 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoPool: Evolutionary Programmatic Annotation for Label-Efficient Specialized Supervision
Jun 01, 2026Large language models excel at general tasks but underperform smaller supervised models in specialized, high-stakes domains where training labels are costly. We address this regime with EvoPool, an evolutionary multi-agent framework inspired by Darwinian evolution. Three specialized agents iteratively propose executable annotator code, a small validation set provides a fitness signal, and a deterministic gate keeps only annotators that pass viability, diversity, and marginal-contribution checks across generations. Pool votes are mapped to soft training labels by EvoAgg, a text-aware aggregator combining semantic features with annotator-vote features. The authored pool runs at near-zero per-example cost and is 4500 to 31000x faster than LLM annotation on 100K examples. Across 7 of 8 LLM-weak specialized and complex tasks spanning biomedical relation extraction, legal-clause classification, complex reasoning, and dense multi-label biomedical classification, EvoPool beats the strongest LLM annotation baseline by an average +0.141 macro-F1, peaking at +0.301 on ChemProt and +0.265 on PubMed. Code is available at: https://github.com/tianyi0216/EvoPool
When Does Multi-Agent RL Improve LLM Workflows? Workflow, Scale, and Policy-Sharing Tradeoffs
May 22, 2026Multi-agent LLM workflows route inference through specialized roles to lift end-task accuracy, but jointly training those roles with reinforcement learning is unstable in ways that are poorly understood. We study when end-to-end RL training of multi-agent LLM workflows improves over their base models, comparing Shared-Policy training, where all roles update one policy, with Isolated-Policy training, where each role has its own parameters. Our experimental matrix spans Eval-Opt, Voting, and Orch-Workers workflows, math and code tasks, and three model scales (0.6B, 1.7B, 4B). We find that multi-agent RL usually improves over base models, but gains depend jointly on workflow, task, and scale, not on policy sharing alone. Isolated-Policy tends to reach higher peak accuracy yet more often falls off a terminal accuracy cliff, while Shared-Policy training does not eliminate failure; it redistributes failure into qualitatively different patterns. We then explain the strongest of these patterns through role-level gradient dynamics induced by workflow topology and policy routing: under Isolated-Policy, parallel same-role agents on shared prompts amplify per-role gradients and drive terminal degradation in Voting and Orch-Workers workflows; under Shared-Policy, asymmetric per-step gradient mass causes the shared policy to be captured by the dominant role, producing different failure signatures by task and workflow. Together, the empirical map and its underlying mechanisms show that policy sharing routes training pressure through different channels rather than offering uniform stability, making it a design choice with workflow- and task-conditional tradeoffs.
MetaAgent-X : Breaking the Ceiling of Automatic Multi-Agent Systems via End-to-End Reinforcement Learning
May 14, 2026Automatic multi-agent systems aim to instantiate agent workflows without relying on manually designed or fixed orchestration. However, existing automatic MAS approaches remain only partially adaptive: they either perform training-free test-time search or optimize the meta-level designer while keeping downstream execution agents frozen, which creating a frozen-executor ceiling and leaving the end-to-end training of self-designing and self-executing agentic models unexplored. To address this, we introduce MetaAgent-X, an end-to-end reinforcement learning framework that jointly optimizes automatic MAS design and execution. MetaAgent-X enables script-based MAS generation, execution rollout collection, and credit assignment for both designer and executor trajectories. To support stable and scalable optimization, we propose Executor Designer Hierarchical Rollout and Stagewise Co-evolution to improve training stability and expose the dynamics of designer-executor co-evolution. MetaAgent-X consistently outperforms existing automatic MAS baselines, achieving up to 21.7% gains. Comprehensive ablations show that both designer and executor improve throughout training, and that effective automatic MAS learning follows a stagewise co-evolution process. These results establish end-to-end trainable automatic MAS as a practical paradigm for building self-designing and self-executing agentic models.
