 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Pretrained Text-to-Text Models for Long Text Sequences
Sep 21, 2022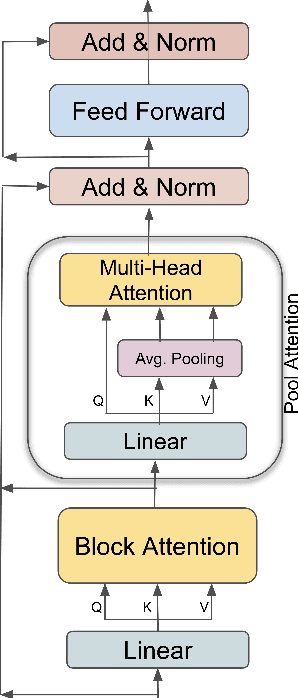
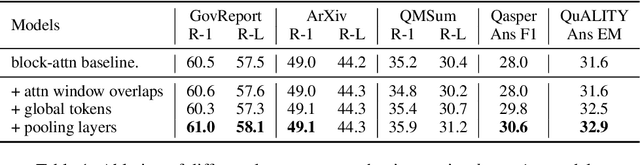
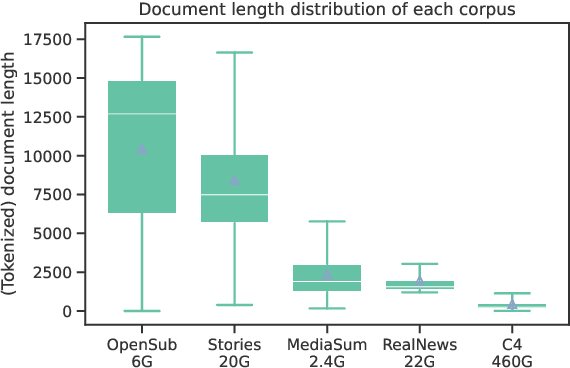
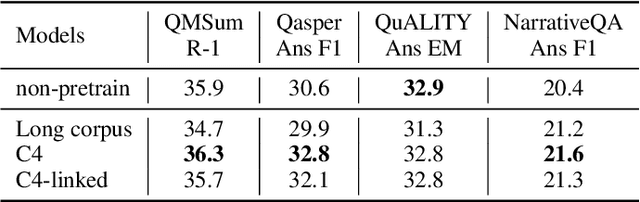
We present an empirical study of adapting an existing pretrained text-to-text model for long-sequence inputs. Through a comprehensive study along three axes of the pretraining pipeline -- model architecture, optimization objective, and pretraining corpus, we propose an effective recipe to build long-context models from existing short-context models. Specifically, we replace the full attention in transformers with pooling-augmented blockwise attention, and pretrain the model with a masked-span prediction task with spans of varying length. In terms of the pretraining corpus, we find that using randomly concatenated short-documents from a large open-domain corpus results in better performance than using existing long document corpora which are typically limited in their domain coverage. With these findings, we build a long-context model that achieves competitive performance on long-text QA tasks and establishes the new state of the art on five long-text summarization datasets, often outperforming previous methods with larger model sizes.
