 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Super-Features for Image Retrieval
Jan 31, 2022
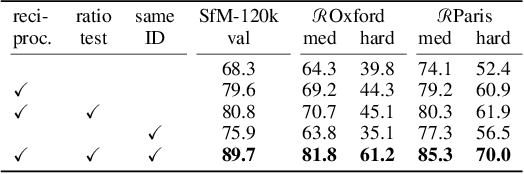
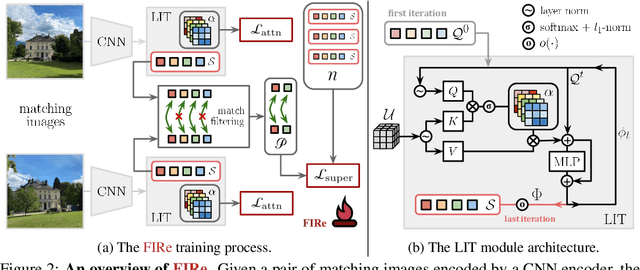
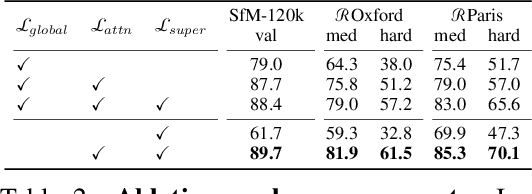
Methods that combine local and global features have recently shown excellent performance on multiple challenging deep image retrieval benchmarks, but their use of local features raises at least two issues. First, these local features simply boil down to the localized map activations of a neural network, and hence can be extremely redundant. Second, they are typically trained with a global loss that only acts on top of an aggregation of local features; by contrast, testing is based on local feature matching, which creates a discrepancy between training and testing. In this paper, we propose a novel architecture for deep image retrieval, based solely on mid-level features that we call Super-features. These Super-features are constructed by an iterative attention module and constitute an ordered set in which each element focuses on a localized and discriminant image pattern. For training, they require only image labels. A contrastive loss operates directly at the level of Super-features and focuses on those that match across images. A second complementary loss encourages diversity. Experiments on common landmark retrieval benchmarks validate that Super-features substantially outperform state-of-the-art methods when using the same number of features, and only require a significantly smaller memory footprint to match their performance. Code and models are available at: https://github.com/naver/FIRe.
TLDR: Twin Learning for Dimensionality Reduction
Oct 18, 2021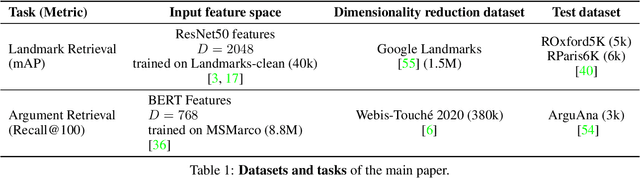
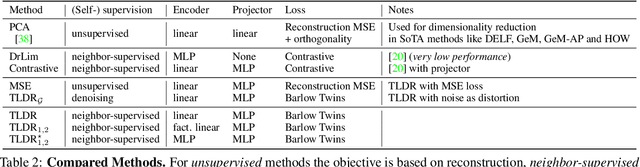
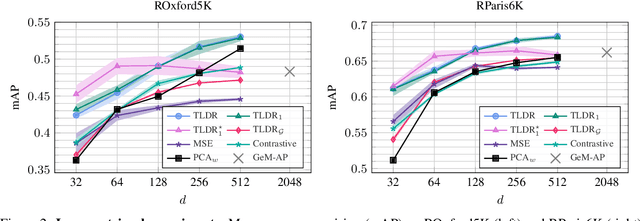
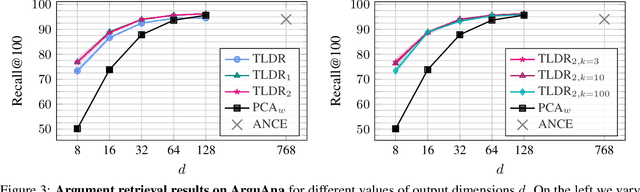
Dimensionality reduction methods are unsupervised approaches which learn low-dimensional spaces where some properties of the initial space, typically the notion of "neighborhood", are preserved. They are a crucial component of diverse tasks like visualization, compression, indexing, and retrieval. Aiming for a totally different goal, self-supervised visual representation learning has been shown to produce transferable representation functions by learning models that encode invariance to artificially created distortions, e.g. a set of hand-crafted image transformations. Unlike manifold learning methods that usually require propagation on large k-NN graphs or complicated