 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCarPLAN: Context-Adaptive and Robust Planning with Dynamic Scene Awareness for Autonomous Driving
Mar 13, 2026Imitation learning (IL) is widely used for motion planning in autonomous driving due to its data efficiency and access to real-world driving data. For safe and robust real-world driving, IL-based planning requires capturing the complex driving contexts inherent in real-world data and enabling context-adaptive decision-making, rather than relying solely on expert trajectory imitation. In this paper, we propose CarPLAN, a novel IL-based motion planning framework that explicitly enhances driving context understanding and enables adaptive planning across diverse traffic scenarios. Our contributions are twofold: We introduce Displacement-Aware Predictive Encoding (DPE) to improve the model's spatial awareness by predicting future displacement vectors between the Autonomous Vehicle (AV) and surrounding scene elements. This allows the planner to account for relational spacing when generating trajectories. In addition to the standard imitation loss, we incorporate an augmented loss term that captures displacement prediction errors, ensuring planning decisions consider relative distances from other agents. To improve the model's ability to handle diverse driving contexts, we propose Context-Adaptive Multi-Expert Decoder (CMD), which leverages the Mixture of Experts (MoE) framework. CMD dynamically selects the most suitable expert decoders based on scene structure at each Transformer layer, enabling adaptive and context-aware planning in dynamic environments. We evaluate CarPLAN on the nuPlan benchmark and demonstrate state-of-the-art performance across all closed-loop simulation metrics. In particular, CarPLAN exhibits robust performance on challenging scenarios such as Test14-Hard, validating its effectiveness in complex driving conditions. Additional experiments on the Waymax benchmark further demonstrate its generalization capability across different benchmark settings.
STONE Dataset: A Scalable Multi-Modal Surround-View 3D Traversability Dataset for Off-Road Robot Navigation
Mar 12, 2026Reliable off-road navigation requires accurate estimation of traversable regions and robust perception under diverse terrain and sensing conditions. However, existing datasets lack both scalability and multi-modality, which limits progress in 3D traversability prediction. In this work, we introduce STONE, a large-scale multi-modal dataset for off-road navigation. STONE provides (1) trajectory-guided 3D traversability maps generated by a fully automated, annotation-free pipeline, and (2) comprehensive surround-view sensing with synchronized 128-channel LiDAR, six RGB cameras, and three 4D imaging radars. The dataset covers a wide range of environments and conditions, including day and night, grasslands, farmlands, construction sites, and lakes. Our auto-labeling pipeline reconstructs dense terrain surfaces from LiDAR scans, extracts geometric attributes such as slope, elevation, and roughness, and assigns traversability labels beyond the robot's trajectory using a Mahalanobis-distance-based criterion. This design enables scalable, geometry-aware ground-truth construction without manual annotation. Finally, we establish a benchmark for voxel-level 3D traversability prediction and provide strong baselines under both single-modal and multi-modal settings. STONE is available at: https://konyul.github.io/STONE-dataset/
Improving the performance of optical inverse design of multilayer thin films using CNN-LSTM tandem neural networks
Jun 11, 2025Optical properties of thin film are greatly influenced by the thickness of each layer. Accurately predicting these thicknesses and their corresponding optical properties is important in the optical inverse design of thin films. However, traditional inverse design methods usually demand extensive numerical simulations and optimization procedures, which are time-consuming. In this paper, we utilize deep learning for the inverse design of the transmission spectra of SiO2/TiO2 multilayer thin films. We implement a tandem neural network (TNN), which can solve the one-to-many mapping problem that greatly degrades the performance of deep-learning-based inverse designs. In general, the TNN has been implemented by a back-to-back connection of an inverse neural network and a pre-trained forward neural network, both of which have been implemented based on multilayer perceptron (MLP) algorithms. In this paper, we propose to use not only MLP, but also convolutional neural network (CNN) or long short-term memory (LSTM) algorithms in the configuration of the TNN. We show that an LSTM-LSTM-based TNN yields the highest accuracy but takes the longest training time among nine configurations of TNNs. We also find that a CNN-LSTM-based TNN will be an optimal solution in terms of accuracy and speed because it could integrate the strengths of the CNN and LSTM algorithms.
PersonaBooth: Personalized Text-to-Motion Generation
Mar 10, 2025



