 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Interpretable Deep Networks for Monocular Depth Estimation
Aug 11, 2021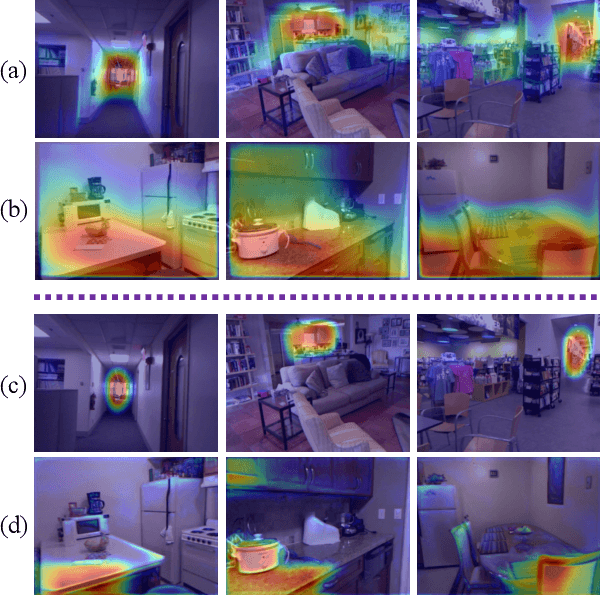

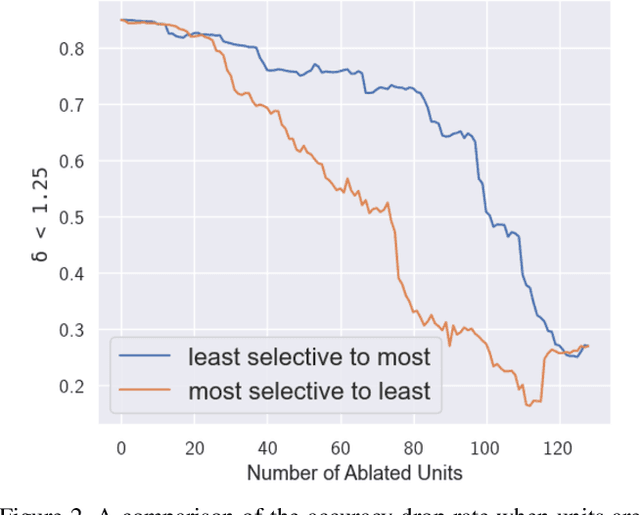
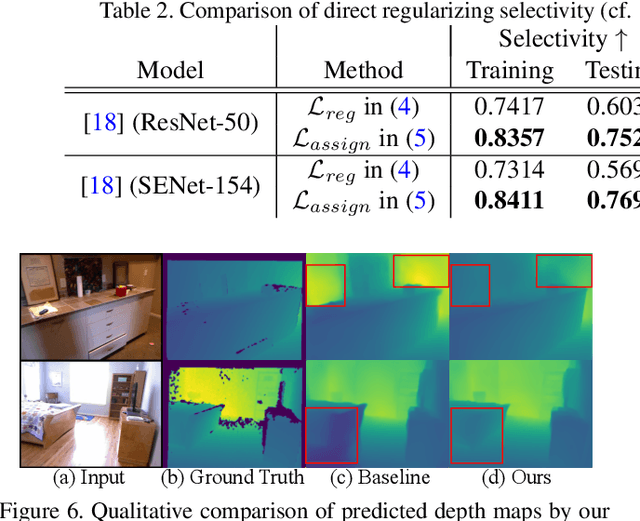
Deep networks for Monocular Depth Estimation (MDE) have achieved promising performance recently and it is of great importance to further understand the interpretability of these networks. Existing methods attempt to provide posthoc explanations by investigating visual cues, which may not explore the internal representations learned by deep networks. In this paper, we find that some hidden units of the network are selective to certain ranges of depth, and thus such behavior can be served as a way to interpret the internal representations. Based on our observations, we quantify the interpretability of a deep MDE network by the depth selectivity of its hidden units. Moreover, we then propose a method to train interpretable MDE deep networks without changing their original architectures, by assigning a depth range for each unit to select. Experimental results demonstrate that our method is able to enhance the interpretability of deep MDE networks by largely improving the depth selectivity of their units, while not harming or even improving the depth estimation accuracy. We further provide a comprehensive analysis to show the reliability of selective units, the applicability of our method on different layers, models, and datasets, and a demonstration on analysis of model error. Source code and models are available at https://github.com/youzunzhi/InterpretableMDE .