BiT: Robustly Binarized Multi-distilled Transformer
May 25, 2022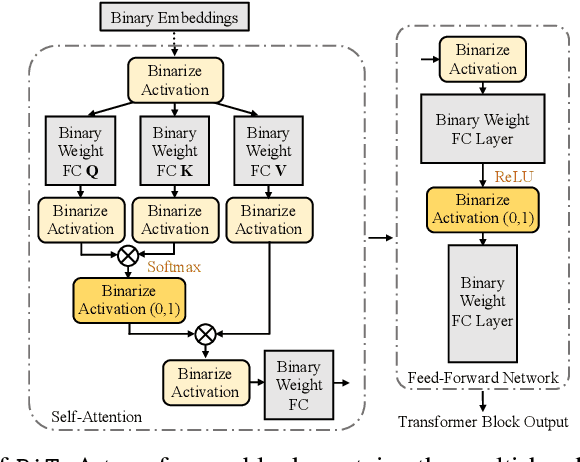
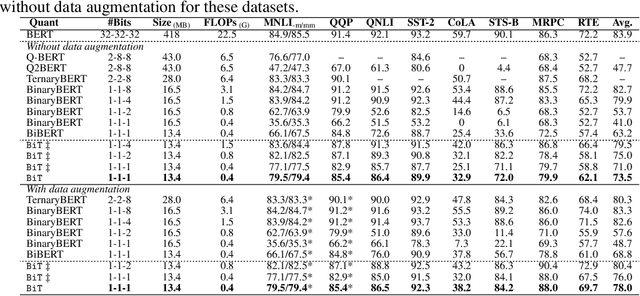

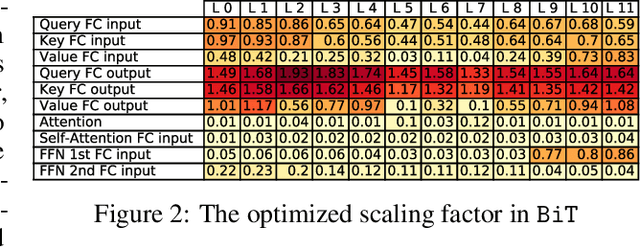
Modern pre-trained transformers have rapidly advanced the state-of-the-art in machine learning, but have also grown in parameters and computational complexity, making them increasingly difficult to deploy in resource-constrained environments. Binarization of the weights and activations of the network can significantly alleviate these issues, however is technically challenging from an optimization perspective. In this work, we identify a series of improvements which enables binary transformers at a much higher accuracy than what was possible previously. These include a two-set binarization scheme, a novel elastic binary activation function with learned parameters, and a method to quantize a network to its limit by successively distilling higher precision models into lower precision students. These approaches allow for the first time, fully binarized transformer models that are at a practical level of accuracy, approaching a full-precision BERT baseline on the GLUE language understanding benchmark within as little as 5.9%.
CONFIT: Toward Faithful Dialogue Summarization with Linguistically-Informed Contrastive Fine-tuning
Dec 16, 2021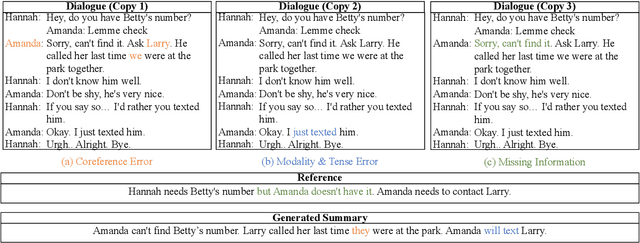
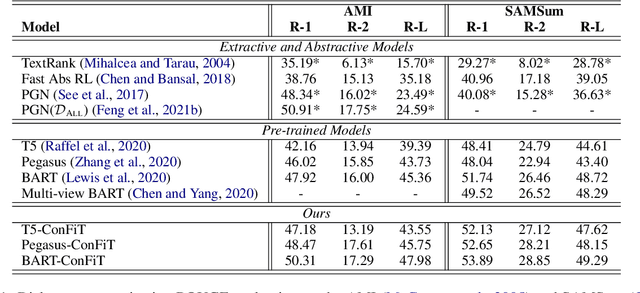
Factual inconsistencies in generated summaries severely limit the practical applications of abstractive dialogue summarization. Although significant progress has been achieved by using pre-trained models, substantial amounts of hallucinated content are found during the human evaluation. Pre-trained models are most commonly fine-tuned with cross-entropy loss for text summarization, which may not be an optimal strategy. In this work, we provide a typology of factual errors with annotation data to highlight the types of errors and move away from a binary understanding of factuality. We further propose a training strategy that improves the factual consistency and overall quality of summaries via a novel contrastive fine-tuning, called ConFiT. Based on our linguistically-informed typology of errors, we design different modular objectives that each target a specific type. Specifically, we utilize hard negative samples with errors to reduce the generation of factual inconsistency. In order to capture the key information between speakers, we also design a dialogue-specific loss. Using human evaluation and automatic faithfulness metrics, we show that our model significantly reduces all kinds of factual errors on the dialogue summarization, SAMSum corpus. Moreover, our model could be generalized to the meeting summarization, AMI corpus, and it produces significantly higher scores than most of the baselines on both datasets regarding word-overlap metrics.
