 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChat-Capsule: A Hierarchical Capsule for Dialog-level Emotion Analysis
Mar 23, 2022

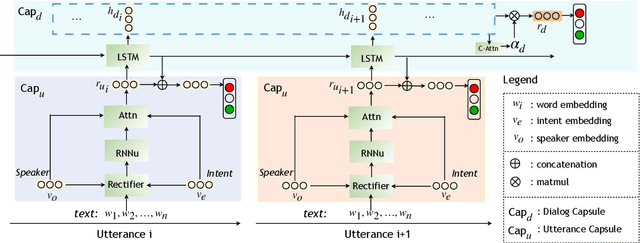
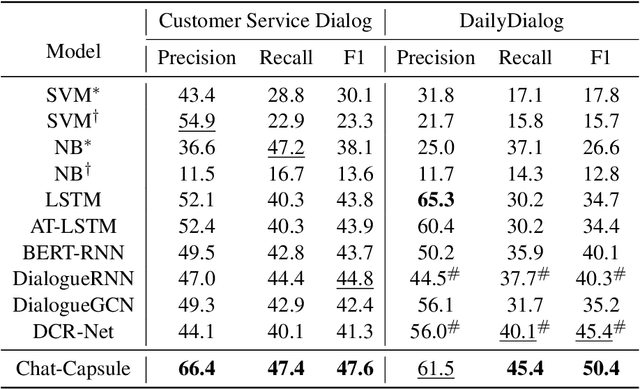
Many studies on dialog emotion analysis focus on utterance-level emotion only. These models hence are not optimized for dialog-level emotion detection, i.e. to predict the emotion category of a dialog as a whole. More importantly, these models cannot benefit from the context provided by the whole dialog. In real-world applications, annotations to dialog could fine-grained, including both utterance-level tags (e.g. speaker type, intent category, and emotion category), and dialog-level tags (e.g. user satisfaction, and emotion curve category). In this paper, we propose a Context-based Hierarchical Attention Capsule~(Chat-Capsule) model, which models both utterance-level and dialog-level emotions and their interrelations. On a dialog dataset collected from customer support of an e-commerce platform, our model is also able to predict user satisfaction and emotion curve category. Emotion curve refers to the change of emotions along the development of a conversation. Experiments show that the proposed Chat-Capsule outperform state-of-the-art baselines on both benchmark dataset and proprietary dataset. Source code will be released upon acceptance.
Exact Decomposition of Joint Low Rankness and Local Smoothness Plus Sparse Matrices
Jan 29, 2022



It is known that the decomposition in low-rank and sparse matrices (\textbf{L+S} for short) can be achieved by several Robust PCA techniques. Besides the low rankness, the local smoothness (\textbf{LSS}) is a vitally essential prior for many real-world matrix data such as hyperspectral images and surveillance videos, which makes such matrices have low-rankness and local smoothness properties at the same time. This poses an interesting question: Can we make a matrix decomposition in terms of \textbf{L\&LSS +S } form exactly? To address this issue, we propose in this paper a new RPCA model based on three-dimensional correlated total variation regularization (3DCTV-RPCA for short) by fully exploiting and encoding the prior expression underlying such joint low-rank and local smoothness matrices. Specifically, using a modification of Golfing scheme, we prove that under some mild assumptions, the proposed 3DCTV-RPCA model can decompose both components exactly, which should be the first theoretical guarantee among all such related methods combining low rankness and local smoothness. In addition, by utilizing Fast Fourier Transform (FFT), we propose an efficient ADMM algorithm with a solid convergence guarantee for solving the resulting optimization problem. Finally, a series of experiments on both simulations and real applications are carried out to demonstrate the general validity of the proposed 3DCTV-RPCA model.