End-to-end Multi-modal Video Temporal Grounding
Jul 12, 2021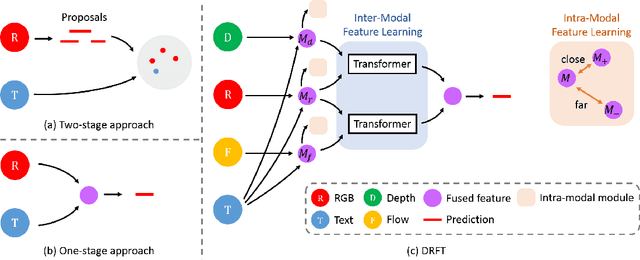

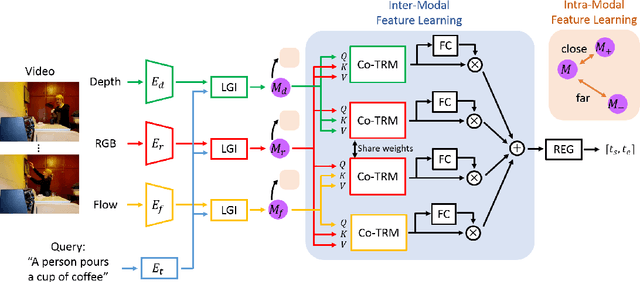
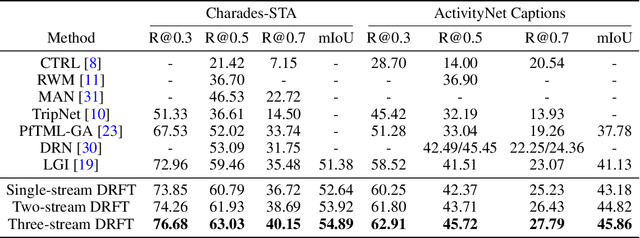
We address the problem of text-guided video temporal grounding, which aims to identify the time interval of certain event based on a natural language description. Different from most existing methods that only consider RGB images as visual features, we propose a multi-modal framework to extract complementary information from videos. Specifically, we adopt RGB images for appearance, optical flow for motion, and depth maps for image structure. While RGB images provide abundant visual cues of certain event, the performance may be affected by background clutters. Therefore, we use optical flow to focus on large motion and depth maps to infer the scene configuration when the action is related to objects recognizable with their shapes. To integrate the three modalities more effectively and enable inter-modal learning, we design a dynamic fusion scheme with transformers to model the interactions between modalities. Furthermore, we apply intra-modal self-supervised learning to enhance feature representations across videos for each modality, which also facilitates multi-modal learning. We conduct extensive experiments on the Charades-STA and ActivityNet Captions datasets, and show that the proposed method performs favorably against state-of-the-art approaches.
