 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCloud2Curve: Generation and Vectorization of Parametric Sketches
Mar 29, 2021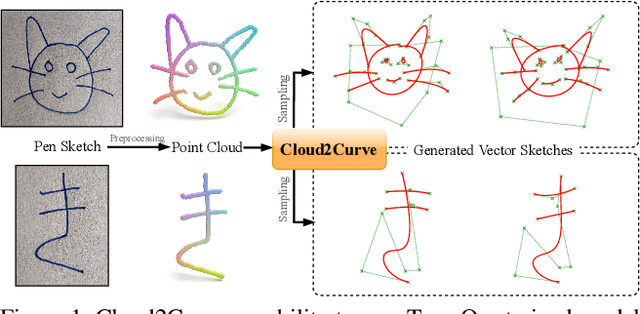
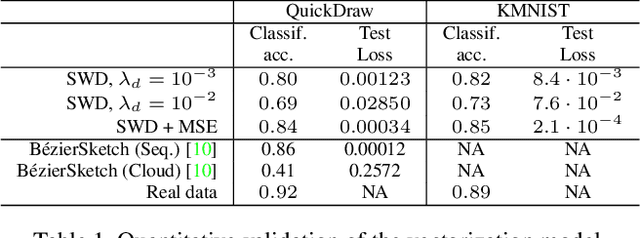
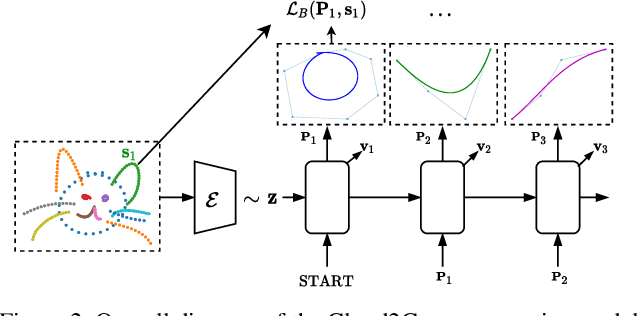
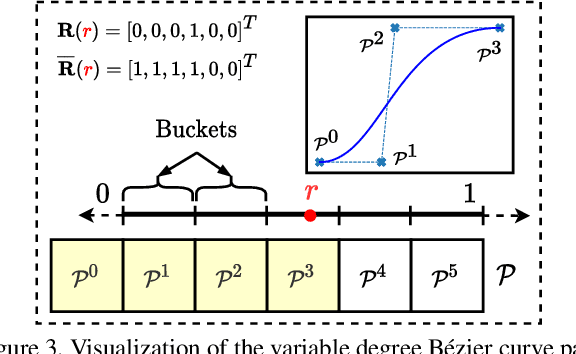
Analysis of human sketches in deep learning has advanced immensely through the use of waypoint-sequences rather than raster-graphic representations. We further aim to model sketches as a sequence of low-dimensional parametric curves. To this end, we propose an inverse graphics framework capable of approximating a raster or waypoint based stroke encoded as a point-cloud with a variable-degree B\'ezier curve. Building on this module, we present Cloud2Curve, a generative model for scalable high-resolution vector sketches that can be trained end-to-end using point-cloud data alone. As a consequence, our model is also capable of deterministic vectorization which can map novel raster or waypoint based sketches to their corresponding high-resolution scalable B\'ezier equivalent. We evaluate the generation and vectorization capabilities of our model on Quick, Draw! and K-MNIST datasets.
