 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA$^2$-Edit: Precise Reference-Guided Image Editing of Arbitrary Objects and Ambiguous Masks
Mar 11, 2026We propose \textbf{A$^2$-Edit}, a unified inpainting framework for arbitrary object categories, which allows users to replace any target region with a reference object using only a coarse mask. To address the issues of severe homogenization and limited category coverage in existing datasets, we construct a large-scale, multi-category dataset \textbf{UniEdit-500K}, which includes 8 major categories, 209 fine-grained subcategories, and a total of 500,104 image pairs. Such rich category diversity poses new challenges for the model, requiring it to automatically learn semantic relationships and distinctions across categories. To this end, we introduce the \textbf{Mixture of Transformer} module, which performs differentiated modeling of various object categories through dynamic expert selection, and further enhances cross-category semantic transfer and generalization through collaboration among experts. In addition, we propose a \textbf{Mask Annealing Training Strategy} (MATS) that progressively relaxes mask precision during training, reducing the model's reliance on accurate masks and improving robustness across diverse editing tasks. Extensive experiments on benchmarks such as VITON-HD and AnyInsertion demonstrate that A$^2$-Edit consistently outperforms existing approaches across all metrics, providing a new and efficient solution for arbitrary object editing.
FlowDirector: Training-Free Flow Steering for Precise Text-to-Video Editing
Jun 05, 2025Text-driven video editing aims to modify video content according to natural language instructions. While recent training-free approaches have made progress by leveraging pre-trained diffusion models, they typically rely on inversion-based techniques that map input videos into the latent space, which often leads to temporal inconsistencies and degraded structural fidelity. To address this, we propose FlowDirector, a novel inversion-free video editing framework. Our framework models the editing process as a direct evolution in data space, guiding the video via an Ordinary Differential Equation (ODE) to smoothly transition along its inherent spatiotemporal manifold, thereby preserving temporal coherence and structural details. To achieve localized and controllable edits, we introduce an attention-guided masking mechanism that modulates the ODE velocity field, preserving non-target regions both spatially and temporally. Furthermore, to address incomplete edits and enhance semantic alignment with editing instructions, we present a guidance-enhanced editing strategy inspired by Classifier-Free Guidance, which leverages differential signals between multiple candidate flows to steer the editing trajectory toward stronger semantic alignment without compromising structural consistency. Extensive experiments across benchmarks demonstrate that FlowDirector achieves state-of-the-art performance in instruction adherence, temporal consistency, and background preservation, establishing a new paradigm for efficient and coherent video editing without inversion.
Dynamic Dense RGB-D SLAM using Learning-based Visual Odometry
May 12, 2022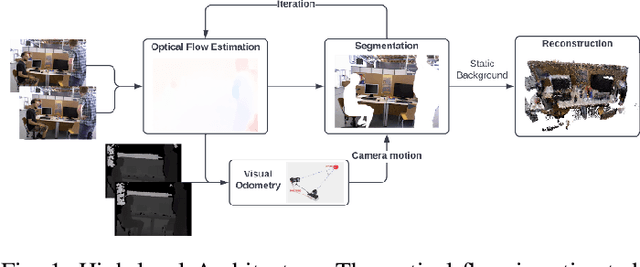
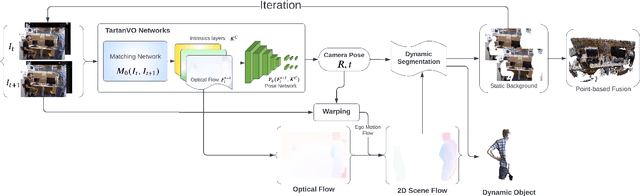
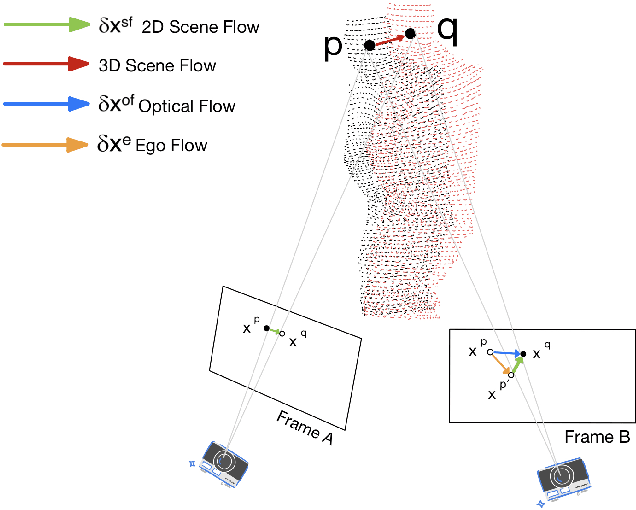
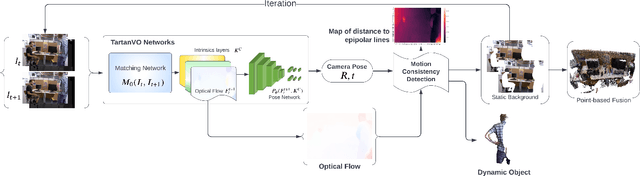
We propose a dense dynamic RGB-D SLAM pipeline based on a learning-based visual odometry, TartanVO. TartanVO, like other direct methods rather than feature-based, estimates camera pose through dense optical flow, which only applies to static scenes and disregards dynamic objects. Due to the color constancy assumption, optical flow is not able to differentiate between dynamic and static pixels. Therefore, to reconstruct a static map through such direct methods, our pipeline resolves dynamic/static segmentation by leveraging the optical flow output, and only fuse static points into the map. Moreover, we rerender the input frames such that the dynamic pixels are removed and iteratively pass them back into the visual odometry to refine the pose estimate.