Simple Local Attentions Remain Competitive for Long-Context Tasks
Dec 14, 2021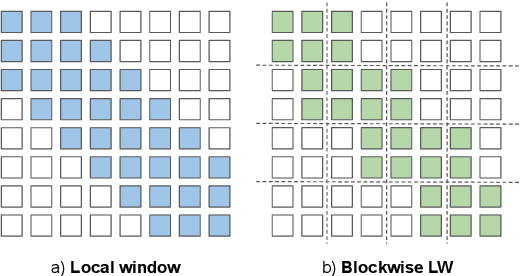
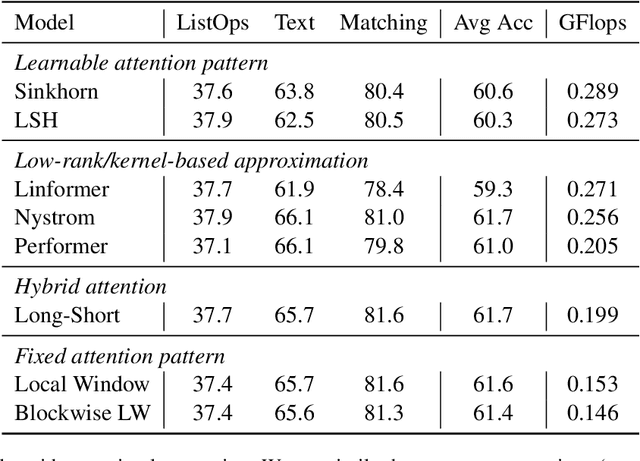
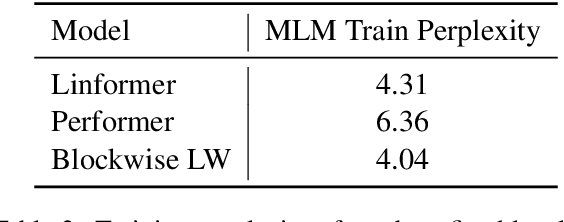
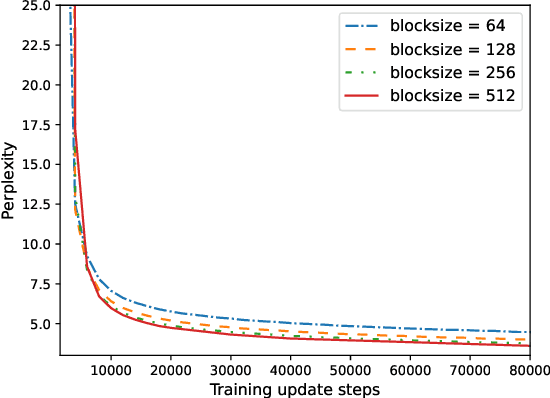
Many NLP tasks require processing long contexts beyond the length limit of pretrained models. In order to scale these models to longer text sequences, many efficient long-range attention variants have been proposed. Despite the abundance of research along this direction, it is still difficult to gauge the relative effectiveness of these models in practical use cases, e.g., if we apply these models following the pretrain-and-finetune paradigm. In this work, we aim to conduct a thorough analysis of these emerging models with large-scale and controlled experiments. For each attention variant, we pretrain large-size models using the same long-doc corpus and then finetune these models for real-world long-context tasks. Our findings reveal pitfalls of an existing widely-used long-range benchmark and show none of the tested efficient attentions can beat a simple local window attention under standard pretraining paradigms. Further analysis on local attention variants suggests that even the commonly used attention-window overlap is not necessary to achieve good downstream results -- using disjoint local attentions, we are able to build a simpler and more efficient long-doc QA model that matches the performance of Longformer~\citep{longformer} with half of its pretraining compute.
Salient Phrase Aware Dense Retrieval: Can a Dense Retriever Imitate a Sparse One?