More Photos are All You Need: Semi-Supervised Learning for Fine-Grained Sketch Based Image Retrieval
Mar 25, 2021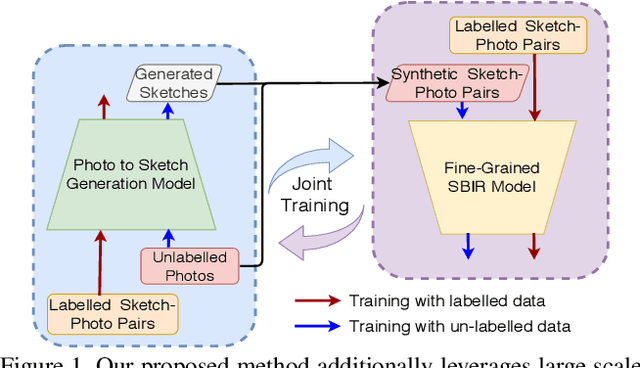
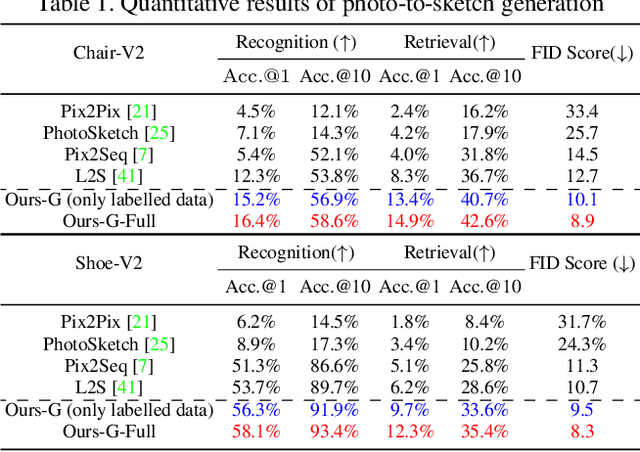
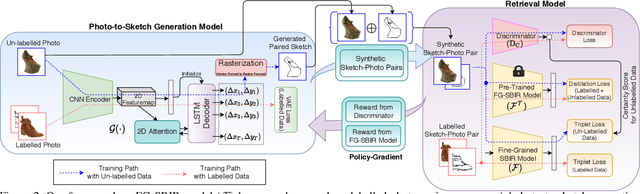
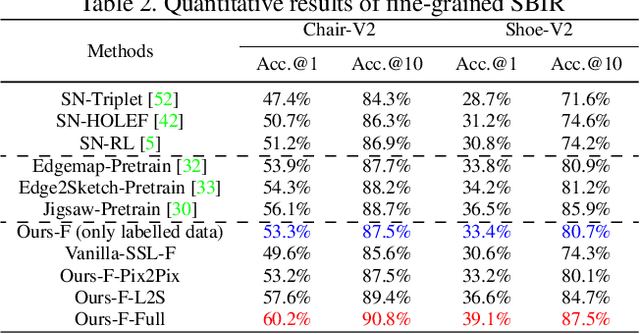
A fundamental challenge faced by existing Fine-Grained Sketch-Based Image Retrieval (FG-SBIR) models is the data scarcity -- model performances are largely bottlenecked by the lack of sketch-photo pairs. Whilst the number of photos can be easily scaled, each corresponding sketch still needs to be individually produced. In this paper, we aim to mitigate such an upper-bound on sketch data, and study whether unlabelled photos alone (of which they are many) can be cultivated for performances gain. In particular, we introduce a novel semi-supervised framework for cross-modal retrieval that can additionally leverage large-scale unlabelled photos to account for data scarcity. At the centre of our semi-supervision design is a sequential photo-to-sketch generation model that aims to generate paired sketches for unlabelled photos. Importantly, we further introduce a discriminator guided mechanism to guide against unfaithful generation, together with a distillation loss based regularizer to provide tolerance against noisy training samples. Last but not least, we treat generation and retrieval as two conjugate problems, where a joint learning procedure is devised for each module to mutually benefit from each other. Extensive experiments show that our semi-supervised model yields significant performance boost over the state-of-the-art supervised alternatives, as well as existing methods that can exploit unlabelled photos for FG-SBIR.
