 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliminating Gradient Conflict in Reference-based Line-Art Colorization
Jul 20, 2022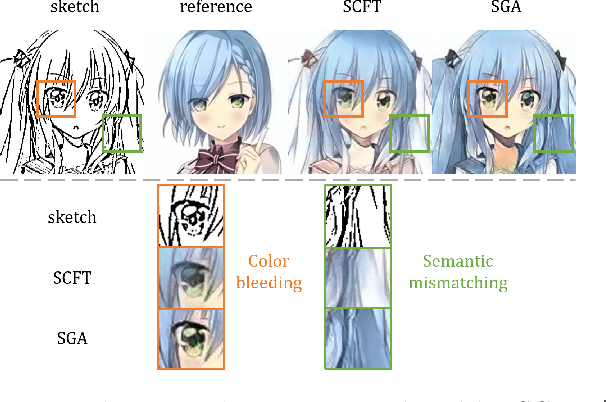
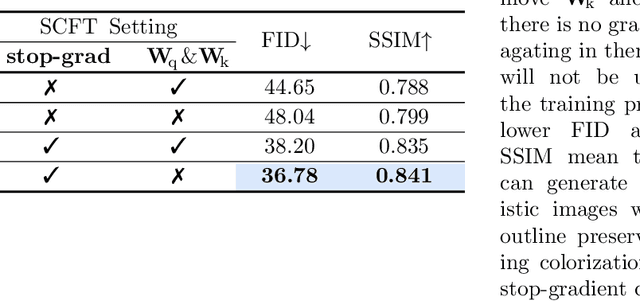
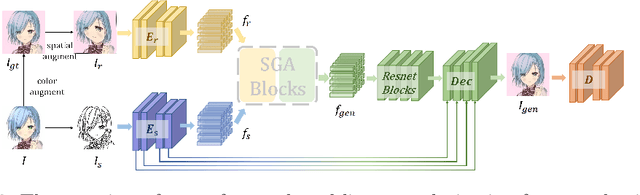
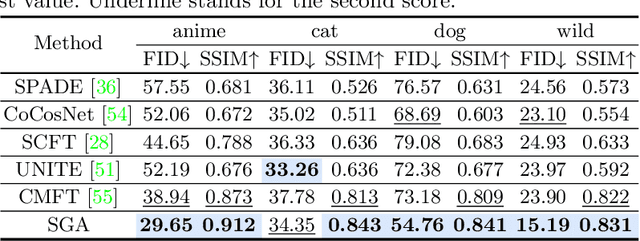
Reference-based line-art colorization is a challenging task in computer vision. The color, texture, and shading are rendered based on an abstract sketch, which heavily relies on the precise long-range dependency modeling between the sketch and reference. Popular techniques to bridge the cross-modal information and model the long-range dependency employ the attention mechanism. However, in the context of reference-based line-art colorization, several techniques would intensify the existing training difficulty of attention, for instance, self-supervised training protocol and GAN-based losses. To understand the instability in training, we detect the gradient flow of attention and observe gradient conflict among attention branches. This phenomenon motivates us to alleviate the gradient issue by preserving the dominant gradient branch while removing the conflict ones. We propose a novel attention mechanism using this training strategy, Stop-Gradient Attention (SGA), outperforming the attention baseline by a large margin with better training stability. Compared with state-of-the-art modules in line-art colorization, our approach demonstrates significant improvements in Fr\'echet Inception Distance (FID, up to 27.21%) and structural similarity index measure (SSIM, up to 25.67%) on several benchmarks. The code of SGA is available at https://github.com/kunkun0w0/SGA .
