 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntailment Graph Learning with Textual Entailment and Soft Transitivity
Apr 07, 2022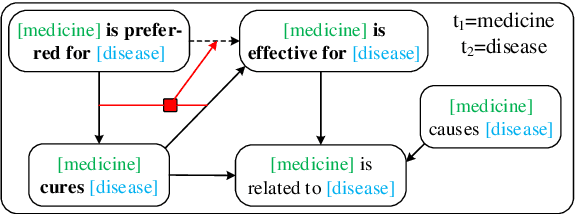
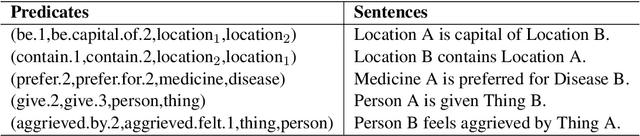
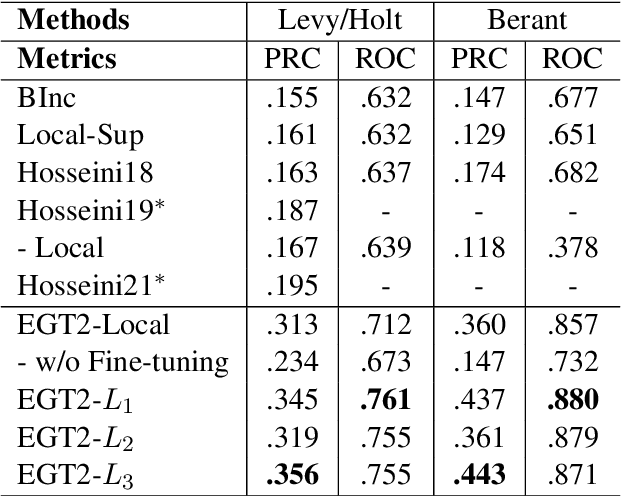
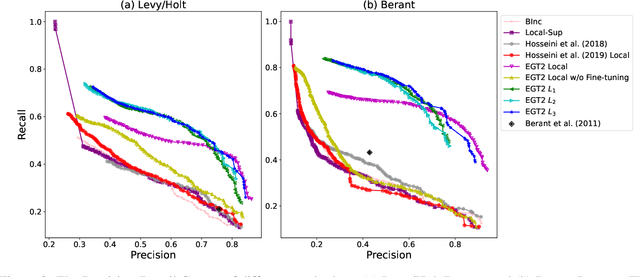
Typed entailment graphs try to learn the entailment relations between predicates from text and model them as edges between predicate nodes. The construction of entailment graphs usually suffers from severe sparsity and unreliability of distributional similarity. We propose a two-stage method, Entailment Graph with Textual Entailment and Transitivity (EGT2). EGT2 learns local entailment relations by recognizing possible textual entailment between template sentences formed by typed CCG-parsed predicates. Based on the generated local graph, EGT2 then uses three novel soft transitivity constraints to consider the logical transitivity in entailment structures. Experiments on benchmark datasets show that EGT2 can well model the transitivity in entailment graph to alleviate the sparsity issue, and lead to significant improvement over current state-of-the-art methods.
Things not Written in Text: Exploring Spatial Commonsense from Visual Signals
Mar 15, 2022
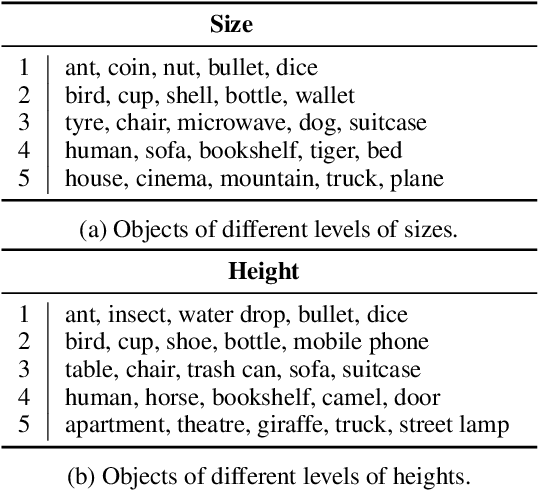
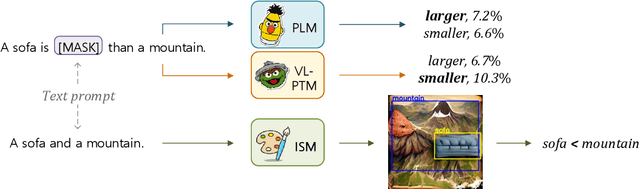

Spatial commonsense, the knowledge about spatial position and relationship between objects (like the relative size of a lion and a girl, and the position of a boy relative to a bicycle when cycling), is an important part of commonsense knowledge. Although pretrained language models (PLMs) succeed in many NLP tasks, they are shown to be ineffective in spatial commonsense reasoning. Starting from the observation that images are more likely to exhibit spatial commonsense than texts, we explore whether models with visual signals learn more spatial commonsense than text-based PLMs. We propose a spatial commonsense benchmark that focuses on the relative scales of objects, and the positional relationship between people and objects under different actions. We probe PLMs and models with visual signals, including vision-language pretrained models and image synthesis models, on this benchmark, and find that image synthesis models are more capable of learning accurate and consistent spatial knowledge than other models. The spatial knowledge from image synthesis models also helps in natural language understanding tasks that require spatial commonsense.