Network-Aware 5G Edge Computing for Object Detection: Augmenting Wearables to "See'' More, Farther and Faster
Dec 25, 2021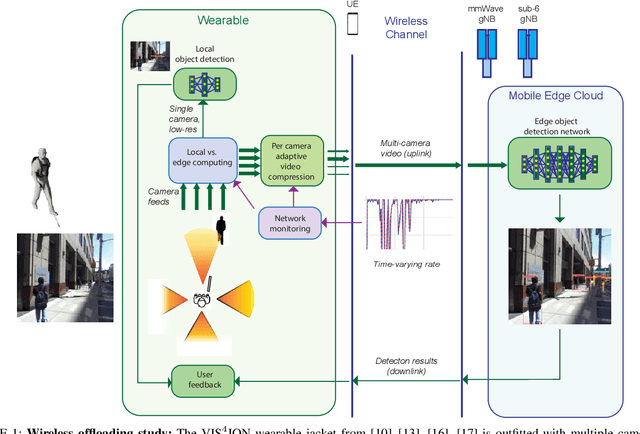
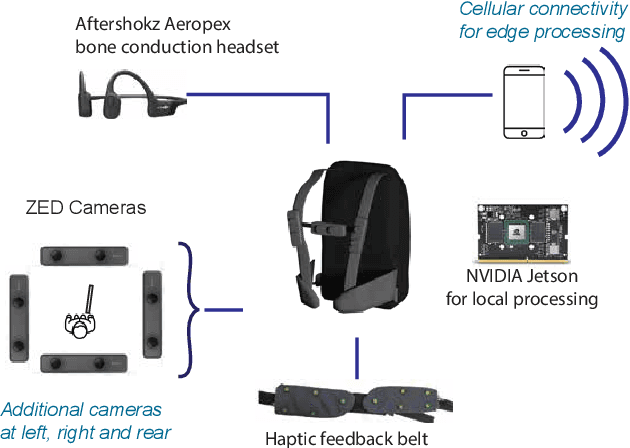
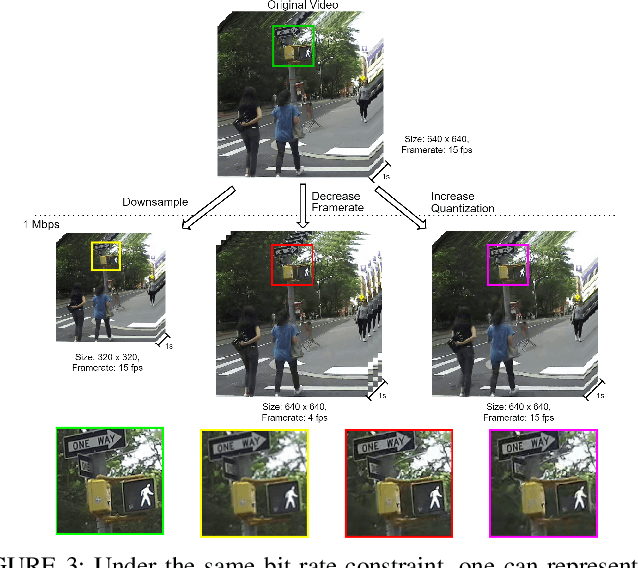
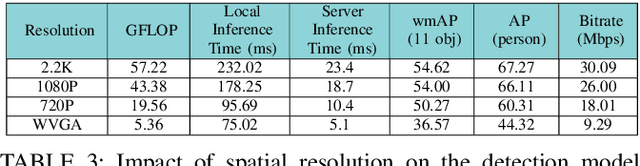
Advanced wearable devices are increasingly incorporating high-resolution multi-camera systems. As state-of-the-art neural networks for processing the resulting image data are computationally demanding, there has been growing interest in leveraging fifth generation (5G) wireless connectivity and mobile edge computing for offloading this processing to the cloud. To assess this possibility, this paper presents a detailed simulation and evaluation of 5G wireless offloading for object detection within a powerful, new smart wearable called VIS4ION, for the Blind-and-Visually Impaired (BVI). The current VIS4ION system is an instrumented book-bag with high-resolution cameras, vision processing and haptic and audio feedback. The paper considers uploading the camera data to a mobile edge cloud to perform real-time object detection and transmitting the detection results back to the wearable. To determine the video requirements, the paper evaluates the impact of video bit rate and resolution on object detection accuracy and range. A new street scene dataset with labeled objects relevant to BVI navigation is leveraged for analysis. The vision evaluation is combined with a detailed full-stack wireless network simulation to determine the distribution of throughputs and delays with real navigation paths and ray-tracing from new high-resolution 3D models in an urban environment. For comparison, the wireless simulation considers both a standard 4G-Long Term Evolution (LTE) carrier and high-rate 5G millimeter-wave (mmWave) carrier. The work thus provides a thorough and realistic assessment of edge computing with mmWave connectivity in an application with both high bandwidth and low latency requirements.
