 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimuRA: Towards General Goal-Oriented Agent via Simulative Reasoning Architecture with LLM-Based World Model
Jul 31, 2025

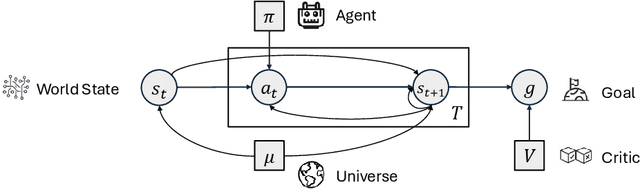

AI agents built on large language models (LLMs) hold enormous promise, but current practice focuses on a one-task-one-agent approach, which not only falls short of scalability and generality, but also suffers from the fundamental limitations of autoregressive LLMs. On the other hand, humans are general agents who reason by mentally simulating the outcomes of their actions and plans. Moving towards a more general and powerful AI agent, we introduce SimuRA, a goal-oriented architecture for generalized agentic reasoning. Based on a principled formulation of optimal agent in any environment, \modelname overcomes the limitations of autoregressive reasoning by introducing a world model for planning via simulation. The generalized world model is implemented using LLM, which can flexibly plan in a wide range of environments using the concept-rich latent space of natural language. Experiments on difficult web browsing tasks show that \modelname improves the success of flight search from 0\% to 32.2\%. World-model-based planning, in particular, shows consistent advantage of up to 124\% over autoregressive planning, demonstrating the advantage of world model simulation as a reasoning paradigm. We are excited about the possibility for training a single, general agent model based on LLMs that can act superintelligently in all environments. To start, we make SimuRA, a web-browsing agent built on \modelname with pretrained LLMs, available as a research demo for public testing.
RestoreGrad: Signal Restoration Using Conditional Denoising Diffusion Models with Jointly Learned Prior
Feb 19, 2025Denoising diffusion probabilistic models (DDPMs) can be utilized for recovering a clean signal from its degraded observation(s) by conditioning the model on the degraded signal. The degraded signals are themselves contaminated versions of the clean signals; due to this correlation, they may encompass certain useful information about the target clean data distribution. However, existing adoption of the standard Gaussian as the prior distribution in turn discards such information, resulting in sub-optimal performance. In this paper, we propose to improve conditional DDPMs for signal restoration by leveraging a more informative prior that is jointly learned with the diffusion model. The proposed framework, called RestoreGrad, seamlessly integrates DDPMs into the variational autoencoder framework and exploits the correlation between the degraded and clean signals to encode a better diffusion prior. On speech and image restoration tasks, we show that RestoreGrad demonstrates faster convergence (5-10 times fewer training steps) to achieve better quality of restored signals over existing DDPM baselines, and improved robustness to using fewer sampling steps in inference time (2-2.5 times fewer), advocating the advantages of leveraging jointly learned prior for efficiency improvements in the diffusion process.
FlexiGPT: Pruning and Extending Large Language Models with Low-Rank Weight Sharing
Jan 24, 2025