Extract, Integrate, Compete: Towards Verification Style Reading Comprehension
Sep 11, 2021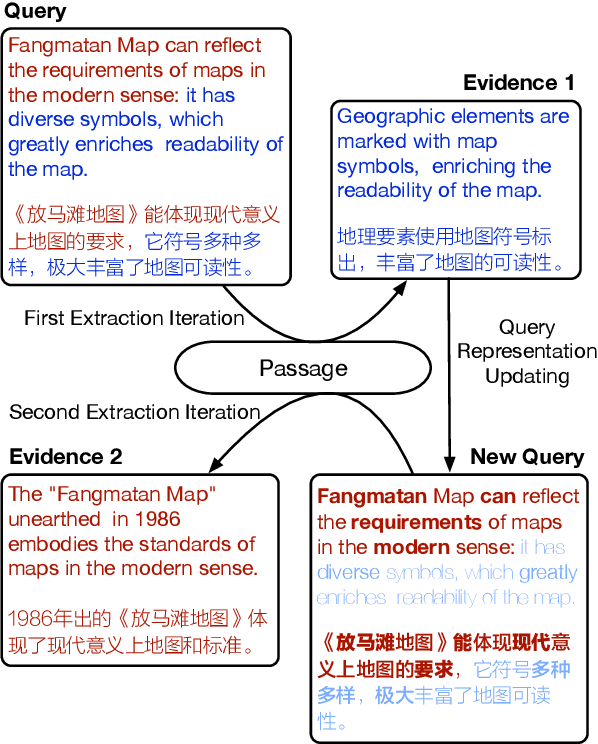

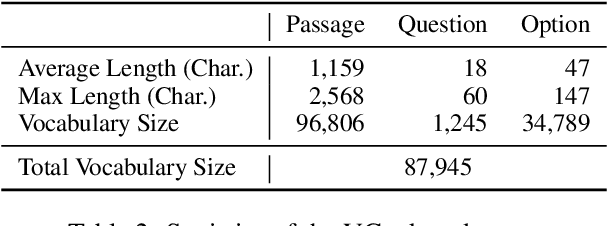
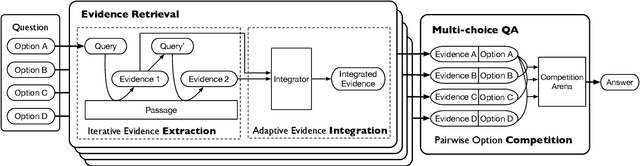
In this paper, we present a new verification style reading comprehension dataset named VGaokao from Chinese Language tests of Gaokao. Different from existing efforts, the new dataset is originally designed for native speakers' evaluation, thus requiring more advanced language understanding skills. To address the challenges in VGaokao, we propose a novel Extract-Integrate-Compete approach, which iteratively selects complementary evidence with a novel query updating mechanism and adaptively distills supportive evidence, followed by a pairwise competition to push models to learn the subtle difference among similar text pieces. Experiments show that our methods outperform various baselines on VGaokao with retrieved complementary evidence, while having the merits of efficiency and explainability. Our dataset and code are released for further research.
