 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Pathologies in KL-Regularized Reinforcement Learning from Expert Demonstrations
Dec 28, 2022KL-regularized reinforcement learning from expert demonstrations has proved successful in improving the sample efficiency of deep reinforcement learning algorithms, allowing them to be applied to challenging physical real-world tasks. However, we show that KL-regularized reinforcement learning with behavioral reference policies derived from expert demonstrations can suffer from pathological training dynamics that can lead to slow, unstable, and suboptimal online learning. We show empirically that the pathology occurs for commonly chosen behavioral policy classes and demonstrate its impact on sample efficiency and online policy performance. Finally, we show that the pathology can be remedied by non-parametric behavioral reference policies and that this allows KL-regularized reinforcement learning to significantly outperform state-of-the-art approaches on a variety of challenging locomotion and dexterous hand manipulation tasks.
CLAM: Selective Clarification for Ambiguous Questions with Large Language Models
Dec 15, 2022



State-of-the-art language models are often accurate on many question-answering benchmarks with well-defined questions. Yet, in real settings questions are often unanswerable without asking the user for clarifying information. We show that current SotA models often do not ask the user for clarification when presented with imprecise questions and instead provide incorrect answers or "hallucinate". To address this, we introduce CLAM, a framework that first uses the model to detect ambiguous questions, and if an ambiguous question is detected, prompts the model to ask the user for clarification. Furthermore, we show how to construct a scalable and cost-effective automatic evaluation protocol using an oracle language model with privileged information to provide clarifying information. We show that our method achieves a 20.15 percentage point accuracy improvement over SotA on a novel ambiguous question-answering answering data set derived from TriviaQA.
Benchmarking Bayesian Deep Learning on Diabetic Retinopathy Detection Tasks
Nov 23, 2022Bayesian deep learning seeks to equip deep neural networks with the ability to precisely quantify their predictive uncertainty, and has promised to make deep learning more reliable for safety-critical real-world applications. Yet, existing Bayesian deep learning methods fall short of this promise; new methods continue to be evaluated on unrealistic test beds that do not reflect the complexities of downstream real-world tasks that would benefit most from reliable uncertainty quantification. We propose the RETINA Benchmark, a set of real-world tasks that accurately reflect such complexities and are designed to assess the reliability of predictive models in safety-critical scenarios. Specifically, we curate two publicly available datasets of high-resolution human retina images exhibiting varying degrees of diabetic retinopathy, a medical condition that can lead to blindness, and use them to design a suite of automated diagnosis tasks that require reliable predictive uncertainty quantification. We use these tasks to benchmark well-established and state-of-the-art Bayesian deep learning methods on task-specific evaluation metrics. We provide an easy-to-use codebase for fast and easy benchmarking following reproducibility and software design principles. We provide implementations of all methods included in the benchmark as well as results computed over 100 TPU days, 20 GPU days, 400 hyperparameter configurations, and evaluation on at least 6 random seeds each.
Discovering Long-period Exoplanets using Deep Learning with Citizen Science Labels
Nov 13, 2022Automated planetary transit detection has become vital to prioritize candidates for expert analysis given the scale of modern telescopic surveys. While current methods for short-period exoplanet detection work effectively due to periodicity in the light curves, there lacks a robust approach for detecting single-transit events. However, volunteer-labelled transits recently collected by the Planet Hunters TESS (PHT) project now provide an unprecedented opportunity to investigate a data-driven approach to long-period exoplanet detection. In this work, we train a 1-D convolutional neural network to classify planetary transits using PHT volunteer scores as training data. We find using volunteer scores significantly improves performance over synthetic data, and enables the recovery of known planets at a precision and rate matching that of the volunteers. Importantly, the model also recovers transits found by volunteers but missed by current automated methods.
