 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More: Learning Highlight Detection from Video Duration
Mar 03, 2019
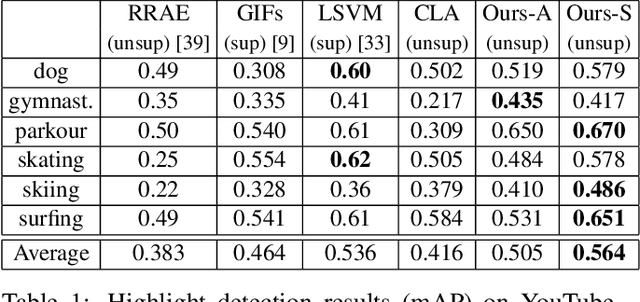
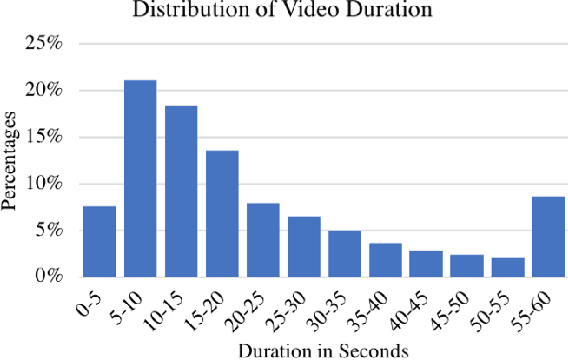
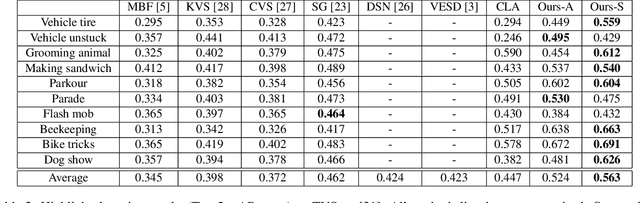
Highlight detection has the potential to significantly ease video browsing, but existing methods often suffer from expensive supervision requirements, where human viewers must manually identify highlights in training videos. We propose a scalable unsupervised solution that exploits video duration as an implicit supervision signal. Our key insight is that video segments from shorter user-generated videos are more likely to be highlights than those from longer videos, since users tend to be more selective about the content when capturing shorter videos. Leveraging this insight, we introduce a novel ranking framework that prefers segments from shorter videos, while properly accounting for the inherent noise in the (unlabeled) training data. We use it to train a highlight detector with 10M hashtagged Instagram videos. In experiments on two challenging public video highlight detection benchmarks, our method substantially improves the state-of-the-art for unsupervised highlight detection.
DMC-Net: Generating Discriminative Motion Cues for Fast Compressed Video Action Recognition
Jan 11, 2019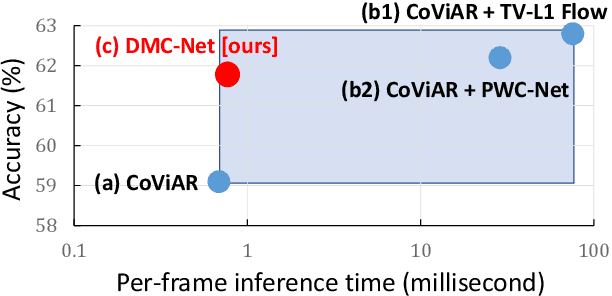

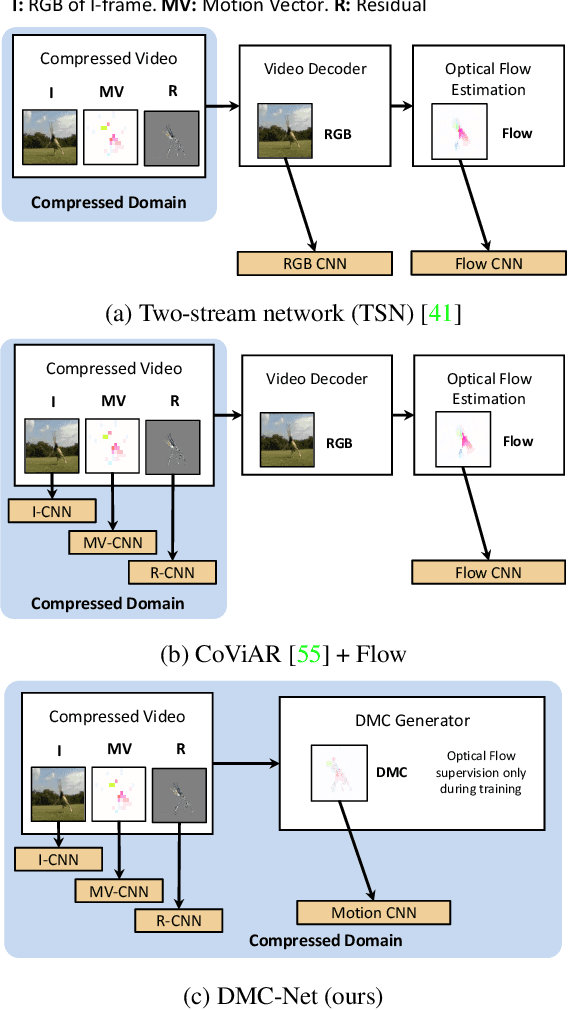
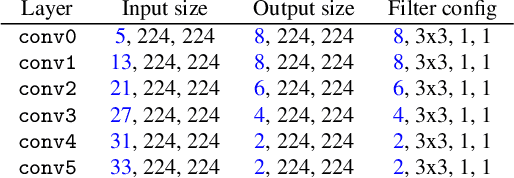
Motion has shown to be useful for video understanding, where motion is typically represented by optical flow. However, computing flow from video frames is very time-consuming. Recent works directly leverage the motion vectors and residuals readily available in the compressed video to represent motion at no cost. While this avoids flow computation, it also hurts accuracy since the motion vector is noisy and has substantially reduced resolution, which makes it a less discriminative motion representation. To remedy these issues, we propose a lightweight generator network, which reduces noises in motion vectors