 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Simple Incentives to Improve Two-Sided Fairness in Ridesharing Systems
Mar 25, 2023State-of-the-art order dispatching algorithms for ridesharing batch passenger requests and allocate them to a fleet of vehicles in a centralized manner, optimizing over the estimated values of each passenger-vehicle matching using integer linear programming (ILP). Using good estimates of future values, such ILP-based approaches are able to significantly increase the service rates (percentage of requests served) for a fixed fleet of vehicles. However, such approaches that focus solely on maximizing efficiency can lead to disparities for both drivers (e.g., income inequality) and passengers (e.g., inequality of service for different groups). Existing approaches that consider fairness only do it for naive assignment policies, require extensive training, or look at only single-sided fairness. We propose a simple incentive-based fairness scheme that can be implemented online as a part of this ILP formulation that allows us to improve fairness over a variety of fairness metrics. Deriving from a lens of variance minimization, we describe how these fairness incentives can be formulated for two distinct use cases for passenger groups and driver fairness. We show that under mild conditions, our approach can guarantee an improvement in the chosen metric for the worst-off individual. We also show empirically that our Simple Incentives approach significantly outperforms prior art, despite requiring no retraining; indeed, it often leads to a large improvement over the state-of-the-art fairness-aware approach in both overall service rate and fairness.
Certified Robust Control under Adversarial Perturbations
Feb 04, 2023Autonomous systems increasingly rely on machine learning techniques to transform high-dimensional raw inputs into predictions that are then used for decision-making and control. However, it is often easy to maliciously manipulate such inputs and, as a result, predictions. While effective techniques have been proposed to certify the robustness of predictions to adversarial input perturbations, such techniques have been disembodied from control systems that make downstream use of the predictions. We propose the first approach for composing robustness certification of predictions with respect to raw input perturbations with robust control to obtain certified robustness of control to adversarial input perturbations. We use a case study of adaptive vehicle control to illustrate our approach and show the value of the resulting end-to-end certificates through extensive experiments.
Certifying Safety in Reinforcement Learning under Adversarial Perturbation Attacks
Dec 28, 2022
Function approximation has enabled remarkable advances in applying reinforcement learning (RL) techniques in environments with high-dimensional inputs, such as images, in an end-to-end fashion, mapping such inputs directly to low-level control. Nevertheless, these have proved vulnerable to small adversarial input perturbations. A number of approaches for improving or certifying robustness of end-to-end RL to adversarial perturbations have emerged as a result, focusing on cumulative reward. However, what is often at stake in adversarial scenarios is the violation of fundamental properties, such as safety, rather than the overall reward that combines safety with efficiency. Moreover, properties such as safety can only be defined with respect to true state, rather than the high-dimensional raw inputs to end-to-end policies. To disentangle nominal efficiency and adversarial safety, we situate RL in deterministic partially-observable Markov decision processes (POMDPs) with the goal of maximizing cumulative reward subject to safety constraints. We then propose a partially-supervised reinforcement learning (PSRL) framework that takes advantage of an additional assumption that the true state of the POMDP is known at training time. We present the first approach for certifying safety of PSRL policies under adversarial input perturbations, and two adversarial training approaches that make direct use of PSRL. Our experiments demonstrate both the efficacy of the proposed approach for certifying safety in adversarial environments, and the value of the PSRL framework coupled with adversarial training in improving certified safety while preserving high nominal reward and high-quality predictions of true state.
A Visual Active Search Framework for Geospatial Exploration
Nov 28, 2022



Many problems can be viewed as forms of geospatial search aided by aerial imagery, with examples ranging from detecting poaching activity to human trafficking. We model this class of problems in a visual active search (VAS) framework, which takes as input an image of a broad area, and aims to identify as many examples of a target object as possible. It does this through a limited sequence of queries, each of which verifies whether an example is present in a given region. We propose a reinforcement learning approach for VAS that leverages a collection of fully annotated search tasks as training data to learn a search policy, and combines features of the input image with a natural representation of active search state. Additionally, we propose domain adaptation techniques to improve the policy at decision time when training data is not fully reflective of the test-time distribution of VAS tasks. Through extensive experiments on several satellite imagery datasets, we show that the proposed approach significantly outperforms several strong baselines. Code and data will be made public.
