance within the 10B parameter class on MMMU-Pro-std (40.7%), MathVerse (42.6%), and DynaMath (55.7%). These remarkable results highlight the effectiveness of our dataset in enhancing VLMs' reasoning capabilities for complex multimodal tasks.
SPLINE-Net: Sparse Photometric Stereo through Lighting Interpolation and Normal Estimation Networks
May 10, 2019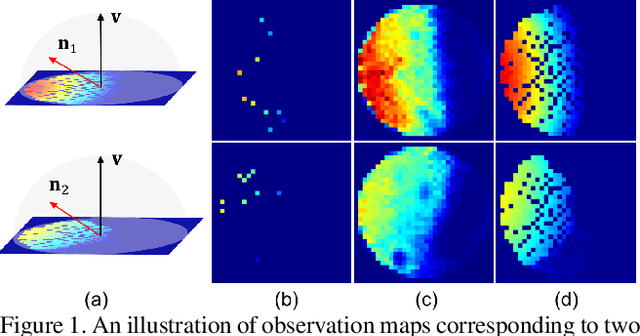
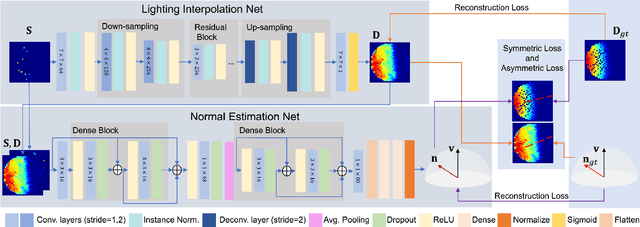
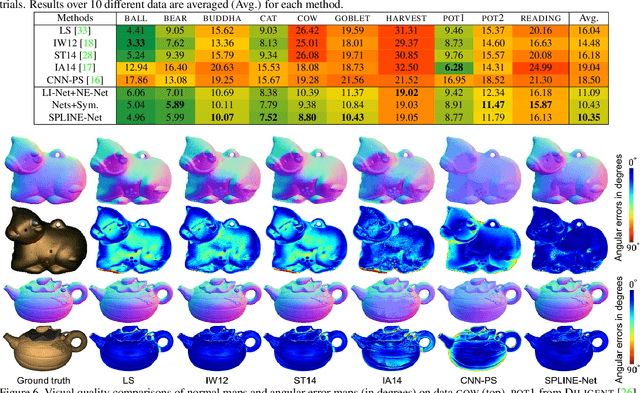
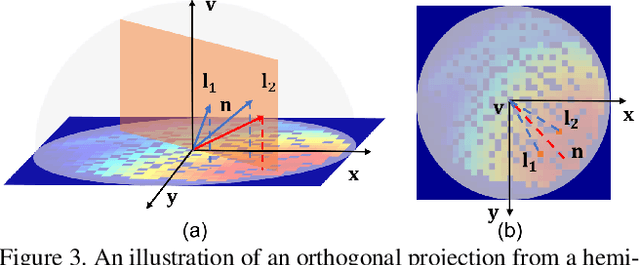
This paper solves the Sparse Photometric stereo through Lighting Interpolation and Normal Estimation using a generative Network (SPLINE-Net). SPLINE-Net contains a lighting interpolation network to generate dense lighting observations given a sparse set of lights as inputs followed by a normal estimation network to estimate surface normals. Both networks are jointly constrained by the proposed symmetric and asymmetric loss functions to enforce isotropic constrain and perform outlier rejection of global illumination effects. SPLINE-Net is verified to outperform existing methods for photometric stereo of general BRDFs by using only ten images of different lights instead of using nearly one hundred images.