 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Reweighted Wake-Sleep
May 26, 2018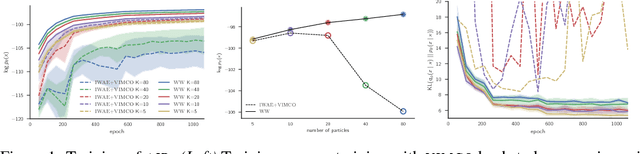
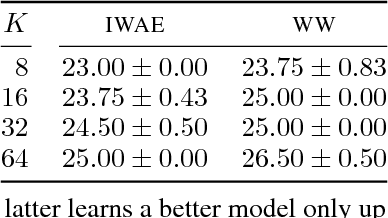
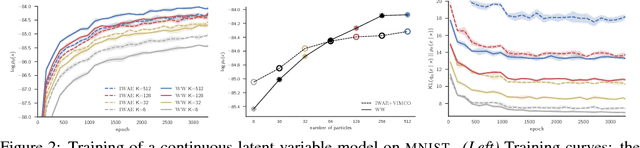
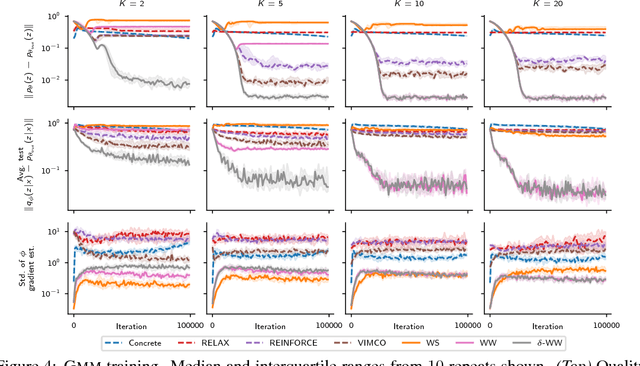
Discrete latent-variable models, while applicable in a variety of settings, can often be difficult to learn. Sampling discrete latent variables can result in high-variance gradient estimators for two primary reasons: 1. branching on the samples within the model, and 2. the lack of a pathwise derivative for the samples. While current state-of-the-art methods employ control-variate schemes for the former and continuous-relaxation methods for the latter, their utility is limited by the complexities of implementing and training effective control-variate schemes and the necessity of evaluating (potentially exponentially) many branch paths in the model. Here, we revisit the reweighted wake-sleep (RWS) (Bornschein and Bengio, 2015) algorithm, and through extensive evaluations, show that it circumvents both these issues, outperforming current state-of-the-art methods in learning discrete latent-variable models. Moreover, we observe that, unlike the importance weighted autoencoder, RWS learns better models and inference networks with increasing numbers of particles, and that its benefits extend to continuous latent-variable models as well. Our results suggest that RWS is a competitive, often preferable, alternative for learning deep generative models.
Causal Inference via Kernel Deviance Measures
Apr 12, 2018


Discovering the causal structure among a set of variables is a fundamental problem in many areas of science. In this paper, we propose Kernel Conditional Deviance for Causal Inference (KCDC) a fully nonparametric causal discovery method based on purely observational data. From a novel interpretation of the notion of asymmetry between cause and effect, we derive a corresponding asymmetry measure using the framework of reproducing kernel Hilbert spaces. Based on this, we propose three decision rules for causal discovery. We demonstrate the wide applicability of our method across a range of diverse synthetic datasets. Furthermore, we test our method on real-world time series data and the real-world benchmark dataset Tubingen Cause-Effect Pairs where we outperform existing state-of-the-art methods.
An Analysis of Categorical Distributional Reinforcement Learning
Feb 22, 2018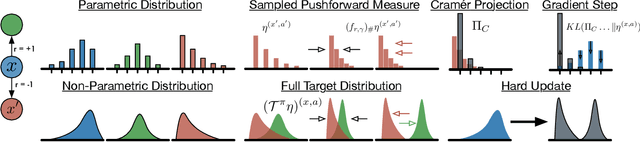
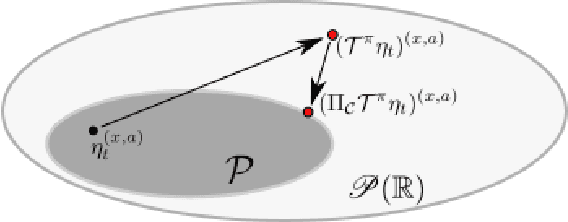
Distributional approaches to value-based reinforcement learning model the entire distribution of returns, rather than just their expected values, and have recently been shown to yield state-of-the-art empirical performance. This was demonstrated by the recently proposed C51 algorithm, based on categorical distributional reinforcement learning (CDRL) [Bellemare et al., 2017]. However, the theoretical properties of CDRL algorithms are not yet well understood. In this paper, we introduce a framework to analyse CDRL algorithms, establish the importance of the projected distributional Bellman operator in distributional RL, draw fundamental connections between CDRL and the Cram\'er distance, and give a proof of convergence for sample-based categorical distributional reinforcement learning algorithms.