and captures fine motion details, achieving a more Discriminative Motion Cue (DMC) representation. Since optical flow is a more accurate motion representation, we train the DMC generator to approximate flow using a reconstruction loss and a generative adversarial loss, jointly with the downstream action classification task. Extensive evaluations on three action recognition benchmarks (HMDB-51, UCF-101, and a subset of Kinetics) confirm the effectiveness of our method. Our full system, consisting of the generator and the classifier, is coined as DMC-Net which obtains high accuracy close to that of using flow and runs two orders of magnitude faster than using optical flow at inference time.
Grounded Video Description
Dec 17, 2018



Video description is one of the most challenging problems in vision and language understanding due to the large variability both on the video and language side. Models, hence, typically shortcut the difficulty in recognition and generate plausible sentences that are based on priors but are not necessarily grounded in the video. In this work, we explicitly link the sentence to the evidence in the video by annotating each noun phrase in a sentence with the corresponding bounding box in one of the frames of a video. Our novel dataset, ActivityNet-Entities, is based on the challenging ActivityNet Captions dataset and augments it with 158k bounding box annotations, each grounding a noun phrase. This allows training video description models with this data, and importantly, evaluate how grounded or "true" such model are to the video they describe. To generate grounded captions, we propose a novel video description model which is able to exploit these bounding box annotations. We demonstrate the effectiveness of our model on our ActivityNet-Entities, but also show how it can be applied to image description on the Flickr30k Entities dataset. We achieve state-of-the-art performance on video description, video paragraph description, and image description and demonstrate our generated sentences are better grounded in the video.