Reward Delay Attacks on Deep Reinforcement Learning
Sep 08, 2022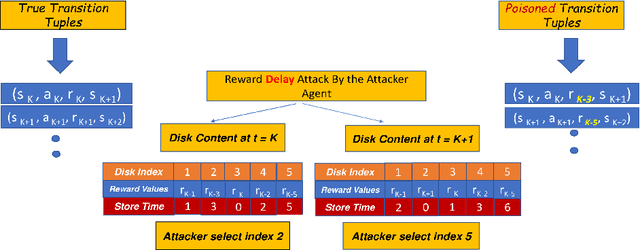
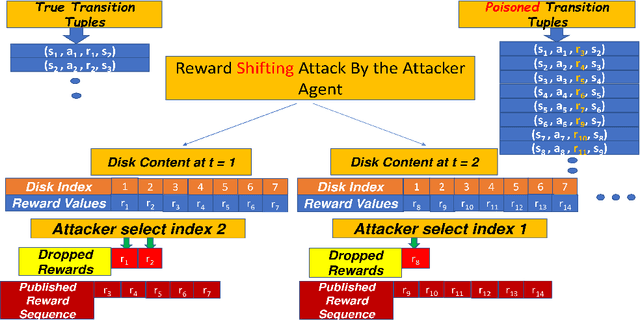
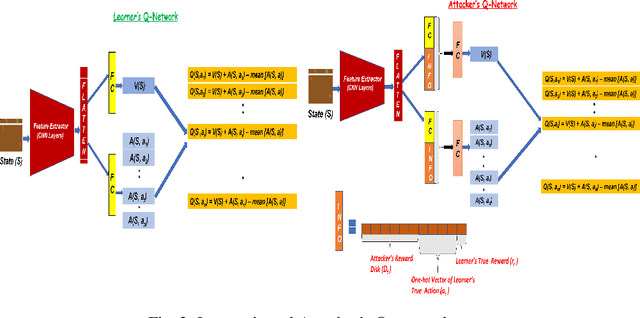
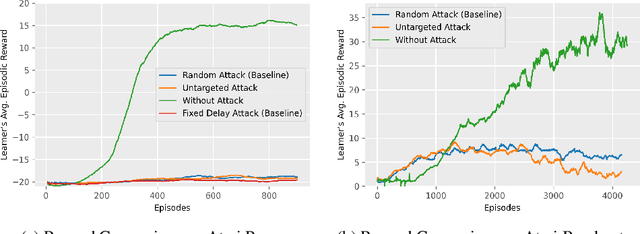
Most reinforcement learning algorithms implicitly assume strong synchrony. We present novel attacks targeting Q-learning that exploit a vulnerability entailed by this assumption by delaying the reward signal for a limited time period. We consider two types of attack goals: targeted attacks, which aim to cause a target policy to be learned, and untargeted attacks, which simply aim to induce a policy with a low reward. We evaluate the efficacy of the proposed attacks through a series of experiments. Our first observation is that reward-delay attacks are extremely effective when the goal is simply to minimize reward. Indeed, we find that even naive baseline reward-delay attacks are also highly successful in minimizing the reward. Targeted attacks, on the other hand, are more challenging, although we nevertheless demonstrate that the proposed approaches remain highly effective at achieving the attacker's targets. In addition, we introduce a second threat model that captures a minimal mitigation that ensures that rewards cannot be used out of sequence. We find that this mitigation remains insufficient to ensure robustness to attacks that delay, but preserve the order, of rewards.