Oct 13, 2021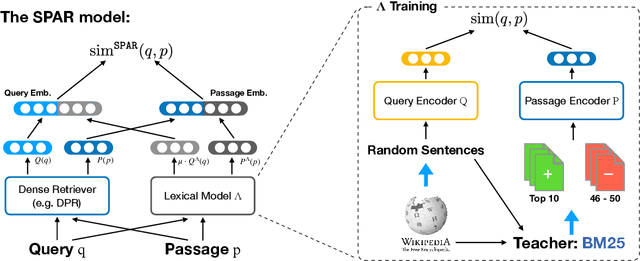
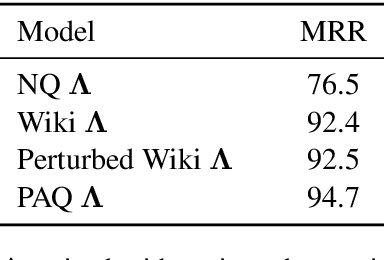
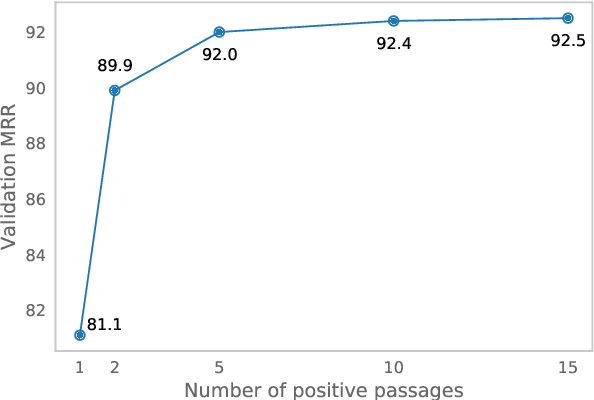
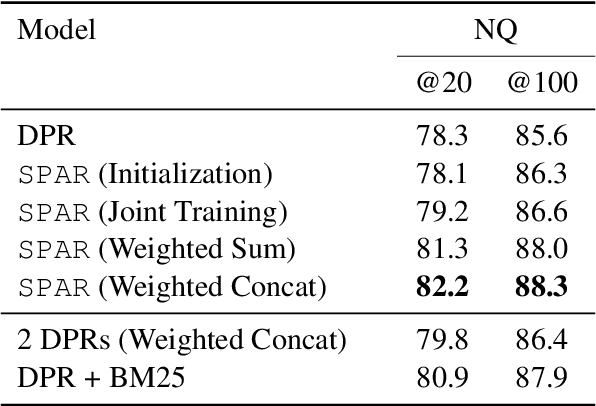
Despite their recent popularity and well known advantages, dense retrievers still lag behind sparse methods such as BM25 in their ability to reliably match salient phrases and rare entities in the query. It has been argued that this is an inherent limitation of dense models. We disprove this claim by introducing the Salient Phrase Aware Retriever (SPAR), a dense retriever with the lexical matching capacity of a sparse model. In particular, we show that a dense retriever {\Lambda} can be trained to imitate a sparse one, and SPAR is built by augmenting a standard dense retriever with {\Lambda}. When evaluated on five open-domain question answering datasets and the MS MARCO passage retrieval task, SPAR sets a new state of the art for dense and sparse retrievers and can match or exceed the performance of more complicated dense-sparse hybrid systems.
Investigating Crowdsourcing Protocols for Evaluating the Factual Consistency of Summaries
Sep 21, 2021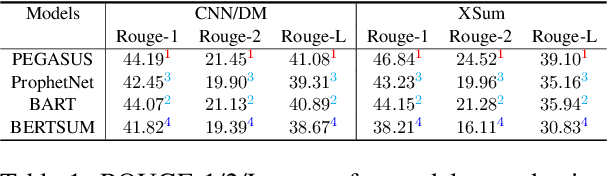
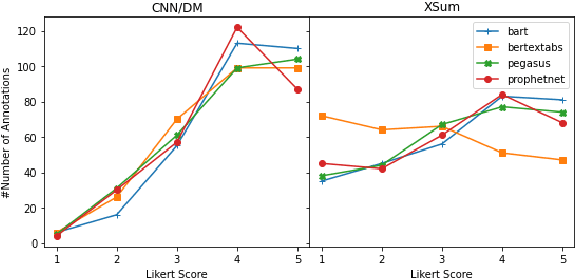
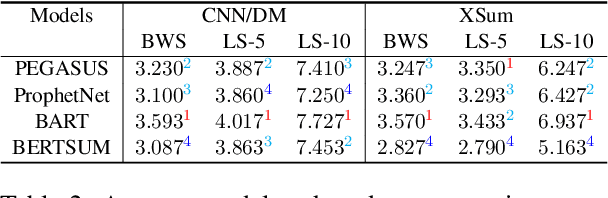
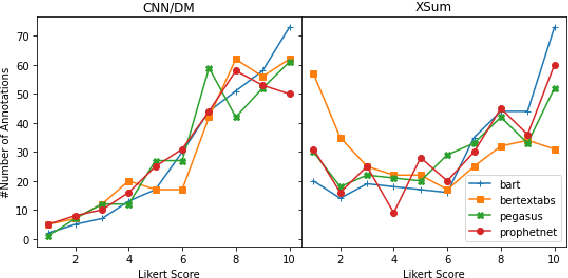
Current pre-trained models applied to summarization are prone to factual inconsistencies which either misrepresent the source text or introduce extraneous information. Thus, comparing the factual consistency of summaries is necessary as we develop improved models. However, the optimal human evaluation setup for factual consistency has not been standardized. To address this issue, we crowdsourced evaluations for factual consistency using the rating-based Likert scale and ranking-based Best-Worst Scaling protocols, on 100 articles from each of the CNN-Daily Mail and XSum datasets over four state-of-the-art models, to determine the most reliable evaluation framework. We find that ranking-based protocols offer a more reliable measure of summary quality across datasets, while the reliability of Likert ratings depends on the target dataset and the evaluation design. Our crowdsourcing templates and summary evaluations will be publicly available to facilitate future research on factual consistency in summarization.