Graph-Based Global Reasoning Networks
Nov 30, 2018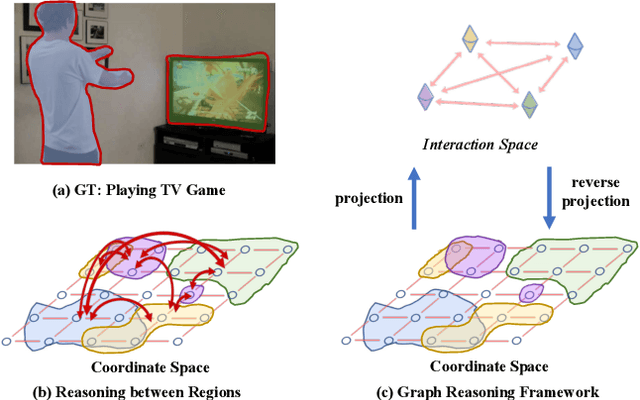
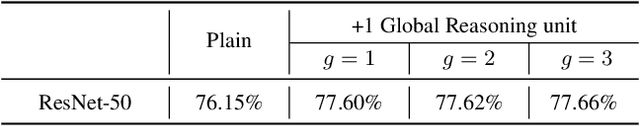
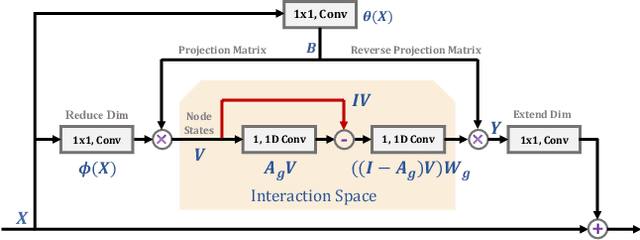
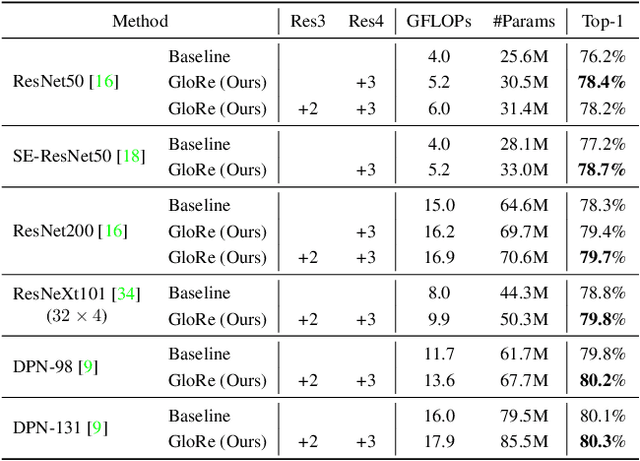
Globally modeling and reasoning over relations between regions can be beneficial for many computer vision tasks on both images and videos. Convolutional Neural Networks (CNNs) excel at modeling local relations by convolution operations, but they are typically inefficient at capturing global relations between distant regions and require stacking multiple convolution layers. In this work, we propose a new approach for reasoning globally in which a set of features are globally aggregated over the coordinate space and then projected to an interaction space where relational reasoning can be efficiently computed. After reasoning, relation-aware features are distributed back to the original coordinate space for down-stream tasks. We further present a highly efficient instantiation of the proposed approach and introduce the Global Reasoning unit (GloRe unit) that implements the coordinate-interaction space mapping by weighted global pooling and weighted broadcasting, and the relation reasoning via graph convolution on a small graph in interaction space. The proposed GloRe unit is lightweight, end-to-end trainable and can be easily plugged into existing CNNs for a wide range of tasks. Extensive experiments show our GloRe unit can consistently boost the performance of state-of-the-art backbone architectures, including ResNet, ResNeXt, SE-Net and DPN, for both 2D and 3D CNNs, on image classification, semantic segmentation and video action recognition task.
$A^2$-Nets: Double Attention Networks
Oct 27, 2018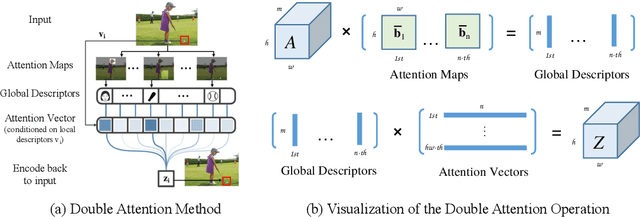
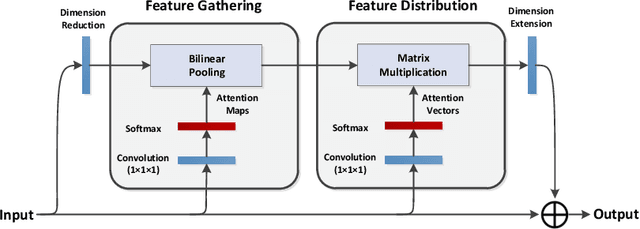
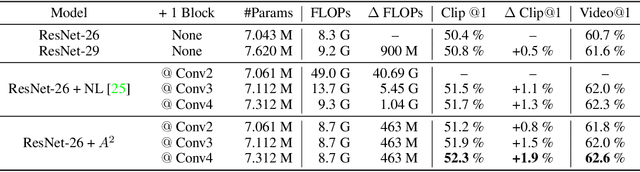
Learning to capture long-range relations is fundamental to image/video recognition. Existing CNN models generally rely on increasing depth to model such relations which is highly inefficient. In this work, we propose the "double attention block", a novel component that aggregates and propagates informative global features from the entire spatio-temporal space of input images/videos, enabling subsequent convolution layers to access features from the entire space efficiently. The component is designed with a double attention mechanism in two steps, where the first step gathers features from the entire space into a compact set through second-order attention pooling and the second step adaptively selects and distributes features to each location via another attention. The proposed double attention block is easy to adopt and can be plugged into existing deep neural networks conveniently. We conduct extensive ablation studies and experiments on both image and video recognition tasks for evaluating its performance. On the image recognition task, a ResNet-50 equipped with our double attention blocks outperforms a much larger ResNet-152 architecture on ImageNet-1k dataset with over 40% less the number of parameters and less FLOPs. On the action recognition task, our proposed model achieves the state-of-the-art results on the Kinetics and UCF-101 datasets with significantly higher efficiency than recent works.