optimization solvers, self-supervised learning approaches rely on simpler and more scalable frameworks for learning. In this paper, we unify these two families of approaches from the angle of manifold learning and propose TLDR, a dimensionality reduction method for generic input spaces that is porting the simple self-supervised learning framework of Barlow Twins to a setting where it is hard or impossible to define an appropriate set of distortions by hand. We propose to use nearest neighbors to build pairs from a training set and a redundancy reduction loss borrowed from the self-supervised literature to learn an encoder that produces representations invariant across such pairs. TLDR is a method that is simple, easy to implement and train, and of broad applicability; it consists of an offline nearest neighbor computation step that can be highly approximated, and a straightforward learning process that does not require mining negative samples to contrast, eigendecompositions, or cumbersome optimization solvers. By replacing PCA with TLDR, we are able to increase the performance of GeM-AP by 4% mAP for 128 dimensions, and to retain its performance with 16x fewer dimensions.
Leveraging MoCap Data for Human Mesh Recovery
Oct 18, 2021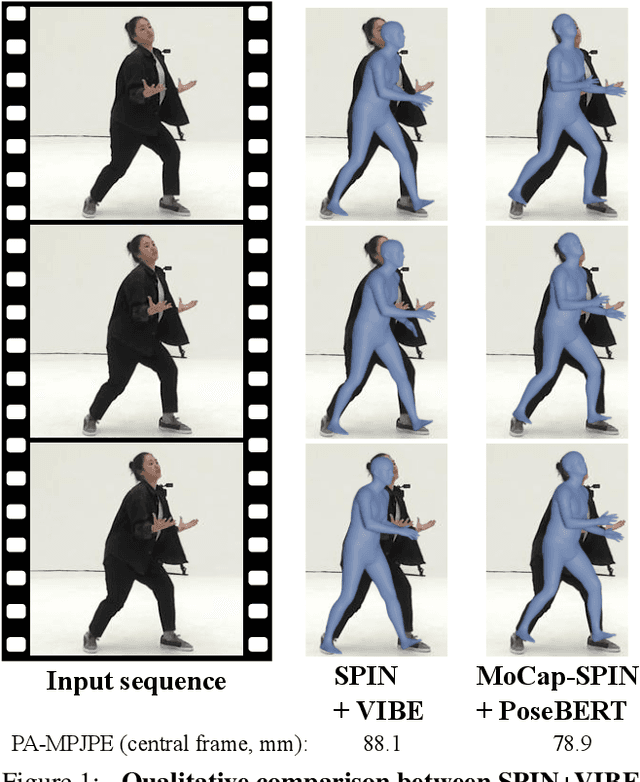
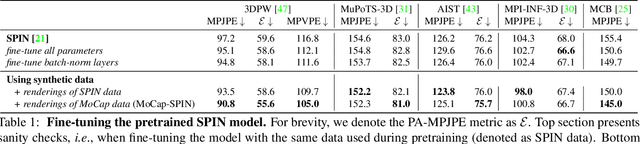


Training state-of-the-art models for human body pose and shape recovery from images or videos requires datasets with corresponding annotations that are really hard and expensive to obtain. Our goal in this paper is to study whether poses from 3D Motion Capture (MoCap) data can be used to improve image-based and video-based human mesh recovery methods. We find that fine-tune image-based models with synthetic renderings from MoCap data can increase their performance, by providing them with a wider variety of poses, textures and backgrounds. In fact, we show that simply fine-tuning the batch normalization layers of the model is enough to achieve large gains. We further study the use of MoCap data for video, and introduce PoseBERT, a transformer module that directly regresses the pose parameters and is trained via masked modeling. It is simple, generic and can be plugged on top of any state-of-the-art image-based model in order to transform it in a video-based model leveraging temporal information. Our experimental results show that the proposed approaches reach state-of-the-art performance on various datasets including 3DPW, MPI-INF-3DHP, MuPoTS-3D, MCB and AIST. Test code and models will be available soon.
