 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Clinical Encounter Summarization: Learning to Compose Discharge Summaries from Prior Notes
Apr 27, 2021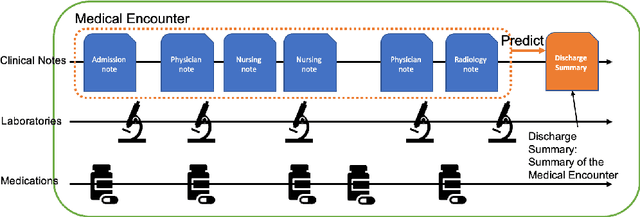

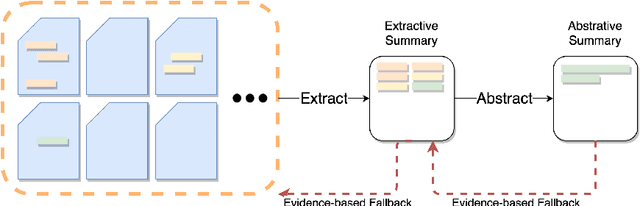
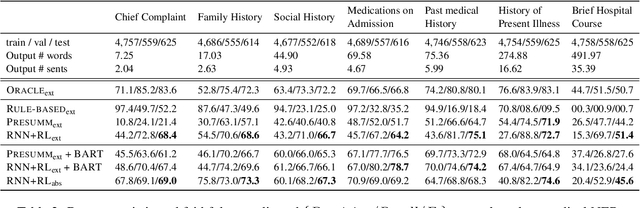
The records of a clinical encounter can be extensive and complex, thus placing a premium on tools that can extract and summarize relevant information. This paper introduces the task of generating discharge summaries for a clinical encounter. Summaries in this setting need to be faithful, traceable, and scale to multiple long documents, motivating the use of extract-then-abstract summarization cascades. We introduce two new measures, faithfulness and hallucination rate for evaluation in this task, which complement existing measures for fluency and informativeness. Results across seven medical sections and five models show that a summarization architecture that supports traceability yields promising results, and that a sentence-rewriting approach performs consistently on the measure used for faithfulness (faithfulness-adjusted $F_3$) over a diverse range of generated sections.
Severing the Edge Between Before and After: Neural Architectures for Temporal Ordering of Events
Apr 08, 2020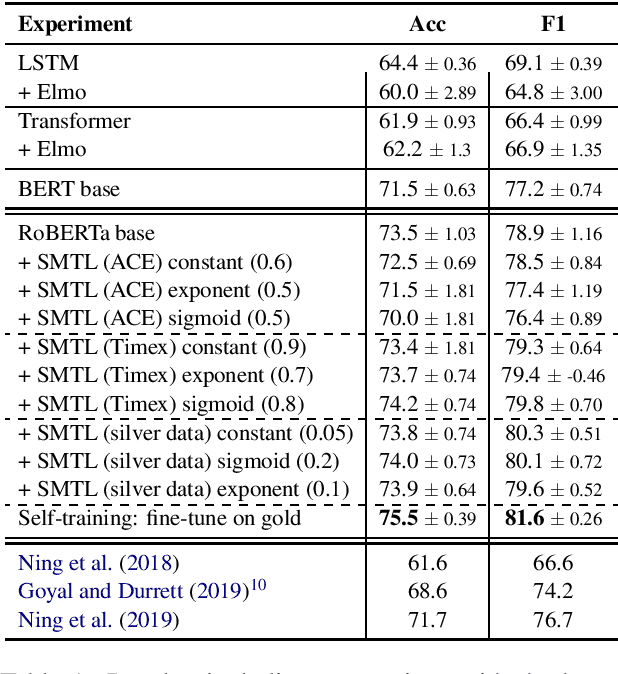
In this paper, we propose a neural architecture and a set of training methods for ordering events by predicting temporal relations. Our proposed models receive a pair of events within a span of text as input and they identify temporal relations (Before, After, Equal, Vague) between them. Given that a key challenge with this task is the scarcity of annotated data, our models rely on either pretrained representations (i.e. RoBERTa, BERT or ELMo), transfer and multi-task learning (by leveraging complementary datasets), and self-training techniques. Experiments on the MATRES dataset of English documents establish a new state-of-the-art on this task.
Translating Translationese: A Two-Step Approach to Unsupervised Machine Translation
Jun 11, 2019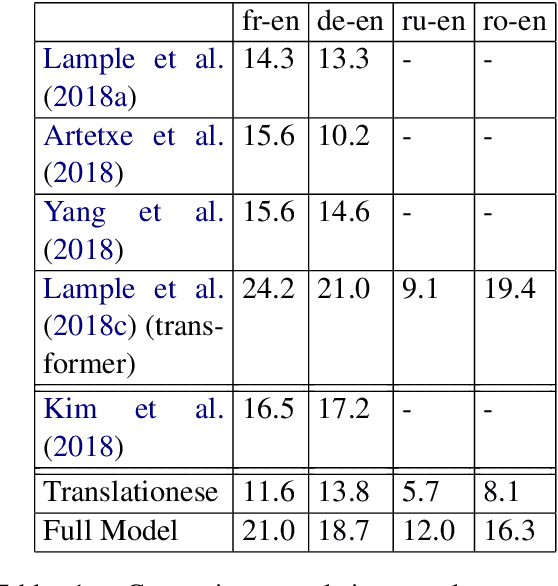
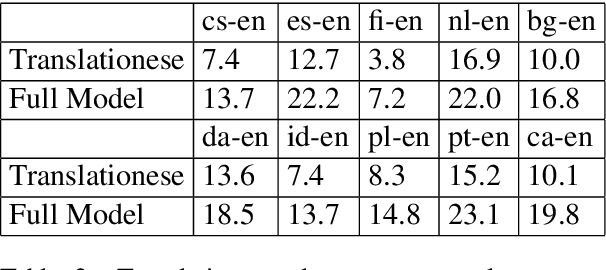
Given a rough, word-by-word gloss of a source language sentence, target language natives can uncover the latent, fully-fluent rendering of the translation. In this work we explore this intuition by breaking translation into a two step process: generating a rough gloss by means of a dictionary and then `translating' the resulting pseudo-translation, or `Translationese' into a fully fluent translation. We build our Translationese decoder once from a mish-mash of parallel data that has the target language in common and then can build dictionaries on demand using unsupervised techniques, resulting in rapidly generated unsupervised neural MT systems for many source languages. We apply this process to 14 test languages, obtaining better or comparable translation results on high-resource languages than previously published unsupervised MT studies, and obtaining good quality results for low-resource languages that have never been used in an unsupervised MT scenario.