 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicro-AU CLIP: Fine-Grained Contrastive Learning from Local Independence to Global Dependency for Micro-Expression Action Unit Detection
Mar 17, 2026Micro-expression (ME) action units (Micro-AUs) provide objective clues for fine-grained genuine emotion analysis. Most existing Micro-AU detection methods learn AU features from the whole facial image/video, which conflicts with the inherent locality of AU, resulting in insufficient perception of AU regions. In fact, each AU independently corresponds to specific localized facial muscle movements (local independence), while there is an inherent dependency between some AUs under specific emotional states (global dependency). Thus, this paper explores the effectiveness of the independence-to-dependency pattern and proposes a novel micro-AU detection framework, micro-AU CLIP, that uniquely decomposes the AU detection process into local semantic independence modeling (LSI) and global semantic dependency (GSD) modeling. In LSI, Patch Token Attention (PTA) is designed, mapping several local features within the AU region to the same feature space; In GSD, Global Dependency Attention (GDA) and Global Dependency Loss (GDLoss) are presented to model the global dependency relationships between different AUs, thereby enhancing each AU feature. Furthermore, considering CLIP's native limitations in micro-semantic alignment, a microAU contrastive loss (MiAUCL) is designed to learn AU features by a fine-grained alignment of visual and text features. Also, Micro-AU CLIP is effectively applied to ME recognition in an emotion-label-free way. The experimental results demonstrate that Micro-AU CLIP can fully learn fine-grained micro-AU features, achieving state-of-the-art performance.
Dual Stream Independence Decoupling for True Emotion Recognition under Masked Expressions
Mar 17, 2026Recongnizing true emotions from masked expressions is extremely challenging due to deliberate concealment. Existing paradigms recognize true emotions from masked-expression clips that contain onsetframes just starting to disguise. However, this paradigm may not reflect the actual disguised state, as the onsetframe leaks the true emotional information without reaching a stable disguise state. Thus, this paper introduces a novel apexframe-based paradigm that classifies true emotions from the apexframe with a stable disguised state. Furthermore, this paper proposes a novel dual stream independence decoupling framework that decouples true and disguised emotion features, avoiding the interference of disguised emotions on true emotions. For efficient decoupling, we design a decoupling loss group, comprising two classification losses that learn true emotion and disguised expression features, respectively, and a Hilbert-Schmidt Independence loss that enhances the independence of two features. Experiments demonstrate that the apexframe-based paradigm is challenging, and the proposed decouple framework improves recogntion performances.
FG-SGL: Fine-Grained Semantic Guidance Learning via Motion Process Decomposition for Micro-Gesture Recognition
Mar 17, 2026Micro-gesture recognition (MGR) is challenging due to subtle inter-class variations. Existing methods rely on category-level supervision, which is insufficient for capturing subtle and localized motion differences. Thus, this paper proposes a Fine-Grained Semantic Guidance Learning (FG-SGL) framework that jointly integrates fine-grained and category-level semantics to guide vision--language models in perceiving local MG motions. FG-SA adopts fine-grained semantic cues to guide the learning of local motion features, while CP-A enhances the separability of MG features through category-level semantic guidance. To support fine-grained semantic guidance, this work constructs a fine-grained textual dataset with human annotations that describes the dynamic process of MGs in four refined semantic dimensions. Furthermore, a Multi-Level Contrastive Optimization strategy is designed to jointly optimize both modules in a coarse-to-fine pattern. Experiments show that FG-SGL achieves competitive performance, validating the effectiveness of fine-grained semantic guidance for MGR.
BeFA: A General Behavior-driven Feature Adapter for Multimedia Recommendation
Jun 01, 2024Multimedia recommender systems focus on utilizing behavioral information and content information to model user preferences. Typically, it employs pre-trained feature encoders to extract content features, then fuses them with behavioral features. However, pre-trained feature encoders often extract features from the entire content simultaneously, including excessive preference-irrelevant details. We speculate that it may result in the extracted features not containing sufficient features to accurately reflect user preferences. To verify our hypothesis, we introduce an attribution analysis method for visually and intuitively analyzing the content features. The results indicate that certain products' content features exhibit the issues of information drift}and information omission,reducing the expressive ability of features. Building upon this finding, we propose an effective and efficient general Behavior-driven Feature Adapter (BeFA) to tackle these issues. This adapter reconstructs the content feature with the guidance of behavioral information, enabling content features accurately reflecting user preferences. Extensive experiments demonstrate the effectiveness of the adapter across all multimedia recommendation methods. The code will be publicly available upon the paper's acceptance.