Vectorization and Rasterization: Self-Supervised Learning for Sketch and Handwriting
Mar 25, 2021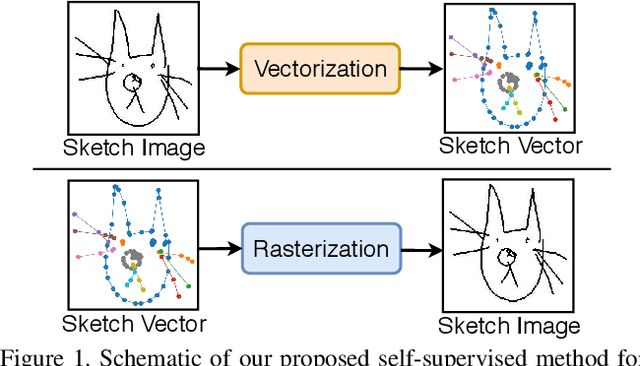
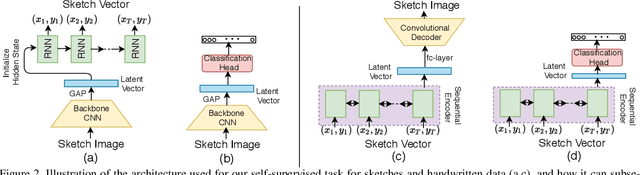
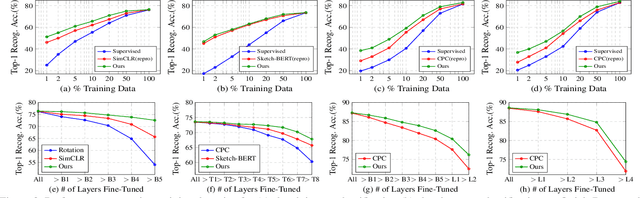
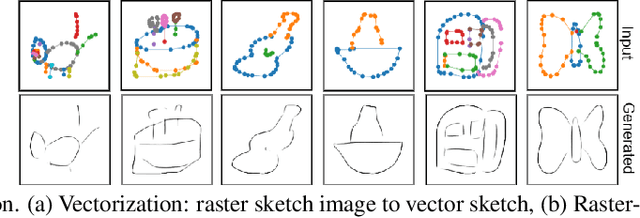
Self-supervised learning has gained prominence due to its efficacy at learning powerful representations from unlabelled data that achieve excellent performance on many challenging downstream tasks. However supervision-free pre-text tasks are challenging to design and usually modality specific. Although there is a rich literature of self-supervised methods for either spatial (such as images) or temporal data (sound or text) modalities, a common pre-text task that benefits both modalities is largely missing. In this paper, we are interested in defining a self-supervised pre-text task for sketches and handwriting data. This data is uniquely characterised by its existence in dual modalities of rasterized images and vector coordinate sequences. We address and exploit this dual representation by proposing two novel cross-modal translation pre-text tasks for self-supervised feature learning: Vectorization and Rasterization. Vectorization learns to map image space to vector coordinates and rasterization maps vector coordinates to image space. We show that the our learned encoder modules benefit both raster-based and vector-based downstream approaches to analysing hand-drawn data. Empirical evidence shows that our novel pre-text tasks surpass existing single and multi-modal self-supervision methods.
