 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpike2Former: Efficient Spiking Transformer for High-performance Image Segmentation
Dec 19, 2024



Spiking Neural Networks (SNNs) have a low-power advantage but perform poorly in image segmentation tasks. The reason is that directly converting neural networks with complex architectural designs for segmentation tasks into spiking versions leads to performance degradation and non-convergence. To address this challenge, we first identify the modules in the architecture design that lead to the severe reduction in spike firing, make targeted improvements, and propose Spike2Former architecture. Second, we propose normalized integer spiking neurons to solve the training stability problem of SNNs with complex architectures. We set a new state-of-the-art for SNNs in various semantic segmentation datasets, with a significant improvement of +12.7% mIoU and 5.0 efficiency on ADE20K, +14.3% mIoU and 5.2 efficiency on VOC2012, and +9.1% mIoU and 6.6 efficiency on CityScapes.
Low-Rank Mixture-of-Experts for Continual Medical Image Segmentation
Jun 19, 2024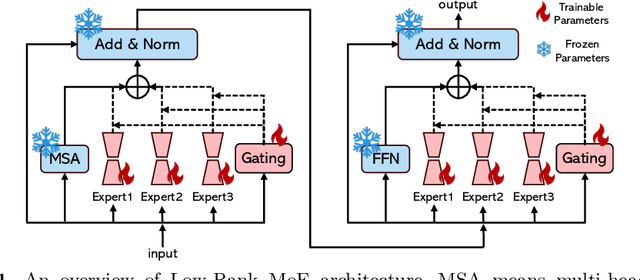
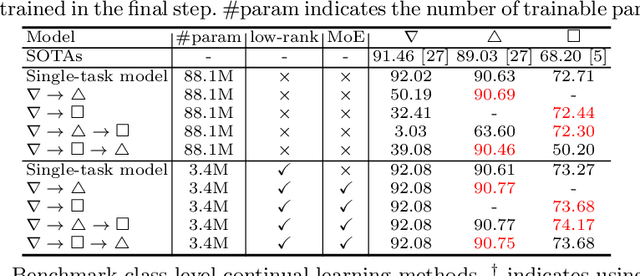
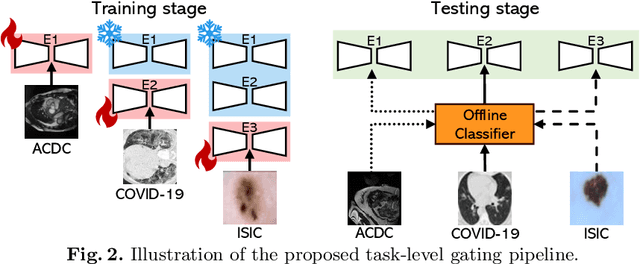
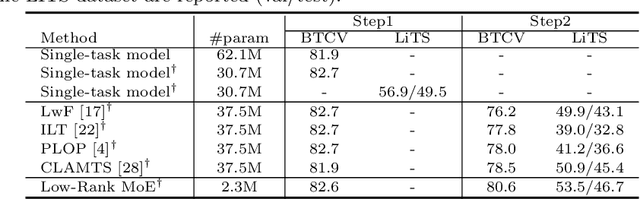
The primary goal of continual learning (CL) task in medical image segmentation field is to solve the "catastrophic forgetting" problem, where the model totally forgets previously learned features when it is extended to new categories (class-level) or tasks (task-level). Due to the privacy protection, the historical data labels are inaccessible. Prevalent continual learning methods primarily focus on generating pseudo-labels for old datasets to force the model to memorize the learned features. However, the incorrect pseudo-labels may corrupt the learned feature and lead to a new problem that the better the model is trained on the old task, the poorer the model performs on the new tasks. To avoid this problem, we propose a network by introducing the data-specific Mixture of Experts (MoE) structure to handle the new tasks or categories, ensuring that the network parameters of previous tasks are unaffected or only minimally impacted. To further overcome the tremendous memory costs caused by introducing additional structures, we propose a Low-Rank strategy which significantly reduces memory cost. We validate our method on both class-level and task-level continual learning challenges. Extensive experiments on multiple datasets show our model outperforms all other methods.