This paper introduces Motion Personalization, a new task that generates personalized motions aligned with text descriptions using several basic motions containing Persona. To support this novel task, we introduce a new large-scale motion dataset called PerMo (PersonaMotion), which captures the unique personas of multiple actors. We also propose a multi-modal finetuning method of a pretrained motion diffusion model called PersonaBooth. PersonaBooth addresses two main challenges: i) A significant distribution gap between the persona-focused PerMo dataset and the pretraining datasets, which lack persona-specific data, and ii) the difficulty of capturing a consistent persona from the motions vary in content (action type). To tackle the dataset distribution gap, we introduce a persona token to accept new persona features and perform multi-modal adaptation for both text and visuals during finetuning. To capture a consistent persona, we incorporate a contrastive learning technique to enhance intra-cohesion among samples with the same persona. Furthermore, we introduce a context-aware fusion mechanism to maximize the integration of persona cues from multiple input motions. PersonaBooth outperforms state-of-the-art motion style transfer methods, establishing a new benchmark for motion personalization.
ProtoOcc: Accurate, Efficient 3D Occupancy Prediction Using Dual Branch Encoder-Prototype Query Decoder
Dec 11, 2024



In this paper, we introduce ProtoOcc, a novel 3D occupancy prediction model designed to predict the occupancy states and semantic classes of 3D voxels through a deep semantic understanding of scenes. ProtoOcc consists of two main components: the Dual Branch Encoder (DBE) and the Prototype Query Decoder (PQD). The DBE produces a new 3D voxel representation by combining 3D voxel and BEV representations across multiple scales through a dual branch structure. This design enhances both performance and computational efficiency by providing a large receptive field for the BEV representation while maintaining a smaller receptive field for the voxel representation. The PQD introduces Prototype Queries to accelerate the decoding process. Scene-Adaptive Prototypes are derived from the 3D voxel features of input sample, while Scene-Agnostic Prototypes are computed by applying Scene-Adaptive Prototypes to an Exponential Moving Average during the training phase. By using these prototype-based queries for decoding, we can directly predict 3D occupancy in a single step, eliminating the need for iterative Transformer decoding. Additionally, we propose the Robust Prototype Learning, which injects noise into prototype generation process and trains the model to denoise during the training phase. ProtoOcc achieves state-of-the-art performance with 45.02% mIoU on the Occ3D-nuScenes benchmark. For single-frame method, it reaches 39.56% mIoU with an inference speed of 12.83 FPS on an NVIDIA RTX 3090. Our code can be found at https://github.com/SPA-junghokim/ProtoOcc.
Mask2Map: Vectorized HD Map Construction Using Bird's Eye View Segmentation Masks
Jul 19, 2024In this paper, we introduce Mask2Map, a novel end-to-end online HD map construction method designed for autonomous driving applications. Our approach focuses on predicting the class and ordered point set of map instances within a scene, represented in the bird's eye view (BEV). Mask2Map consists of two primary components: the Instance-Level Mask Prediction Network (IMPNet) and the Mask-Driven Map Prediction Network (MMPNet). IMPNet generates Mask-Aware Queries and BEV Segmentation Masks to capture comprehensive semantic information globally. Subsequently, MMPNet enhances these query features using local contextual information through two submodules: the Positional Query Generator (PQG) and the Geometric Feature Extractor (GFE). PQG extracts instance-level positional queries by embedding BEV positional information into Mask-Aware Queries, while GFE utilizes BEV Segmentation Masks to generate point-level geometric features. However, we observed limited performance in Mask2Map due to inter-network inconsistency stemming from different predictions to Ground Truth (GT) matching between IMPNet and MMPNet. To tackle this challenge, we propose the Inter-network Denoising Training method, which guides the model to denoise the output affected by both noisy GT queries and perturbed GT Segmentation Masks. Our evaluation conducted on nuScenes and Argoverse2 benchmarks demonstrates that Mask2Map achieves remarkable performance improvements over previous state-of-the-art methods, with gains of 10.1% mAP and 4.1 mAP, respectively. Our code can be found at https://github.com/SehwanChoi0307/Mask2Map.
MoST: Motion Style Transformer between Diverse Action Contents
Mar 20, 2024



