 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualized Streaming End-to-End Speech Recognition with Trie-Based Deep Biasing and Shallow Fusion
Apr 05, 2021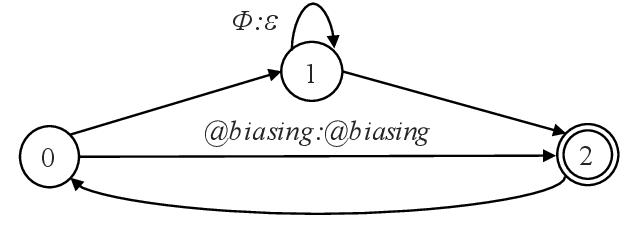
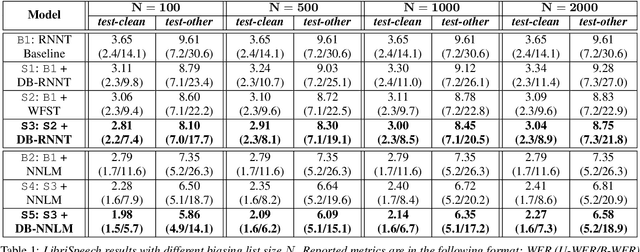
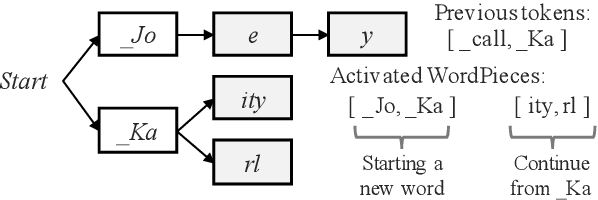
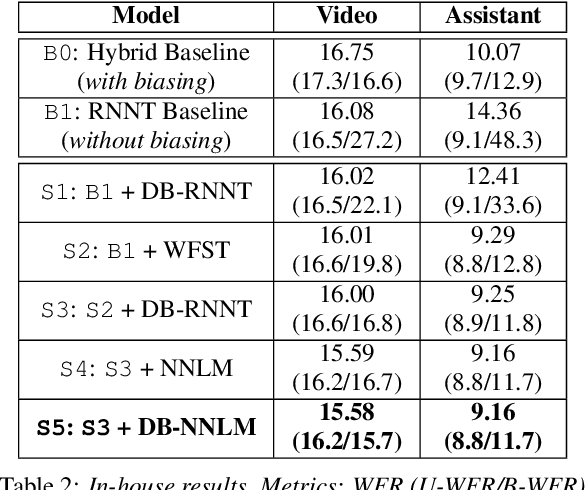
How to leverage dynamic contextual information in end-to-end speech recognition has remained an active research area. Previous solutions to this problem were either designed for specialized use cases that did not generalize well to open-domain scenarios, did not scale to large biasing lists, or underperformed on rare long-tail words. We address these limitations by proposing a novel solution that combines shallow fusion, trie-based deep biasing, and neural network language model contextualization. These techniques result in significant 19.5% relative Word Error Rate improvement over existing contextual biasing approaches and 5.4%-9.3% improvement compared to a strong hybrid baseline on both open-domain and constrained contextualization tasks, where the targets consist of mostly rare long-tail words. Our final system remains lightweight and modular, allowing for quick modification without model re-training.