Exploring Low Rank Training of Deep Neural Networks
Sep 27, 2022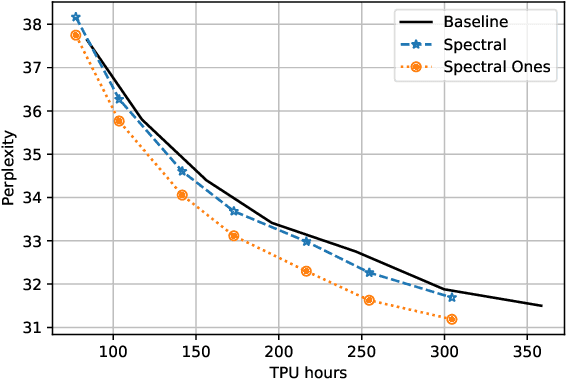

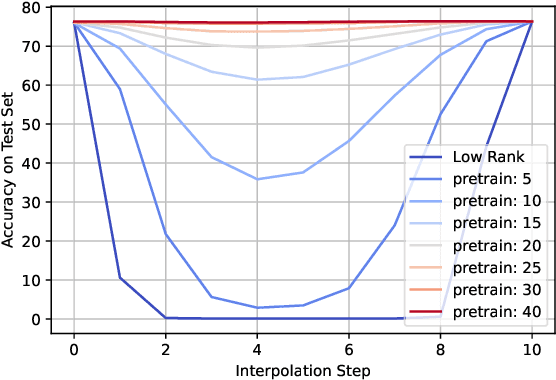
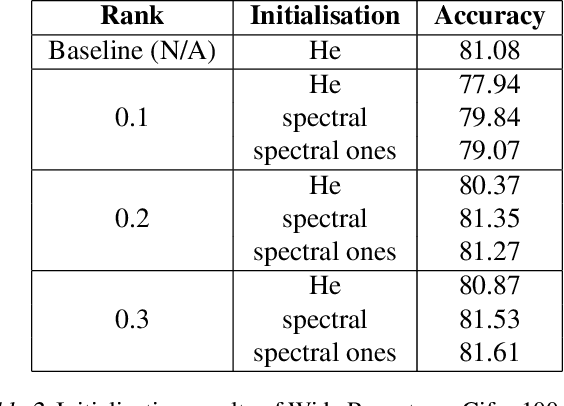
Training deep neural networks in low rank, i.e. with factorised layers, is of particular interest to the community: it offers efficiency over unfactorised training in terms of both memory consumption and training time. Prior work has focused on low rank approximations of pre-trained networks and training in low rank space with additional objectives, offering various ad hoc explanations for chosen practice. We analyse techniques that work well in practice, and through extensive ablations on models such as GPT2 we provide evidence falsifying common beliefs in the field, hinting in the process at exciting research opportunities that still need answering.
Exploring the Limits of Synthetic Creation of Solar EUV Images via Image-to-Image Translation
Aug 19, 2022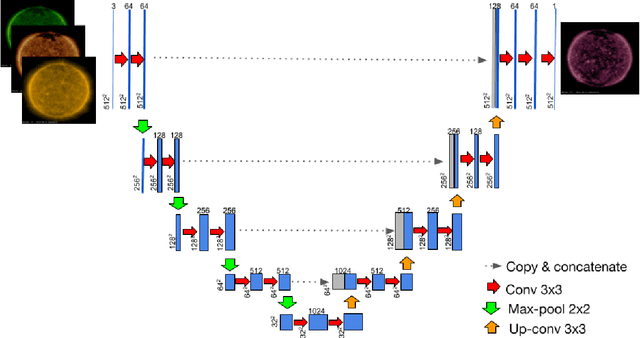
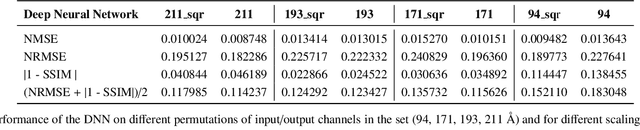
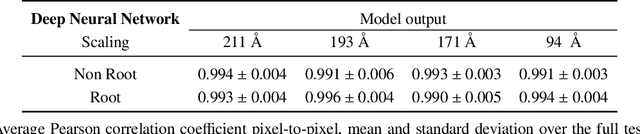
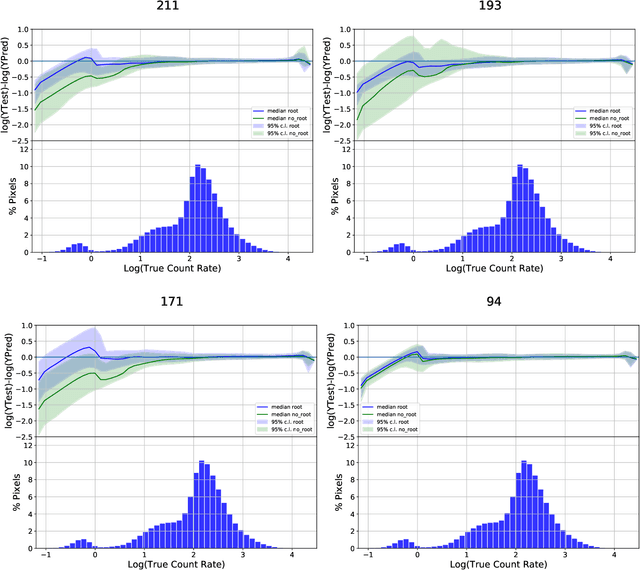
The Solar Dynamics Observatory (SDO), a NASA multi-spectral decade-long mission that has been daily producing terabytes of observational data from the Sun, has been recently used as a use-case to demonstrate the potential of machine learning methodologies and to pave the way for future deep-space mission planning. In particular, the idea of using image-to-image translation to virtually produce extreme ultra-violet channels has been proposed in several recent studies, as a way to both enhance missions with less available channels and to alleviate the challenges due to the low downlink rate in deep space. This paper investigates the potential and the limitations of such a deep learning approach by focusing on the permutation of four channels and an encoder--decoder based architecture, with particular attention to how morphological traits and brightness of the solar surface affect the neural network predictions. In this work we want to answer the question: can synthetic images of the solar corona produced via image-to-image translation be used for scientific studies of the Sun? The analysis highlights that the neural network produces high-quality images over three orders of magnitude in count rate (pixel intensity) and can generally reproduce the covariance across channels within a 1% error. However the model performance drastically diminishes in correspondence of extremely high energetic events like flares, and we argue that the reason is related to the rareness of such events posing a challenge to model training.
Unifying Approaches in Data Subset Selection via Fisher Information and Information-Theoretic Quantities
Aug 01, 2022The mutual information between predictions and model parameters -- also referred to as expected information gain or BALD in machine learning -- measures informativeness. It is a popular acquisition function in Bayesian active learning and Bayesian optimal experiment design. In data subset selection, i.e. active learning and active sampling, several recent works use Fisher information, Hessians, similarity matrices based on the gradients, or simply the gradient lengths to compute the acquisition scores that guide sample selection. Are these different approaches connected, and if so how? In this paper, we revisit the Fisher information and use it to show how several otherwise disparate methods are connected as approximations of information-theoretic quantities.
