 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTragedy Plus Time: Capturing Unintended Human Activities from Weakly-labeled Videos
Apr 28, 2022
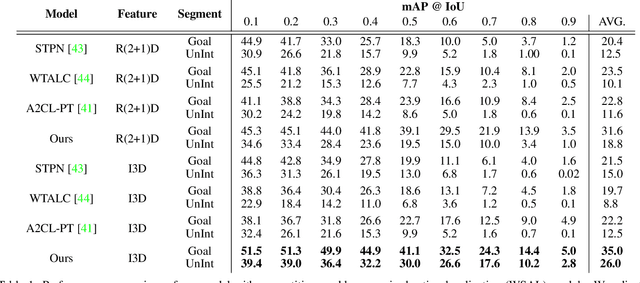
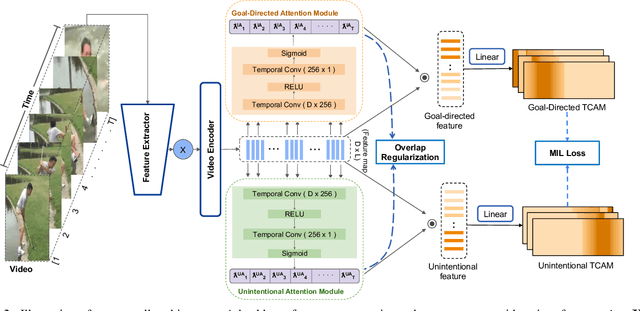
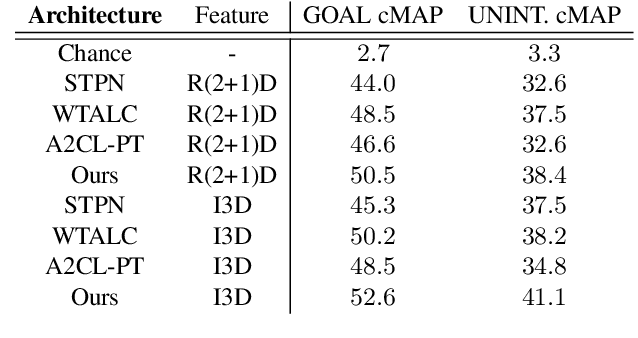
In videos that contain actions performed unintentionally, agents do not achieve their desired goals. In such videos, it is challenging for computer vision systems to understand high-level concepts such as goal-directed behavior, an ability present in humans from a very early age. Inculcating this ability in artificially intelligent agents would make them better social learners by allowing them to evaluate human action under a teleological lens. To validate the ability of deep learning models to perform this task, we curate the W-Oops dataset, built upon the Oops dataset [15]. W-Oops consists of 2,100 unintentional human action videos, with 44 goal-directed and 30 unintentional video-level activity labels collected through human annotations. Due to the expensive segment annotation procedure, we propose a weakly supervised algorithm for localizing the goal-directed as well as unintentional temporal regions in the video leveraging solely video-level labels. In particular, we employ an attention mechanism-based strategy that predicts the temporal regions which contribute the most to a classification task. Meanwhile, our designed overlap regularization allows the model to focus on distinct portions of the video for inferring the goal-directed and unintentional activity while guaranteeing their temporal ordering. Extensive quantitative experiments verify the validity of our localization method. We further conduct a video captioning experiment which demonstrates that the proposed localization module does indeed assist teleological action understanding.