Context-Aware Layout to Image Generation with Enhanced Object Appearance
Mar 22, 2021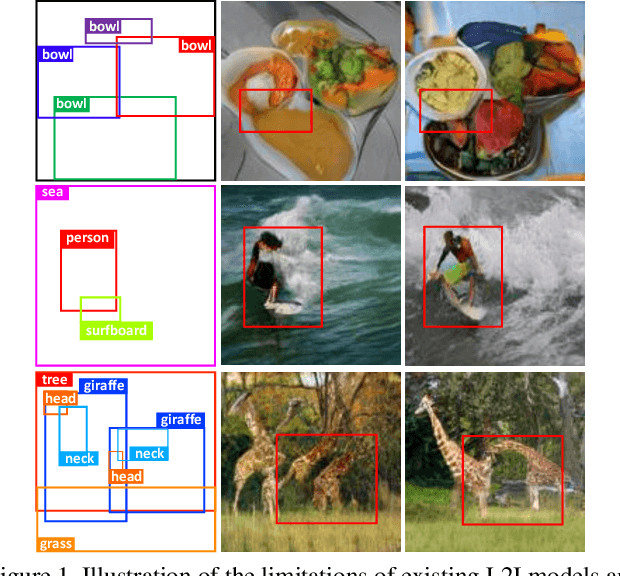
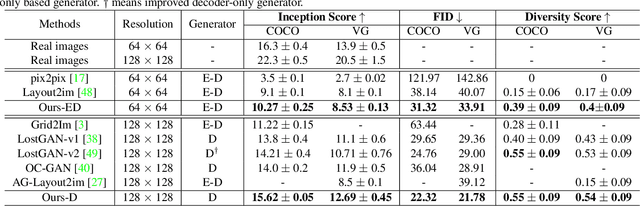
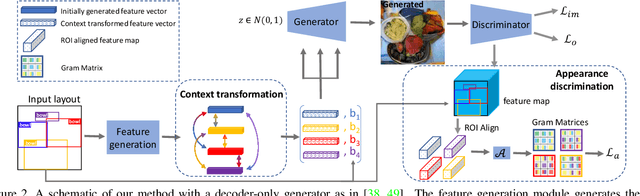

A layout to image (L2I) generation model aims to generate a complicated image containing multiple objects (things) against natural background (stuff), conditioned on a given layout. Built upon the recent advances in generative adversarial networks (GANs), existing L2I models have made great progress. However, a close inspection of their generated images reveals two major limitations: (1) the object-to-object as well as object-to-stuff relations are often broken and (2) each object's appearance is typically distorted lacking the key defining characteristics associated with the object class. We argue that these are caused by the lack of context-aware object and stuff feature encoding in their generators, and location-sensitive appearance representation in their discriminators. To address these limitations, two new modules are proposed in this work. First, a context-aware feature transformation module is introduced in the generator to ensure that the generated feature encoding of either object or stuff is aware of other co-existing objects/stuff in the scene. Second, instead of feeding location-insensitive image features to the discriminator, we use the Gram matrix computed from the feature maps of the generated object images to preserve location-sensitive information, resulting in much enhanced object appearance. Extensive experiments show that the proposed method achieves state-of-the-art performance on the COCO-Thing-Stuff and Visual Genome benchmarks.
Your "Labrador" is My "Dog": Fine-Grained, or Not
Nov 18, 2020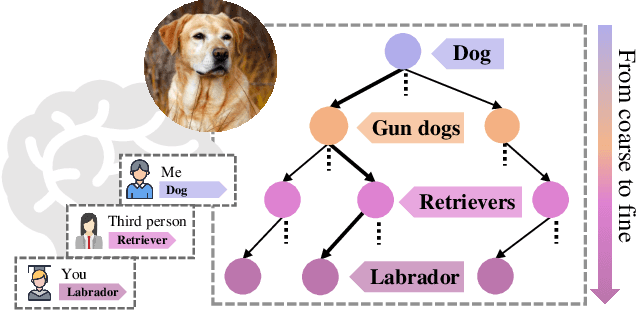

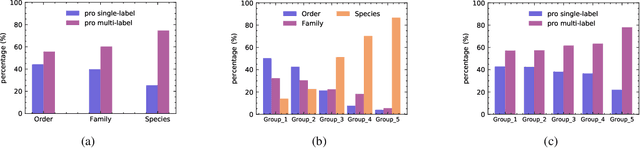
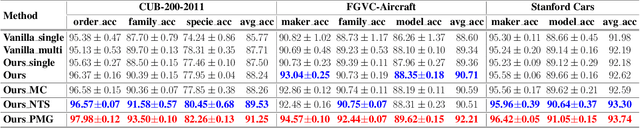
Whether what you see in Figure 1 is a "labrador" or a "dog", is the question we ask in this paper. While fine-grained visual classification (FGVC) strives to arrive at the former, for the majority of us non-experts just "dog" would probably suffice. The real question is therefore -- how can we tailor for different fine-grained definitions under divergent levels of expertise. For that, we re-envisage the traditional setting of FGVC, from single-label classification, to that of top-down traversal of a pre-defined coarse-to-fine label hierarchy -- so