Domain-matched Pre-training Tasks for Dense Retrieval
Jul 28, 2021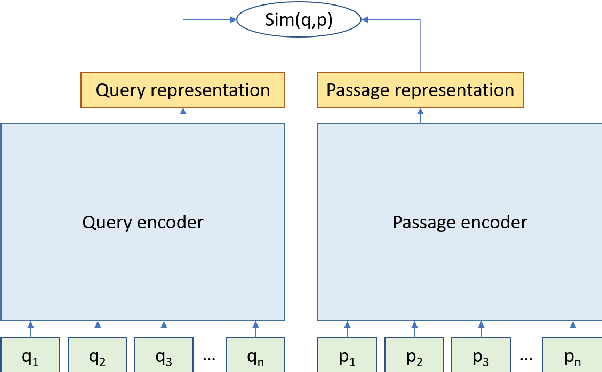
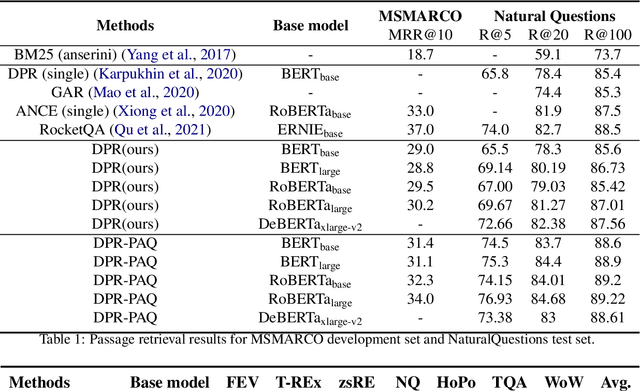
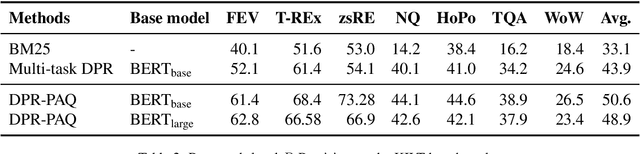
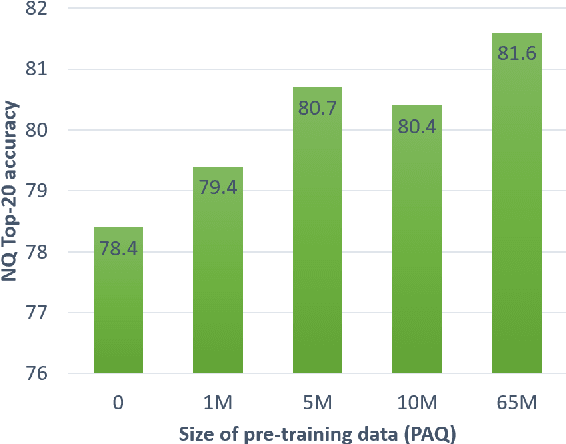
Pre-training on larger datasets with ever increasing model size is now a proven recipe for increased performance across almost all NLP tasks. A notable exception is information retrieval, where additional pre-training has so far failed to produce convincing results. We show that, with the right pre-training setup, this barrier can be overcome. We demonstrate this by pre-training large bi-encoder models on 1) a recently released set of 65 million synthetically generated questions, and 2) 200 million post-comment pairs from a preexisting dataset of Reddit conversations made available by pushshift.io. We evaluate on a set of information retrieval and dialogue retrieval benchmarks, showing substantial improvements over supervised baselines.