Scaling the Codebook Size of VQGAN to 100,000 with a Utilization Rate of 99%
Jun 17, 2024



In the realm of image quantization exemplified by VQGAN, the process encodes images into discrete tokens drawn from a codebook with a predefined size. Recent advancements, particularly with LLAMA 3, reveal that enlarging the codebook significantly enhances model performance. However, VQGAN and its derivatives, such as VQGAN-FC (Factorized Codes) and VQGAN-EMA, continue to grapple with challenges related to expanding the codebook size and enhancing codebook utilization. For instance, VQGAN-FC is restricted to learning a codebook with a maximum size of 16,384, maintaining a typically low utilization rate of less than 12% on ImageNet. In this work, we propose a novel image quantization model named VQGAN-LC (Large Codebook), which extends the codebook size to 100,000, achieving an utilization rate exceeding 99%. Unlike previous methods that optimize each codebook entry, our approach begins with a codebook initialized with 100,000 features extracted by a pre-trained vision encoder. Optimization then focuses on training a projector that aligns the entire codebook with the feature distributions of the encoder in VQGAN-LC. We demonstrate the superior performance of our model over its counterparts across a variety of tasks, including image reconstruction, image classification, auto-regressive image generation using GPT, and image creation with diffusion- and flow-based generative models. Code and models are available at https://github.com/zh460045050/VQGAN-LC.
Beyond Text: Frozen Large Language Models in Visual Signal Comprehension
Mar 12, 2024



In this work, we investigate the potential of a large language model (LLM) to directly comprehend visual signals without the necessity of fine-tuning on multi-modal datasets. The foundational concept of our method views an image as a linguistic entity, and translates it to a set of discrete words derived from the LLM's vocabulary. To achieve this, we present the Vision-to-Language Tokenizer, abbreviated as V2T Tokenizer, which transforms an image into a ``foreign language'' with the combined aid of an encoder-decoder, the LLM vocabulary, and a CLIP model. With this innovative image encoding, the LLM gains the ability not only for visual comprehension but also for image denoising and restoration in an auto-regressive fashion-crucially, without any fine-tuning. We undertake rigorous experiments to validate our method, encompassing understanding tasks like image recognition, image captioning, and visual question answering, as well as image denoising tasks like inpainting, outpainting, deblurring, and shift restoration. Code and models are available at https://github.com/zh460045050/V2L-Tokenizer.
Scribble Hides Class: Promoting Scribble-Based Weakly-Supervised Semantic Segmentation with Its Class Label
Feb 27, 2024



Scribble-based weakly-supervised semantic segmentation using sparse scribble supervision is gaining traction as it reduces annotation costs when compared to fully annotated alternatives. Existing methods primarily generate pseudo-labels by diffusing labeled pixels to unlabeled ones with local cues for supervision. However, this diffusion process fails to exploit global semantics and class-specific cues, which are important for semantic segmentation. In this study, we propose a class-driven scribble promotion network, which utilizes both scribble annotations and pseudo-labels informed by image-level classes and global semantics for supervision. Directly adopting pseudo-labels might misguide the segmentation model, thus we design a localization rectification module to correct foreground representations in the feature space. To further combine the advantages of both supervisions, we also introduce a distance entropy loss for uncertainty reduction, which adapts per-pixel confidence weights according to the reliable region determined by the scribble and pseudo-label's boundary. Experiments on the ScribbleSup dataset with different qualities of scribble annotations outperform all the previous methods, demonstrating the superiority and robustness of our method.The code is available at https://github.com/Zxl19990529/Class-driven-Scribble-Promotion-Network.
Multi-level Asymmetric Contrastive Learning for Medical Image Segmentation Pre-training
Sep 21, 2023Contrastive learning, which is a powerful technique for learning image-level representations from unlabeled data, leads a promising direction to dealing with the dilemma between large-scale pre-training and limited labeled data. However, most existing contrastive learning strategies are designed mainly for downstream tasks of natural images, therefore they are sub-optimal and even worse than learning from scratch when directly applied to medical images whose downstream tasks are usually segmentation. In this work, we propose a novel asymmetric contrastive learning framework named JCL for medical image segmentation with self-supervised pre-training. Specifically, (1) A novel asymmetric contrastive learning strategy is proposed to pre-train both encoder and decoder simultaneously in one-stage to provide better initialization for segmentation models. (2) A multi-level contrastive loss is designed to take the correspondence among feature-level, image-level and pixel-level projections, respectively into account to make sure multi-level representations can be learned by the encoder and decoder during pre-training. (3) Experiments on multiple medical image datasets indicate our JCL framework outperforms existing SOTA contrastive learning strategies.
Branches Mutual Promotion for End-to-End Weakly Supervised Semantic Segmentation
Aug 09, 2023



End-to-end weakly supervised semantic segmentation aims at optimizing a segmentation model in a single-stage training process based on only image annotations. Existing methods adopt an online-trained classification branch to provide pseudo annotations for supervising the segmentation branch. However, this strategy makes the classification branch dominate the whole concurrent training process, hindering these two branches from assisting each other. In our work, we treat these two branches equally by viewing them as diverse ways to generate the segmentation map, and add interactions on both their supervision and operation to achieve mutual promotion. For this purpose, a bidirectional supervision mechanism is elaborated to force the consistency between the outputs of these two branches. Thus, the segmentation branch can also give feedback to the classification branch to enhance the quality of localization seeds. Moreover, our method also designs interaction operations between these two branches to exchange their knowledge to assist each other. Experiments indicate our work outperforms existing end-to-end weakly supervised segmentation methods.