SFNet: Faster, Accurate, and Domain Agnostic Semantic Segmentation via Semantic Flow
Jul 10, 2022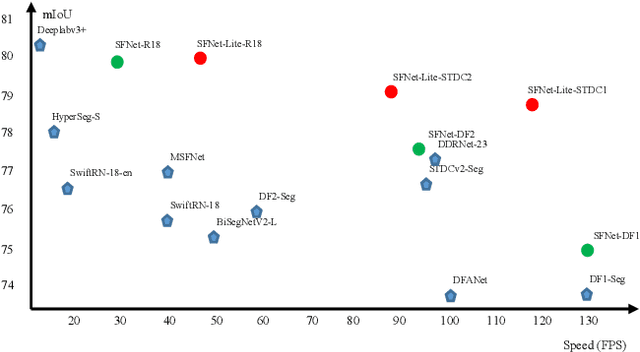

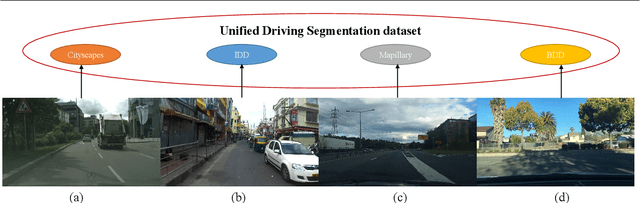
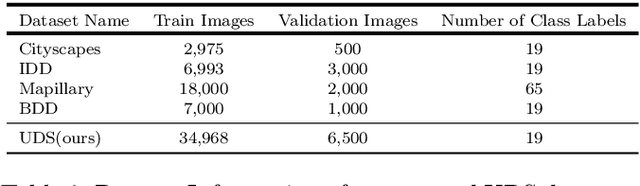
In this paper, we focus on exploring effective methods for faster, accurate, and domain agnostic semantic segmentation. Inspired by the Optical Flow for motion alignment between adjacent video frames, we propose a Flow Alignment Module (FAM) to learn \textit{Semantic Flow} between feature maps of adjacent levels, and broadcast high-level features to high resolution features effectively and efficiently. Furthermore, integrating our FAM to a common feature pyramid structure exhibits superior performance over other real-time methods even on light-weight backbone networks, such as ResNet-18 and DFNet. Then to further speed up the inference procedure, we also present a novel Gated Dual Flow Alignment Module to directly align high resolution feature maps and low resolution feature maps where we term improved version network as SFNet-Lite. Extensive experiments are conducted on several challenging datasets, where results show the effectiveness of both SFNet and SFNet-Lite. In particular, the proposed SFNet-Lite series achieve 80.1 mIoU while running at 60 FPS using ResNet-18 backbone and 78.8 mIoU while running at 120 FPS using STDC backbone on RTX-3090. Moreover, we unify four challenging driving datasets (i.e., Cityscapes, Mapillary, IDD and BDD) into one large dataset, which we named Unified Driving Segmentation (UDS) dataset. It contains diverse domain and style information. We benchmark several representative works on UDS. Both SFNet and SFNet-Lite still achieve the best speed and accuracy trade-off on UDS which serves as a strong baseline in such a new challenging setting. All the code and models are publicly available at https://github.com/lxtGH/SFSegNets.
EATFormer: Improving Vision Transformer Inspired by Evolutionary Algorithm
Jun 19, 2022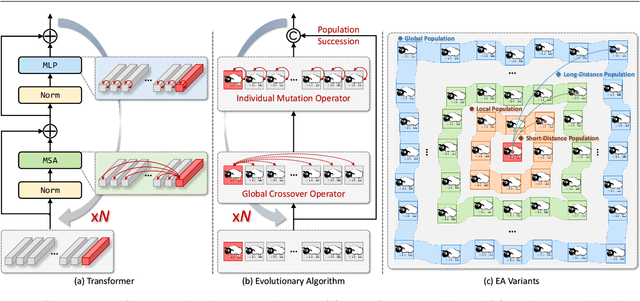

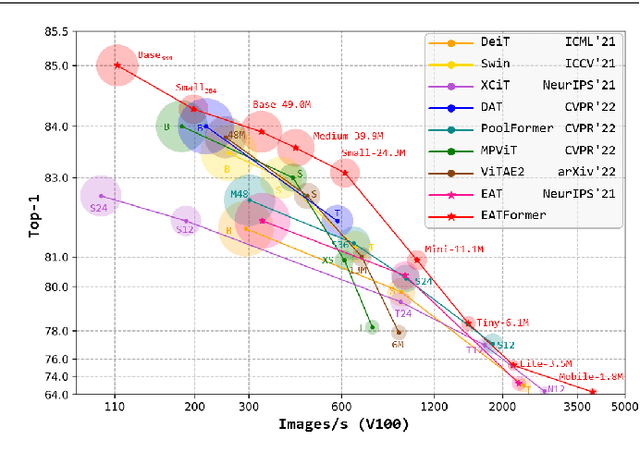
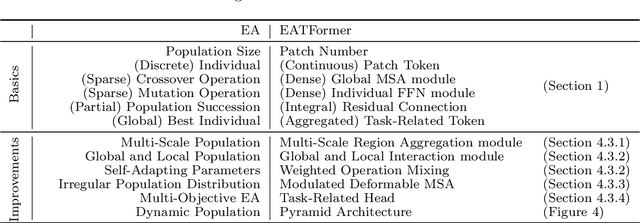