DegreEmbed: incorporating entity embedding into logic rule learning for knowledge graph reasoning
Dec 18, 2021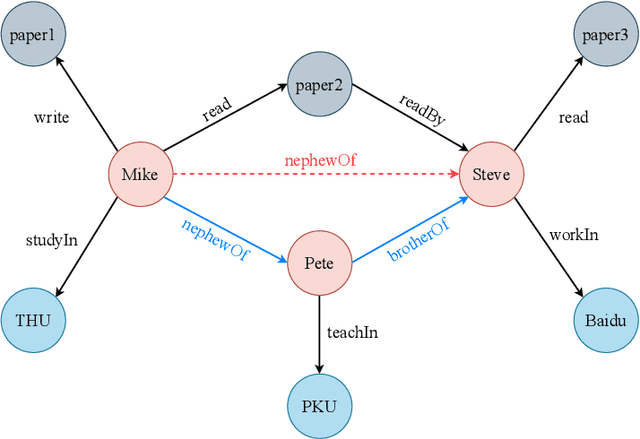
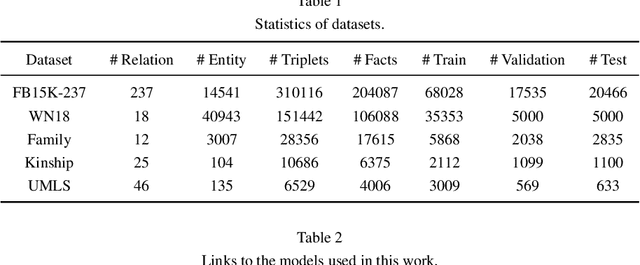
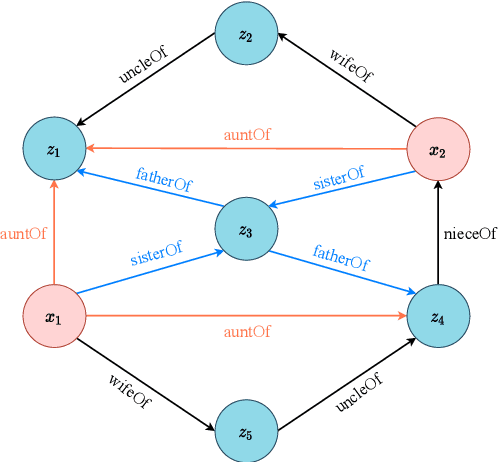

Knowledge graphs (KGs), as structured representations of real world facts, are intelligent databases incorporating human knowledge that can help machine imitate the way of human problem solving. However, due to the nature of rapid iteration as well as incompleteness of data, KGs are usually huge and there are inevitably missing facts in KGs. Link prediction for knowledge graphs is the task aiming to complete missing facts by reasoning based on the existing knowledge. Two main streams of research are widely studied: one learns low-dimensional embeddings for entities and relations that can capture latent patterns, and the other gains good interpretability by mining logical rules. Unfortunately, previous studies rarely pay attention to heterogeneous KGs. In this paper, we propose DegreEmbed, a model that combines embedding-based learning and logic rule mining for inferring on KGs. Specifically, we study the problem of predicting missing links in heterogeneous KGs that involve entities and relations of various types from the perspective of the degrees of nodes. Experimentally, we demonstrate that our DegreEmbed model outperforms the state-of-the-art methods on real world datasets. Meanwhile, the rules mined by our model are of high quality and interpretability.