Scaling up the Automatic Statistician: Scalable Structure Discovery using Gaussian Processes
Feb 14, 2018
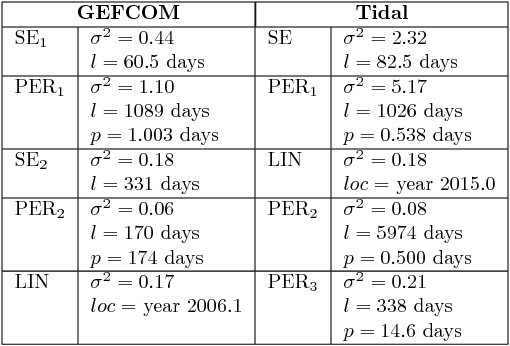
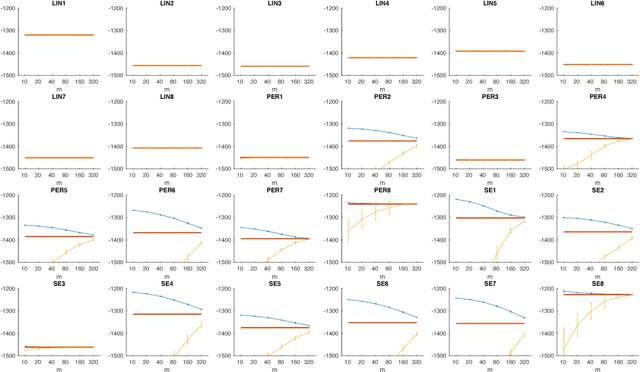
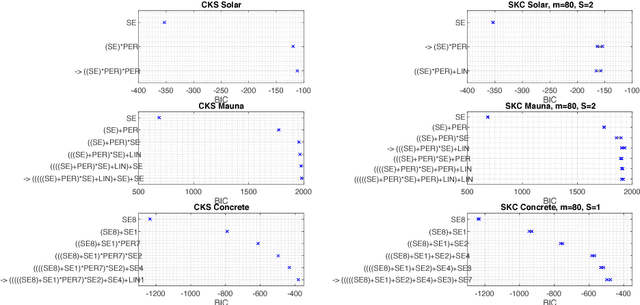
Automating statistical modelling is a challenging problem in artificial intelligence. The Automatic Statistician takes a first step in this direction, by employing a kernel search algorithm with Gaussian Processes (GP) to provide interpretable statistical models for regression problems. However this does not scale due to its $O(N^3)$ running time for the model selection. We propose Scalable Kernel Composition (SKC), a scalable kernel search algorithm that extends the Automatic Statistician to bigger data sets. In doing so, we derive a cheap upper bound on the GP marginal likelihood that sandwiches the marginal likelihood with the variational lower bound . We show that the upper bound is significantly tighter than the lower bound and thus useful for model selection.