A Multi-View Approach To Audio-Visual Speaker Verification
Feb 11, 2021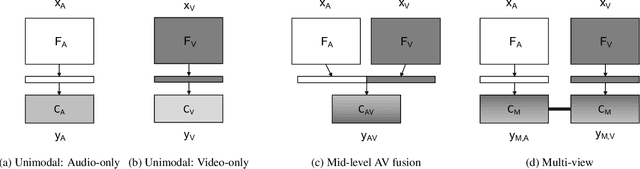
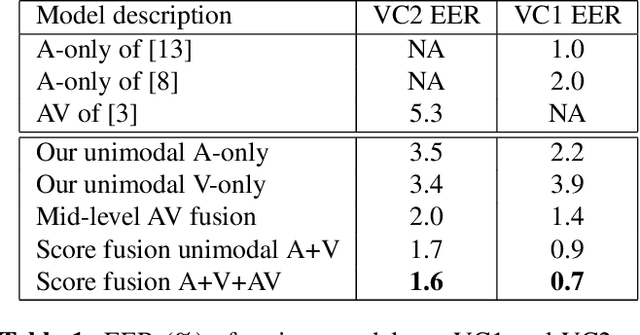

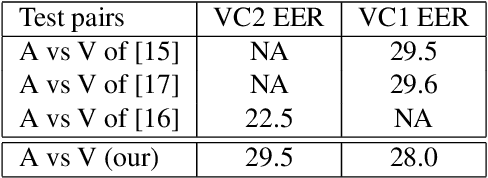
Although speaker verification has conventionally been an audio-only task, some practical applications provide both audio and visual streams of input. In these cases, the visual stream provides complementary information and can often be leveraged in conjunction with the acoustics of speech to improve verification performance. In this study, we explore audio-visual approaches to speaker verification, starting with standard fusion techniques to learn joint audio-visual (AV) embeddings, and then propose a novel approach to handle cross-modal verification at test time. Specifically, we investigate unimodal and concatenation based AV fusion and report the lowest AV equal error rate (EER) of 0.7% on the VoxCeleb1 dataset using our best system. As these methods lack the ability to do cross-modal verification, we introduce a multi-view model which uses a shared classifier to map audio and video into the same space. This new approach achieves 28% EER on VoxCeleb1 in the challenging testing condition of cross-modal verification.
Improving RNN Transducer Based ASR with Auxiliary Tasks
Nov 09, 2020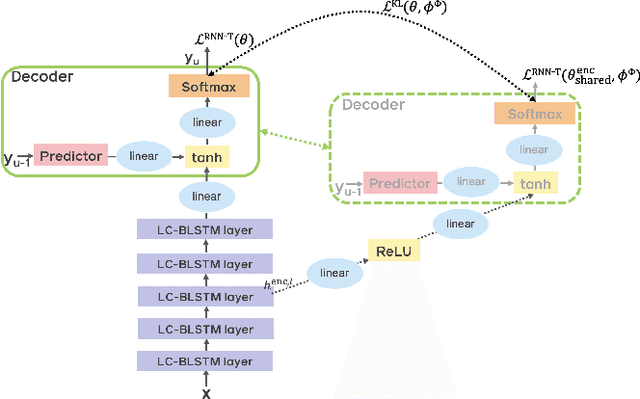

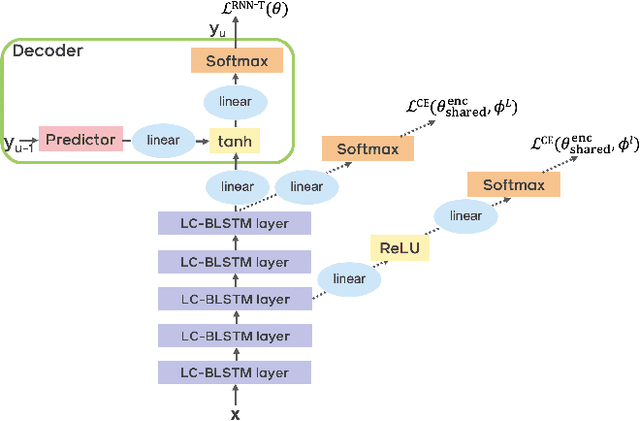
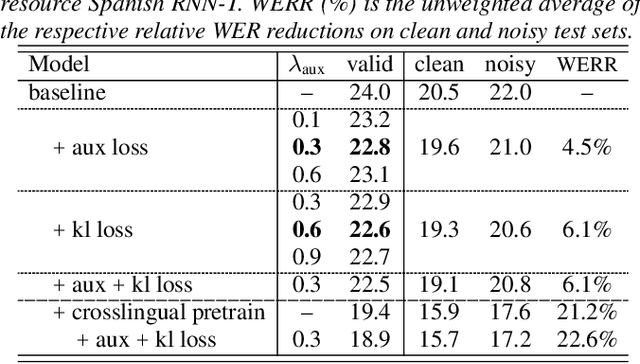
End-to-end automatic speech recognition (ASR) models with a single neural network have recently demonstrated state-of-the-art results compared to conventional hybrid speech recognizers. Specifically, recurrent neural network transducer (RNN-T) has shown competitive ASR performance on various benchmarks. In this work, we examine ways in which RNN-T can achieve better ASR accuracy via performing auxiliary tasks. We propose (i) using the same auxiliary task as primary RNN-T ASR task, and (ii) performing context-dependent graphemic state prediction as in conventional hybrid modeling. In transcribing social media videos with varying training data size, we first evaluate the streaming ASR performance on three languages: Romanian, Turkish and German. We find that both proposed methods provide consistent improvements. Next, we observe that both auxiliary tasks demonstrate efficacy in learning deep transformer encoders for RNN-T criterion, thus achieving competitive results - 2.0%/4.2% WER on LibriSpeech test-clean/other - as compared to prior top performing models.