SSR-GNNs: Stroke-based Sketch Representation with Graph Neural Networks
Apr 27, 2022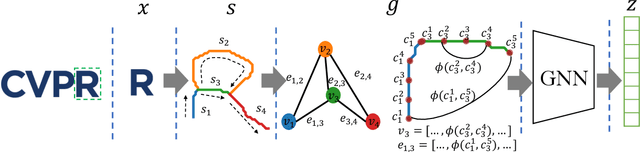
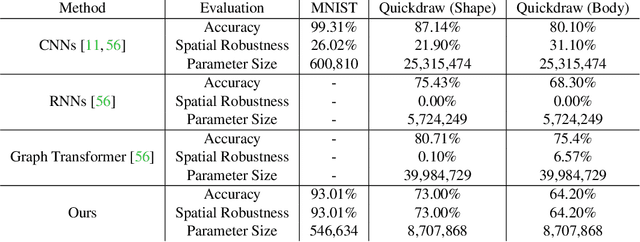
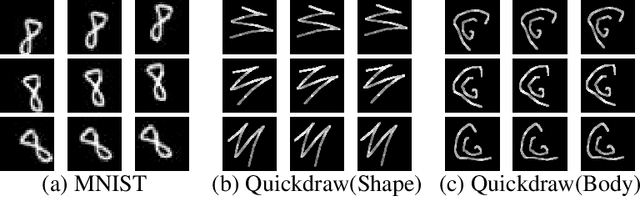
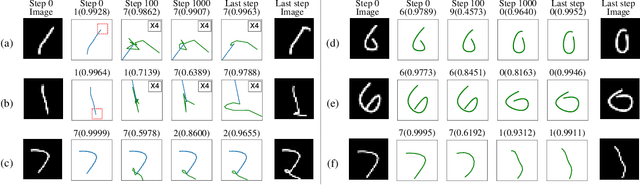
This paper follows cognitive studies to investigate a graph representation for sketches, where the information of strokes, i.e., parts of a sketch, are encoded on vertices and information of inter-stroke on edges. The resultant graph representation facilitates the training of a Graph Neural Networks for classification tasks, and achieves accuracy and robustness comparable to the state-of-the-art against translation and rotation attacks, as well as stronger attacks on graph vertices and topologies, i.e., modifications and addition of strokes, all without resorting to adversarial training. Prior studies on sketches, e.g., graph transformers, encode control points of stroke on vertices, which are not invariant to spatial transformations. In contrary, we encode vertices and edges using pairwise distances among control points to achieve invariance. Compared with existing generative sketch model for one-shot classification, our method does not rely on run-time statistical inference. Lastly, the proposed representation enables generation of novel sketches that are structurally similar to while separable from the existing dataset.
To Find Waldo You Need Contextual Cues: Debiasing Who's Waldo
Mar 30, 2022
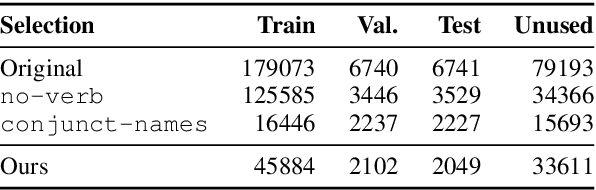
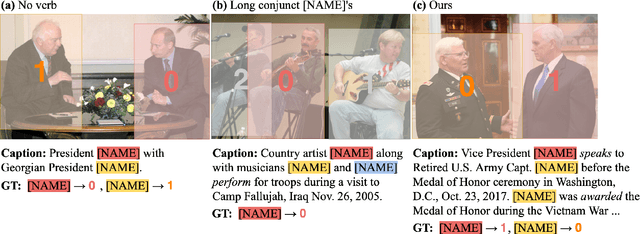
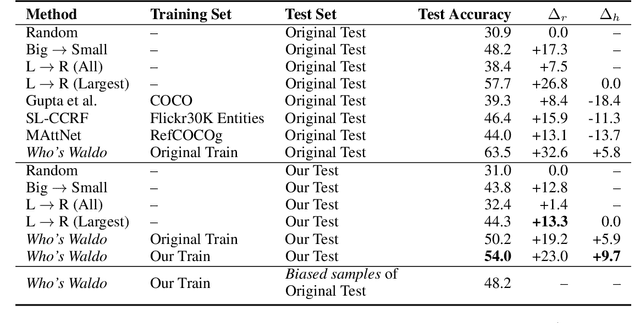
We present a debiased dataset for the Person-centric Visual Grounding (PCVG) task first proposed by Cui et al. (2021) in the Who's Waldo dataset. Given an image and a caption, PCVG requires pairing up a person's name mentioned in a caption with a bounding box that points to the person in the image. We find that the original Who's Waldo dataset compiled for this task contains a large number of biased samples that are solvable simply by heuristic methods; for instance, in many cases the first name in the sentence corresponds to the largest bounding box, or the sequence of names in the sentence corresponds to an exact left-to-right order in the image. Naturally, models trained on these biased data lead to over-estimation of performance on the benchmark. To enforce models being correct for the correct reasons, we design automated tools to filter and debias the original dataset by ruling out all examples of insufficient context, such as those with no verb or with a long chain of conjunct names in their captions. Our experiments show that our new sub-sampled dataset contains less bias with much lowered heuristic performances and widened gaps between heuristic and supervised methods. We also demonstrate the same benchmark model trained on our debiased training set outperforms that trained on the original biased (and larger) training set on our debiased test set. We argue our debiased dataset offers the PCVG task a more practical baseline for reliable benchmarking and future improvements.