Non-exchangeable random partition models for microclustering
Nov 20, 2017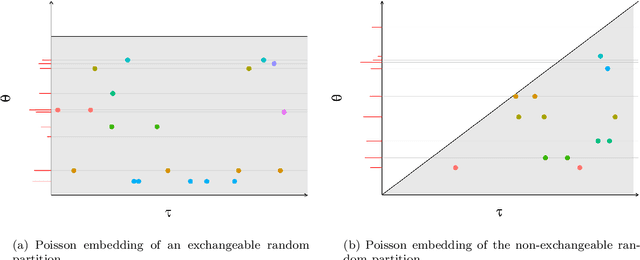

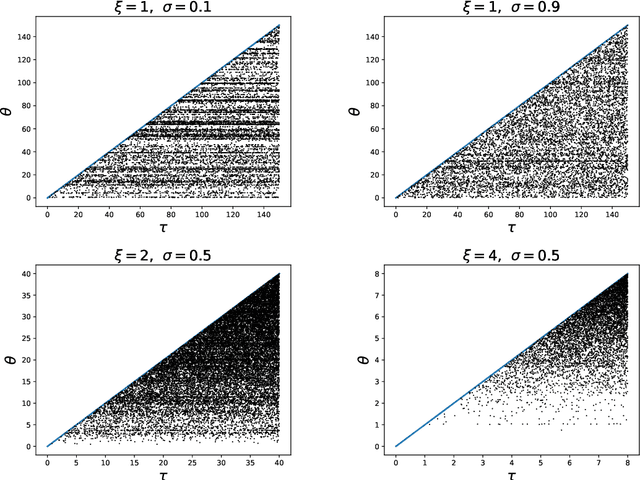
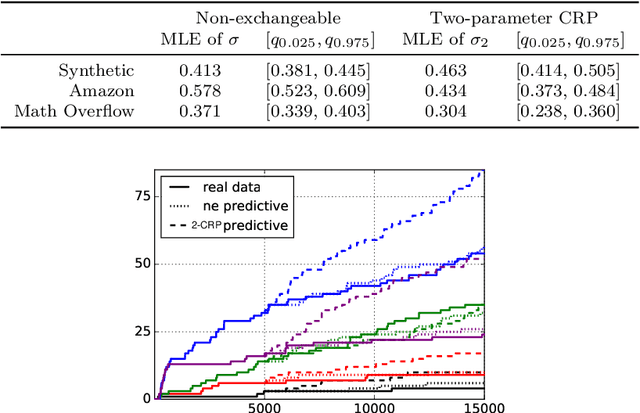
Many popular random partition models, such as the Chinese restaurant process and its two-parameter extension, fall in the class of exchangeable random partitions, and have found wide applicability in model-based clustering, population genetics, ecology or network analysis. While the exchangeability assumption is sensible in many cases, it has some strong implications. In particular, Kingman's representation theorem implies that the size of the clusters necessarily grows linearly with the sample size; this feature may be undesirable for some applications, as recently pointed out by Miller et al. (2015). We present here a flexible class of non-exchangeable random partition models which are able to generate partitions whose cluster sizes grow sublinearly with the sample size, and where the growth rate is controlled by one parameter. Along with this result, we provide the asymptotic behaviour of the number of clusters of a given size, and show that the model can exhibit a power-law behavior, controlled by another parameter. The construction is based on completely random measures and a Poisson embedding of the random partition, and inference is performed using a Sequential Monte Carlo algorithm. Additionally, we show how the model can also be directly used to generate sparse multigraphs with power-law degree distributions and degree sequences with sublinear growth. Finally, experiments on real datasets emphasize the usefulness of the approach compared to a two-parameter Chinese restaurant process.
Filtering Variational Objectives
Nov 12, 2017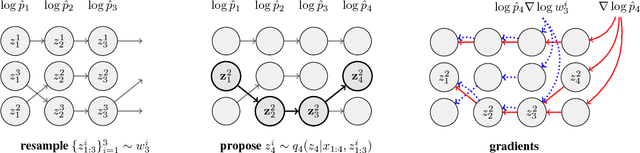
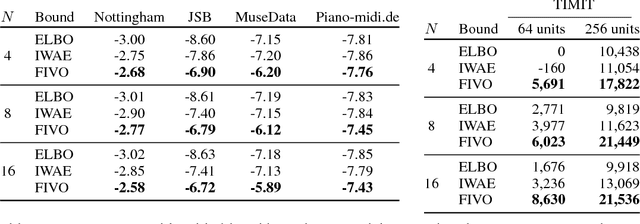
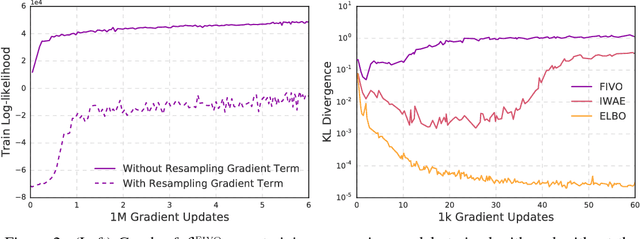
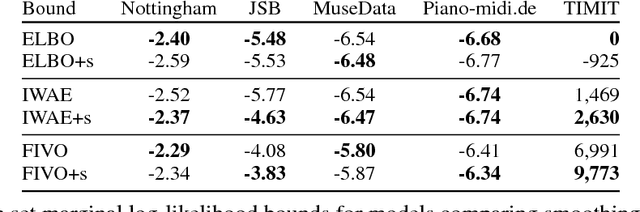
When used as a surrogate objective for maximum likelihood estimation in latent variable models, the evidence lower bound (ELBO) produces state-of-the-art results. Inspired by this, we consider the extension of the ELBO to a family of lower bounds defined by a particle filter's estimator of the marginal likelihood, the filtering variational objectives (FIVOs). FIVOs take the same arguments as the ELBO, but can exploit a model's sequential structure to form tighter bounds. We present results that relate the tightness of FIVO's bound to the variance of the particle filter's estimator by considering the generic case of bounds defined as log-transformed likelihood estimators. Experimentally, we show that training with FIVO results in substantial improvements over training the same model architecture with the ELBO on sequential data.