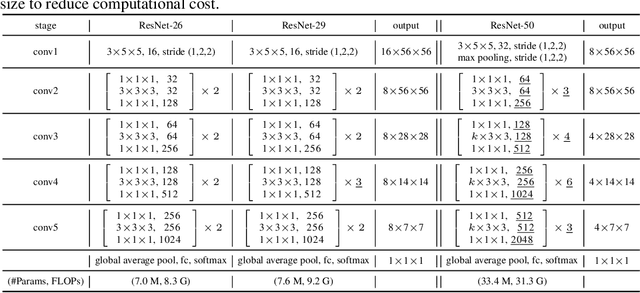
Multi-Fiber Networks for Video Recognition
Sep 18, 2018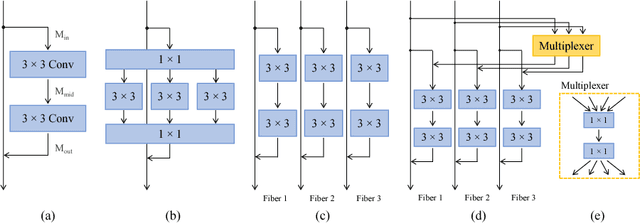
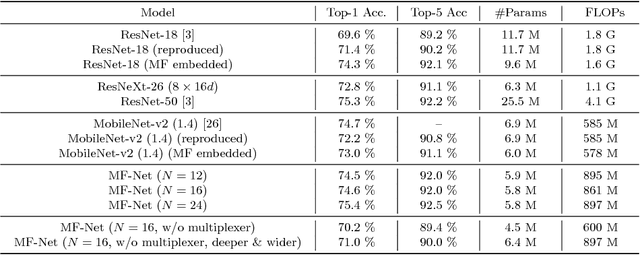
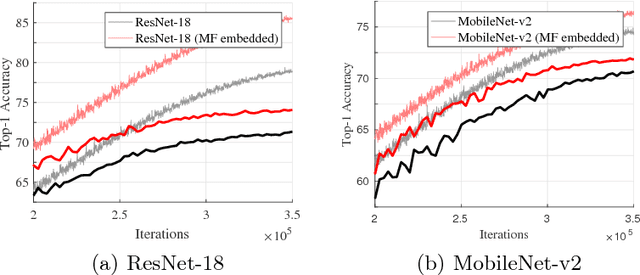
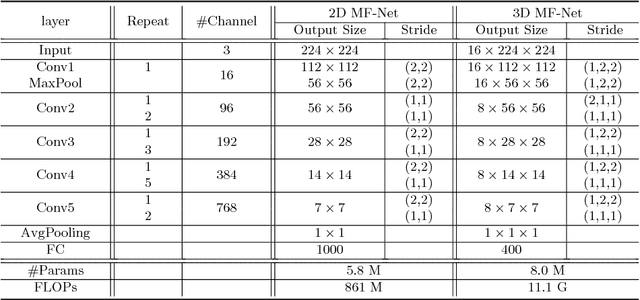
In this paper, we aim to reduce the computational cost of spatio-temporal deep neural networks, making them run as fast as their 2D counterparts while preserving state-of-the-art accuracy on video recognition benchmarks. To this end, we present the novel Multi-Fiber architecture that slices a complex neural network into an ensemble of lightweight networks or fibers that run through the network. To facilitate information flow between fibers we further incorporate multiplexer modules and end up with an architecture that reduces the computational cost of 3D networks by an order of magnitude, while increasing recognition performance at the same time. Extensive experimental results show that our multi-fiber architecture significantly boosts the efficiency of existing convolution networks for both image and video recognition tasks, achieving state-of-the-art performance on UCF-101, HMDB-51 and Kinetics datasets. Our proposed model requires over 9x and 13x less computations than the I3D and R(2+1)D models, respectively, yet providing higher accuracy.