While existing motion style transfer methods are effective between two motions with identical content, their performance significantly diminishes when transferring style between motions with different contents. This challenge lies in the lack of clear separation between content and style of a motion. To tackle this challenge, we propose a novel motion style transformer that effectively disentangles style from content and generates a plausible motion with transferred style from a source motion. Our distinctive approach to achieving the goal of disentanglement is twofold: (1) a new architecture for motion style transformer with `part-attentive style modulator across body parts' and `Siamese encoders that encode style and content features separately'; (2) style disentanglement loss. Our method outperforms existing methods and demonstrates exceptionally high quality, particularly in motion pairs with different contents, without the need for heuristic post-processing. Codes are available at https://github.com/Boeun-Kim/MoST.
Dimensionality reduction can be used as a surrogate model for high-dimensional forward uncertainty quantification
Feb 07, 2024We introduce a method to construct a stochastic surrogate model from the results of dimensionality reduction in forward uncertainty quantification. The hypothesis is that the high-dimensional input augmented by the output of a computational model admits a low-dimensional representation. This assumption can be met by numerous uncertainty quantification applications with physics-based computational models. The proposed approach differs from a sequential application of dimensionality reduction followed by surrogate modeling, as we "extract" a surrogate model from the results of dimensionality reduction in the input-output space. This feature becomes desirable when the input space is genuinely high-dimensional. The proposed method also diverges from the Probabilistic Learning on Manifold, as a reconstruction mapping from the feature space to the input-output space is circumvented. The final product of the proposed method is a stochastic simulator that propagates a deterministic input into a stochastic output, preserving the convenience of a sequential "dimensionality reduction + Gaussian process regression" approach while overcoming some of its limitations. The proposed method is demonstrated through two uncertainty quantification problems characterized by high-dimensional input uncertainties.
R-Pred: Two-Stage Motion Prediction Via Tube-Query Attention-Based Trajectory Refinement
Nov 21, 2022



Predicting the future motion of dynamic agents is of paramount importance to ensure safety or assess risks in motion planning for autonomous robots. In this paper, we propose a two-stage motion prediction method, referred to as R-Pred, that effectively utilizes both the scene and interaction context using a cascade of the initial trajectory proposal network and the trajectory refinement network. The initial trajectory proposal network produces M trajectory proposals corresponding to M modes of a future trajectory distribution. The trajectory refinement network enhances each of M proposals using 1) the tube-query scene attention (TQSA) and 2) the proposal-level interaction attention (PIA). TQSA uses tube-queries to aggregate the local scene context features pooled from proximity around the trajectory proposals of interest. PIA further enhances the trajectory proposals by modeling inter-agent interactions using a group of trajectory proposals selected based on their distances from neighboring agents. Our experiments conducted on the Argoverse and nuScenes datasets demonstrate that the proposed refinement network provides significant performance improvements compared to the single-stage baseline and that R-Pred achieves state-of-the-art performance in some categories of the benchmark.
Global-local Motion Transformer for Unsupervised Skeleton-based Action Learning
Jul 13, 2022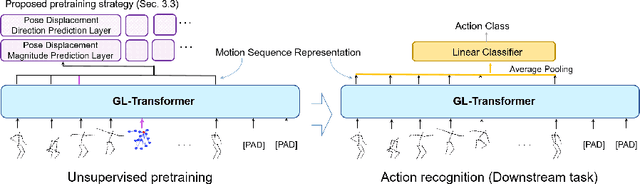

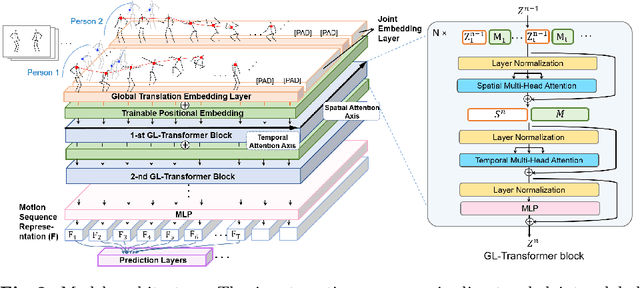

We propose a new transformer model for the task of unsupervised learning of skeleton motion sequences. The existing transformer model utilized for unsupervised skeleton-based action learning is learned the instantaneous velocity of each joint from adjacent frames without global motion information. Thus, the model has difficulties in learning the attention globally over whole-body motions and temporally distant joints. In addition, person-to-person interactions have not been considered in the model. To tackle the learning of whole-body motion, long-range temporal dynamics, and person-to-person interactions, we design a global and local attention mechanism, where, global body motions and local joint motions pay attention to each other. In addition, we propose a novel pretraining strategy, multi-interval pose displacement prediction, to learn both global and local attention in diverse time ranges. The proposed model successfully learns local dynamics of the joints and captures global context from the motion sequences. Our model outperforms state-of-the-art models by notable margins in the representative benchmarks. Codes are available at https://github.com/Boeun-Kim/GL-Transformer.