Generalization Performance of Empirical Risk Minimization on Over-parameterized Deep ReLU Nets
Dec 14, 2021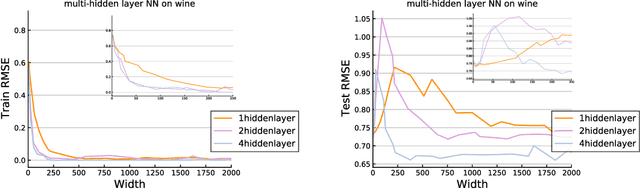
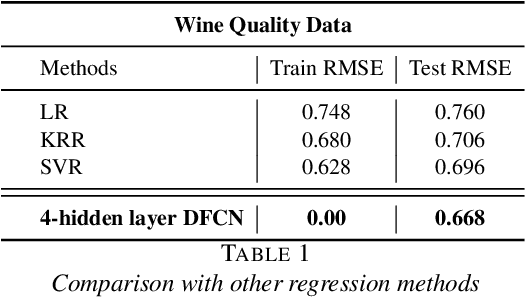
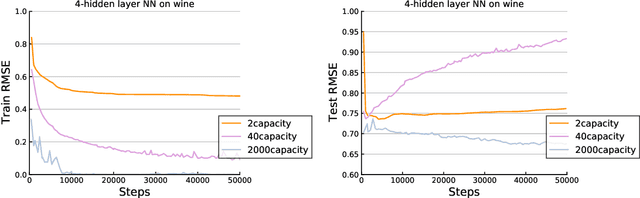
In this paper, we study the generalization performance of global minima for implementing empirical risk minimization (ERM) on over-parameterized deep ReLU nets. Using a novel deepening scheme for deep ReLU nets, we rigorously prove that there exist perfect global minima achieving almost optimal generalization error bounds for numerous types of data under mild conditions. Since over-parameterization is crucial to guarantee that the global minima of ERM on deep ReLU nets can be realized by the widely used stochastic gradient descent (SGD) algorithm, our results indeed fill a gap between optimization and generalization.
MPLR: a novel model for multi-target learning of logical rules for knowledge graph reasoning
Dec 12, 2021
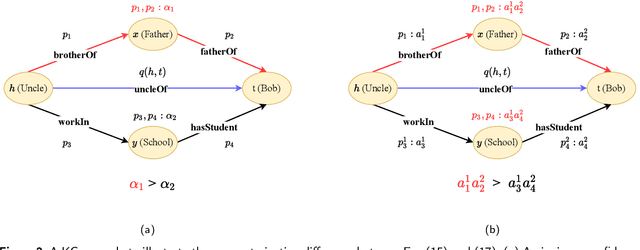

Large-scale knowledge graphs (KGs) provide structured representations of human knowledge. However, as it is impossible to contain all knowledge, KGs are usually incomplete. Reasoning based on existing facts paves a way to discover missing facts. In this paper, we study the problem of learning logic rules for reasoning on knowledge graphs for completing missing factual triplets. Learning logic rules equips a model with strong interpretability as well as the ability to generalize to similar tasks. We propose a model called MPLR that improves the existing models to fully use training data and multi-target scenarios are considered. In addition, considering the deficiency in evaluating the performance of models and the quality of mined rules, we further propose two novel indicators to help with the problem. Experimental results empirically demonstrate that our MPLR model outperforms state-of-the-art methods on five benchmark datasets. The results also prove the effectiveness of the indicators.