LD4MRec: Simplifying and Powering Diffusion Model for Multimedia Recommendation
Sep 27, 2023



Multimedia recommendation aims to predict users' future behaviors based on historical behavioral data and item's multimodal information. However, noise inherent in behavioral data, arising from unintended user interactions with uninteresting items, detrimentally impacts recommendation performance. Recently, diffusion models have achieved high-quality information generation, in which the reverse process iteratively infers future information based on the corrupted state. It meets the need of predictive tasks under noisy conditions, and inspires exploring their application to predicting user behaviors. Nonetheless, several challenges must be addressed: 1) Classical diffusion models require excessive computation, which does not meet the efficiency requirements of recommendation systems. 2) Existing reverse processes are mainly designed for continuous data, whereas behavioral information is discrete in nature. Therefore, an effective method is needed for the generation of discrete behavioral information. To tackle the aforementioned issues, we propose a Light Diffusion model for Multimedia Recommendation. First, to reduce computational complexity, we simplify the formula of the reverse process, enabling one-step inference instead of multi-step inference. Second, to achieve effective behavioral information generation, we propose a novel Conditional neural Network. It maps the discrete behavior data into a continuous latent space, and generates behaviors with the guidance of collaborative signals and user multimodal preference. Additionally, considering that completely clean behavior data is inaccessible, we introduce a soft behavioral reconstruction constraint during model training, facilitating behavior prediction with noisy data. Empirical studies conducted on three public datasets demonstrate the effectiveness of LD4MRec.
Multi-View Graph Convolutional Network for Multimedia Recommendation
Aug 07, 2023Multimedia recommendation has received much attention in recent years. It models user preferences based on both behavior information and item multimodal information. Though current GCN-based methods achieve notable success, they suffer from two limitations: (1) Modality noise contamination to the item representations. Existing methods often mix modality features and behavior features in a single view (e.g., user-item view) for propagation, the noise in the modality features may be amplified and coupled with behavior features. In the end, it leads to poor feature discriminability; (2) Incomplete user preference modeling caused by equal treatment of modality features. Users often exhibit distinct modality preferences when purchasing different items. Equally fusing each modality feature ignores the relative importance among different modalities, leading to the suboptimal user preference modeling. To tackle the above issues, we propose a novel Multi-View Graph Convolutional Network for the multimedia recommendation. Specifically, to avoid modality noise contamination, the modality features are first purified with the aid of item behavior information. Then, the purified modality features of items and behavior features are enriched in separate views, including the user-item view and the item-item view. In this way, the distinguishability of features is enhanced. Meanwhile, a behavior-aware fuser is designed to comprehensively model user preferences by adaptively learning the relative importance of different modality features. Furthermore, we equip the fuser with a self-supervised auxiliary task. This task is expected to maximize the mutual information between the fused multimodal features and behavior features, so as to capture complementary and supplementary preference information simultaneously. Extensive experiments on three public datasets demonstrate the effectiveness of our methods.
Prior Information based Decomposition and Reconstruction Learning for Micro-Expression Recognition
Mar 03, 2023


Micro-expression recognition (MER) draws intensive research interest as micro-expressions (MEs) can infer genuine emotions. Prior information can guide the model to learn discriminative ME features effectively. However, most works focus on researching the general models with a stronger representation ability to adaptively aggregate ME movement information in a holistic way, which may ignore the prior information and properties of MEs. To solve this issue, driven by the prior information that the category of ME can be inferred by the relationship between the actions of facial different components, this work designs a novel model that can conform to this prior information and learn ME movement features in an interpretable way. Specifically, this paper proposes a Decomposition and Reconstruction-based Graph Representation Learning (DeRe-GRL) model to effectively learn high-level ME features. DeRe-GRL includes two modules: Action Decomposition Module (ADM) and Relation Reconstruction Module (RRM), where ADM learns action features of facial key components and RRM explores the relationship between these action features. Based on facial key components, ADM divides the geometric movement features extracted by the graph model-based backbone into several sub-features, and learns the map matrix to map these sub-features into multiple action features; then, RRM learns weights to weight all action features to build the relationship between action features. The experimental results demonstrate the effectiveness of the proposed modules, and the proposed method achieves competitive performance.