Contextual RNN-T For Open Domain ASR
Jun 04, 2020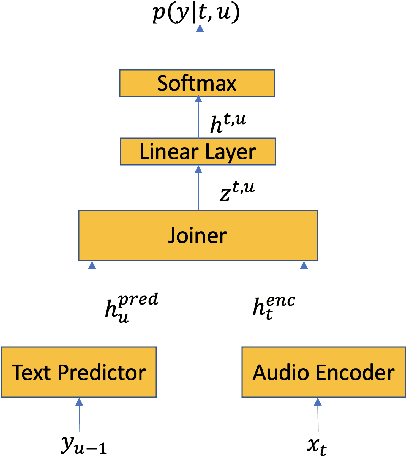
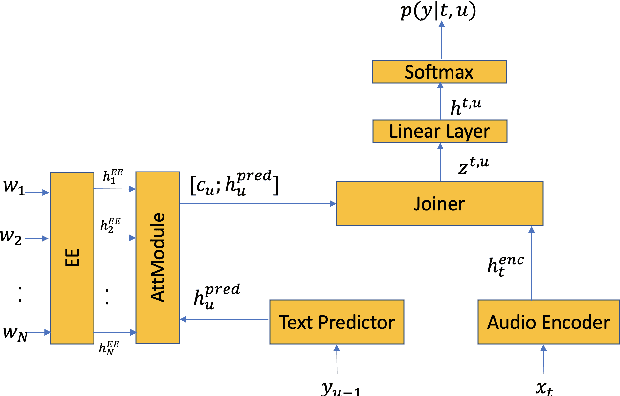
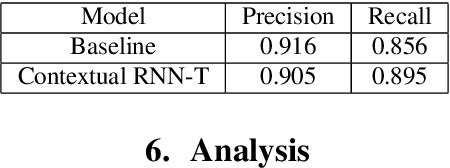

End-to-end (E2E) systems for automatic speech recognition (ASR), such as RNN Transducer (RNN-T) and Listen-Attend-Spell (LAS) blend the individual components of a traditional hybrid ASR system - acoustic model, language model, pronunciation model - into a single neural network. While this has some nice advantages, it limits the system to be trained using only paired audio and text. Because of this, E2E models tend to have difficulties with correctly recognizing rare words that are not frequently seen during training, such as entity names. In this paper, we propose modifications to the RNN-T model that allow the model to utilize additional metadata text with the objective of improving performance on these named entity words. We evaluate our approach on an in-house dataset sampled from de-identified public social media videos, which represent an open domain ASR task. By using an attention model to leverage the contextual metadata that accompanies a video, we observe a relative improvement of about 12% in Word Error Rate on Named Entities (WER-NE) for videos with related metadata.