Syntax-augmented Multilingual BERT for Cross-lingual Transfer
Jun 03, 2021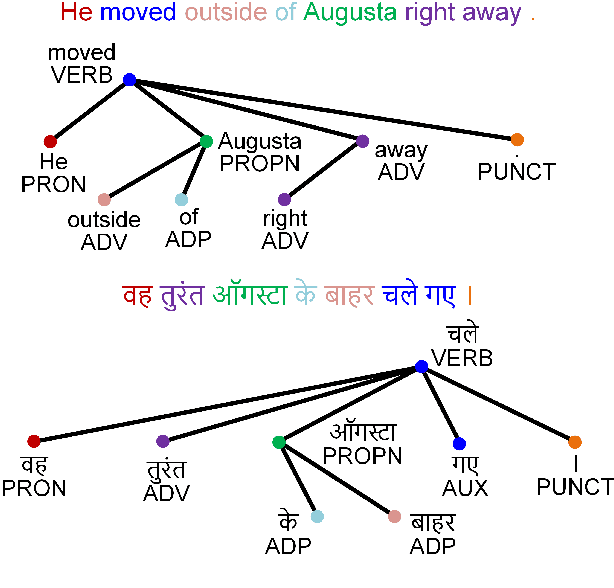

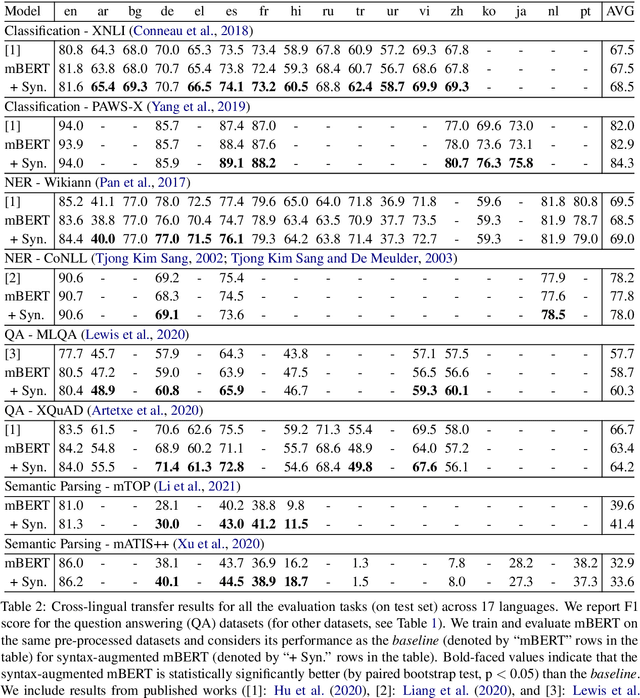
In recent years, we have seen a colossal effort in pre-training multilingual text encoders using large-scale corpora in many languages to facilitate cross-lingual transfer learning. However, due to typological differences across languages, the cross-lingual transfer is challenging. Nevertheless, language syntax, e.g., syntactic dependencies, can bridge the typological gap. Previous works have shown that pre-trained multilingual encoders, such as mBERT \cite{devlin-etal-2019-bert}, capture language syntax, helping cross-lingual transfer. This work shows that explicitly providing language syntax and training mBERT using an auxiliary objective to encode the universal dependency tree structure helps cross-lingual transfer. We perform rigorous experiments on four NLP tasks, including text classification, question answering, named entity recognition, and task-oriented semantic parsing. The experiment results show that syntax-augmented mBERT improves cross-lingual transfer on popular benchmarks, such as PAWS-X and MLQA, by 1.4 and 1.6 points on average across all languages. In the \emph{generalized} transfer setting, the performance boosted significantly, with 3.9 and 3.1 points on average in PAWS-X and MLQA.