CDLNet: Noise-Adaptive Convolutional Dictionary Learning Network for Blind Denoising and Demosaicing
Dec 08, 2021

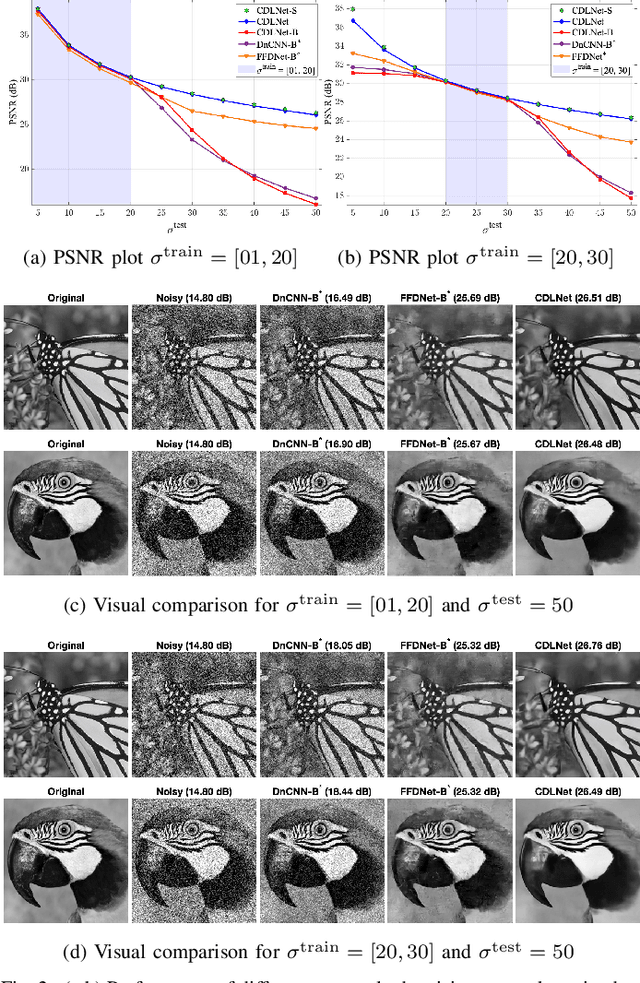
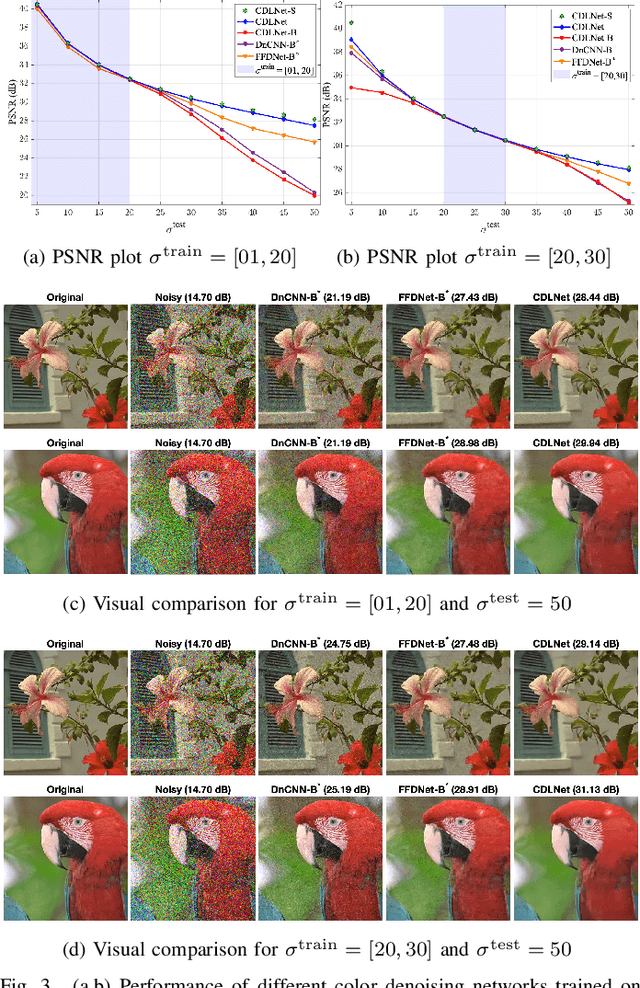
Deep learning based methods hold state-of-the-art results in low-level image processing tasks, but remain difficult to interpret due to their black-box construction. Unrolled optimization networks present an interpretable alternative to constructing deep neural networks by deriving their architecture from classical iterative optimization methods without use of tricks from the standard deep learning tool-box. So far, such methods have demonstrated performance close to that of state-of-the-art models while using their interpretable construction to achieve a comparably low learned parameter count. In this work, we propose an unrolled convolutional dictionary learning network (CDLNet) and demonstrate its competitive denoising and joint denoising and demosaicing (JDD) performance both in low and high parameter count regimes. Specifically, we show that the proposed model outperforms state-of-the-art fully convolutional denoising and JDD models when scaled to a similar parameter count. In addition, we leverage the model's interpretable construction to propose a noise-adaptive parameterization of thresholds in the network that enables state-of-the-art blind denoising performance, and near perfect generalization on noise-levels unseen during training. Furthermore, we show that such performance extends to the JDD task and unsupervised learning.