EVA: Efficient Reinforcement Learning for End-to-End Video Agent
Mar 24, 2026Video understanding with multimodal large language models (MLLMs) remains challenging due to the long token sequences of videos, which contain extensive temporal dependencies and redundant frames. Existing approaches typically treat MLLMs as passive recognizers, processing entire videos or uniformly sampled frames without adaptive reasoning. Recent agent-based methods introduce external tools, yet still depend on manually designed workflows and perception-first strategies, resulting in inefficiency on long videos. We present EVA, an Efficient Reinforcement Learning framework for End-to-End Video Agent, which enables planning-before-perception through iterative summary-plan-action-reflection reasoning. EVA autonomously decides what to watch, when to watch, and how to watch, achieving query-driven and efficient video understanding. To train such agents, we design a simple yet effective three-stage learning pipeline - comprising supervised fine-tuning (SFT), Kahneman-Tversky Optimization (KTO), and Generalized Reward Policy Optimization (GRPO) - that bridges supervised imitation and reinforcement learning. We further construct high-quality datasets for each stage, supporting stable and reproducible training. We evaluate EVA on six video understanding benchmarks, demonstrating its comprehensive capabilities. Compared with existing baselines, EVA achieves a substantial improvement of 6-12% over general MLLM baselines and a further 1-3% gain over prior adaptive agent methods. Our code and model are available at https://github.com/wangruohui/EfficientVideoAgent.
Live-Evo: Online Evolution of Agentic Memory from Continuous Feedback
Feb 02, 2026Large language model (LLM) agents are increasingly equipped with memory, which are stored experience and reusable guidance that can improve task-solving performance. Recent \emph{self-evolving} systems update memory based on interaction outcomes, but most existing evolution pipelines are developed for static train/test splits and only approximate online learning by folding static benchmarks, making them brittle under true distribution shift and continuous feedback. We introduce \textsc{Live-Evo}, an online self-evolving memory system that learns from a stream of incoming data over time. \textsc{Live-Evo} decouples \emph{what happened} from \emph{how to use it} via an Experience Bank and a Meta-Guideline Bank, compiling task-adaptive guidelines from retrieved experiences for each task. To manage memory online, \textsc{Live-Evo} maintains experience weights and updates them from feedback: experiences that consistently help are reinforced and retrieved more often, while misleading or stale experiences are down-weighted and gradually forgotten, analogous to reinforcement and decay in human memory. On the live \textit{Prophet Arena} benchmark over a 10-week horizon, \textsc{Live-Evo} improves Brier score by 20.8\% and increases market returns by 12.9\%, while also transferring to deep-research benchmarks with consistent gains over strong baselines. Our code is available at https://github.com/ag2ai/Live-Evo.
ELV-Halluc: Benchmarking Semantic Aggregation Hallucinations in Long Video Understanding
Aug 29, 2025

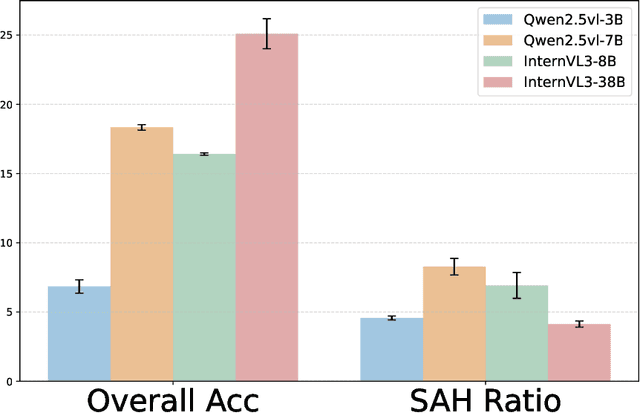

Video multimodal large language models (Video-MLLMs) have achieved remarkable progress in video understanding. However, they remain vulnerable to hallucination-producing content inconsistent with or unrelated to video inputs. Previous video hallucination benchmarks primarily focus on short-videos. They attribute hallucinations to factors such as strong language priors, missing frames, or vision-language biases introduced by the visual encoder. While these causes indeed account for most hallucinations in short videos, they still oversimplify the cause of hallucinations. Sometimes, models generate incorrect outputs but with correct frame-level semantics. We refer to this type of hallucination as Semantic Aggregation Hallucination (SAH), which arises during the process of aggregating frame-level semantics into event-level semantic groups. Given that SAH becomes particularly critical in long videos due to increased semantic complexity across multiple events, it is essential to separate and thoroughly investigate the causes of this type of hallucination. To address the above issues, we introduce ELV-Halluc, the first benchmark dedicated to long-video hallucination, enabling a systematic investigation of SAH. Our experiments confirm the existence of SAH and show that it increases with semantic complexity. Additionally, we find that models are more prone to SAH on rapidly changing semantics. Moreover, we discuss potential approaches to mitigate SAH. We demonstrate that positional encoding strategy contributes to alleviating SAH, and further adopt DPO strategy to enhance the model's ability to distinguish semantics within and across events. To support this, we curate a dataset of 8K adversarial data pairs and achieve improvements on both ELV-Halluc and Video-MME, including a substantial 27.7% reduction in SAH ratio.