Robust 360-8PA: Redesigning The Normalized 8-point Algorithm for 360-FoV Images
Apr 22, 2021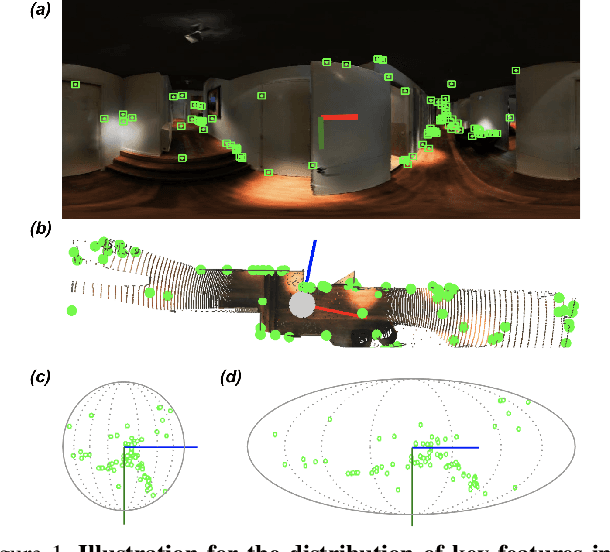
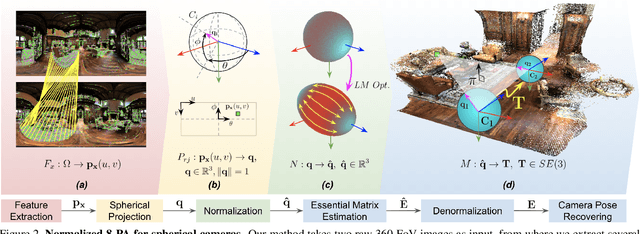
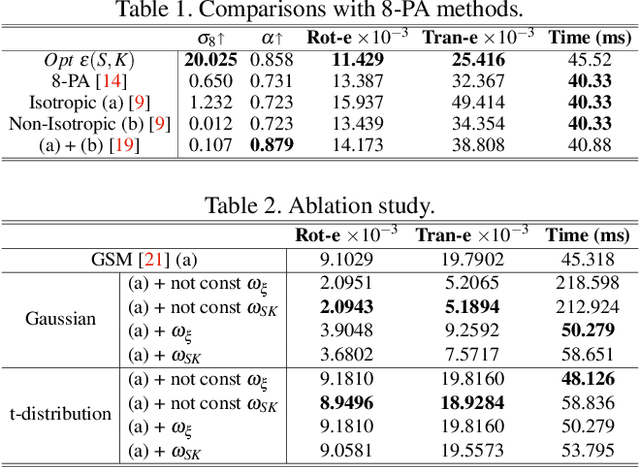
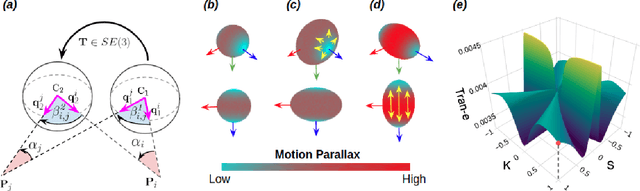
This paper presents a novel preconditioning strategy for the classic 8-point algorithm (8-PA) for estimating an essential matrix from 360-FoV images (i.e., equirectangular images) in spherical projection. To alleviate the effect of uneven key-feature distributions and outlier correspondences, which can potentially decrease the accuracy of an essential matrix, our method optimizes a non-rigid transformation to deform a spherical camera into a new spatial domain, defining a new constraint and a more robust and accurate solution for an essential matrix. Through several experiments using random synthetic points, 360-FoV, and fish-eye images, we demonstrate that our normalization can increase the camera pose accuracy by about 20% without significantly overhead the computation time. In addition, we present further benefits of our method through both a constant weighted least-square optimization that improves further the well known Gold Standard Method (GSM) (i.e., the non-linear optimization by using epipolar errors); and a relaxation of the number of RANSAC iterations, both showing that our normalization outcomes a more reliable, robust, and accurate solution.