Exploring Distantly-Labeled Rationales in Neural Network Models
Jun 03, 2021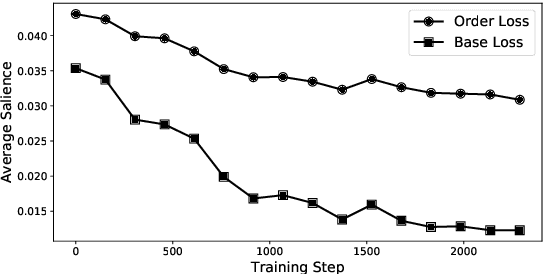
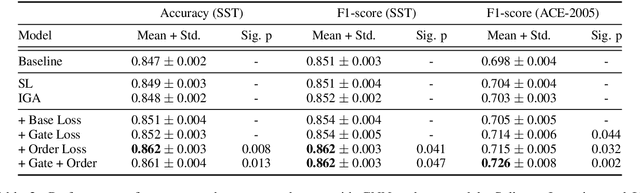
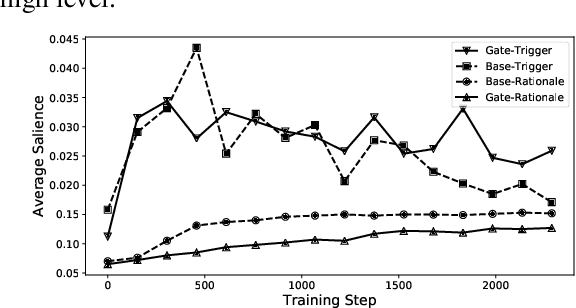
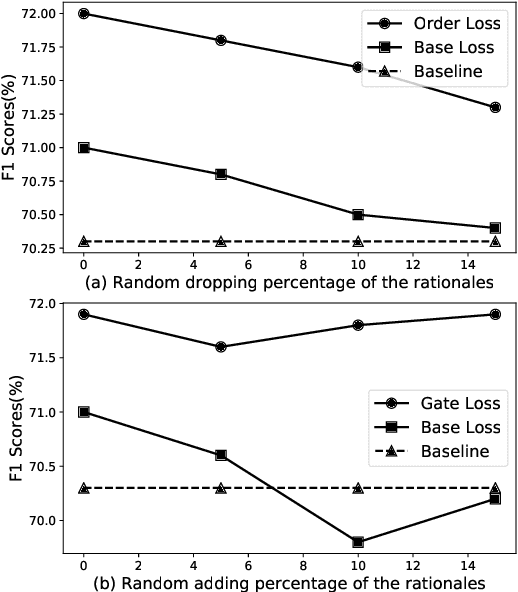
Recent studies strive to incorporate various human rationales into neural networks to improve model performance, but few pay attention to the quality of the rationales. Most existing methods distribute their models' focus to distantly-labeled rationale words entirely and equally, while ignoring the potential important non-rationale words and not distinguishing the importance of different rationale words. In this paper, we propose two novel auxiliary loss functions to make better use of distantly-labeled rationales, which encourage models to maintain their focus on important words beyond labeled rationales (PINs) and alleviate redundant training on non-helpful rationales (NoIRs). Experiments on two representative classification tasks show that our proposed methods can push a classification model to effectively learn crucial clues from non-perfect rationales while maintaining the ability to spread its focus to other unlabeled important words, thus significantly outperform existing methods.
Three Sentences Are All You Need: Local Path Enhanced Document Relation Extraction
Jun 03, 2021
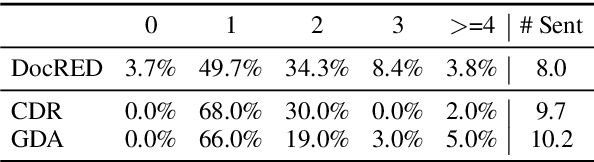
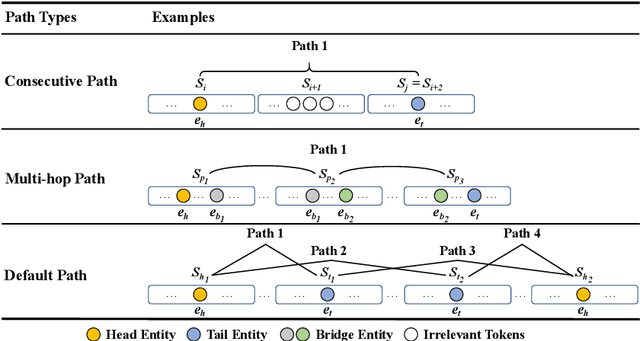
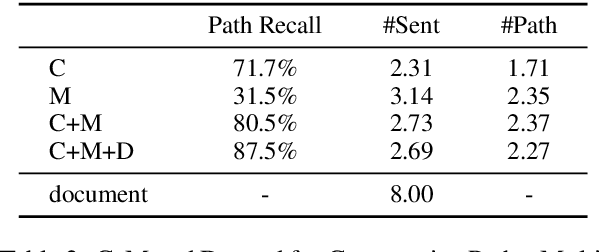
Document-level Relation Extraction (RE) is a more challenging task than sentence RE as it often requires reasoning over multiple sentences. Yet, human annotators usually use a small number of sentences to identify the relationship between a given entity pair. In this paper, we present an embarrassingly simple but effective method to heuristically select evidence sentences for document-level RE, which can be easily combined with BiLSTM to achieve good performance on benchmark datasets, even better than fancy graph neural network based methods. We have released our code at https://github.com/AndrewZhe/Three-Sentences-Are-All-You-Need.