Scanpath Prediction on Information Visualisations
Dec 04, 2021
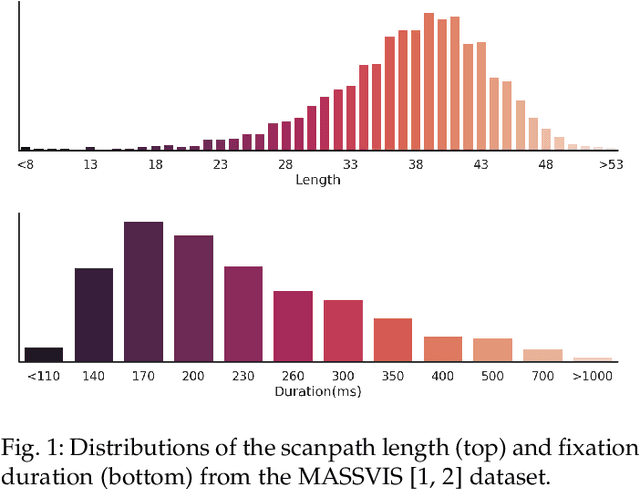
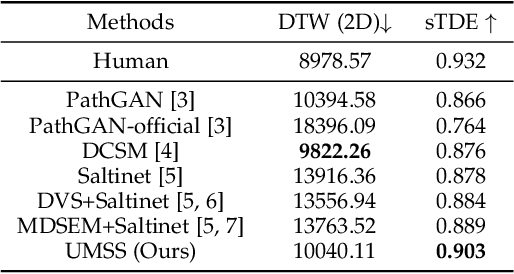
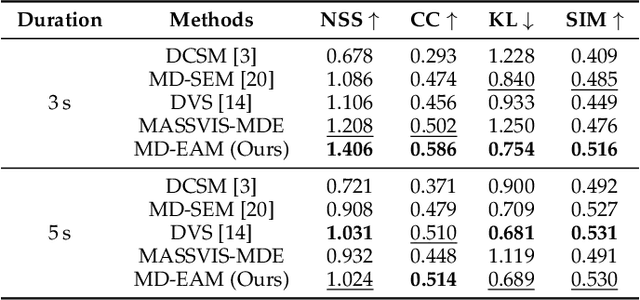
We propose Unified Model of Saliency and Scanpaths (UMSS) -- a model that learns to predict visual saliency and scanpaths (i.e. sequences of eye fixations) on information visualisations. Although scanpaths provide rich information about the importance of different visualisation elements during the visual exploration process, prior work has been limited to predicting aggregated attention statistics, such as visual saliency. We present in-depth analyses of gaze behaviour for different information visualisation elements (e.g. Title, Label, Data) on the popular MASSVIS dataset. We show that while, overall, gaze patterns are surprisingly consistent across visualisations and viewers, there are also structural differences in gaze dynamics for different elements. Informed by our analyses, UMSS first predicts multi-duration element-level saliency maps, then probabilistically samples scanpaths from them. Extensive experiments on MASSVIS show that our method consistently outperforms state-of-the-art methods with respect to several, widely used scanpath and saliency evaluation metrics. Our method achieves a relative improvement in sequence score of 11.5% for scanpath prediction, and a relative improvement in Pearson correlation coefficient of up to 23.6% for saliency prediction. These results are auspicious and point towards richer user models and simulations of visual attention on visualisations without the need for any eye tracking equipment.
Domain Adaptation of Networks for Camera Pose Estimation: Learning Camera Pose Estimation Without Pose Labels
Nov 29, 2021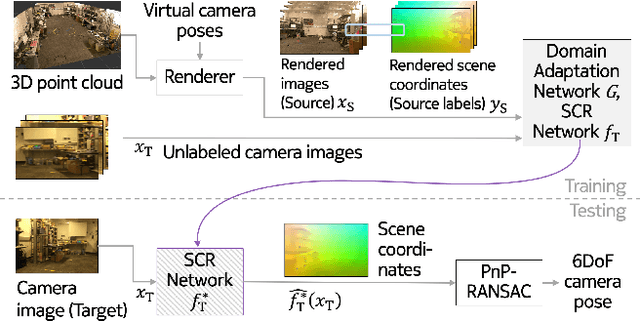
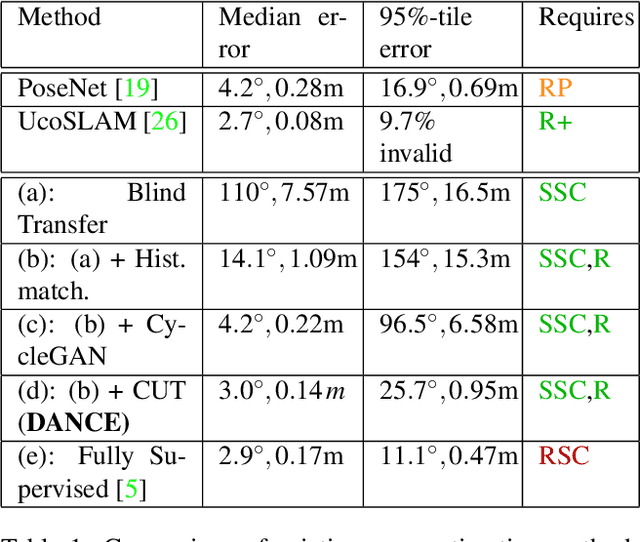
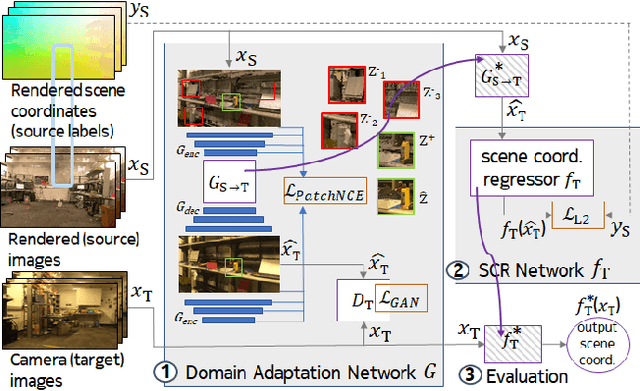

