 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVCap: Hypergeometric Rewards for Weak-to-Strong Visual Captioning
May 27, 2026Visual captioning requires models to capture visual content faithfully while minimizing both omission and hallucination. As the dominant paradigm for captioning, MLLMs have achieved strong performance through scaling and high-quality data. Recently, RL has emerged as a key route to driving MLLMs toward higher precision and broader coverage, however, existing reward designs for captioning fail to provide fine-grained and reliable signals for factual verification, limiting their effectiveness. To address this, we propose VCap, a Witness-Adjudicator reward that pairs the reference caption (a witness) with the visual signal (an adjudicator). By explicitly verifying factual consistency between the reference and policy-generated captions grounded in the visual signal, VCap delivers a reward signal with hypergeometric-distribution-level precision for caption quality verification. This design enables effective learning even from imperfect references, facilitating weak-to-strong generalization in RL training. In our experiments, an 8B model trained with VCap outperforms open- and closed-source SOTA models on multiple image and video captioning benchmarks. Human evaluation further confirms its strong alignment with factual correctness. Additionally, VCap improves MLLM perceptual capability, generalizes across tasks, and surpasses best-of-N distillation, challenging prior assumptions about RLVR.
From Pixels to Words -- Towards Native One-Vision Models at Scale
May 27, 2026Current vision-language models (VLMs) typically stitch together separate image encoders and language decoders via multi-stage alignment, a modular framework that inevitably fragments pixel-level signals across frames and scatters early pixel-word interactions. In parallel, native VLMs, despite impressive performance on single images, remain largely unexplored in multi-image, video understanding, and spatial intelligence. Hence, we introduce NEO-ov, a native foundation model that learns cross-frame and pixel-word correspondence end-to-end, without any external encoders, auxiliary adapters, or post-hoc fusion. By eliminating module boundaries entirely, NEO-ov enables fine-grained and unified spatiotemporal modeling to emerge natively inside the model. Notably, NEO-ov largely narrows the gap to modular counterparts while excelling at fine-grained visual perception, validating that native "one-vision" architectures are not only feasible but competitive at scale. Beyond empirical performance, we unveil systematic architectural analyses and detailed training recipes to facilitate subsequent native multimodal modeling. Our code and models are publicly available at: https://github.com/EvolvingLMMs-Lab/NEO.
EVA: Efficient Reinforcement Learning for End-to-End Video Agent
Mar 24, 2026Video understanding with multimodal large language models (MLLMs) remains challenging due to the long token sequences of videos, which contain extensive temporal dependencies and redundant frames. Existing approaches typically treat MLLMs as passive recognizers, processing entire videos or uniformly sampled frames without adaptive reasoning. Recent agent-based methods introduce external tools, yet still depend on manually designed workflows and perception-first strategies, resulting in inefficiency on long videos. We present EVA, an Efficient Reinforcement Learning framework for End-to-End Video Agent, which enables planning-before-perception through iterative summary-plan-action-reflection reasoning. EVA autonomously decides what to watch, when to watch, and how to watch, achieving query-driven and efficient video understanding. To train such agents, we design a simple yet effective three-stage learning pipeline - comprising supervised fine-tuning (SFT), Kahneman-Tversky Optimization (KTO), and Generalized Reward Policy Optimization (GRPO) - that bridges supervised imitation and reinforcement learning. We further construct high-quality datasets for each stage, supporting stable and reproducible training. We evaluate EVA on six video understanding benchmarks, demonstrating its comprehensive capabilities. Compared with existing baselines, EVA achieves a substantial improvement of 6-12% over general MLLM baselines and a further 1-3% gain over prior adaptive agent methods. Our code and model are available at https://github.com/wangruohui/EfficientVideoAgent.
ELV-Halluc: Benchmarking Semantic Aggregation Hallucinations in Long Video Understanding
Aug 29, 2025

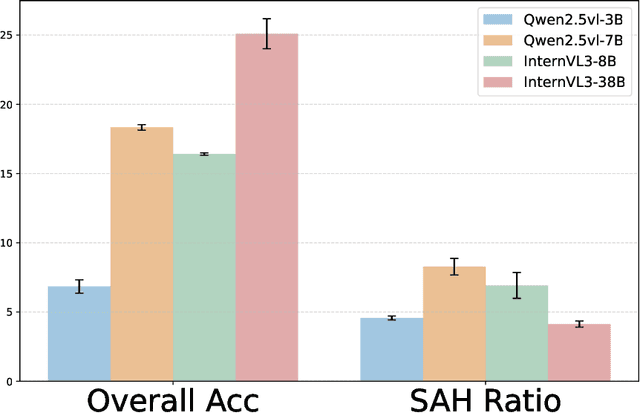

Video multimodal large language models (Video-MLLMs) have achieved remarkable progress in video understanding. However, they remain vulnerable to hallucination-producing content inconsistent with or unrelated to video inputs. Previous video hallucination benchmarks primarily focus on short-videos. They attribute hallucinations to factors such as strong language priors, missing frames, or vision-language biases introduced by the visual encoder. While these causes indeed account for most hallucinations in short videos, they still oversimplify the cause of hallucinations. Sometimes, models generate incorrect outputs but with correct frame-level semantics. We refer to this type of hallucination as Semantic Aggregation Hallucination (SAH), which arises during the process of aggregating frame-level semantics into event-level semantic groups. Given that SAH becomes particularly critical in long videos due to increased semantic complexity across multiple events, it is essential to separate and thoroughly investigate the causes of this type of hallucination. To address the above issues, we introduce ELV-Halluc, the first benchmark dedicated to long-video hallucination, enabling a systematic investigation of SAH. Our experiments confirm the existence of SAH and show that it increases with semantic complexity. Additionally, we find that models are more prone to SAH on rapidly changing semantics. Moreover, we discuss potential approaches to mitigate SAH. We demonstrate that positional encoding strategy contributes to alleviating SAH, and further adopt DPO strategy to enhance the model's ability to distinguish semantics within and across events. To support this, we curate a dataset of 8K adversarial data pairs and achieve improvements on both ELV-Halluc and Video-MME, including a substantial 27.7% reduction in SAH ratio.
Recent Advances in Data-driven Intelligent Control for Wireless Communication: A Comprehensive Survey
Aug 06, 2024The advent of next-generation wireless communication systems heralds an era characterized by high data rates, low latency, massive connectivity, and superior energy efficiency. These systems necessitate innovative and adaptive strategies for resource allocation and device behavior control in wireless networks. Traditional optimization-based methods have been found inadequate in meeting the complex demands of these emerging systems. As the volume of data continues to escalate, the integration of data-driven methods has become indispensable for enabling adaptive and intelligent control mechanisms in future wireless communication systems. This comprehensive survey explores recent advancements in data-driven methodologies applied to wireless communication networks. It focuses on developments over the past five years and their application to various control objectives within wireless cyber-physical systems. It encompasses critical areas such as link adaptation, user scheduling, spectrum allocation, beam management, power control, and the co-design of communication and control systems. We provide an in-depth exploration of the technical underpinnings that support these data-driven approaches, including the algorithms, models, and frameworks developed to enhance network performance and efficiency. We also examine the challenges that current data-driven algorithms face, particularly in the context of the dynamic and heterogeneous nature of next-generation wireless networks. The paper provides a critical analysis of these challenges and offers insights into potential solutions and future research directions. This includes discussing the adaptability, integration with 6G, and security of data-driven methods in the face of increasing network complexity and data volume.