Why Machine Reading Comprehension Models Learn Shortcuts?
Jun 02, 2021
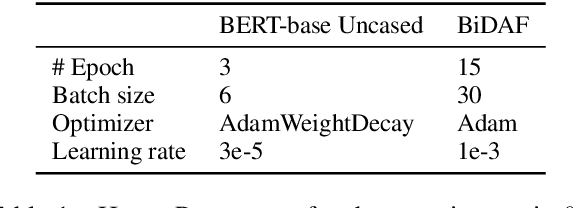
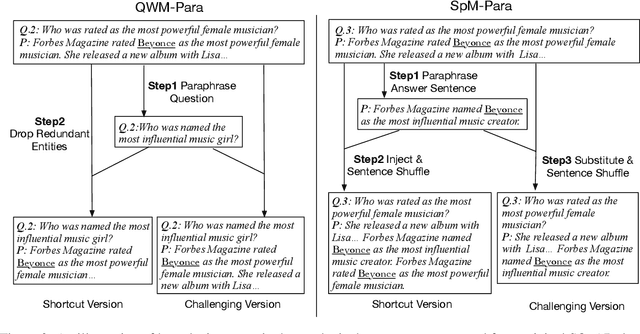

Recent studies report that many machine reading comprehension (MRC) models can perform closely to or even better than humans on benchmark datasets. However, existing works indicate that many MRC models may learn shortcuts to outwit these benchmarks, but the performance is unsatisfactory in real-world applications. In this work, we attempt to explore, instead of the expected comprehension skills, why these models learn the shortcuts. Based on the observation that a large portion of questions in current datasets have shortcut solutions, we argue that larger proportion of shortcut questions in training data make models rely on shortcut tricks excessively. To investigate this hypothesis, we carefully design two synthetic datasets with annotations that indicate whether a question can be answered using shortcut solutions. We further propose two new methods to quantitatively analyze the learning difficulty regarding shortcut and challenging questions, and revealing the inherent learning mechanism behind the different performance between the two kinds of questions. A thorough empirical analysis shows that MRC models tend to learn shortcut questions earlier than challenging questions, and the high proportions of shortcut questions in training sets hinder models from exploring the sophisticated reasoning skills in the later stage of training.
Everything Has a Cause: Leveraging Causal Inference in Legal Text Analysis
Apr 21, 2021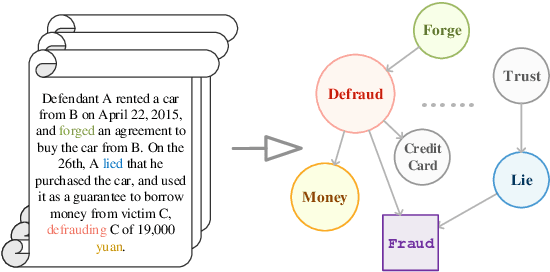

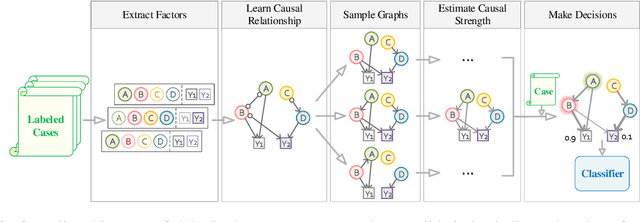
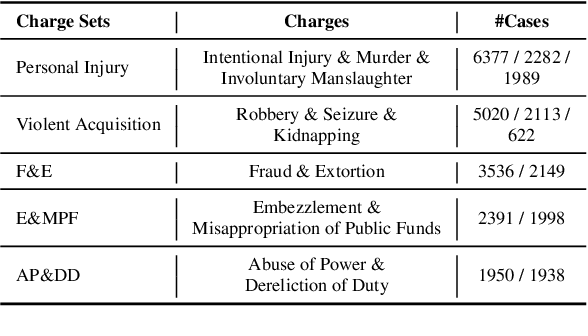
Causal inference is the process of capturing cause-effect relationship among variables. Most existing works focus on dealing with structured data, while mining causal relationship among factors from unstructured data, like text, has been less examined, but is of great importance, especially in the legal domain. In this paper, we propose a novel Graph-based Causal Inference (GCI) framework, which builds causal graphs from fact descriptions without much human involvement and enables causal inference to facilitate legal practitioners to make proper decisions. We evaluate the framework on a challenging similar charge disambiguation task. Experimental results show that GCI can capture the nuance from fact descriptions among multiple confusing charges and provide explainable discrimination, especially in few-shot settings. We also observe that the causal knowledge contained in GCI can be effectively injected into powerful neural networks for better performance and interpretability.