Large-Scale Visual Relationship Understanding
Sep 14, 2018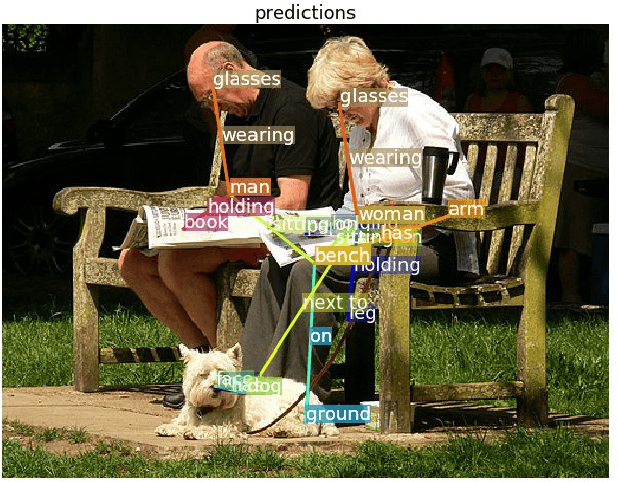
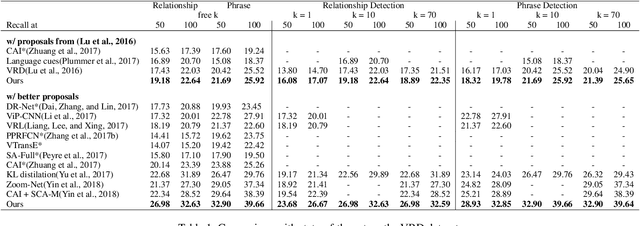
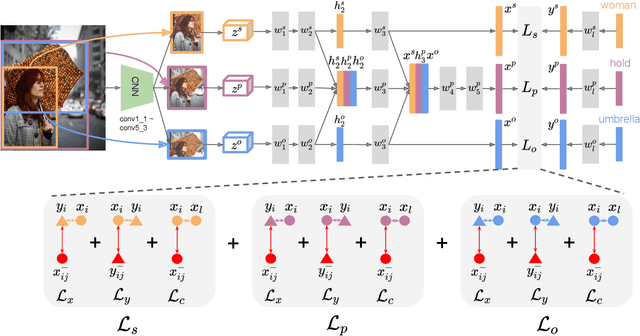
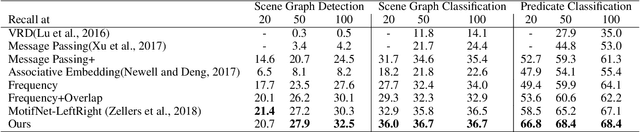
Large scale visual understanding is challenging, as it requires a model to handle the widely-spread and imbalanced distribution of <subject, relation, object> triples. In real-world scenarios with large numbers of objects and relations, some are seen very commonly while others are barely seen. We develop a new relationship detection model that embeds objects and relations into two vector spaces where both discriminative capability and semantic affinity are preserved. We learn both a visual and a semantic module that map features from the two modalities into a shared space, where matched pairs of features have to discriminate against those unmatched, but also maintain close distances to semantically similar ones. Benefiting from that, our model can achieve superior performance even when the visual entity categories scale up to more than 80,000, with extremely skewed class distribution. We demonstrate the efficacy of our model on a large and imbalanced benchmark based of Visual Genome that comprises 53,000+ objects and 29,000+ relations, a scale at which no previous work has ever been evaluated at. We show superiority of our model over carefully designed baselines on the original Visual Genome dataset with 80,000+ categories. We also show state-of-the-art performance on the VRD dataset and the scene graph dataset which is a subset of Visual Genome with 200 categories.