that our answer becomes "dog"-->"gun dog"-->"retriever"-->"labrador". To approach this new problem, we first conduct a comprehensive human study where we confirm that most participants prefer multi-granularity labels, regardless whether they consider themselves experts. We then discover the key intuition that: coarse-level label prediction exacerbates fine-grained feature learning, yet fine-level feature betters the learning of coarse-level classifier. This discovery enables us to design a very simple albeit surprisingly effective solution to our new problem, where we (i) leverage level-specific classification heads to disentangle coarse-level features with fine-grained ones, and (ii) allow finer-grained features to participate in coarser-grained label predictions, which in turn helps with better disentanglement. Experiments show that our method achieves superior performance in the new FGVC setting, and performs better than state-of-the-art on traditional single-label FGVC problem as well. Thanks to its simplicity, our method can be easily implemented on top of any existing FGVC frameworks and is parameter-free.
Deep Sketch-Based Modeling: Tips and Tricks
Nov 17, 2020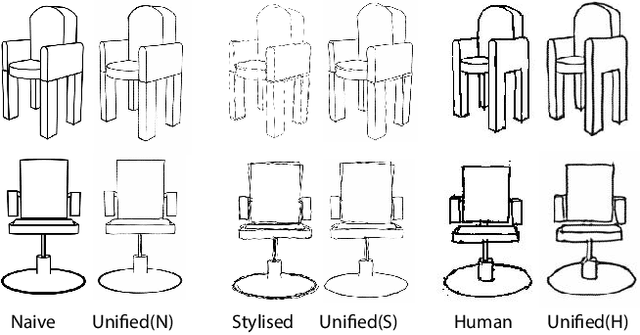
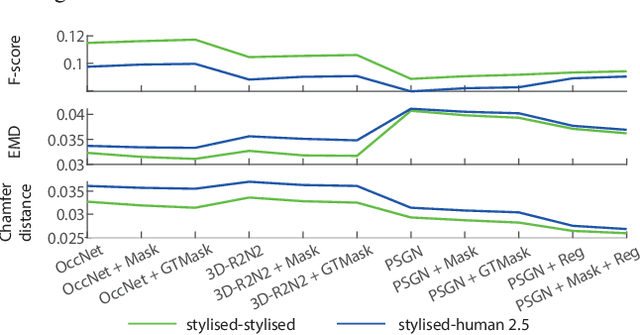

Deep image-based modeling received lots of attention in recent years, yet the parallel problem of sketch-based modeling has only been briefly studied, often as a potential application. In this work, for the first time, we identify the main differences between sketch and image inputs: (i) style variance, (ii) imprecise perspective, and (iii) sparsity. We discuss why each of these differences can pose a challenge, and even make a certain class of image-based methods inapplicable. We study alternative solutions to address each of the difference. By doing so, we drive out a few important insights: (i) sparsity commonly results in an incorrect prediction of foreground versus background, (ii) diversity of human styles, if not taken into account, can lead to very poor generalization properties, and finally (iii) unless a dedicated sketching interface is used, one can not expect sketches to match a perspective of a fixed viewpoint. Finally, we compare a set of representative deep single-image modeling solutions and show how their performance can be improved to tackle sketch input by taking into consideration the identified critical differences.