Plex: Towards Reliability using Pretrained Large Model Extensions
Jul 15, 2022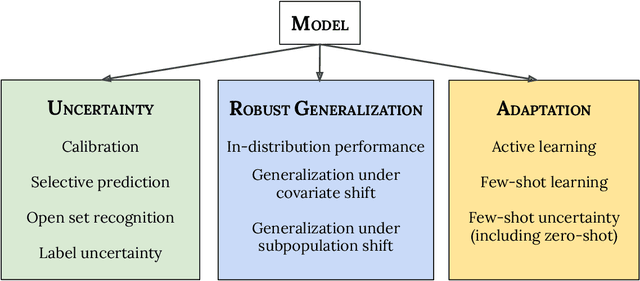

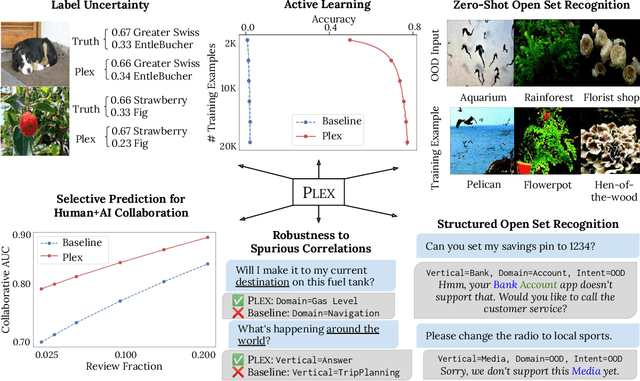

A recent trend in artificial intelligence is the use of pretrained models for language and vision tasks, which have achieved extraordinary performance but also puzzling failures. Probing these models' abilities in diverse ways is therefore critical to the field. In this paper, we explore the reliability of models, where we define a reliable model as one that not only achieves strong predictive performance but also performs well consistently over many decision-making tasks involving uncertainty (e.g., selective prediction, open set recognition), robust generalization (e.g., accuracy and proper scoring rules such as log-likelihood on in- and out-of-distribution datasets), and adaptation (e.g., active learning, few-shot uncertainty). We devise 10 types of tasks over 40 datasets in order to evaluate different aspects of reliability on both vision and language domains. To improve reliability, we developed ViT-Plex and T5-Plex, pretrained large model extensions for vision and language modalities, respectively. Plex greatly improves the state-of-the-art across reliability tasks, and simplifies the traditional protocol as it improves the out-of-the-box performance and does not require designing scores or tuning the model for each task. We demonstrate scaling effects over model sizes up to 1B parameters and pretraining dataset sizes up to 4B examples. We also demonstrate Plex's capabilities on challenging tasks including zero-shot open set recognition, active learning, and uncertainty in conversational language understanding.
Prioritized Training on Points that are Learnable, Worth Learning, and Not Yet Learnt
Jun 16, 2022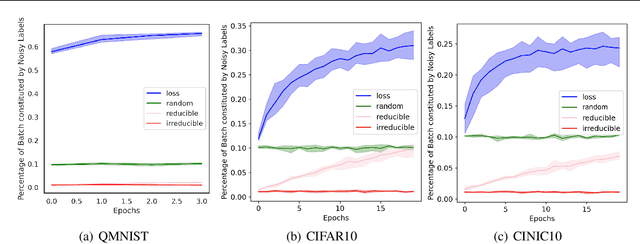
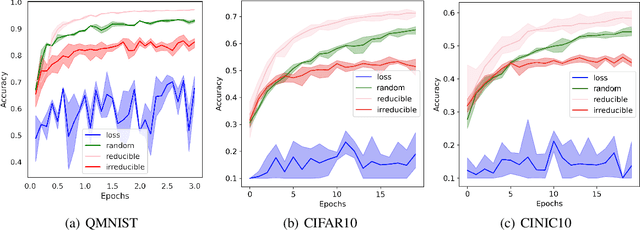
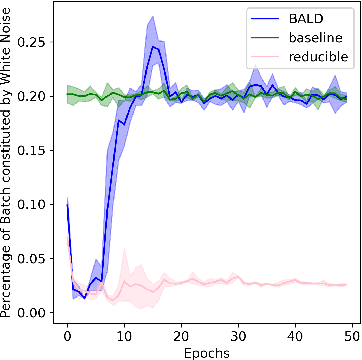
Training on web-scale data can take months. But most computation and time is wasted on redundant and noisy points that are already learnt or not learnable. To accelerate training, we introduce Reducible Holdout Loss Selection (RHO-LOSS), a simple but principled technique which selects approximately those points for training that most reduce the model's generalization loss. As a result, RHO-LOSS mitigates the weaknesses of existing data selection methods: techniques from the optimization literature typically select 'hard' (e.g. high loss) points, but such points are often noisy (not learnable) or less task-relevant. Conversely, curriculum learning prioritizes 'easy' points, but such points need not be trained on once learned. In contrast, RHO-LOSS selects points that are learnable, worth learning, and not yet learnt. RHO-LOSS trains in far fewer steps than prior art, improves accuracy, and speeds up training on a wide range of datasets, hyperparameters, and architectures (MLPs, CNNs, and BERT). On the large web-scraped image dataset Clothing-1M, RHO-LOSS trains in 18x fewer steps and reaches 2% higher final accuracy than uniform data shuffling.