Probabilistic Embeddings for Cross-Modal Retrieval
Jan 13, 2021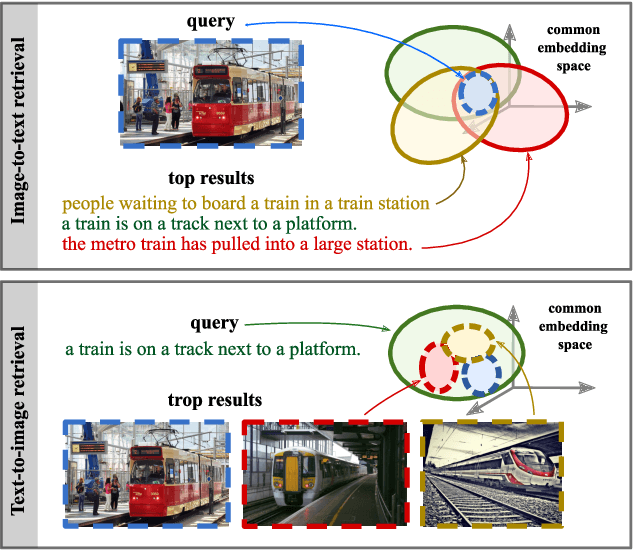
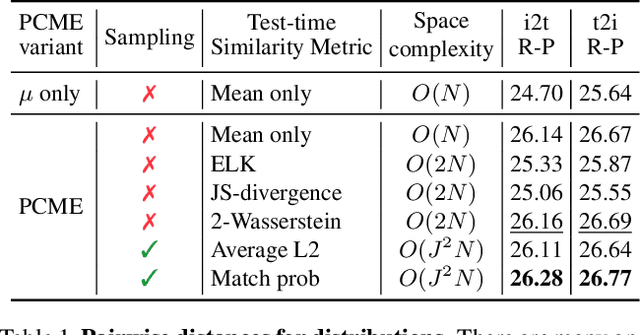
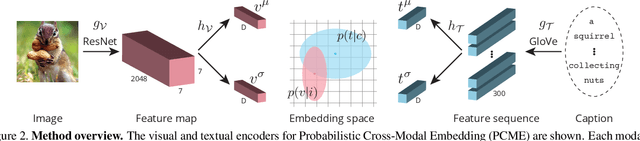
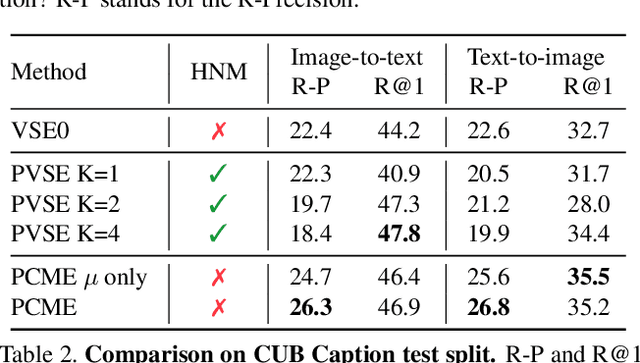
Cross-modal retrieval methods build a common representation space for samples from multiple modalities, typically from the vision and the language domains. For images and their captions, the multiplicity of the correspondences makes the task particularly challenging. Given an image (respectively a caption), there are multiple captions (respectively images) that equally make sense. In this paper, we argue that deterministic functions are not sufficiently powerful to capture such one-to-many correspondences. Instead, we propose to use Probabilistic Cross-Modal Embedding (PCME), where samples from the different modalities are represented as probabilistic distributions in the common embedding space. Since common benchmarks such as COCO suffer from non-exhaustive annotations for cross-modal matches, we propose to additionally evaluate retrieval on the CUB dataset, a smaller yet clean database where all possible image-caption pairs are annotated. We extensively ablate PCME and demonstrate that it not only improves the retrieval performance over its deterministic counterpart, but also provides uncertainty estimates that render the embeddings more interpretable.