Motivated by biological evolution, this paper explains the rationality of Vision Transformer by analogy with the proven practical Evolutionary Algorithm (EA) and derives that both have consistent mathematical formulation. Then inspired by effective EA variants, we propose a novel pyramid EATFormer backbone that only contains the proposed \emph{EA-based Transformer} (EAT) block, which consists of three residual parts, \ie, \emph{Multi-Scale Region Aggregation} (MSRA), \emph{Global and Local Interaction} (GLI), and \emph{Feed-Forward Network} (FFN) modules, to model multi-scale, interactive, and individual information separately. Moreover, we design a \emph{Task-Related Head} (TRH) docked with transformer backbone to complete final information fusion more flexibly and \emph{improve} a \emph{Modulated Deformable MSA} (MD-MSA) to dynamically model irregular locations. Massive quantitative and quantitative experiments on image classification, downstream tasks, and explanatory experiments demonstrate the effectiveness and superiority of our approach over State-Of-The-Art (SOTA) methods. \Eg, our Mobile (1.8M), Tiny (6.1M), Small (24.3M), and Base (49.0M) models achieve 69.4, 78.4, 83.1, and 83.9 Top-1 only trained on ImageNet-1K with naive training recipe; EATFormer-Tiny/Small/Base armed Mask-R-CNN obtain 45.4/47.4/49.0 box AP and 41.4/42.9/44.2 mask AP on COCO detection, surpassing contemporary MPViT-T, Swin-T, and Swin-S by 0.6/1.4/0.5 box AP and 0.4/1.3/0.9 mask AP separately with less FLOPs; Our EATFormer-Small/Base achieve 47.3/49.3 mIoU on ADE20K by Upernet that exceeds Swin-T/S by 2.8/1.7. Code will be available at \url{https://https://github.com/zhangzjn/EATFormer}.
Multi-Task Learning with Multi-query Transformer for Dense Prediction
May 31, 2022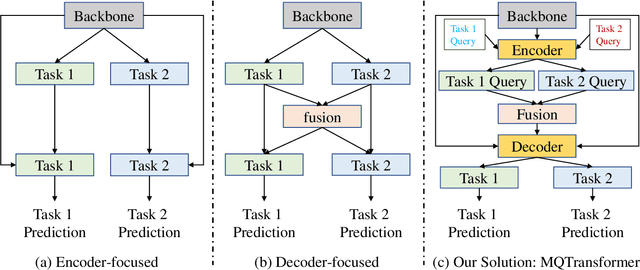
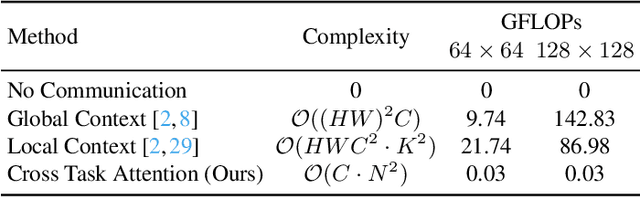
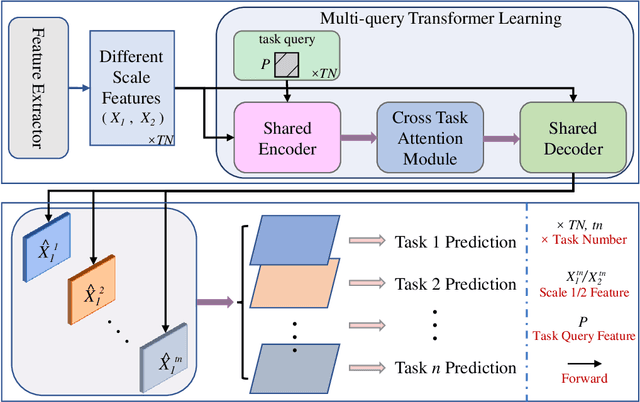
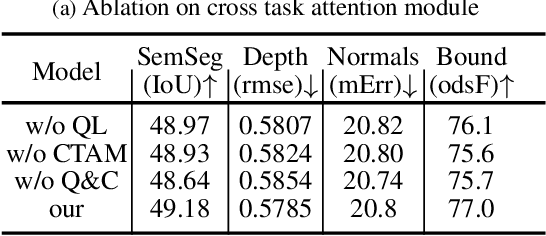
Previous multi-task dense prediction studies developed complex pipelines such as multi-modal distillations in multiple stages or searching for task relational contexts for each task. The core insight beyond these methods is to maximize the mutual effects between each task. Inspired by the recent query-based Transformers, we propose a simpler pipeline named Multi-Query Transformer (MQTransformer) that is equipped with multiple queries from