Understanding Synonymous Referring Expressions via Contrastive Features
Apr 20, 2021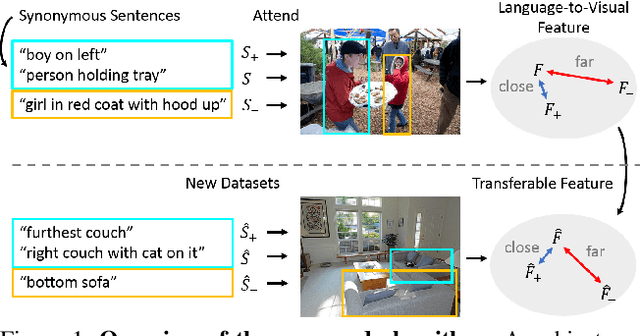
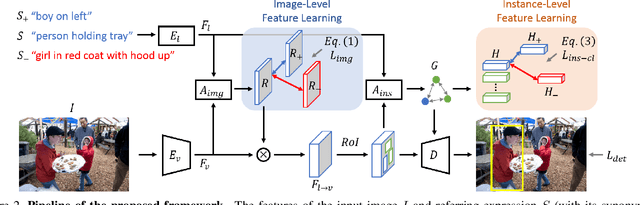
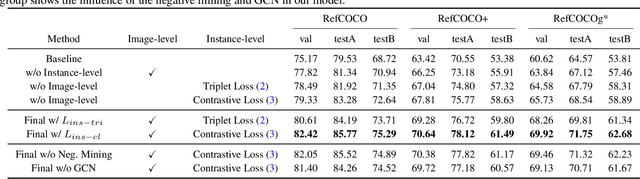
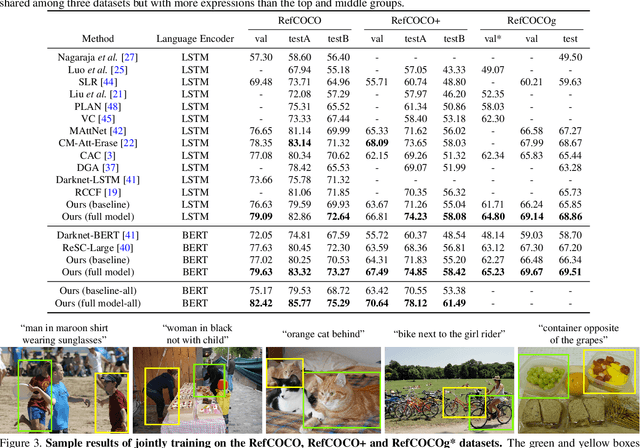
Referring expression comprehension aims to localize objects identified by natural language descriptions. This is a challenging task as it requires understanding of both visual and language domains. One nature is that each object can be described by synonymous sentences with paraphrases, and such varieties in languages have critical impact on learning a comprehension model. While prior work usually treats each sentence and attends it to an object separately, we focus on learning a referring expression comprehension model that considers the property in synonymous sentences. To this end, we develop an end-to-end trainable framework to learn contrastive features on the image and object instance levels, where features extracted from synonymous sentences to describe the same object should be closer to each other after mapping to the visual domain. We conduct extensive experiments to evaluate the proposed algorithm on several benchmark datasets, and demonstrate that our method performs favorably against the state-of-the-art approaches. Furthermore, since the varieties in expressions become larger across datasets when they describe objects in different ways, we present the cross-dataset and transfer learning settings to validate the ability of our learned transferable features.
LED2-Net: Monocular 360 Layout Estimation via Differentiable Depth Rendering
Apr 03, 2021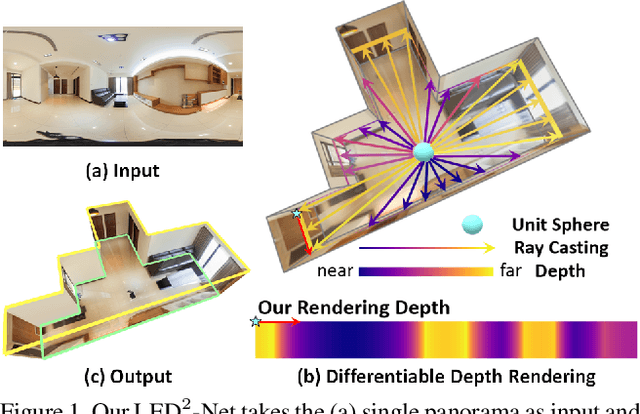
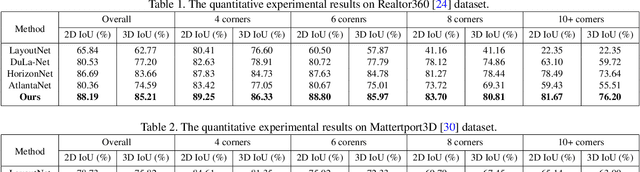


Although significant progress has been made in room layout estimation, most methods aim to reduce the loss in the 2D pixel coordinate rather than exploiting the room structure in the 3D space. Towards reconstructing the room layout in 3D, we formulate the task of 360 layout estimation as a problem of predicting depth on the horizon line of a panorama. Specifically, we propose the Differentiable Depth Rendering procedure to make the conversion from layout to depth prediction differentiable, thus making our proposed model end-to-end trainable while leveraging the 3D geometric information, without the need of providing the ground truth depth. Our method achieves state-of-the-art performance on numerous 360 layout benchmark datasets. Moreover, our formulation enables a pre-training step on the depth dataset, which further improves the generalizability of our layout estimation model.