Fast, Simpler and More Accurate Hybrid ASR Systems Using Wordpieces
May 19, 2020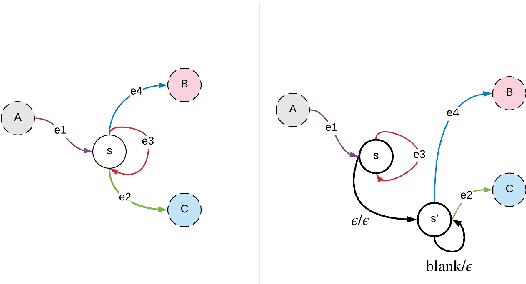

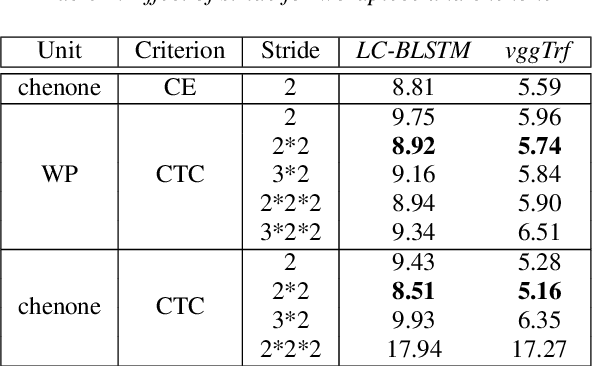
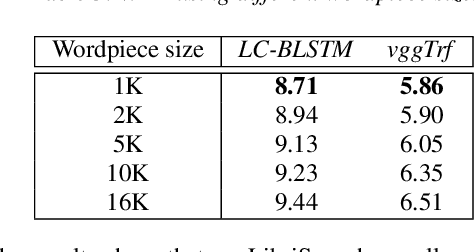
In this work, we first show that on the widely used LibriSpeech benchmark, our transformer-based context-dependent connectionist temporal classification (CTC) system produces state-of-the-art results. We then show that using wordpieces as modeling units combined with CTC training, we can greatly simplify the engineering pipeline compared to conventional frame-based cross-entropy training by excluding all the GMM bootstrapping, decision tree building and force alignment steps, while still achieving very competitive word-error-rate. Additionally, using wordpieces as modeling units can significantly improve runtime efficiency since we can use larger stride without losing accuracy. We further confirm these findings on two internal \emph{VideoASR} datasets: German, which is similar to English as a fusional language, and Turkish, which is an agglutinative language.
Large scale weakly and semi-supervised learning for low-resource video ASR
May 16, 2020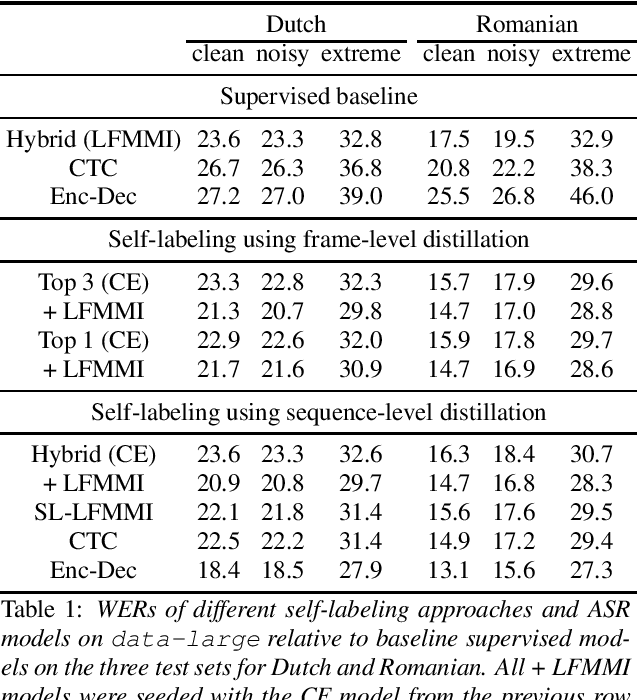
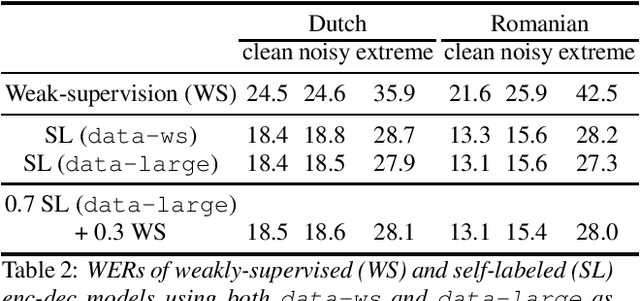
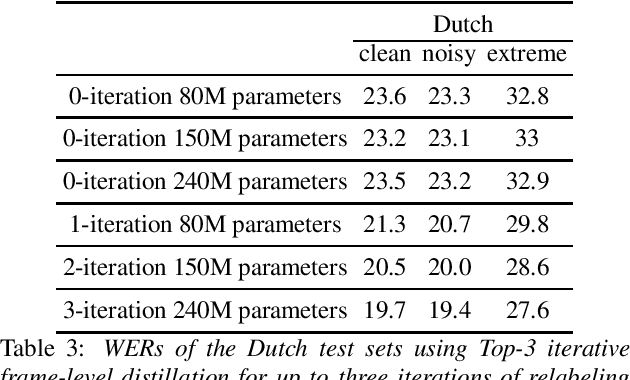
Many semi- and weakly-supervised approaches have been investigated for overcoming the labeling cost of building high quality speech recognition systems. On the challenging task of transcribing social media videos in low-resource conditions, we conduct a large scale systematic comparison between two self-labeling methods on one hand, and weakly-supervised pretraining using contextual metadata on the other. We investigate distillation methods at the frame level and the sequence level for hybrid, encoder-only CTC-based, and encoder-decoder speech recognition systems on Dutch and Romanian languages using 27,000 and 58,000 hours of unlabeled audio respectively. Although all approaches improved upon their respective baseline WERs by more than 8%, sequence-level distillation for encoder-decoder models provided the largest relative WER reduction of 20% compared to the strongest data-augmented supervised baseline.