ConvoSumm: Conversation Summarization Benchmark and Improved Abstractive Summarization with Argument Mining
Jun 01, 2021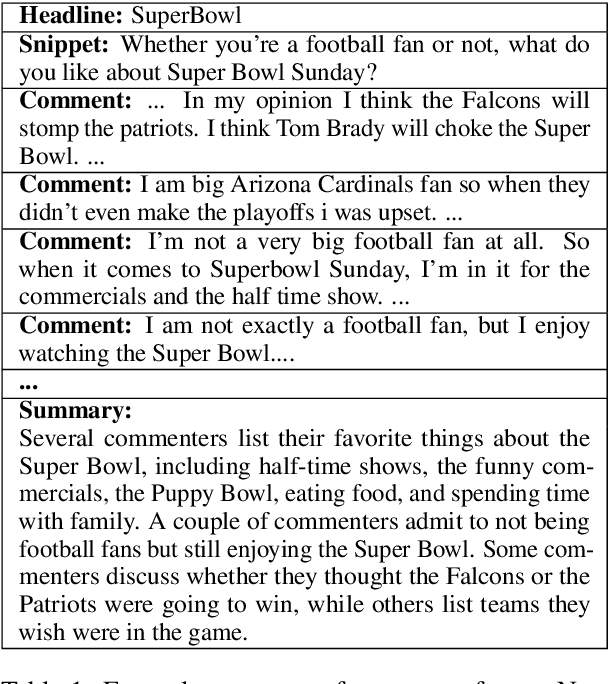
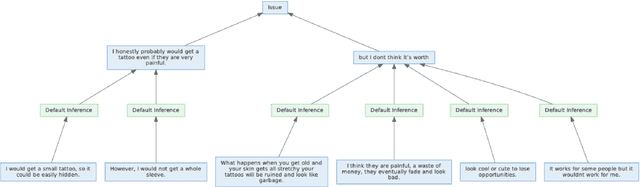


While online conversations can cover a vast amount of information in many different formats, abstractive text summarization has primarily focused on modeling solely news articles. This research gap is due, in part, to the lack of standardized datasets for summarizing online discussions. To address this gap, we design annotation protocols motivated by an issues--viewpoints--assertions framework to crowdsource four new datasets on diverse online conversation forms of news comments, discussion forums, community question answering forums, and email threads. We benchmark state-of-the-art models on our datasets and analyze characteristics associated with the data. To create a comprehensive benchmark, we also evaluate these models on widely-used conversation summarization datasets to establish strong baselines in this domain. Furthermore, we incorporate argument mining through graph construction to directly model the issues, viewpoints, and assertions present in a conversation and filter noisy input, showing comparable or improved results according to automatic and human evaluations.
EASE: Extractive-Abstractive Summarization with Explanations
May 14, 2021
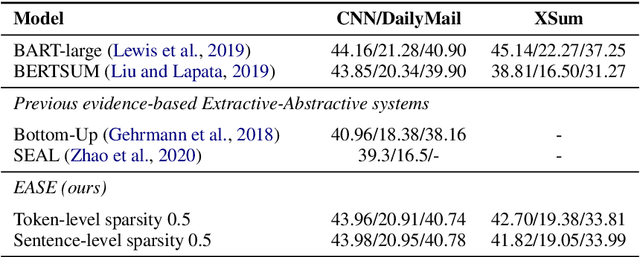
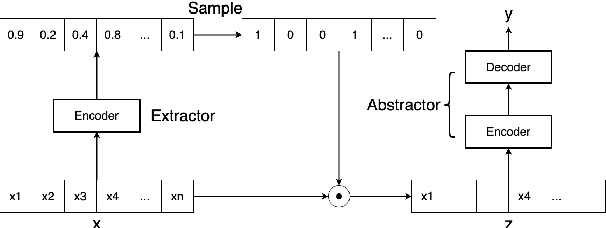
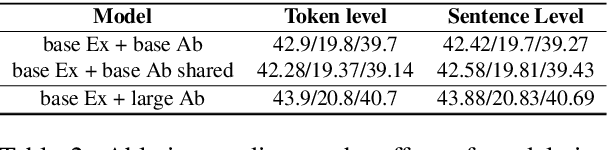
Current abstractive summarization systems outperform their extractive counterparts, but their widespread adoption is inhibited by the inherent lack of interpretability. To achieve the best of both worlds, we propose EASE, an extractive-abstractive framework for evidence-based text generation and apply it to document summarization. We present an explainable summarization system based on the Information Bottleneck principle that is jointly trained for extraction and abstraction in an end-to-end fashion. Inspired by previous research that humans use a two-stage framework to summarize long documents (Jing and McKeown, 2000), our framework first extracts a pre-defined amount of evidence spans as explanations and then generates a summary using only the evidence. Using automatic and human evaluations, we show that explanations from our framework are more relevant than simple baselines, without substantially sacrificing the quality of the generated summary.