MetaAgent: Automatically Constructing Multi-Agent Systems Based on Finite State Machines
Jul 30, 2025Large Language Models (LLMs) have demonstrated the ability to solve a wide range of practical tasks within multi-agent systems. However, existing human-designed multi-agent frameworks are typically limited to a small set of pre-defined scenarios, while current automated design methods suffer from several limitations, such as the lack of tool integration, dependence on external training data, and rigid communication structures. In this paper, we propose MetaAgent, a finite state machine based framework that can automatically generate a multi-agent system. Given a task description, MetaAgent will design a multi-agent system and polish it through an optimization algorithm. When the multi-agent system is deployed, the finite state machine will control the agent's actions and the state transitions. To evaluate our framework, we conduct experiments on both text-based tasks and practical tasks. The results indicate that the generated multi-agent system surpasses other auto-designed methods and can achieve a comparable performance with the human-designed multi-agent system, which is optimized for those specific tasks.
PyBench: Evaluating LLM Agent on various real-world coding tasks
Jul 23, 2024



The LLM Agent, equipped with a code interpreter, is capable of automatically solving real-world coding tasks, such as data analysis and image editing. However, existing benchmarks primarily focus on either simplistic tasks, such as completing a few lines of code, or on extremely complex and specific tasks at the repository level, neither of which are representative of various daily coding tasks. To address this gap, we introduce \textbf{PyBench}, a benchmark encompassing five main categories of real-world tasks, covering more than 10 types of files. Given a high-level user query and related files, the LLM Agent needs to reason and execute Python code via a code interpreter for a few turns before making a formal response to fulfill the user's requirements. Successfully addressing tasks in PyBench demands a robust understanding of various Python packages, superior reasoning capabilities, and the ability to incorporate feedback from executed code. Our evaluations indicate that current open-source LLMs are struggling with these tasks. Hence, we conduct analysis and experiments on four kinds of datasets proving that comprehensive abilities are needed for PyBench. Our fine-tuned 8B size model: \textbf{PyLlama3} achieves an exciting performance on PyBench which surpasses many 33B and 70B size models. Our Benchmark, Training Dataset, and Model are available at: \href{https://github.com/Mercury7353/PyBench}{https://github.com/Mercury7353/PyBench}
Depending on yourself when you should: Mentoring LLM with RL agents to become the master in cybersecurity games
Mar 26, 2024



Integrating LLM and reinforcement learning (RL) agent effectively to achieve complementary performance is critical in high stake tasks like cybersecurity operations. In this study, we introduce SecurityBot, a LLM agent mentored by pre-trained RL agents, to support cybersecurity operations. In particularly, the LLM agent is supported with a profile module to generated behavior guidelines, a memory module to accumulate local experiences, a reflection module to re-evaluate choices, and an action module to reduce action space. Additionally, it adopts the collaboration mechanism to take suggestions from pre-trained RL agents, including a cursor for dynamic suggestion taken, an aggregator for multiple mentors' suggestions ranking and a caller for proactive suggestion asking. Building on the CybORG experiment framework, our experiences show that SecurityBot demonstrates significant performance improvement compared with LLM or RL standalone, achieving the complementary performance in the cybersecurity games.