different tasks to facilitate the reasoning among multiple tasks and simplify the cross task pipeline. Instead of modeling the dense per-pixel context among different tasks, we seek a task-specific proxy to perform cross-task reasoning via multiple queries where each query encodes the task-related context. The MQTransformer is composed of three key components: shared encoder, cross task attention and shared decoder. We first model each task with a task-relevant and scale-aware query, and then both the image feature output by the feature extractor and the task-relevant query feature are fed into the shared encoder, thus encoding the query feature from the image feature. Secondly, we design a cross task attention module to reason the dependencies among multiple tasks and feature scales from two perspectives including different tasks of the same scale and different scales of the same task. Then we use a shared decoder to gradually refine the image features with the reasoned query features from different tasks. Extensive experiment results on two dense prediction datasets (NYUD-v2 and PASCAL-Context) show that the proposed method is an effective approach and achieves the state-of-the-art result. Code will be available.
Neural Collapse Inspired Attraction-Repulsion-Balanced Loss for Imbalanced Learning
Apr 27, 2022
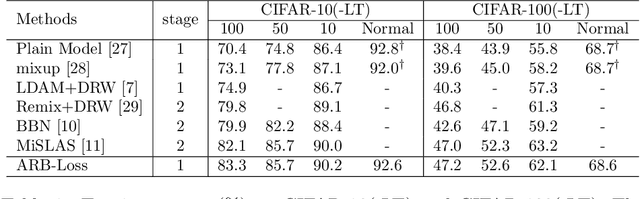
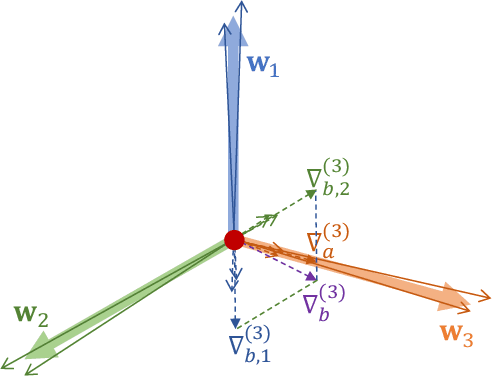
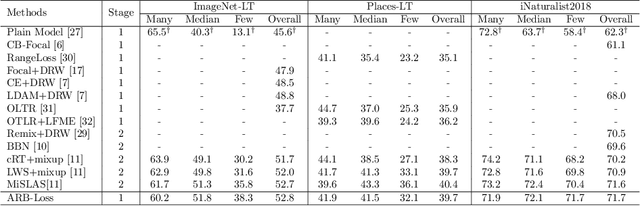
Class imbalance distribution widely exists in real-world engineering. However, the mainstream optimization algorithms that seek to minimize error will trap the deep learning model in sub-optimums when facing extreme class imbalance. It seriously harms the classification precision, especially on the minor classes. The essential reason is that the gradients of the classifier weights are imbalanced among the components from different classes. In this paper, we propose Attraction-Repulsion-Balanced Loss (ARB-Loss) to balance the different components of the gradients. We perform experiments on the large-scale classification and segmentation datasets and our ARB-Loss can achieve state-of-the-art performance via only one-stage training instead of 2-stage learning like nowadays SOTA works.