Attributable Watermarking of Speech Generative Models
Feb 17, 2022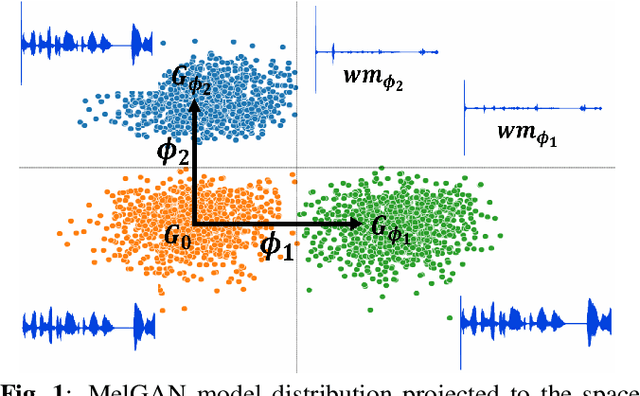
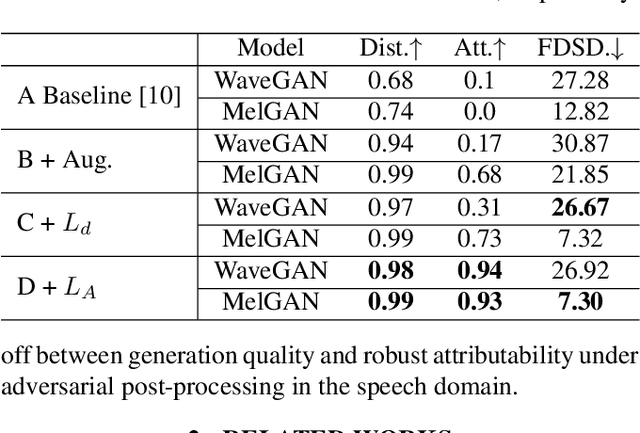
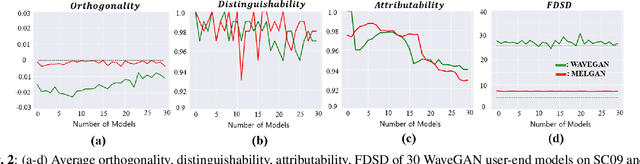
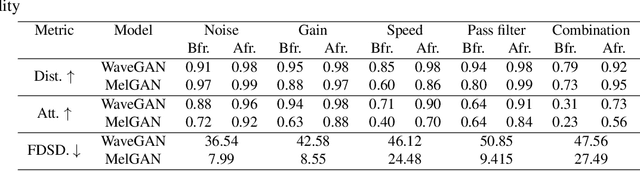
Generative models are now capable of synthesizing images, speeches, and videos that are hardly distinguishable from authentic contents. Such capabilities cause concerns such as malicious impersonation and IP theft. This paper investigates a solution for model attribution, i.e., the classification of synthetic contents by their source models via watermarks embedded in the contents. Building on past success of model attribution in the image domain, we discuss algorithmic improvements for generating user-end speech models that empirically achieve high attribution accuracy, while maintaining high generation quality. We show the trade off between attributability and generation quality under a variety of attacks on generated speech signals attempting to remove the watermarks, and the feasibility of learning robust watermarks against these attacks.