Cross-Modal Hierarchical Modelling for Fine-Grained Sketch Based Image Retrieval
Aug 11, 2020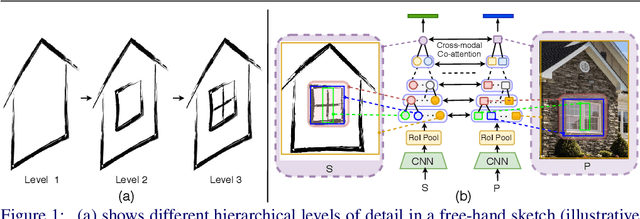
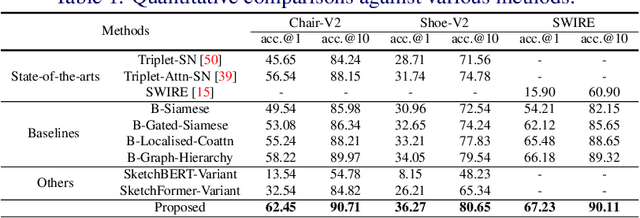
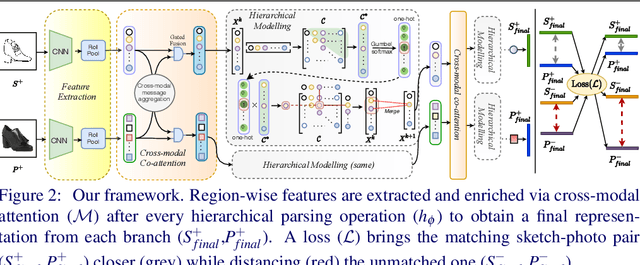
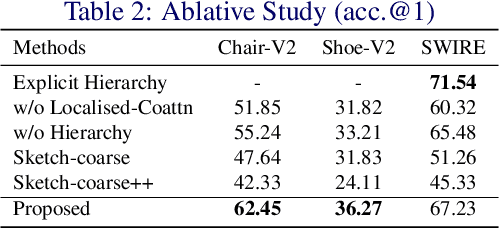
Sketch as an image search query is an ideal alternative to text in capturing the fine-grained visual details. Prior successes on fine-grained sketch-based image retrieval (FG-SBIR) have demonstrated the importance of tackling the unique traits of sketches as opposed to photos, e.g., temporal vs. static, strokes vs. pixels, and abstract vs. pixel-perfect. In this paper, we study a further trait of sketches that has been overlooked to date, that is, they are hierarchical in terms of the levels of detail -- a person typically sketches up to various extents of detail to depict an object. This hierarchical structure is often visually distinct. In this paper, we design a novel network that is capable of cultivating sketch-specific hierarchies and exploiting them to match sketch with photo at corresponding hierarchical levels. In particular, features from a sketch and a photo are enriched using cross-modal co-attention, coupled with hierarchical node fusion at every level to form a better embedding space to conduct retrieval. Experiments on common benchmarks show our method to outperform state-of-the-arts by a significant margin.