The rapid proliferation of large language models (LLMs) in natural language processing (NLP) has created a critical need for techniques that enable efficient deployment on memory-constrained devices without compromising performance. We present a method to prune LLMs that selectively prunes model blocks based on an importance score and replaces them with a low-parameter replacement strategy. Specifically, we propose a principled metric to replace each pruned block using a weight-sharing mechanism that leverages unpruned counterparts from the model and block-specific low-rank adapters. Furthermore, we facilitate the learning of these replacement blocks with output feature normalization and an adapter initialization scheme built on low-rank SVD reconstructions. Empirical evaluations demonstrate substantial performance gains over existing methods, achieving state-of-the-art performance on 5/6 benchmarks for a compression rate of 30% and 6/6 benchmarks for a compression rate of 40%. We also demonstrate that our approach can extend smaller models, boosting performance on 6/6 benchmarks using only ~0.3% tokens of extended training with minimal additional parameter costs.
DISP-LLM: Dimension-Independent Structural Pruning for Large Language Models
Oct 15, 2024Large Language Models (LLMs) have achieved remarkable success in various natural language processing tasks, including language modeling, understanding, and generation. However, the increased memory and computational costs associated with these models pose significant challenges for deployment on resource-limited devices. Structural pruning has emerged as a promising solution to reduce the costs of LLMs without requiring post-processing steps. Prior structural pruning methods either follow the dependence of structures at the cost of limiting flexibility, or introduce non-trivial additional parameters by incorporating different projection matrices. In this work, we propose a novel approach that relaxes the constraint imposed by regular structural pruning methods and eliminates the structural dependence along the embedding dimension. Our dimension-independent structural pruning method offers several benefits. Firstly, our method enables different blocks to utilize different subsets of the feature maps. Secondly, by removing structural dependence, we facilitate each block to possess varying widths along its input and output dimensions, thereby significantly enhancing the flexibility of structural pruning. We evaluate our method on various LLMs, including OPT, LLaMA, LLaMA-2, Phi-1.5, and Phi-2. Experimental results demonstrate that our approach outperforms other state-of-the-art methods, showing for the first time that structural pruning can achieve an accuracy similar to semi-structural pruning.
MoDeGPT: Modular Decomposition for Large Language Model Compression
Aug 20, 2024



Large Language Models (LLMs) have reshaped the landscape of artificial intelligence by demonstrating exceptional performance across various tasks. However, substantial computational requirements make their deployment challenging on devices with limited resources. Recently, compression methods using low-rank matrix techniques have shown promise, yet these often lead to degraded accuracy or introduce significant overhead in parameters and inference latency. This paper introduces \textbf{Mo}dular \textbf{De}composition (MoDeGPT), a novel structured compression framework that does not need recovery fine-tuning while resolving the above drawbacks. MoDeGPT partitions the Transformer block into modules comprised of matrix pairs and reduces the hidden dimensions via reconstructing the module-level outputs. MoDeGPT is developed based on a theoretical framework that utilizes three well-established matrix decomposition algorithms -- Nystr\"om approximation, CR decomposition, and SVD -- and applies them to our redefined transformer modules. Our comprehensive experiments show MoDeGPT, without backward propagation, matches or surpasses previous structured compression methods that rely on gradient information, and saves 98% of compute costs on compressing a 13B model. On \textsc{Llama}-2/3 and OPT models, MoDeGPT maintains 90-95% zero-shot performance with 25-30% compression rates. Moreover, the compression can be done on a single GPU within a few hours and increases the inference throughput by up to 46%.
DynaMo: Accelerating Language Model Inference with Dynamic Multi-Token Sampling
May 01, 2024



Traditional language models operate autoregressively, i.e., they predict one token at a time. Rapid explosion in model sizes has resulted in high inference times. In this work, we propose DynaMo, a suite of multi-token prediction language models that reduce net inference times. Our models $\textit{dynamically}$ predict multiple tokens based on their confidence in the predicted joint probability distribution. We propose a lightweight technique to train these models, leveraging the weights of traditional autoregressive counterparts. Moreover, we propose novel ways to enhance the estimated joint probability to improve text generation quality, namely co-occurrence weighted masking and adaptive thresholding. We also propose systematic qualitative and quantitative methods to rigorously test the quality of generated text for non-autoregressive generation. One of the models in our suite, DynaMo-7.3B-T3, achieves same-quality generated text as the baseline (Pythia-6.9B) while achieving 2.57$\times$ speed-up with only 5.87% and 2.67% parameter and training time overheads, respectively.
Compositional Generalization in Spoken Language Understanding
Dec 25, 2023