Geometric Graph Representation with Learnable Graph Structure and Adaptive AU Constraint for Micro-Expression Recognition
May 01, 2022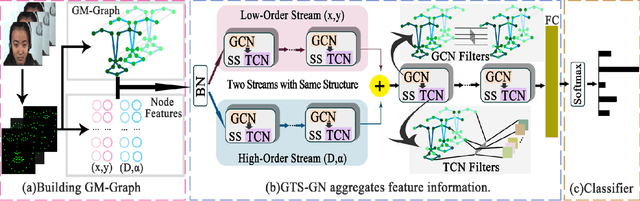
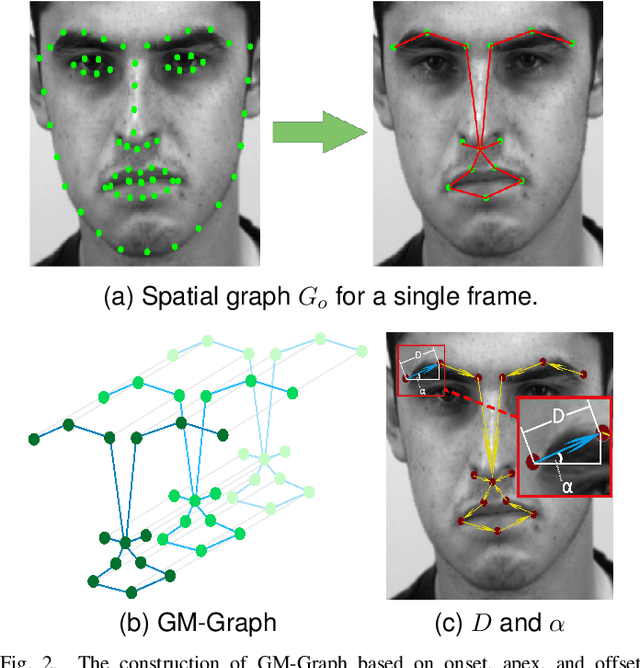
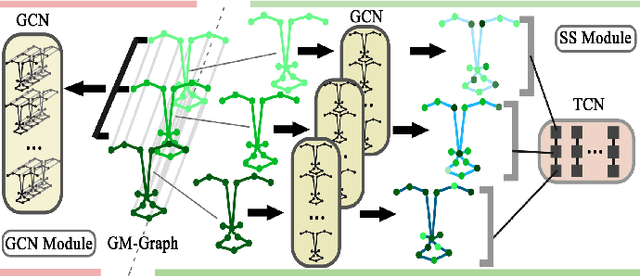
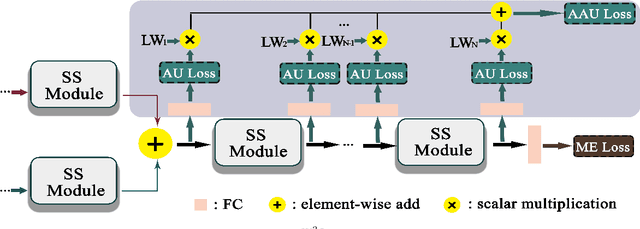
Micro-expression recognition (MER) is valuable because the involuntary nature of micro-expressions (MEs) can reveal genuine emotions. Most works recognize MEs by taking RGB videos or images as input. In fact, the activated facial regions in ME images are very small and the subtle motion can be easily submerged in the unrelated information. Facial landmarks are a low-dimensional and compact modality, which leads to much lower computational cost and can potentially concentrate more on ME-related features. However, the discriminability of landmarks for MER is not clear. Thus, this paper explores the contribution of facial landmarks and constructs a new framework to efficiently recognize MEs with sole facial landmark information. Specially, we design a separate structure module to separately aggregate the spatial and temporal information in the geometric movement graph based on facial landmarks, and a Geometric Two-Stream Graph Network is constructed to aggregate the low-order geometric information and high-order semantic information of facial landmarks. Furthermore, two core components are proposed to enhance features. Specifically, a semantic adjacency matrix can automatically model the relationship between nodes even long-distance nodes in a self-learning fashion; and an Adaptive Action Unit loss is introduced to guide the learning process such that the learned features are forced to have a synchronized pattern with facial action units. Notably, this work tackles MER only utilizing geometric features, processed based on a graph model, which provides a new idea with much higher efficiency to promote MER. The experimental results demonstrate that the proposed method can achieve competitive or even superior performance with a significantly reduced computational cost, and facial landmarks can significantly contribute to MER and are worth further study for efficient ME analysis.