BézierSketch: A generative model for scalable vector sketches
Jul 14, 2020
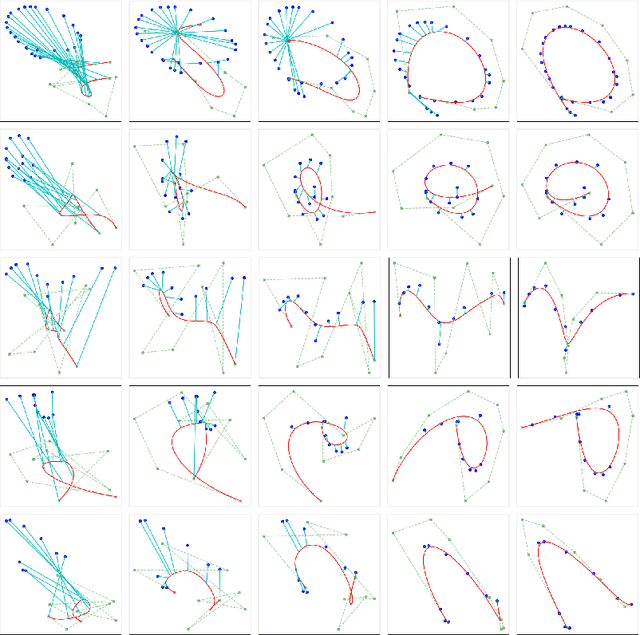
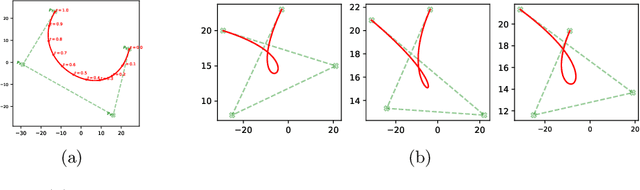
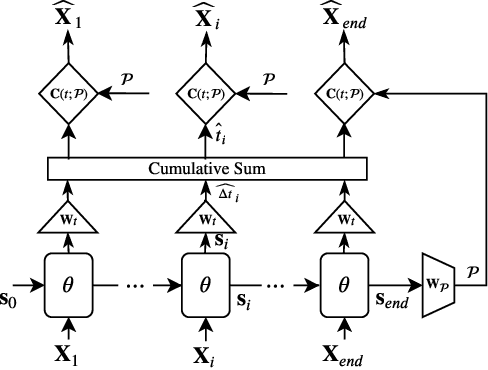
The study of neural generative models of human sketches is a fascinating contemporary modeling problem due to the links between sketch image generation and the human drawing process. The landmark SketchRNN provided breakthrough by sequentially generating sketches as a sequence of waypoints. However this leads to low-resolution image generation, and failure to model long sketches. In this paper we present B\'ezierSketch, a novel generative model for fully vector sketches that are automatically scalable and high-resolution. To this end, we first introduce a novel inverse graphics approach to stroke embedding that trains an encoder to embed each stroke to its best fit B\'ezier curve. This enables us to treat sketches as short sequences of paramaterized strokes and thus train a recurrent sketch generator with greater capacity for longer sketches, while producing scalable high-resolution results. We report qualitative and quantitative results on the Quick, Draw! benchmark.
On Learning Semantic Representations for Million-Scale Free-Hand Sketches
Jul 07, 2020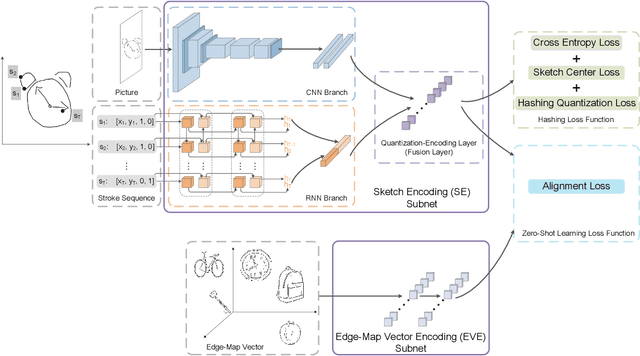
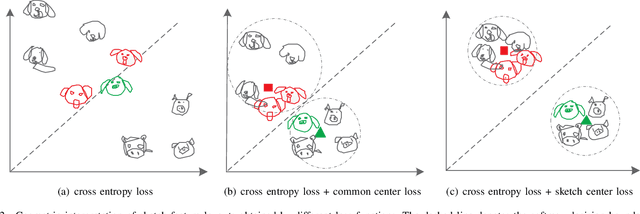
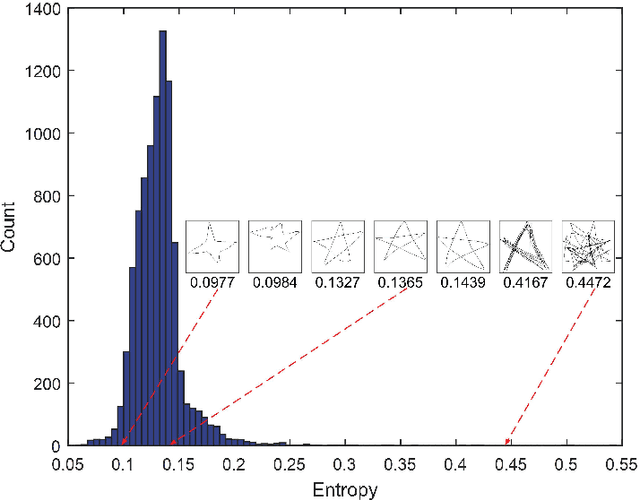

In this paper, we study learning semantic representations for million-scale free-hand sketches. This is highly challenging due to the domain-unique traits of sketches, e.g., diverse, sparse, abstract, noisy. We propose a dual-branch CNNRNN network architecture to represent sketches, which simultaneously encodes both the static and temporal patterns of sketch strokes. Based on this architecture, we further explore learning the sketch-oriented semantic representations in two challenging yet practical settings, i.e., hashing retrieval and zero-shot recognition on million-scale sketches. Specifically, we use our dual-branch architecture as a universal representation framework to design two sketch-specific deep