Injecting Semantic Concepts into End-to-End Image Captioning
Dec 09, 2021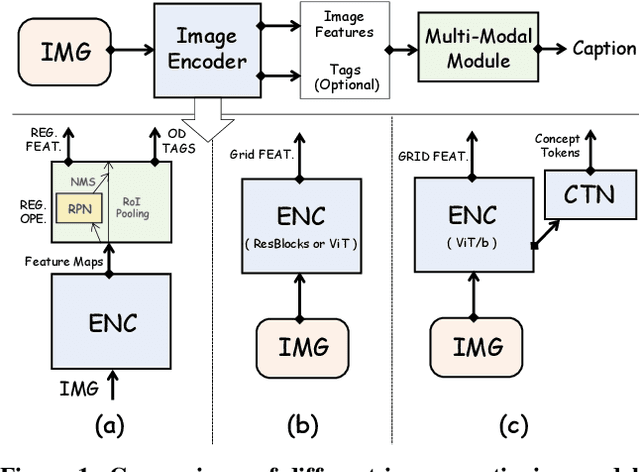
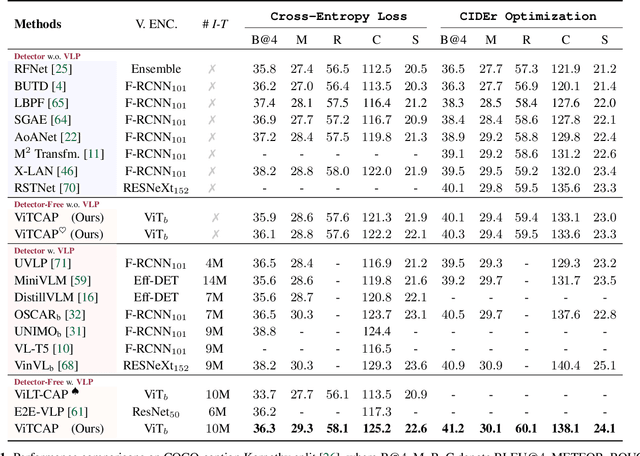
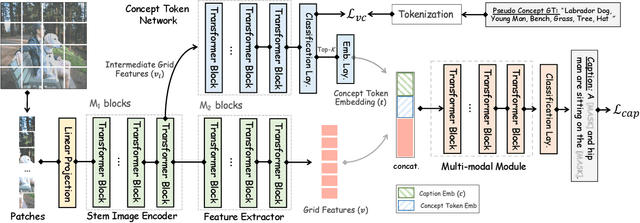
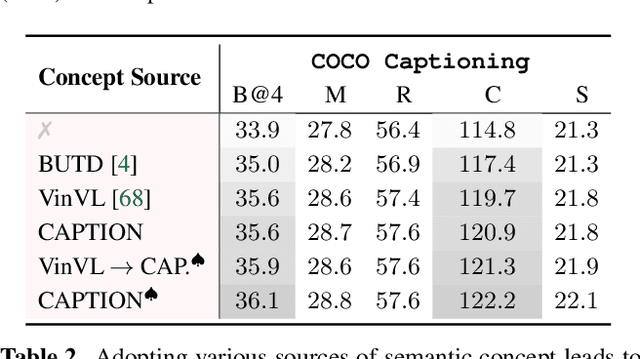
Tremendous progress has been made in recent years in developing better image captioning models, yet most of them rely on a separate object detector to extract regional features. Recent vision-language studies are shifting towards the detector-free trend by leveraging grid representations for more flexible model training and faster inference speed. However, such development is primarily focused on image understanding tasks, and remains less investigated for the caption generation task. In this paper, we are concerned with a better-performing detector-free image captioning model, and propose a pure vision transformer-based image captioning model, dubbed as ViTCAP, in which grid representations are used without extracting the regional features. For improved performance, we introduce a novel Concept Token Network (CTN) to predict the semantic concepts and then incorporate them into the end-to-end captioning. In particular, the CTN is built on the basis of a vision transformer and is designed to predict the concept tokens through a classification task, from which the rich semantic information contained greatly benefits the captioning task. Compared with the previous detector-based models, ViTCAP drastically simplifies the architectures and at the same time achieves competitive performance on various challenging image captioning datasets. In particular, ViTCAP reaches 138.1 CIDEr scores on COCO-caption Karpathy-split, 93.8 and 108.6 CIDEr scores on nocaps, and Google-CC captioning datasets, respectively.