Lattice-BERT: Leveraging Multi-Granularity Representations in Chinese Pre-trained Language Models
Apr 15, 2021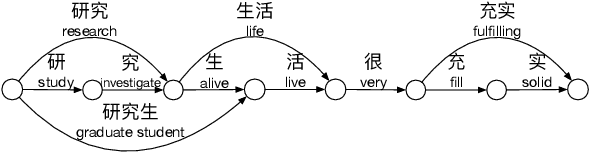
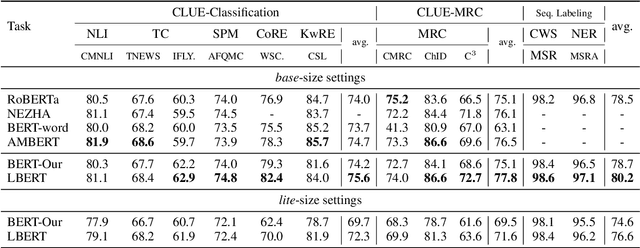
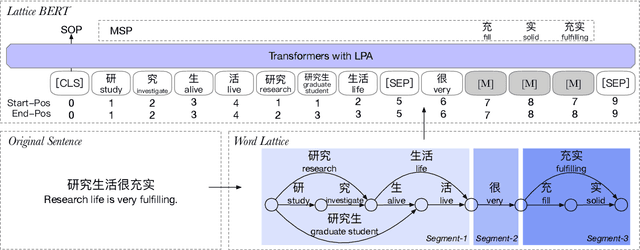
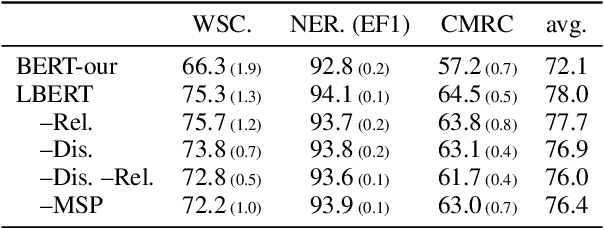
Chinese pre-trained language models usually process text as a sequence of characters, while ignoring more coarse granularity, e.g., words. In this work, we propose a novel pre-training paradigm for Chinese -- Lattice-BERT, which explicitly incorporates word representations along with characters, thus can model a sentence in a multi-granularity manner. Specifically, we construct a lattice graph from the characters and words in a sentence and feed all these text units into transformers. We design a lattice position attention mechanism to exploit the lattice structures in self-attention layers. We further propose a masked segment prediction task to push the model to learn from rich but redundant information inherent in lattices, while avoiding learning unexpected tricks. Experiments on 11 Chinese natural language understanding tasks show that our model can bring an average increase of 1.5% under the 12-layer setting, which achieves new state-of-the-art among base-size models on the CLUE benchmarks. Further analysis shows that Lattice-BERT can harness the lattice structures, and the improvement comes from the exploration of redundant information and multi-granularity representations. Our code will be available at https://github.com/alibaba/pretrained-language-models/LatticeBERT.