models: (i) We propose a deep hashing model for sketch retrieval, where a novel hashing loss is specifically designed to accommodate both the abstract and messy traits of sketches. (ii) We propose a deep embedding model for sketch zero-shot recognition, via collecting a large-scale edge-map dataset and proposing to extract a set of semantic vectors from edge-maps as the semantic knowledge for sketch zero-shot domain alignment. Both deep models are evaluated by comprehensive experiments on million-scale sketches and outperform the state-of-the-art competitors.
Sequential Learning for Domain Generalization
Apr 03, 2020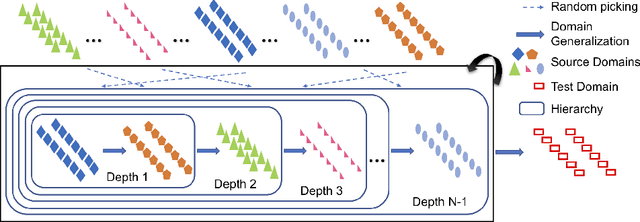


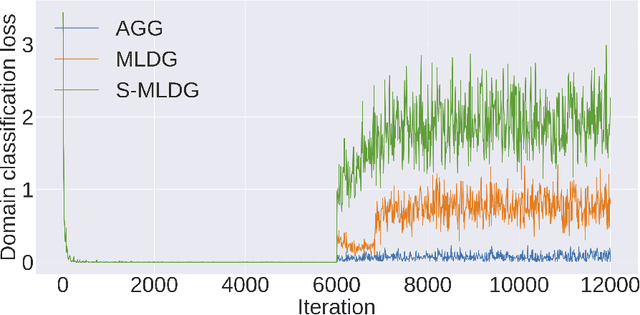
In this paper we propose a sequential learning framework for Domain Generalization (DG), the problem of training a model that is robust to domain shift by design. Various DG approaches have been proposed with different motivating intuitions, but they typically optimize for a single step of domain generalization -- training on one set of domains and generalizing to one other. Our sequential learning is inspired by the idea lifelong learning, where accumulated experience means that learning the $n^{th}$ thing becomes easier than the $1^{st}$ thing. In DG this means encountering a sequence of domains and at each step training to maximise performance on the next domain. The performance at domain $n$ then depends on the previous $n-1$ learning problems. Thus backpropagating through the sequence means optimizing performance not just for the next domain, but all following domains. Training on all such sequences of domains provides dramatically more `practice' for a base DG learner compared to existing approaches, thus improving performance on a true testing domain. This strategy can be instantiated for different base DG algorithms, but we focus on its application to the recently proposed Meta-Learning Domain generalization (MLDG). We show that for MLDG it leads to a simple to implement and fast algorithm that provides consistent performance improvement on a variety of DG benchmarks.