Do We Really Need a Learnable Classifier at the End of Deep Neural Network?
Mar 17, 2022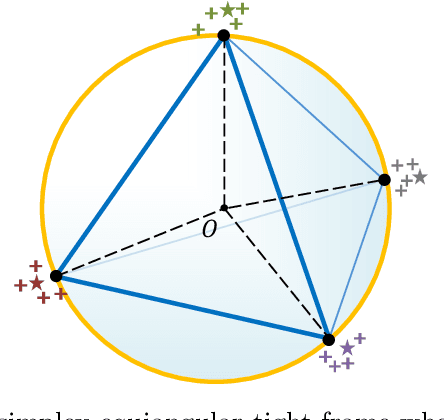

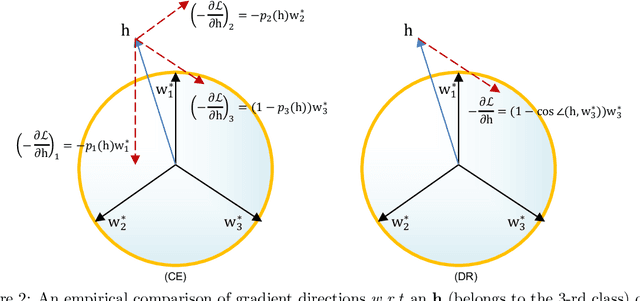
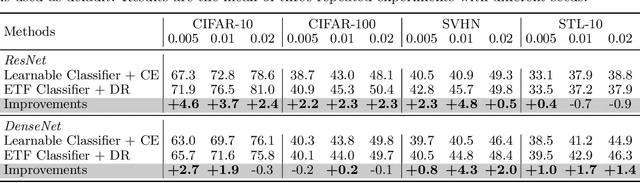
Modern deep neural networks for classification usually jointly learn a backbone for representation and a linear classifier to output the logit of each class. A recent study has shown a phenomenon called neural collapse that the within-class means of features and the classifier vectors converge to the vertices of a simplex equiangular tight frame (ETF) at the terminal phase of training on a balanced dataset. Since the ETF geometric structure maximally separates the pair-wise angles of all classes in the classifier, it is natural to raise the question, why do we spend an effort to learn a classifier when we know its optimal geometric structure? In this paper, we study the potential of learning a neural network for classification with the classifier randomly initialized as an ETF and fixed during training. Our analytical work based on the layer-peeled model indicates that the feature learning with a fixed ETF classifier naturally leads to the neural collapse state even when the dataset is imbalanced among classes. We further show that in this case the cross entropy (CE) loss is not necessary and can be replaced by a simple squared loss that shares the same global optimality but enjoys a more accurate gradient and better convergence property. Our experimental results show that our method is able to achieve similar performances on image classification for balanced datasets, and bring significant improvements in the long-tailed and fine-grained classification tasks.