Semantically Distributed Robust Optimization for Vision-and-Language Inference
Oct 14, 2021
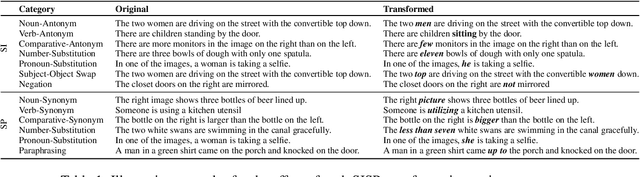
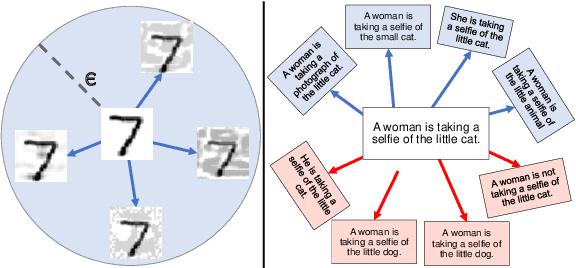
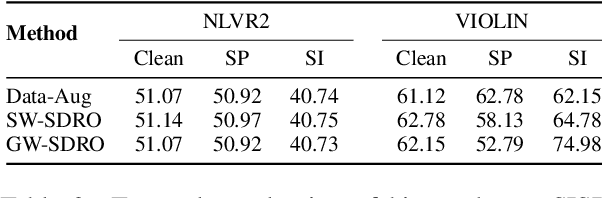
Analysis of vision-and-language models has revealed their brittleness under linguistic phenomena such as paraphrasing, negation, textual entailment, and word substitutions with synonyms or antonyms. While data augmentation techniques have been designed to mitigate against these failure modes, methods that can integrate this knowledge into the training pipeline remain under-explored. In this paper, we present \textbf{SDRO}, a model-agnostic method that utilizes a set linguistic transformations in a distributed robust optimization setting, along with an ensembling technique to leverage these transformations during inference. Experiments on benchmark datasets with images (NLVR$^2$) and video (VIOLIN) demonstrate performance improvements as well as robustness to adversarial attacks. Experiments on binary VQA explore the generalizability of this method to other V\&L tasks.