Tag Prediction at Flickr: a View from the Darkroom
Dec 19, 2017
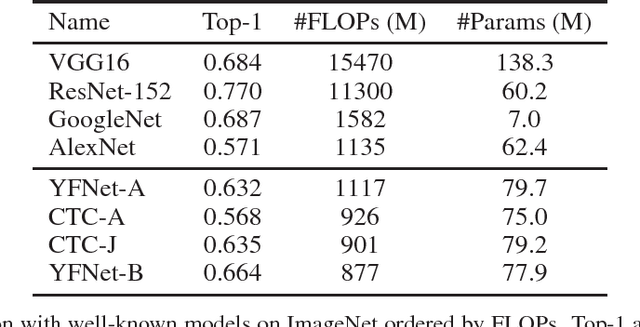

Automated photo tagging has established itself as one of the most compelling applications of deep learning. While deep convolutional neural networks have repeatedly demonstrated top performance on standard datasets for classification, there are a number of often overlooked but important considerations when deploying this technology in a real-world scenario. In this paper, we present our efforts in developing a large-scale photo tagging system for Flickr photo search. We discuss topics including how to 1) select the tags that matter most to our users; 2) develop lightweight, high-performance models for tag prediction; and 3) leverage the power of large amounts of noisy data for training. Our results demonstrate that, for real-world datasets, training exclusively with this noisy data yields performance on par with the standard paradigm of first pre-training on clean data and then fine-tuning. In addition, we observe that the models trained with user-generated data can yield better fine-tuning results when a small amount of clean data is available. As such, we advocate for the approach of harnessing user-generated data in large-scale systems.
MemexQA: Visual Memex Question Answering
Aug 04, 2017


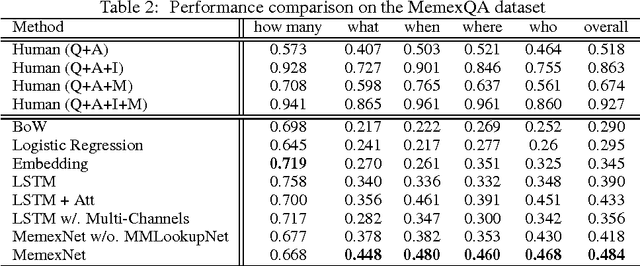
This paper proposes a new task, MemexQA: given a collection of photos or videos from a user, the goal is to automatically answer questions that help users recover their memory about events captured in the collection. Towards solving the task, we 1) present the MemexQA dataset, a large, realistic multimodal dataset consisting of real personal photos and crowd-sourced questions/answers, 2) propose MemexNet, a unified, end-to-end trainable network architecture for image, text and video question answering. Experimental results on the MemexQA dataset demonstrate that MemexNet outperforms strong baselines and yields the state-of-the-art on this novel and challenging task. The promising results on TextQA and VideoQA suggest MemexNet's efficacy and scalability across various QA tasks.
LOH and behold: Web-scale visual search, recommendation and clustering using Locally Optimized Hashing
Jul 30, 2016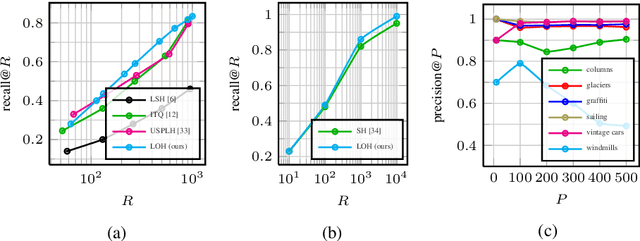



We propose a novel hashing-based matching scheme, called Locally Optimized Hashing (LOH), based on a state-of-the-art quantization algorithm that can be used for efficient, large-scale search, recommendation, clustering, and deduplication. We show that matching with LOH only requires set intersections and summations to compute and so is easily implemented in generic distributed computing systems. We further show application of LOH to: a) large-scale search tasks where performance is on par with other state-of-the-art hashing approaches; b) large-scale recommendation where queries consisting of thousands of images can be used to generate accurate recommendations from collections of hundreds of millions of images; and c) efficient clustering with a graph-based algorithm that can be scaled to massive collections in a distributed environment or can be used for deduplication for small collections, like search results, performing better than traditional hashing approaches while only requiring a few milliseconds to run. In this paper we experiment on datasets of up to 100 million images, but in practice our system can scale to larger collections and can be used for other types of data that have a vector representation in a Euclidean space.