ART-Point: Improving Rotation Robustness of Point Cloud Classifiers via Adversarial Rotation
Mar 08, 2022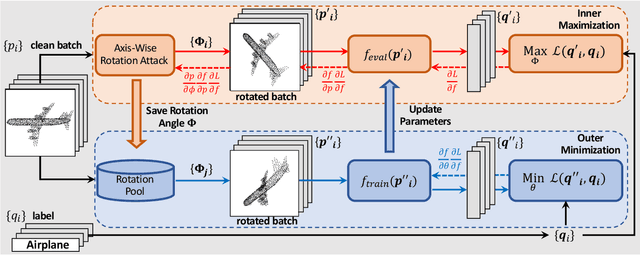
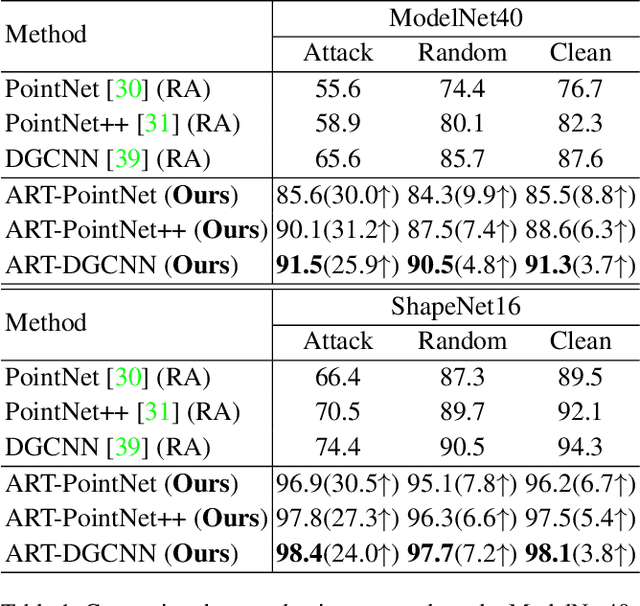
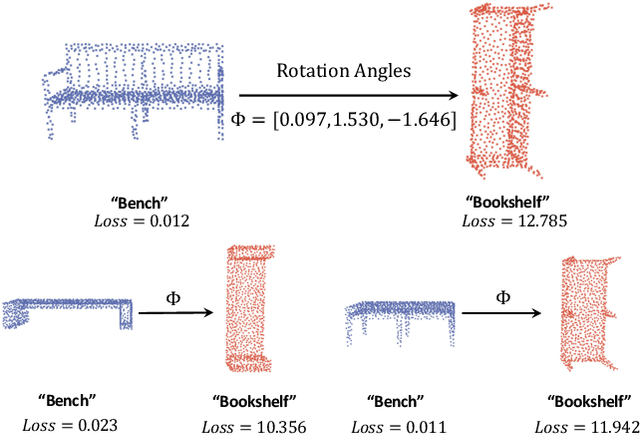
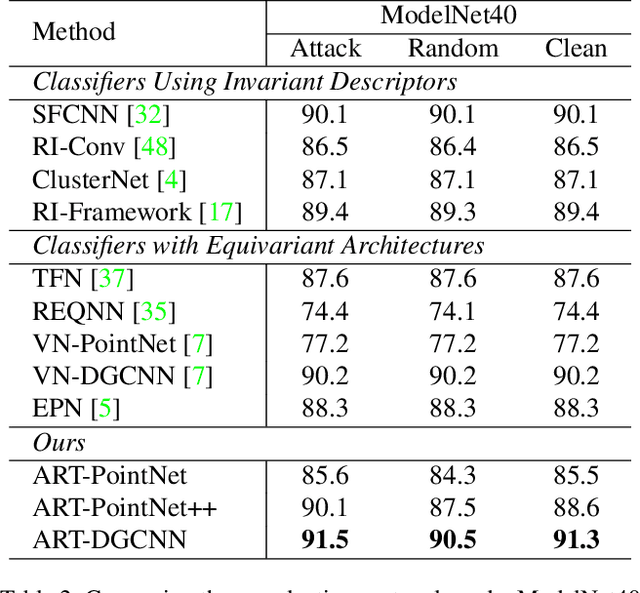
Point cloud classifiers with rotation robustness have been widely discussed in the 3D deep learning community. Most proposed methods either use rotation invariant descriptors as inputs or try to design rotation equivariant networks. However, robust models generated by these methods have limited performance under clean aligned datasets due to modifications on the original classifiers or input space. In this study, for the first time, we show that the rotation robustness of point cloud classifiers can also be acquired via adversarial training with better performance on both rotated and clean datasets. Specifically, our proposed framework named ART-Point regards the rotation of the point cloud as an attack and improves rotation robustness by training the classifier on inputs with Adversarial RoTations. We contribute an axis-wise rotation attack that uses back-propagated gradients of the pre-trained model to effectively find the adversarial rotations. To avoid model over-fitting on adversarial inputs, we construct rotation pools that leverage the transferability of adversarial rotations among samples to increase the diversity of training data. Moreover, we propose a fast one-step optimization to efficiently reach the final robust model. Experiments show that our proposed rotation attack achieves a high success rate and ART-Point can be used on most existing classifiers to improve the rotation robustness while showing better performance on clean datasets than state-of-the-art methods.