State-of-the-art spoken language understanding (SLU) models have shown tremendous success in benchmark SLU datasets, yet they still fail in many practical scenario due to the lack of model compositionality when trained on limited training data. In this paper, we study two types of compositionality: (a) novel slot combination, and (b) length generalization. We first conduct in-depth analysis, and find that state-of-the-art SLU models often learn spurious slot correlations during training, which leads to poor performance in both compositional cases. To mitigate these limitations, we create the first compositional splits of benchmark SLU datasets and we propose the first compositional SLU model, including compositional loss and paired training that tackle each compositional case respectively. On both benchmark and compositional splits in ATIS and SNIPS, we show that our compositional SLU model significantly outperforms (up to $5\%$ F1 score) state-of-the-art BERT SLU model.
* Published in INTERSPEECH 2023
Prompt Tuning for Zero-shot Compositional Learning
Dec 02, 2023



Open World Compositional Zero-Shot Learning (OW-CZSL) is known to be an extremely challenging task, which aims to recognize unseen compositions formed from seen attributes and objects without any prior assumption of the output space. In order to achieve this goal, a model has to be "smart" and "knowledgeable". To be smart, a model should be good at reasoning the interactions between attributes and objects from the seen compositions. While "knowledgeable" means the model owns "common sense" to the open world that can "foresee" some features of the unseen compositions. Most previous work focuses on the "smart" part, while few of them provided an effective solution to achieve the "knowledgeable" goal. In this paper, we proposed a framework named Multi-Modal Prompt Tuning (MMPT) to inherit the "knowledgeable" property from the large pre-trained vision-language model. Extensive experiments show that our proposed MMPT obtains new state-of-the-art results in OW-CZSL task. On the UT-Zappos dataset, MMPT pushes the AUC score to $29.8$, while the previous best score is $26.5$. On the more challenging MIT-States dataset, the AUC score of MMPT is 1.5 times better than the current state-of-the-art.
Token Fusion: Bridging the Gap between Token Pruning and Token Merging
Dec 02, 2023



Vision Transformers (ViTs) have emerged as powerful backbones in computer vision, outperforming many traditional CNNs. However, their computational overhead, largely attributed to the self-attention mechanism, makes deployment on resource-constrained edge devices challenging. Multiple solutions rely on token pruning or token merging. In this paper, we introduce "Token Fusion" (ToFu), a method that amalgamates the benefits of both token pruning and token merging. Token pruning proves advantageous when the model exhibits sensitivity to input interpolations, while token merging is effective when the model manifests close to linear responses to inputs. We combine this to propose a new scheme called Token Fusion. Moreover, we tackle the limitations of average merging, which doesn't preserve the intrinsic feature norm, resulting in distributional shifts. To mitigate this, we introduce MLERP merging, a variant of the SLERP technique, tailored to merge multiple tokens while maintaining the norm distribution. ToFu is versatile, applicable to ViTs with or without additional training. Our empirical evaluations indicate that ToFu establishes new benchmarks in both classification and image generation tasks concerning computational efficiency and model accuracy.
Continual Diffusion with STAMINA: STack-And-Mask INcremental Adapters
Nov 30, 2023Recent work has demonstrated a remarkable ability to customize text-to-image diffusion models to multiple, fine-grained concepts in a sequential (i.e., continual) manner while only providing a few example images for each concept. This setting is known as continual diffusion. Here, we ask the question: Can we scale these methods to longer concept sequences without forgetting? Although prior work mitigates the forgetting of previously learned concepts, we show that its capacity to learn new tasks reaches saturation over longer sequences. We address this challenge by introducing a novel method, STack-And-Mask INcremental Adapters (STAMINA), which is composed of low-ranked attention-masked adapters and customized MLP tokens. STAMINA is designed to enhance the robust fine-tuning properties of LoRA for sequential concept learning via learnable hard-attention masks parameterized with low rank MLPs, enabling precise, scalable learning via sparse adaptation. Notably, all introduced trainable parameters can be folded back into the model after training, inducing no additional inference parameter costs. We show that STAMINA outperforms the prior SOTA for the setting of text-to-image continual customization on a 50-concept benchmark composed of landmarks and human faces, with no stored replay data. Additionally, we extended our method to the setting of continual learning for image classification, demonstrating that our gains also translate to state-of-the-art performance in this standard benchmark.