Robust Deep Reinforcement Learning through Bootstrapped Opportunistic Curriculum
Jun 21, 2022
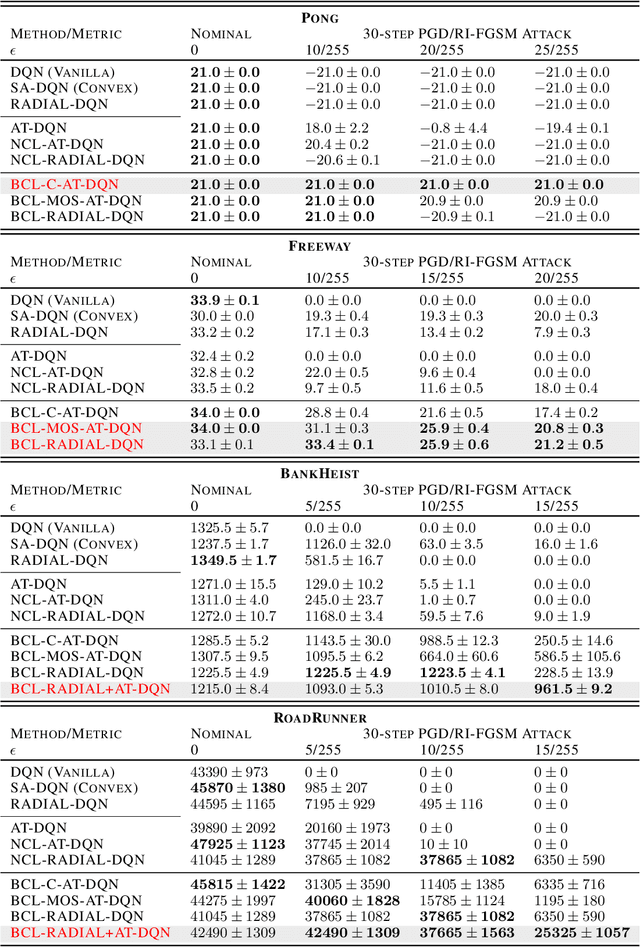
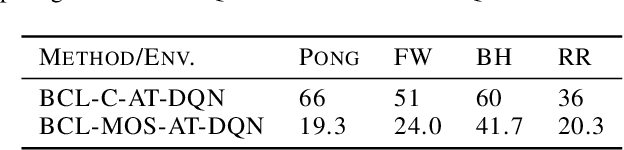

Despite considerable advances in deep reinforcement learning, it has been shown to be highly vulnerable to adversarial perturbations to state observations. Recent efforts that have attempted to improve adversarial robustness of reinforcement learning can nevertheless tolerate only very small perturbations, and remain fragile as perturbation size increases. We propose Bootstrapped Opportunistic Adversarial Curriculum Learning (BCL), a novel flexible adversarial curriculum learning framework for robust reinforcement learning. Our framework combines two ideas: conservatively bootstrapping each curriculum phase with highest quality solutions obtained from multiple runs of the previous phase, and opportunistically skipping forward in the curriculum. In our experiments we show that the proposed BCL framework enables dramatic improvements in robustness of learned policies to adversarial perturbations. The greatest improvement is for Pong, where our framework yields robustness to perturbations of up to 25/255; in contrast, the best existing approach can only tolerate adversarial noise up to 5/255. Our code is available at: https://github.com/jlwu002/BCL.
Proceedings of the Artificial Intelligence for Cyber Security (AICS) Workshop at AAAI 2022
Mar 01, 2022The workshop will focus on the application of AI to problems in cyber security. Cyber systems generate large volumes of data, utilizing this effectively is beyond human capabilities. Additionally, adversaries continue to develop new attacks. Hence, AI methods are required to understand and protect the cyber domain. These challenges are widely studied in enterprise networks, but there are many gaps in research and practice as well as novel problems in other domains. In general, AI techniques are still not widely adopted in the real world. Reasons include: (1) a lack of certification of AI for security, (2) a lack of formal study of the implications of practical constraints (e.g., power, memory, storage) for AI systems in the cyber domain, (3) known vulnerabilities such as evasion, poisoning attacks, (4) lack of meaningful explanations for security analysts, and (5) lack of analyst trust in AI solutions. There is a need for the research community to develop novel solutions for these practical issues.
Networked Restless Multi-Armed Bandits for Mobile Interventions
Jan 28, 2022
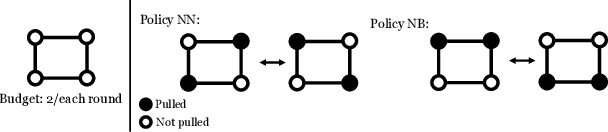
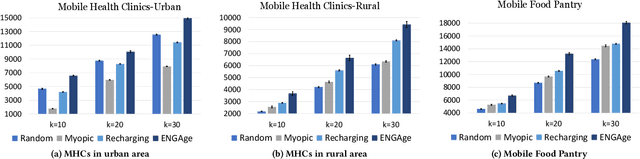
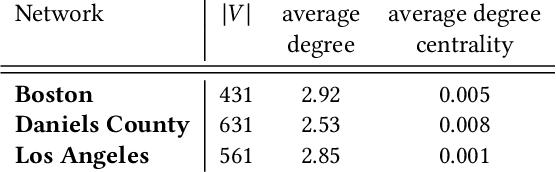
Motivated by a broad class of mobile intervention problems, we propose and study restless multi-armed bandits (RMABs) with network effects. In our model, arms are partially recharging and connected through a graph, so that pulling one arm also improves the state of neighboring arms, significantly extending the previously studied setting of fully recharging bandits with no network effects. In mobile interventions, network effects may arise due to regular population movements (such as commuting between home and work). We show that network effects in RMABs induce strong reward coupling that is not accounted for by existing solution methods. We propose a new solution approach for networked RMABs, exploiting concavity properties which arise under natural assumptions on the structure of intervention effects. We provide sufficient conditions for optimality of our approach in idealized settings and demonstrate that it empirically outperforms state-of-the art baselines in three mobile intervention domains using real-world graphs.