Targeted Attack on Deep RL-based Autonomous Driving with Learned Visual Patterns
Sep 16, 2021
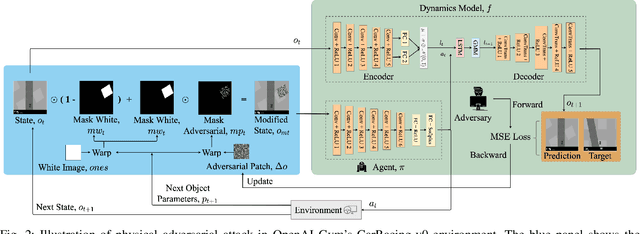
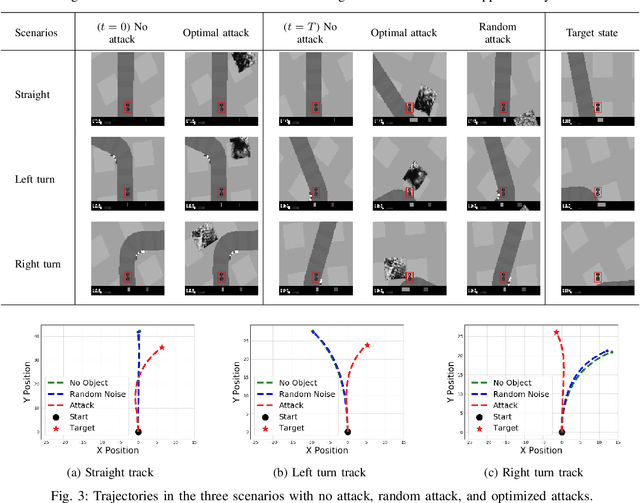
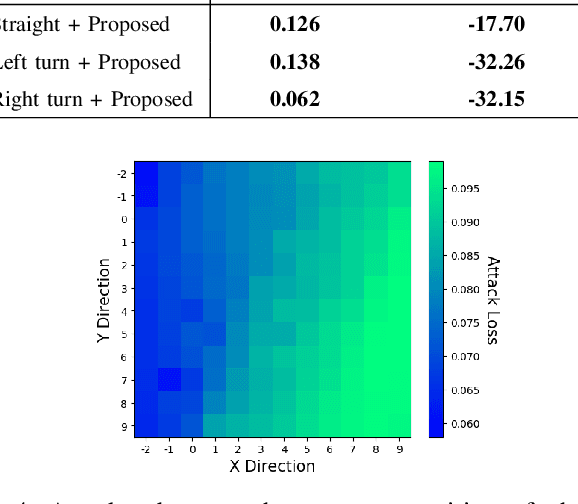
Recent studies demonstrated the vulnerability of control policies learned through deep reinforcement learning against adversarial attacks, raising concerns about the application of such models to risk-sensitive tasks such as autonomous driving. Threat models for these demonstrations are limited to (1) targeted attacks through real-time manipulation of the agent's observation, and (2) untargeted attacks through manipulation of the physical environment. The former assumes full access to the agent's states/observations at all times, while the latter has no control over attack outcomes. This paper investigates the feasibility of targeted attacks through visually learned patterns placed on physical object in the environment, a threat model that combines the practicality and effectiveness of the existing ones. Through analysis, we demonstrate that a pre-trained policy can be hijacked within a time window, e.g., performing an unintended self-parking, when an adversarial object is present. To enable the attack, we adopt an assumption that the dynamics of both the environment and the agent can be learned by the attacker. Lastly, we empirically show the effectiveness of the proposed attack on different driving scenarios, perform a location robustness test, and study the tradeoff between the attack strength and its effectiveness.
Weakly Supervised Relative Spatial Reasoning for Visual Question Answering
Sep 04, 2021
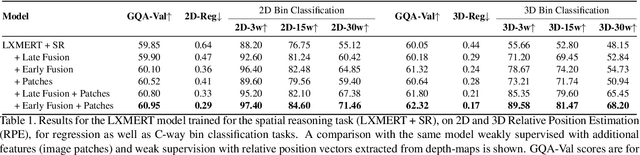
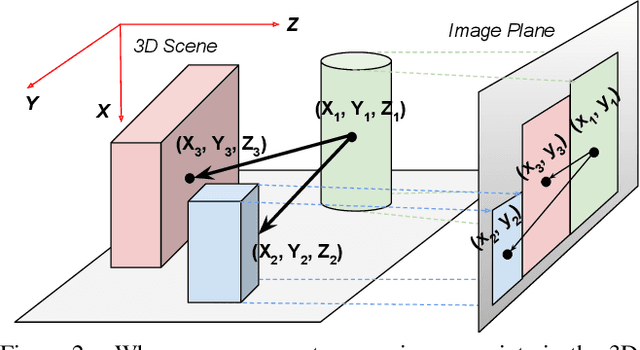
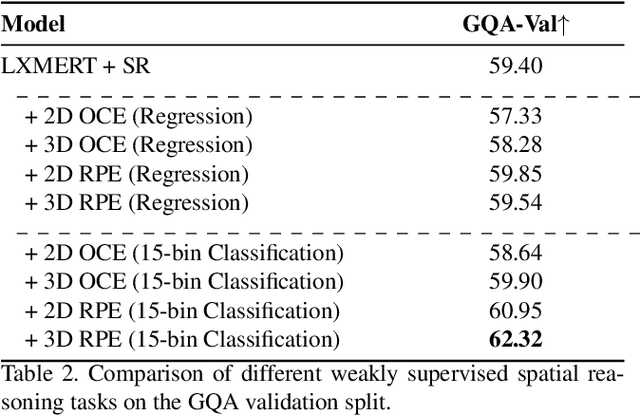