Learning Dynamics and Generalization in Reinforcement Learning
Jun 05, 2022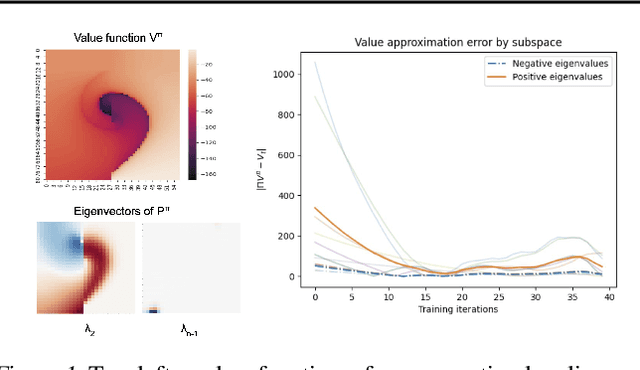
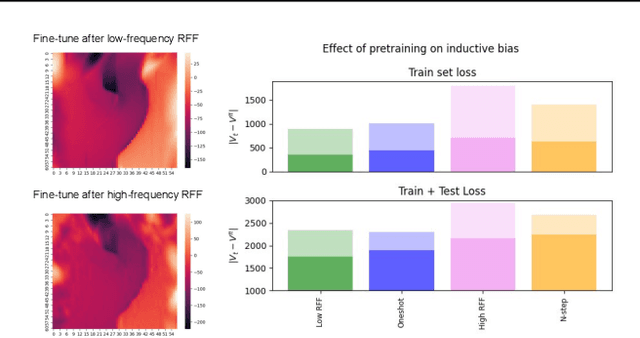
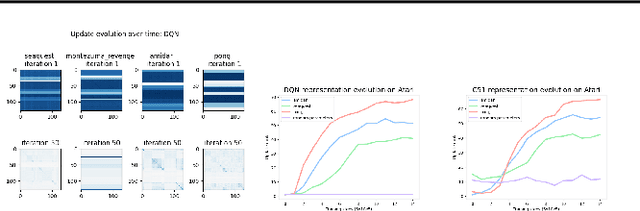
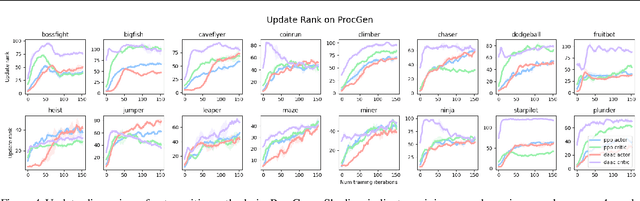
Solving a reinforcement learning (RL) problem poses two competing challenges: fitting a potentially discontinuous value function, and generalizing well to new observations. In this paper, we analyze the learning dynamics of temporal difference algorithms to gain novel insight into the tension between these two objectives. We show theoretically that temporal difference learning encourages agents to fit non-smooth components of the value function early in training, and at the same time induces the second-order effect of discouraging generalization. We corroborate these findings in deep RL agents trained on a range of environments, finding that neural networks trained using temporal difference algorithms on dense reward tasks exhibit weaker generalization between states than randomly initialized networks and networks trained with policy gradient methods. Finally, we investigate how post-training policy distillation may avoid this pitfall, and show that this approach improves generalization to novel environments in the ProcGen suite and improves robustness to input perturbations.