Scalable Uncertainty Quantification for Deep Operator Networks using Randomized Priors
Mar 06, 2022
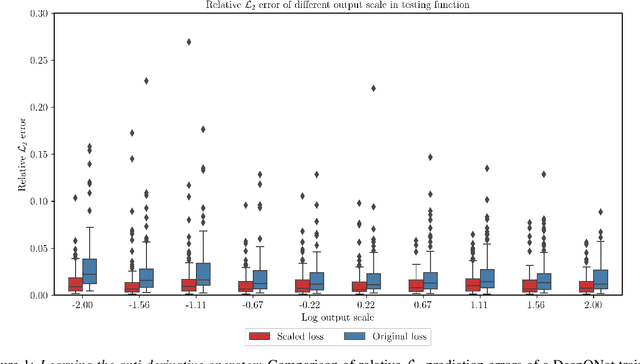
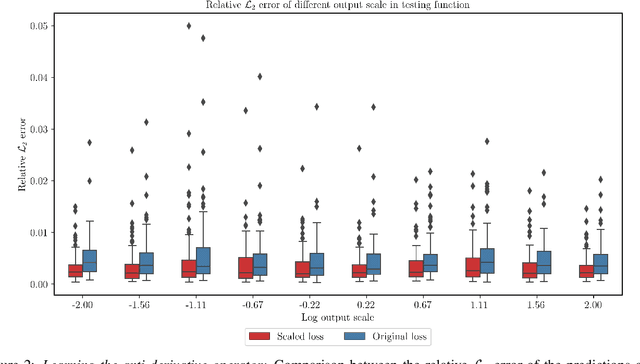
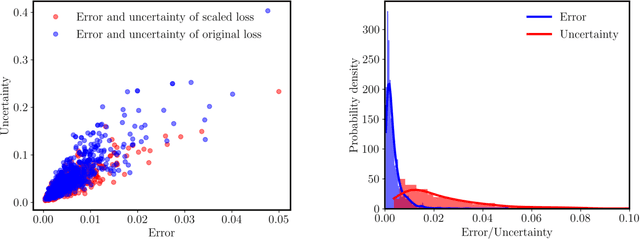
We present a simple and effective approach for posterior uncertainty quantification in deep operator networks (DeepONets); an emerging paradigm for supervised learning in function spaces. We adopt a frequentist approach based on randomized prior ensembles, and put forth an efficient vectorized implementation for fast parallel inference on accelerated hardware. Through a collection of representative examples in computational mechanics and climate modeling, we show that the merits of the proposed approach are fourfold. (1) It can provide more robust and accurate predictions when compared against deterministic DeepONets. (2) It shows great capability in providing reliable uncertainty estimates on scarce data-sets with multi-scale function pairs. (3) It can effectively detect out-of-distribution and adversarial examples. (4) It can seamlessly quantify uncertainty due to model bias, as well as noise corruption in the data. Finally, we provide an optimized JAX library called {\em UQDeepONet} that can accommodate large model architectures, large ensemble sizes, as well as large data-sets with excellent parallel performance on accelerated hardware, thereby enabling uncertainty quantification for DeepONets in realistic large-scale applications.
An Introduction to Neural Data Compression
Feb 14, 2022



Neural compression is the application of neural networks and other machine learning methods to data compression. While machine learning deals with many concepts closely related to compression, entering the field of neural compression can be difficult due to its reliance on information theory, perceptual metrics, and other knowledge specific to the field. This introduction hopes to fill in the necessary background by reviewing basic coding topics such as entropy coding and rate-distortion theory, related machine learning ideas such as bits-back coding and perceptual metrics, and providing a guide through the representative works in the literature so far.