Unfairness Despite Awareness: Group-Fair Classification with Strategic Agents
Dec 06, 2021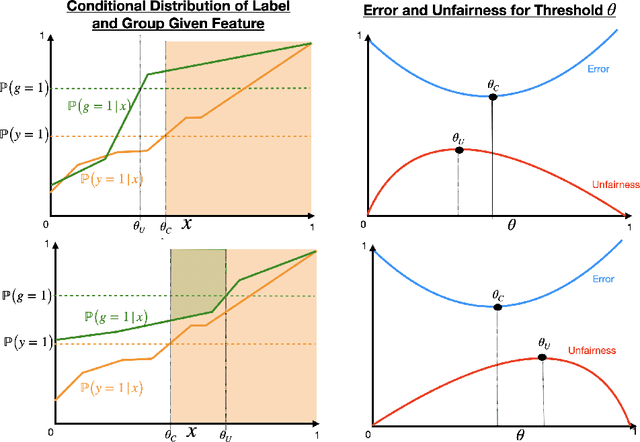
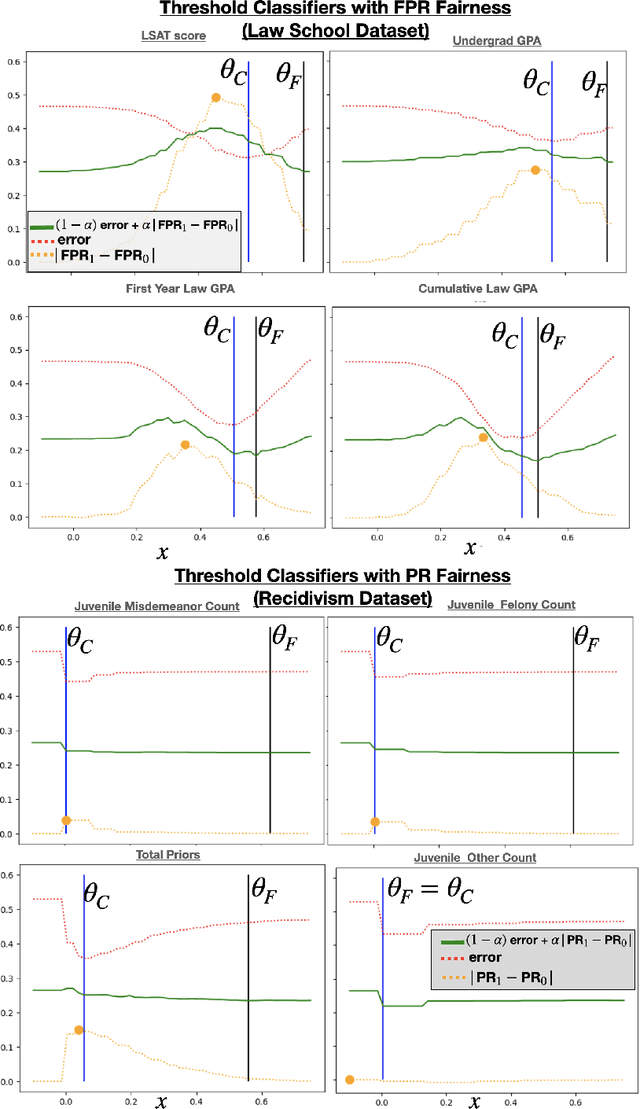
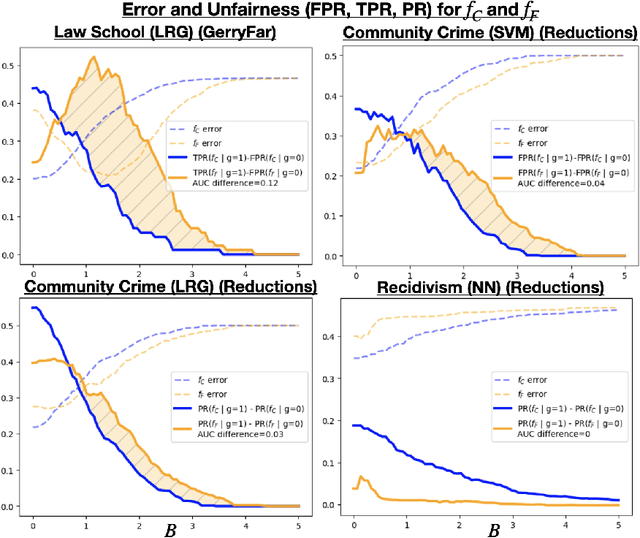
The use of algorithmic decision making systems in domains which impact the financial, social, and political well-being of people has created a demand for these decision making systems to be "fair" under some accepted notion of equity. This demand has in turn inspired a large body of work focused on the development of fair learning algorithms which are then used in lieu of their conventional counterparts. Most analysis of such fair algorithms proceeds from the assumption that the people affected by the algorithmic decisions are represented as immutable feature vectors. However, strategic agents may possess both the ability and the incentive to manipulate this observed feature vector in order to attain a more favorable outcome. We explore the impact that strategic agent behavior could have on fair classifiers and derive conditions under which this behavior leads to fair classifiers becoming less fair than their conventional counterparts under the same measure of fairness that the fair classifier takes into account. These conditions are related to the the way in which the fair classifier remedies unfairness on the original unmanipulated data: fair classifiers which remedy unfairness by becoming more selective than their conventional counterparts are the ones that become less fair than their counterparts when agents are strategic. We further demonstrate that both the increased selectiveness of the fair classifier, and consequently the loss of fairness, arises when performing fair learning on domains in which the advantaged group is overrepresented in the region near (and on the beneficial side of) the decision boundary of conventional classifiers. Finally, we observe experimentally, using several datasets and learning methods, that this fairness reversal is common, and that our theoretical characterization of the fairness reversal conditions indeed holds in most such cases.