Contextualizing ASR Lattice Rescoring with Hybrid Pointer Network Language Model
May 15, 2020
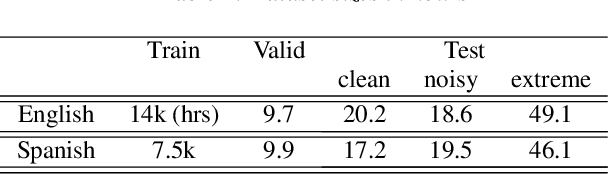
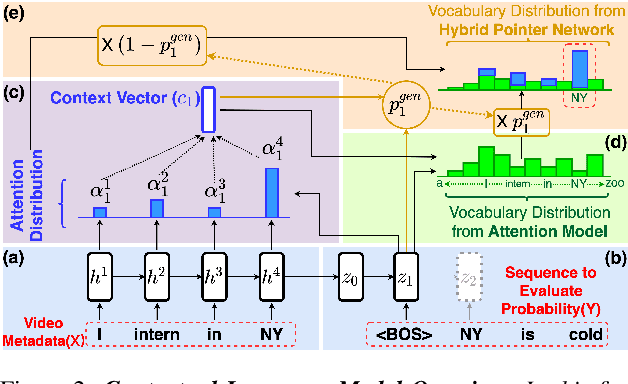
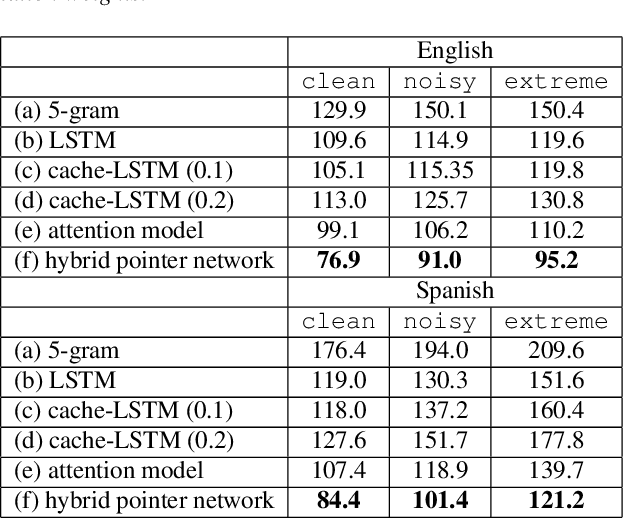
Videos uploaded on social media are often accompanied with textual descriptions. In building automatic speech recognition (ASR) systems for videos, we can exploit the contextual information provided by such video metadata. In this paper, we explore ASR lattice rescoring by selectively attending to the video descriptions. We first use an attention based method to extract contextual vector representations of video metadata, and use these representations as part of the inputs to a neural language model during lattice rescoring. Secondly, we propose a hybrid pointer network approach to explicitly interpolate the word probabilities of the word occurrences in metadata. We perform experimental evaluations on both language modeling and ASR tasks, and demonstrate that both proposed methods provide performance improvements by selectively leveraging the video metadata.