TransVOD: End-to-end Video Object Detection with Spatial-Temporal Transformers
Jan 17, 2022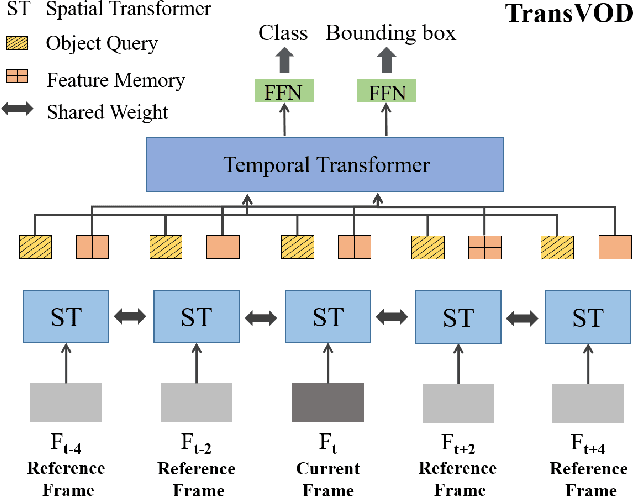
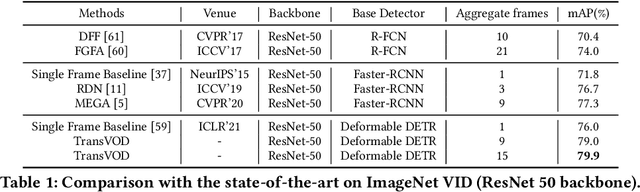
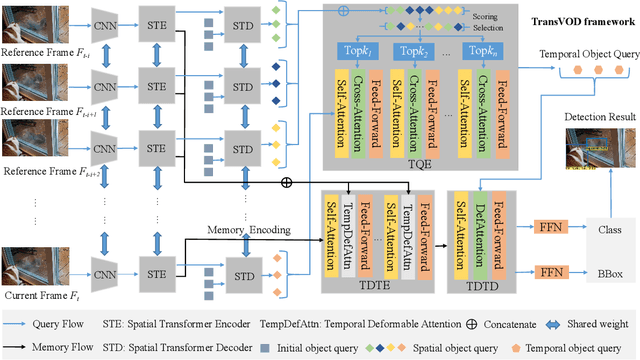
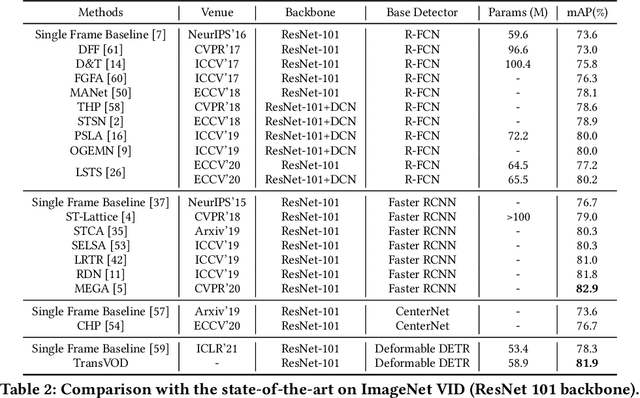
Detection Transformer (DETR) and Deformable DETR have been proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance as previous complex hand-crafted detectors. However, their performance on Video Object Detection (VOD) has not been well explored. In this paper, we present TransVOD, the first end-to-end video object detection system based on spatial-temporal Transformer architectures. The first goal of this paper is to streamline the pipeline of VOD, effectively removing the need for many hand-crafted components for feature aggregation, e.g., optical flow model, relation networks. Besides, benefited from the object query design in DETR, our method does not need complicated post-processing methods such as Seq-NMS. In particular, we present a temporal Transformer to aggregate both the spatial object queries and the feature memories of each frame. Our temporal transformer consists of two components: Temporal Query Encoder (TQE) to fuse object queries, and Temporal Deformable Transformer Decoder (TDTD) to obtain current frame detection results. These designs boost the strong baseline deformable DETR by a significant margin (3%-4% mAP) on the ImageNet VID dataset. Then, we present two improved versions of TransVOD including TransVOD++ and TransVOD Lite. The former fuses object-level information into object query via dynamic convolution while the latter models the entire video clips as the output to speed up the inference time. We give detailed analysis of all three models in the experiment part. In particular, our proposed TransVOD++ sets a new state-of-the-art record in terms of accuracy on ImageNet VID with 90.0% mAP. Our proposed TransVOD Lite also achieves the best speed and accuracy trade-off with 83.7% mAP while running at around 30 FPS on a single V100 GPU device. Code and models will be available for further research.