One-Pot Multi-Frame Denoising
Feb 18, 2023The performance of learning-based denoising largely depends on clean supervision. However, it is difficult to obtain clean images in many scenes. On the contrary, the capture of multiple noisy frames for the same field of view is available and often natural in real life. Therefore, it is necessary to avoid the restriction of clean labels and make full use of noisy data for model training. So we propose an unsupervised learning strategy named one-pot denoising (OPD) for multi-frame images. OPD is the first proposed unsupervised multi-frame denoising (MFD) method. Different from the traditional supervision schemes including both supervised Noise2Clean (N2C) and unsupervised Noise2Noise (N2N), OPD executes mutual supervision among all of the multiple frames, which gives learning more diversity of supervision and allows models to mine deeper into the correlation among frames. N2N has also been proved to be actually a simplified case of the proposed OPD. From the perspectives of data allocation and loss function, two specific implementations, random coupling (RC) and alienation loss (AL), are respectively provided to accomplish OPD during model training. In practice, our experiments demonstrate that OPD behaves as the SOTA unsupervised denoising method and is comparable to supervised N2C methods for synthetic Gaussian and Poisson noise, and real-world optical coherence tomography (OCT) speckle noise.
Bagging Regional Classification Activation Maps for Weakly Supervised Object Localization
Jul 16, 2022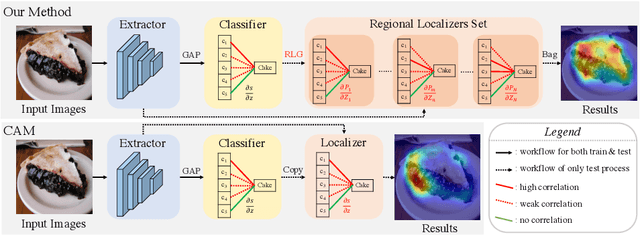
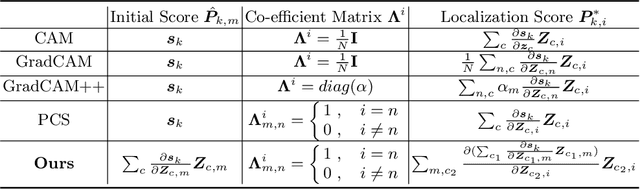
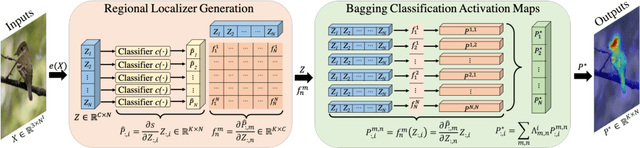
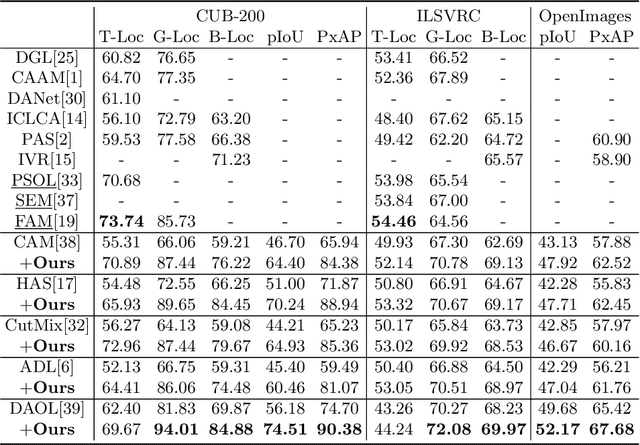
Classification activation map (CAM), utilizing the classification structure to generate pixel-wise localization maps, is a crucial mechanism for weakly supervised object localization (WSOL). However, CAM directly uses the classifier trained on image-level features to locate objects, making it prefers to discern global discriminative factors rather than regional object cues. Thus only the discriminative locations are activated when feeding pixel-level features into this classifier. To solve this issue, this paper elaborates a plug-and-play mechanism called BagCAMs to better project a well-trained classifier for the localization task without refining or re-training the baseline structure. Our BagCAMs adopts a proposed regional localizer generation (RLG) strategy to define a set of regional localizers and then derive them from a well-trained classifier. These regional localizers can be viewed as the base learner that only discerns region-wise object factors for localization tasks, and their results can be effectively weighted by our BagCAMs to form the final localization map. Experiments indicate that adopting our proposed BagCAMs can improve the performance of baseline WSOL methods to a great extent and obtains state-of-the-art performance on three WSOL benchmarks. Code are released at https://github.com/zh460045050/BagCAMs.