One of the key criticisms of deep learning is that large amounts of expensive and difficult-to-acquire training data are required in order to train models with high performance and good generalization capabilities. Focusing on the task of monocular camera pose estimation via scene coordinate regression (SCR), we describe a novel method, Domain Adaptation of Networks for Camera pose Estimation (DANCE), which enables the training of models without access to any labels on the target task. DANCE requires unlabeled images (without known poses, ordering, or scene coordinate labels) and a 3D representation of the space (e.g., a scanned point cloud), both of which can be captured with minimal effort using off-the-shelf commodity hardware. DANCE renders labeled synthetic images from the 3D model, and bridges the inevitable domain gap between synthetic and real images by applying unsupervised image-level domain adaptation techniques (unpaired image-to-image translation). When tested on real images, the SCR model trained with DANCE achieved comparable performance to its fully supervised counterpart (in both cases using PnP-RANSAC for final pose estimation) at a fraction of the cost. Our code and dataset are available at https://github.com/JackLangerman/dance
Nyström Regularization for Time Series Forecasting
Nov 13, 2021
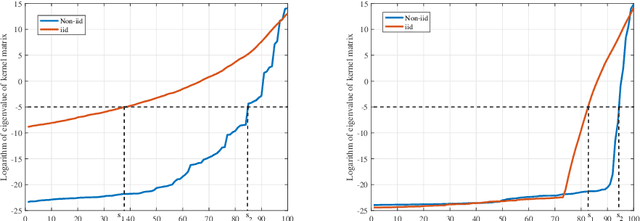
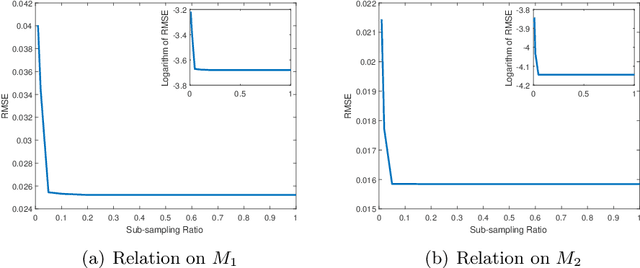

This paper focuses on learning rate analysis of Nystr\"{o}m regularization with sequential sub-sampling for $\tau$-mixing time series. Using a recently developed Banach-valued Bernstein inequality for $\tau$-mixing sequences and an integral operator approach based on second-order decomposition, we succeed in deriving almost optimal learning rates of Nystr\"{o}m regularization with sequential sub-sampling for $\tau$-mixing time series. A series of numerical experiments are carried out to verify our theoretical results, showing the excellent learning performance of Nystr\"{o}m regularization with sequential sub-sampling in learning massive time series data. All these results extend the applicable range of Nystr\"{o}m regularization from i.i.d. samples to non-i.i.d. sequences.