Training ASR models by Generation of Contextual Information
Oct 27, 2019
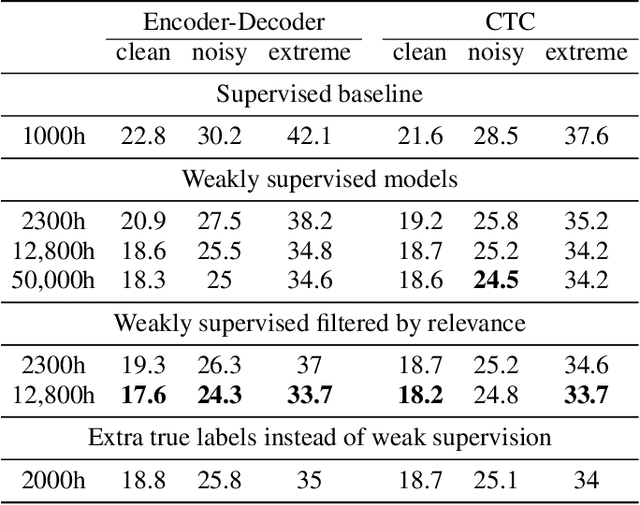
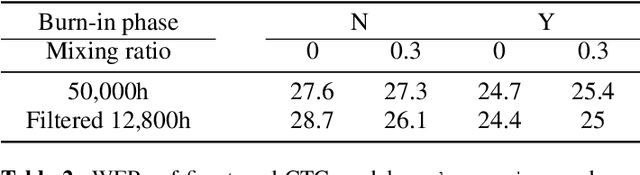

Supervised ASR models have reached unprecedented levels of accuracy, thanks in part to ever-increasing amounts of labelled training data. However, in many applications and locales, only moderate amounts of data are available, which has led to a surge in semi- and weakly-supervised learning research. In this paper, we conduct a large-scale study evaluating the effectiveness of weakly-supervised learning for speech recognition by using loosely related contextual information as a surrogate for ground-truth labels. For weakly supervised training, we use 50k hours of public English social media videos along with their respective titles and post text to train an encoder-decoder transformer model. Our best encoder-decoder models achieve an average of 20.8% WER reduction over a 1000 hours supervised baseline, and an average of 13.4% WER reduction when using only the weakly supervised encoder for CTC fine-tuning. Our results show that our setup for weak supervision improved both the encoder acoustic representations as well as the decoder language generation abilities.
Multilingual ASR with Massive Data Augmentation
Sep 14, 2019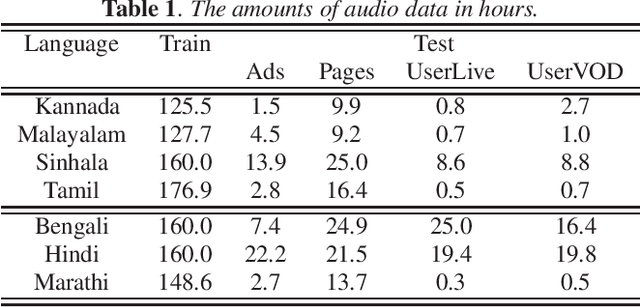
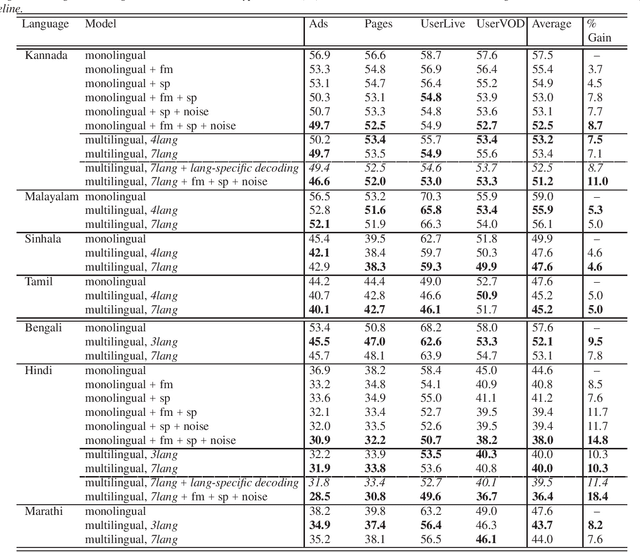
Towards developing high-performing ASR for low-resource languages, approaches to address the lack of resources are to make use of data from multiple languages, and to augment the training data by creating acoustic variations. In this work we present a single grapheme-based ASR model learned on 7 geographically proximal languages, using standard hybrid BLSTM-HMM acoustic models with lattice-free MMI objective. We build the single ASR grapheme set via taking the union over each language-specific grapheme set, and we find such multilingual ASR model can perform language-independent recognition on all 7 languages, and substantially outperform each monolingual ASR model. Secondly, we evaluate the efficacy of multiple data augmentation alternatives within language, as well as their complementarity with multilingual modeling. Overall, we show that the proposed multilingual ASR with various data augmentation can not only recognize any within training set languages, but also provide large ASR performance improvements.