Distributed Bayesian Learning with Stochastic Natural-gradient Expectation Propagation and the Posterior Server
Sep 07, 2017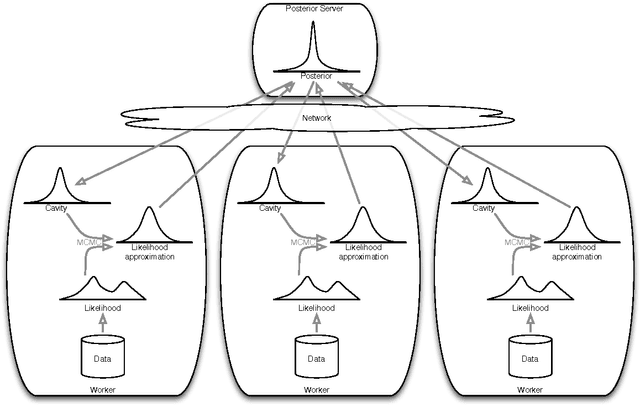
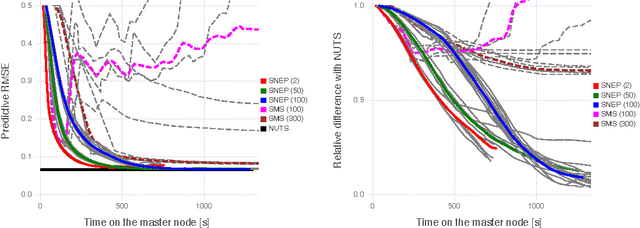
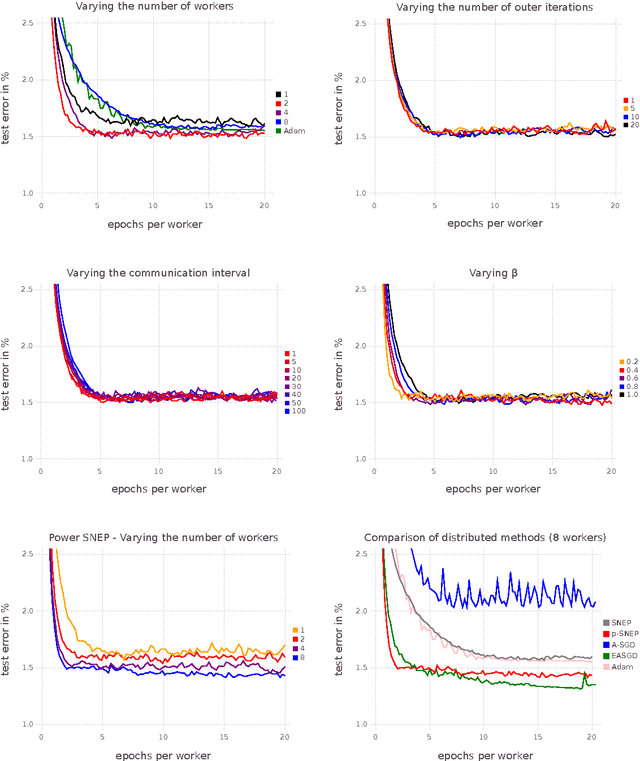
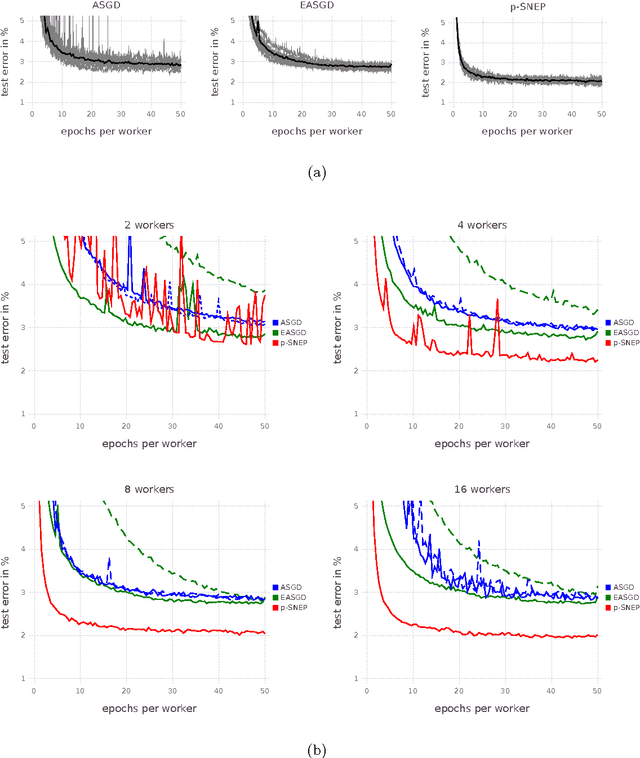
This paper makes two contributions to Bayesian machine learning algorithms. Firstly, we propose stochastic natural gradient expectation propagation (SNEP), a novel alternative to expectation propagation (EP), a popular variational inference algorithm. SNEP is a black box variational algorithm, in that it does not require any simplifying assumptions on the distribution of interest, beyond the existence of some Monte Carlo sampler for estimating the moments of the EP tilted distributions. Further, as opposed to EP which has no guarantee of convergence, SNEP can be shown to be convergent, even when using Monte Carlo moment estimates. Secondly, we propose a novel architecture for distributed Bayesian learning which we call the posterior server. The posterior server allows scalable and robust Bayesian learning in cases where a data set is stored in a distributed manner across a cluster, with each compute node containing a disjoint subset of data. An independent Monte Carlo sampler is run on each compute node, with direct access only to the local data subset, but which targets an approximation to the global posterior distribution given all data across the whole cluster. This is achieved by using a distributed asynchronous implementation of SNEP to pass messages across the cluster. We demonstrate SNEP and the posterior server on distributed Bayesian learning of logistic regression and neural networks. Keywords: Distributed Learning, Large Scale Learning, Deep Learning, Bayesian Learn- ing, Variational Inference, Expectation Propagation, Stochastic Approximation, Natural Gradient, Markov chain Monte Carlo, Parameter Server, Posterior Server.