Cross-Domain Similarity Learning for Face Recognition in Unseen Domains
Mar 12, 2021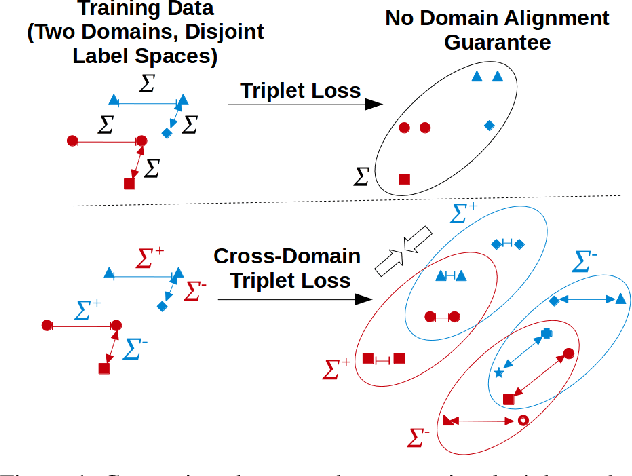
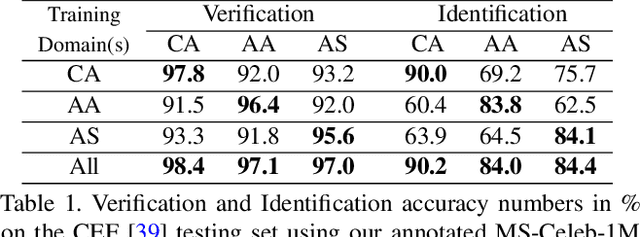
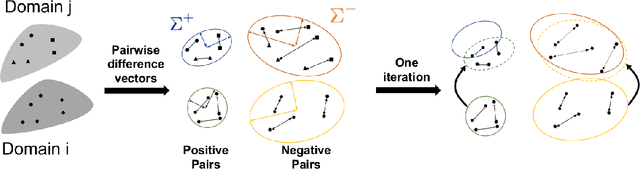
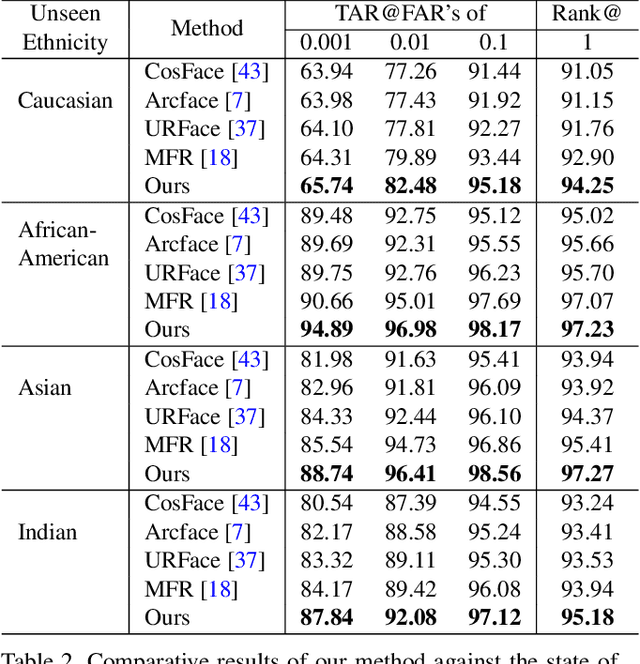
Face recognition models trained under the assumption of identical training and test distributions often suffer from poor generalization when faced with unknown variations, such as a novel ethnicity or unpredictable individual make-ups during test time. In this paper, we introduce a novel cross-domain metric learning loss, which we dub Cross-Domain Triplet (CDT) loss, to improve face recognition in unseen domains. The CDT loss encourages learning semantically meaningful features by enforcing compact feature clusters of identities from one domain, where the compactness is measured by underlying similarity metrics that belong to another training domain with different statistics. Intuitively, it discriminatively correlates explicit metrics derived from one domain, with triplet samples from another domain in a unified loss function to be minimized within a network, which leads to better alignment of the training domains. The network parameters are further enforced to learn generalized features under domain shift, in a model-agnostic learning pipeline. Unlike the recent work of Meta Face Recognition, our method does not require careful hard-pair sample mining and filtering strategy during training. Extensive experiments on various face recognition benchmarks show the superiority of our method in handling variations, compared to baseline and the state-of-the-art methods.