Latent Template Induction with Gumbel-CRFs
Nov 29, 2020
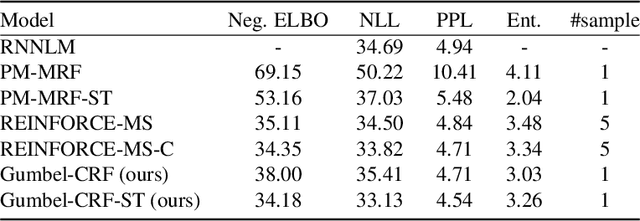
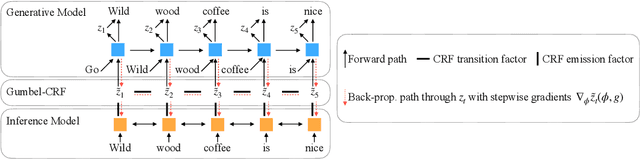
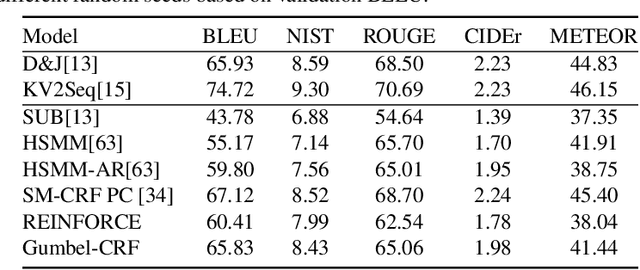
Learning to control the structure of sentences is a challenging problem in text generation. Existing work either relies on simple deterministic approaches or RL-based hard structures. We explore the use of structured variational autoencoders to infer latent templates for sentence generation using a soft, continuous relaxation in order to utilize reparameterization for training. Specifically, we propose a Gumbel-CRF, a continuous relaxation of the CRF sampling algorithm using a relaxed Forward-Filtering Backward-Sampling (FFBS) approach. As a reparameterized gradient estimator, the Gumbel-CRF gives more stable gradients than score-function based estimators. As a structured inference network, we show that it learns interpretable templates during training, which allows us to control the decoder during testing. We demonstrate the effectiveness of our methods with experiments on data-to-text generation and unsupervised paraphrase generation.
Exploring Question-Specific Rewards for Generating Deep Questions
Nov 02, 2020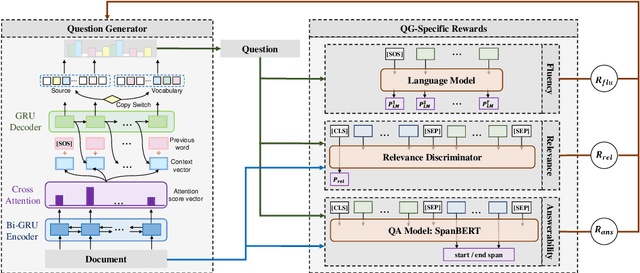
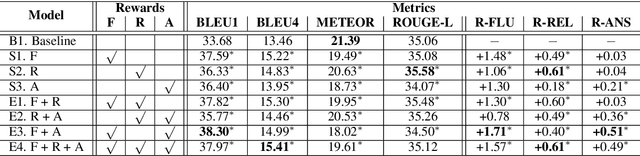
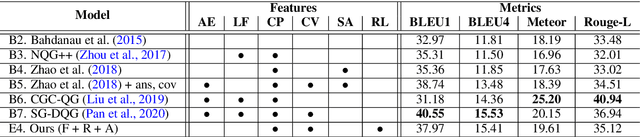
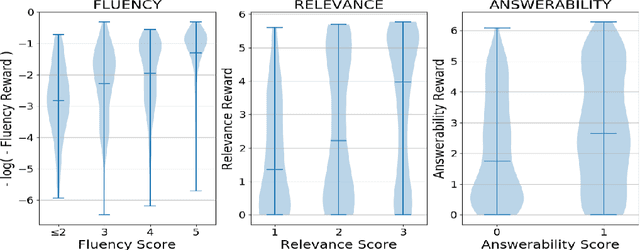
Recent question generation (QG) approaches often utilize the sequence-to-sequence framework (Seq2Seq) to optimize the log-likelihood of ground-truth questions using teacher forcing. However, this training objective is inconsistent with actual question quality, which is often reflected by certain global properties such as whether the question can be answered by the document. As such, we directly optimize for QG-specific objectives via reinforcement learning to improve question quality. We design three different rewards that target to improve the fluency, relevance, and answerability of generated questions. We conduct both automatic and human evaluations in addition to a thorough analysis to explore the effect of each QG-specific reward. We find that optimizing question-specific rewards generally leads to better performance in automatic evaluation metrics. However, only the rewards that correlate well with human judgement (e.g., relevance) lead to real improvement in question quality. Optimizing for the others, especially answerability, introduces incorrect bias to the model, resulting in poor question quality. Our code is publicly available at https://github.com/YuxiXie/RL-for-Question-Generation.