* 37 pages, 7 figures
Distral: Robust Multitask Reinforcement Learning
Jul 13, 2017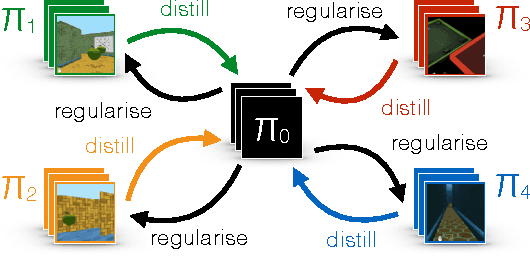

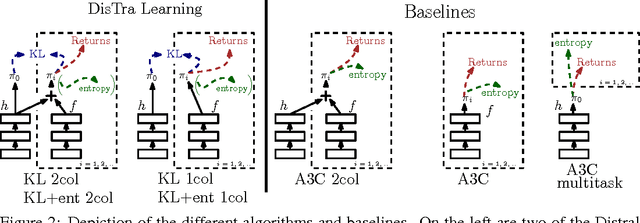
Most deep reinforcement learning algorithms are data inefficient in complex and rich environments, limiting their applicability to many scenarios. One direction for improving data efficiency is multitask learning with shared neural network parameters, where efficiency may be improved through transfer across related tasks. In practice, however, this is not usually observed, because gradients from different tasks can interfere negatively, making learning unstable and sometimes even less data efficient. Another issue is the different reward schemes between tasks, which can easily lead to one task dominating the learning of a shared model. We propose a new approach for joint training of multiple tasks, which we refer to as Distral (Distill & transfer learning). Instead of sharing parameters between the different workers, we propose to share a "distilled" policy that captures common behaviour across tasks. Each worker is trained to solve its own task while constrained to stay close to the shared policy, while the shared policy is trained by distillation to be the centroid of all task policies. Both aspects of the learning process are derived by optimizing a joint objective function. We show that our approach supports efficient transfer on complex 3D environments, outperforming several related methods. Moreover, the proposed learning process is more robust and more stable---attributes that are critical in deep reinforcement learning.