Vision-and-language (V\&L) reasoning necessitates perception of visual concepts such as objects and actions, understanding semantics and language grounding, and reasoning about the interplay between the two modalities. One crucial aspect of visual reasoning is spatial understanding, which involves understanding relative locations of objects, i.e.\ implicitly learning the geometry of the scene. In this work, we evaluate the faithfulness of V\&L models to such geometric understanding, by formulating the prediction of pair-wise relative locations of objects as a classification as well as a regression task. Our findings suggest that state-of-the-art transformer-based V\&L models lack sufficient abilities to excel at this task. Motivated by this, we design two objectives as proxies for 3D spatial reasoning (SR) -- object centroid estimation, and relative position estimation, and train V\&L with weak supervision from off-the-shelf depth estimators. This leads to considerable improvements in accuracy for the "GQA" visual question answering challenge (in fully supervised, few-shot, and O.O.D settings) as well as improvements in relative spatial reasoning. Code and data will be released \href{https://github.com/pratyay-banerjee/weak_sup_vqa}{here}.
SMURF: SeMantic and linguistic UndeRstanding Fusion for Caption Evaluation via Typicality Analysis
Jun 02, 2021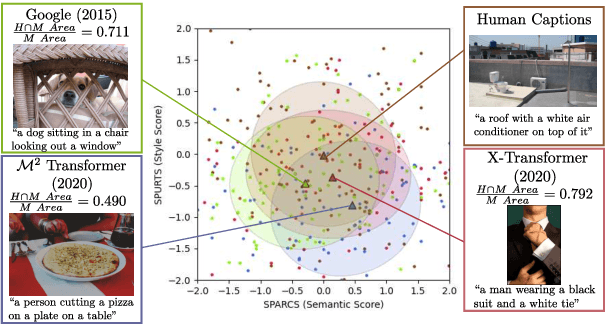
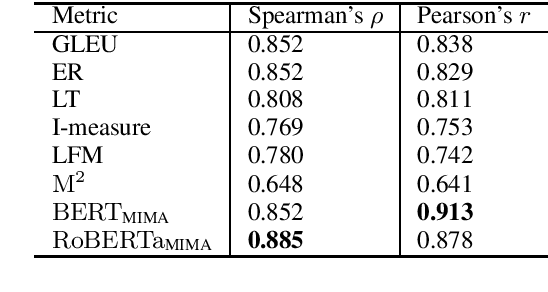
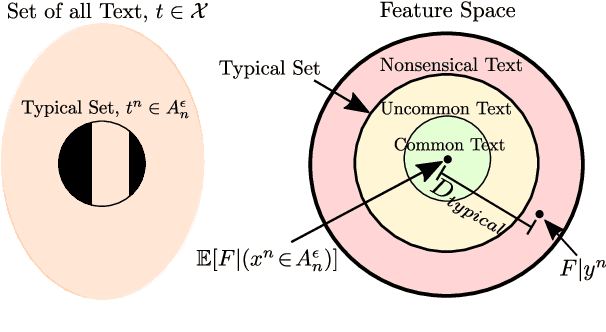
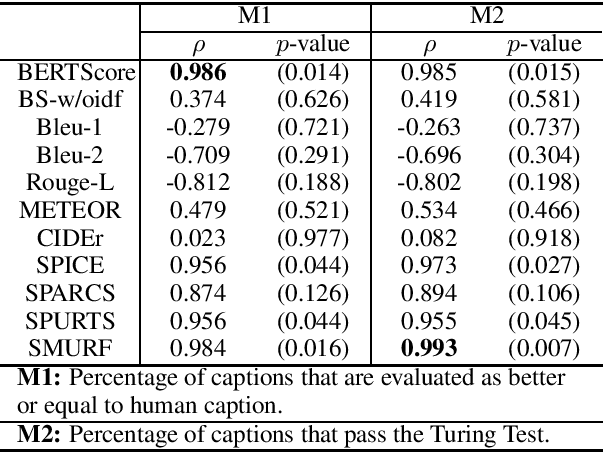
The open-ended nature of visual captioning makes it a challenging area for evaluation. The majority of proposed models rely on specialized training to improve human-correlation, resulting in limited adoption, generalizability, and explainabilty. We introduce "typicality", a new formulation of evaluation rooted in information theory, which is uniquely