Voting-based Approaches For Differentially Private Federated Learning
Oct 09, 2020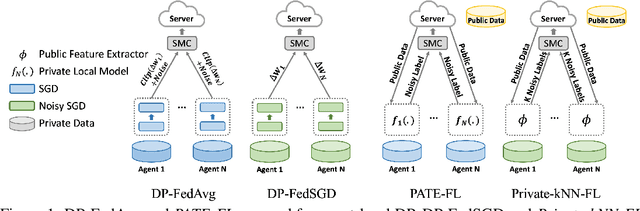
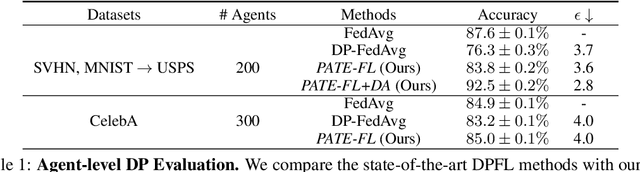
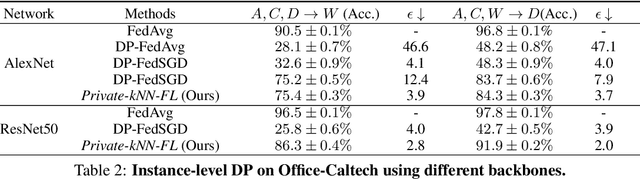
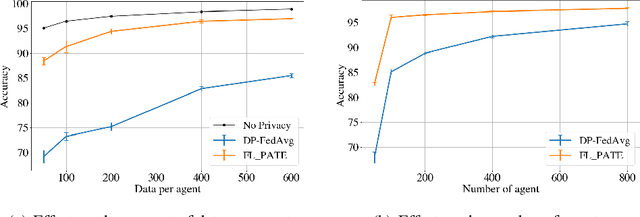
While federated learning (FL) enables distributed agents to collaboratively train a centralized model without sharing data with each other, it fails to protect users against inference attacks that mine private information from the centralized model. Thus, facilitating federated learning methods with differential privacy (DPFL) becomes attractive. Existing algorithms based on privately aggregating clipped gradients require many rounds of communication, which may not converge, and cannot scale up to large-capacity models due to explicit dimension-dependence in its added noise. In this paper, we adopt the knowledge transfer model of private learning pioneered by Papernot et al. (2017; 2018) and extend their algorithm PATE, as well as the recent alternative PrivateKNN (Zhu et al., 2020) to the federated learning setting. The key difference is that our method privately aggregates the labels from the agents in a voting scheme, instead of aggregating the gradients, hence avoiding the dimension dependence and achieving significant savings in communication cost. Theoretically, we show that when the margins of the voting scores are large, the agents enjoy exponentially higher accuracy and stronger (data-dependent) differential privacy guarantees on both agent-level and instance-level. Extensive experiments show that our approach significantly improves the privacy-utility trade-off over the current state-of-the-art in DPFL.