Poisson intensity estimation with reproducing kernels
Jun 26, 2017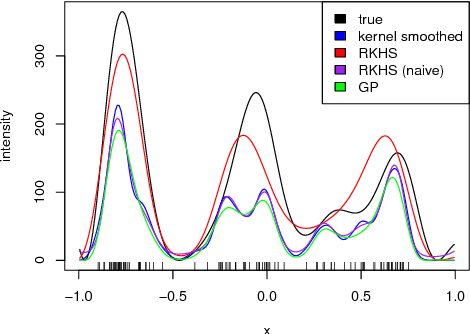
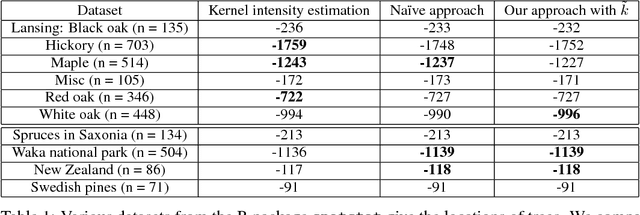
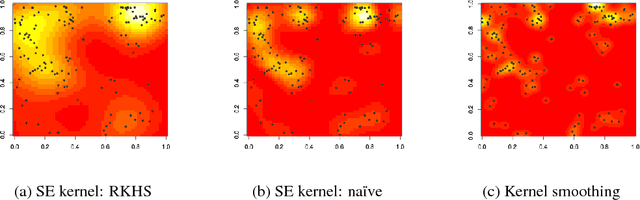
Despite the fundamental nature of the inhomogeneous Poisson process in the theory and application of stochastic processes, and its attractive generalizations (e.g. Cox process), few tractable nonparametric modeling approaches of intensity functions exist, especially when observed points lie in a high-dimensional space. In this paper we develop a new, computationally tractable Reproducing Kernel Hilbert Space (RKHS) formulation for the inhomogeneous Poisson process. We model the square root of the intensity as an RKHS function. Whereas RKHS models used in supervised learning rely on the so-called representer theorem, the form of the inhomogeneous Poisson process likelihood means that the representer theorem does not apply. However, we prove that the representer theorem does hold in an appropriately transformed RKHS, guaranteeing that the optimization of the penalized likelihood can be cast as a tractable finite-dimensional problem. The resulting approach is simple to implement, and readily scales to high dimensions and large-scale datasets.
Collaborative Filtering with Side Information: a Gaussian Process Perspective
Jun 08, 2017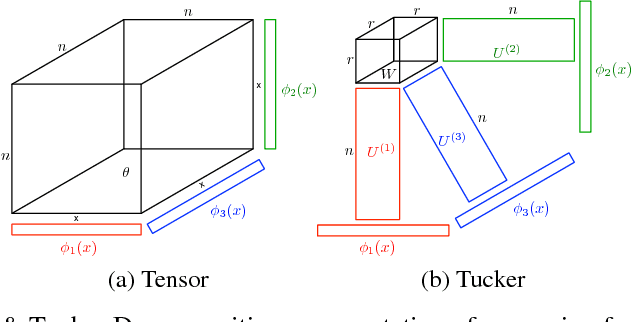
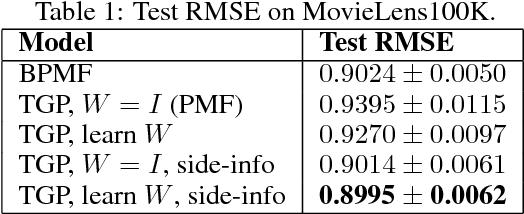

We tackle the problem of collaborative filtering (CF) with side information, through the lens of Gaussian Process (GP) regression. Driven by the idea of using the kernel to explicitly model user-item similarities, we formulate the GP in a way that allows the incorporation of low-rank matrix factorisation, arriving at our model, the Tucker Gaussian Process (TGP). Consequently, TGP generalises classical Bayesian matrix factorisation models, and goes beyond them to give a natural and elegant method for incorporating side information, giving enhanced predictive performance for CF problems. Moreover we show that it is a novel model for regression, especially well-suited to grid-structured data and problems where the dependence on covariates is close to being separable.