Weakly Supervised Object Localization as Domain Adaption
Mar 25, 2022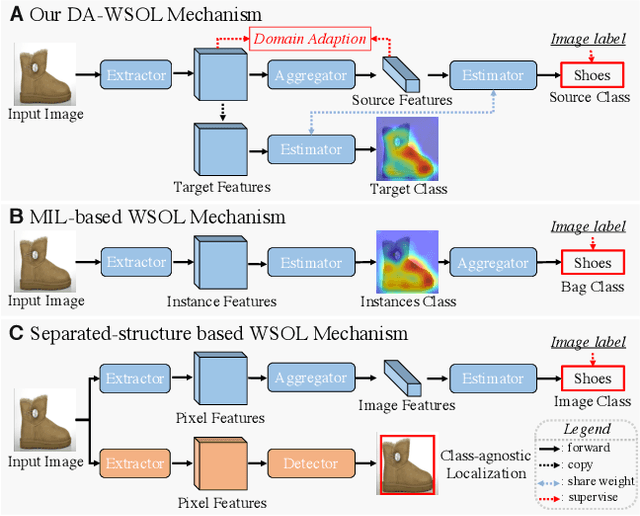
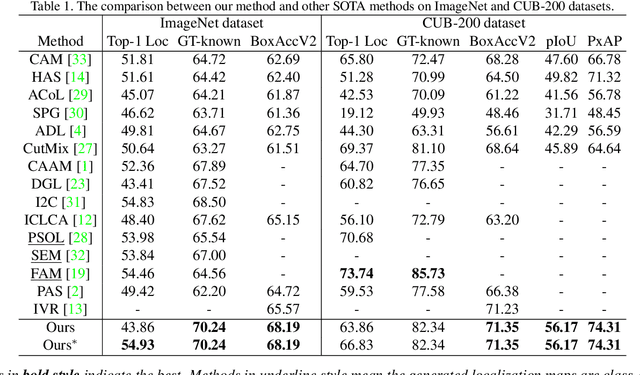
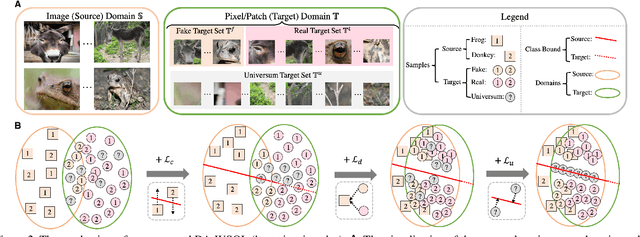
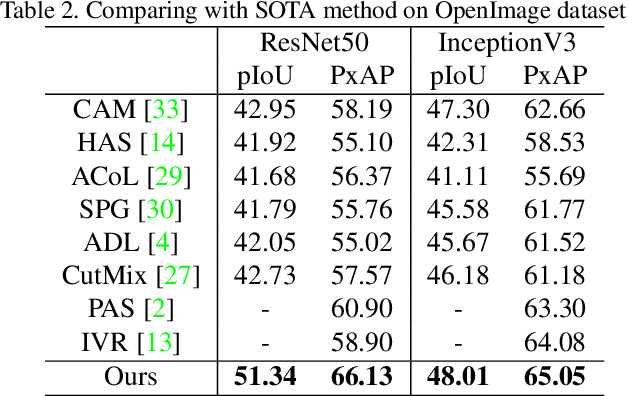
Weakly supervised object localization (WSOL) focuses on localizing objects only with the supervision of image-level classification masks. Most previous WSOL methods follow the classification activation map (CAM) that localizes objects based on the classification structure with the multi-instance learning (MIL) mechanism. However, the MIL mechanism makes CAM only activate discriminative object parts rather than the whole object, weakening its performance for localizing objects. To avoid this problem, this work provides a novel perspective that models WSOL as a domain adaption (DA) task, where the score estimator trained on the source/image domain is tested on the target/pixel domain to locate objects. Under this perspective, a DA-WSOL pipeline is designed to better engage DA approaches into WSOL to enhance localization performance. It utilizes a proposed target sampling strategy to select different types of target samples. Based on these types of target samples, domain adaption localization (DAL) loss is elaborated. It aligns the feature distribution between the two domains by DA and makes the estimator perceive target domain cues by Universum regularization. Experiments show that our pipeline outperforms SOTA methods on multi benchmarks. Code are released at \url{https://github.com/zh460045050/DA-WSOL_CVPR2022}.