Every Pixel Matters: Center-aware Feature Alignment for Domain Adaptive Object Detector
Aug 19, 2020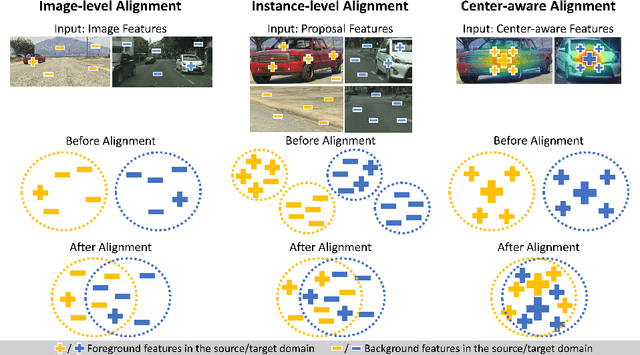
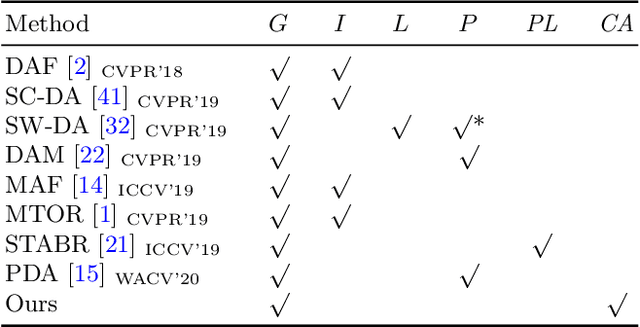
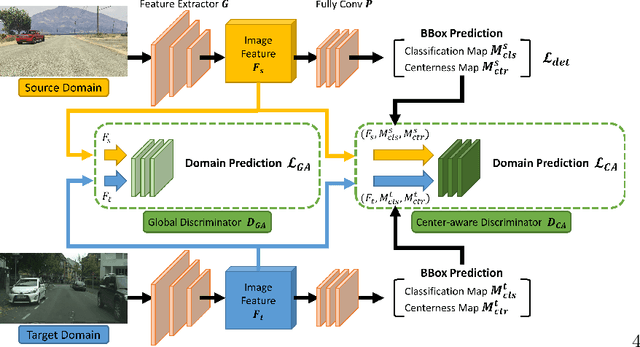
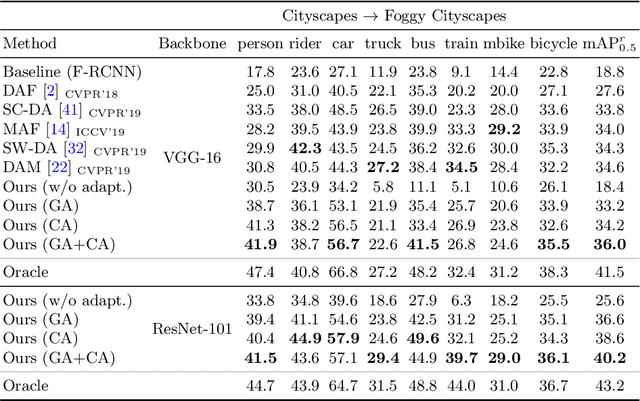
A domain adaptive object detector aims to adapt itself to unseen domains that may contain variations of object appearance, viewpoints or backgrounds. Most existing methods adopt feature alignment either on the image level or instance level. However, image-level alignment on global features may tangle foreground/background pixels at the same time, while instance-level alignment using proposals may suffer from the background noise. Different from existing solutions, we propose a domain adaptation framework that accounts for each pixel via predicting pixel-wise objectness and centerness. Specifically, the proposed method carries out center-aware alignment by paying more attention to foreground pixels, hence achieving better adaptation across domains. We demonstrate our method on numerous adaptation settings with extensive experimental results and show favorable performance against existing state-of-the-art algorithms.