PROVES: Establishing Image Provenance using Semantic Signatures
Oct 21, 2021
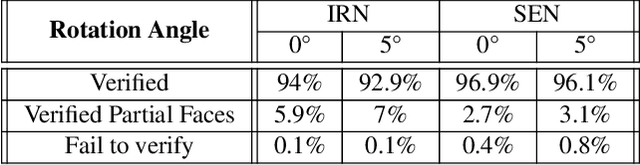
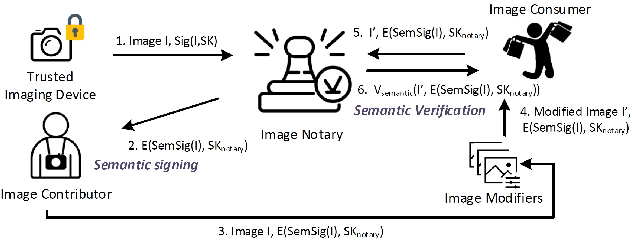
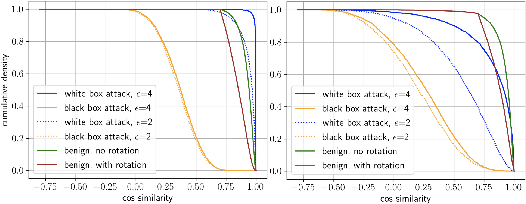
Modern AI tools, such as generative adversarial networks, have transformed our ability to create and modify visual data with photorealistic results. However, one of the deleterious side-effects of these advances is the emergence of nefarious uses in manipulating information in visual data, such as through the use of deep fakes. We propose a novel architecture for preserving the provenance of semantic information in images to make them less susceptible to deep fake attacks. Our architecture includes semantic signing and verification steps. We apply this architecture to verifying two types of semantic information: individual identities (faces) and whether the photo was taken indoors or outdoors. Verification accounts for a collection of common image transformation, such as translation, scaling, cropping, and small rotations, and rejects adversarial transformations, such as adversarially perturbed or, in the case of face verification, swapped faces. Experiments demonstrate that in the case of provenance of faces in an image, our approach is robust to black-box adversarial transformations (which are rejected) as well as benign transformations (which are accepted), with few false negatives and false positives. Background verification, on the other hand, is susceptible to black-box adversarial examples, but becomes significantly more robust after adversarial training.