A comparative study on movement feature in different directions for micro-expression recognition
Feb 16, 2021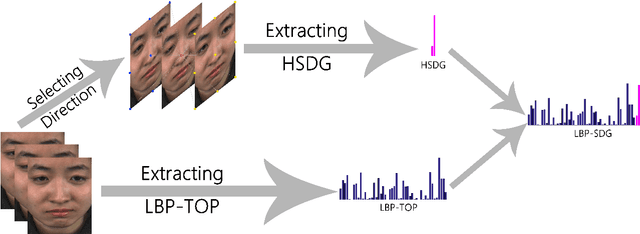
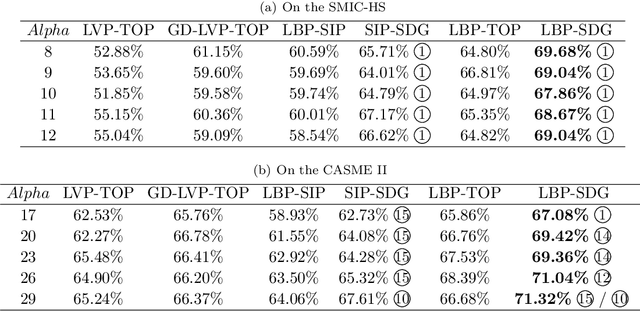
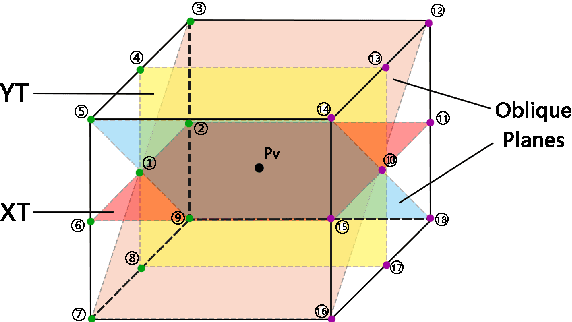
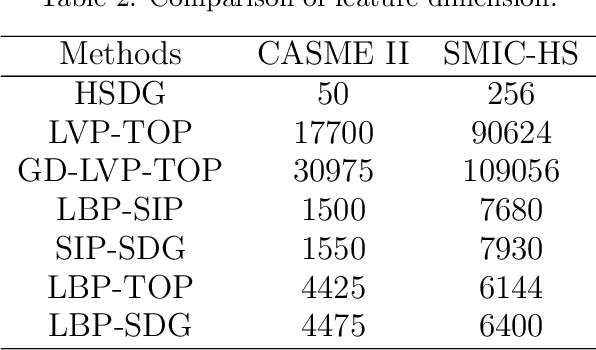
Micro-expression can reflect people's real emotions. Recognizing micro-expressions is difficult because they are small motions and have a short duration. As the research is deepening into micro-expression recognition, many effective features and methods have been proposed. To determine which direction of movement feature is easier for distinguishing micro-expressions, this paper selects 18 directions (including three types of horizontal, vertical and oblique movements) and proposes a new low-dimensional feature called the Histogram of Single Direction Gradient (HSDG) to study this topic. In this paper, HSDG in every direction is concatenated with LBP-TOP to obtain the LBP with Single Direction Gradient (LBP-SDG) and analyze which direction of movement feature is more discriminative for micro-expression recognition. As with some existing work, Euler Video Magnification (EVM) is employed as a preprocessing step. The experiments on the CASME II and SMIC-HS databases summarize the effective and optimal directions and demonstrate that HSDG in an optimal direction is discriminative, and the corresponding LBP-SDG achieves state-of-the-art performance using EVM.