Object Detection with a Unified Label Space from Multiple Datasets
Aug 15, 2020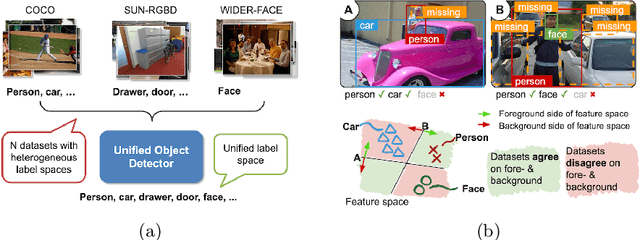

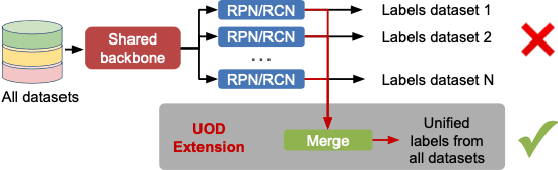
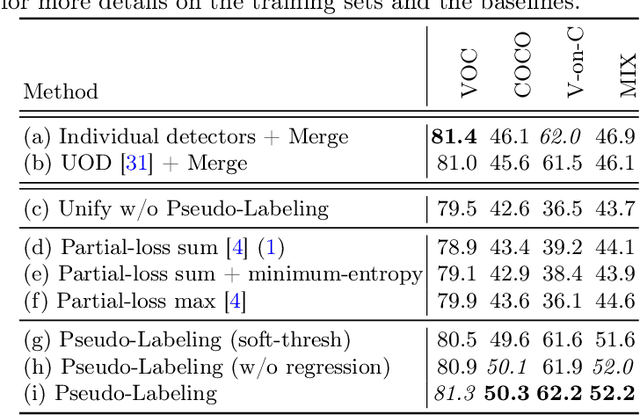
Given multiple datasets with different label spaces, the goal of this work is to train a single object detector predicting over the union of all the label spaces. The practical benefits of such an object detector are obvious and significant application-relevant categories can be picked and merged form arbitrary existing datasets. However, naive merging of datasets is not possible in this case, due to inconsistent object annotations. Consider an object category like faces that is annotated in one dataset, but is not annotated in another dataset, although the object itself appears in the latter images. Some categories, like face here, would thus be considered foreground in one dataset, but background in another. To address this challenge, we design a framework which works with such partial annotations, and we exploit a pseudo labeling approach that we adapt for our specific case. We propose loss functions that carefully integrate partial but correct annotations with complementary but noisy pseudo labels. Evaluation in the proposed novel setting requires full annotation on the test set. We collect the required annotations and define a new challenging experimental setup for this task based one existing public datasets. We show improved performances compared to competitive baselines and appropriate adaptations of existing work.
Learning to Caricature via Semantic Shape Transform
Aug 13, 2020

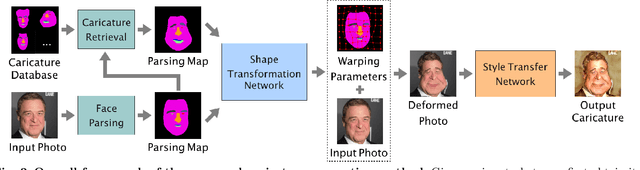
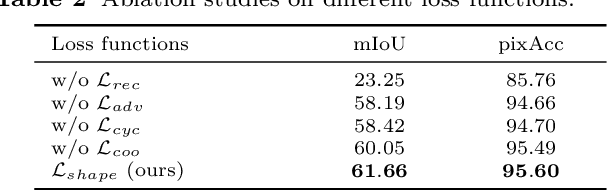
Caricature is an artistic drawing created to abstract or exaggerate facial features of a person. Rendering visually pleasing caricatures is a difficult task that requires professional skills, and thus it is of great interest to design a method to automatically generate such drawings. To deal with large shape changes, we propose an algorithm based on a semantic shape transform to produce diverse and plausible shape exaggerations. Specifically, we predict pixel-wise semantic correspondences and perform image warping on the input photo to achieve dense shape transformation. We show that the proposed framework is able to render visually pleasing shape exaggerations while maintaining their facial structures. In addition, our model allows users to manipulate the shape via the semantic map. We demonstrate the effectiveness of our approach on a large photograph-caricature benchmark dataset with comparisons to the state-of-the-art methods.