suited for problems lacking a definite ground truth. Typicality serves as our framework to develop a novel semantic comparison, SPARCS, as well as referenceless fluency evaluation metrics. Over the course of our analysis, two separate dimensions of fluency naturally emerge: style, captured by metric SPURTS, and grammar, captured in the form of grammatical outlier penalties. Through extensive experiments and ablation studies on benchmark datasets, we show how these decomposed dimensions of semantics and fluency provide greater system-level insight into captioner differences. Our proposed metrics along with their combination, SMURF, achieve state-of-the-art correlation with human judgment when compared with other rule-based evaluation metrics.
CLEVR_HYP: A Challenge Dataset and Baselines for Visual Question Answering with Hypothetical Actions over Images
Apr 13, 2021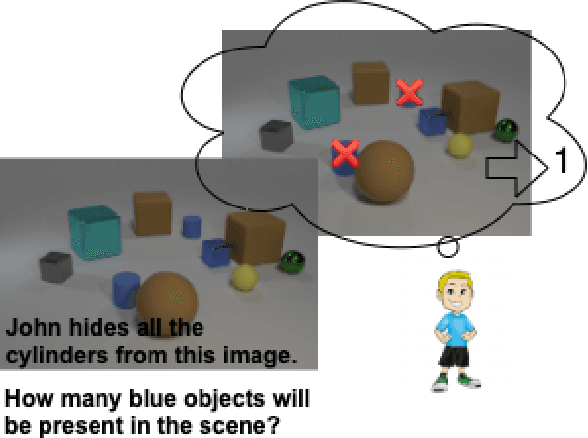


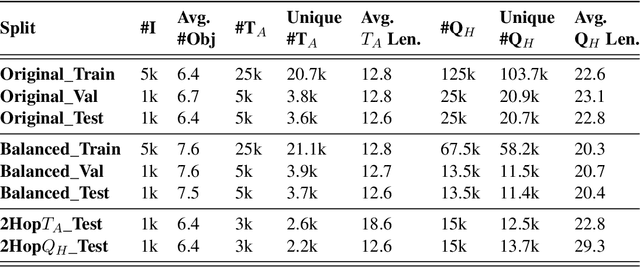
Most existing research on visual question answering (VQA) is limited to information explicitly present in an image or a video. In this paper, we take visual understanding to a higher level where systems are challenged to answer questions that involve mentally simulating the hypothetical consequences of performing specific actions in a given scenario. Towards that end, we formulate a vision-language question answering task based on the CLEVR (Johnson et. al., 2017) dataset. We then modify the best existing VQA methods and propose baseline solvers for this task. Finally, we motivate the development of better vision-language models by providing insights about the capability of diverse architectures to perform joint reasoning over image-text modality. Our dataset setup scripts and codes will be made publicly available at https://github.com/shailaja183/clevr_hyp.