Concept Generalization in Visual Representation Learning
Dec 10, 2020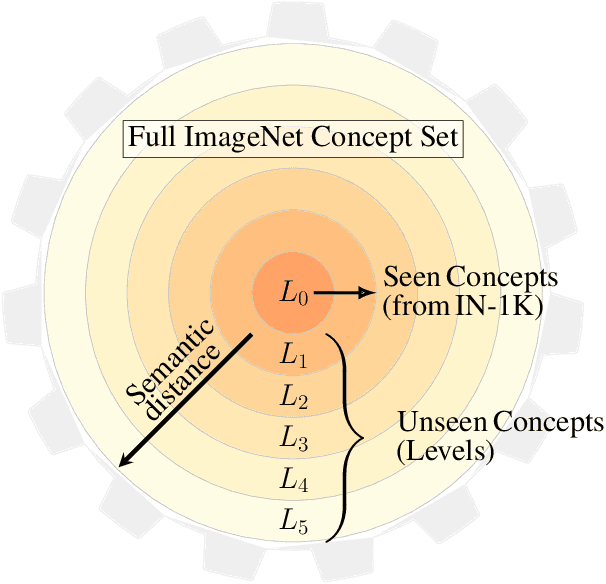
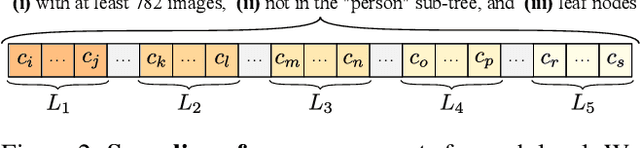
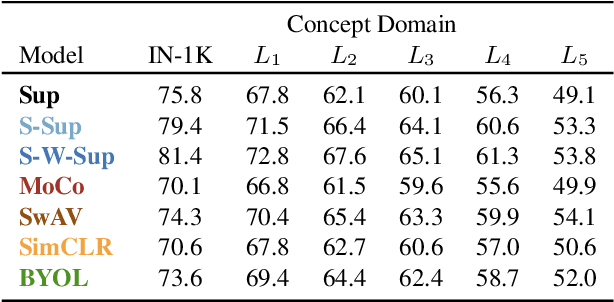
Measuring concept generalization, i.e., the extent to which models trained on a set of (seen) visual concepts can be used to recognize a new set of (unseen) concepts, is a popular way of evaluating visual representations, especially when they are learned with self-supervised learning. Nonetheless, the choice of which unseen concepts to use is usually made arbitrarily, and independently from the seen concepts used to train representations, thus ignoring any semantic relationships between the two. In this paper, we argue that semantic relationships between seen and unseen concepts affect generalization performance and propose ImageNet-CoG, a novel benchmark on the ImageNet dataset that enables measuring concept generalization in a principled way. Our benchmark leverages expert knowledge that comes from WordNet in order to define a sequence of unseen ImageNet concept sets that are semantically more and more distant from the ImageNet-1K subset, a ubiquitous training set. This allows us to benchmark visual representations learned on ImageNet-1K out-of-the box: we analyse a number of such models from supervised, semi-supervised and self-supervised approaches under the prism of concept generalization, and show how our benchmark is able to uncover a number of interesting insights. We will provide resources for the benchmark at https://europe.naverlabs.com/cog-benchmark.
Hard Negative Mixing for Contrastive Learning
Oct 02, 2020



Contrastive learning has become a key component of self-supervised learning approaches for computer vision. By learning to embed two augmented versions of the same image close to each other and to push the embeddings of different images apart, one can train highly transferable visual representations. As revealed by recent studies, heavy data augmentation and large sets of negatives are both crucial in learning such representations. At the same time, data mixing strategies either at the image or the feature level improve both supervised and semi-supervised learning by synthesizing novel examples, forcing networks to learn more robust features. In this paper, we argue that an important aspect of contrastive learning, i.e., the effect of hard negatives, has so far been neglected. To get more meaningful negative samples, current top contrastive self-supervised learning approaches either substantially increase the batch sizes, or keep very large memory banks; increasing the memory size, however, leads to diminishing returns in terms of performance. We therefore start by delving deeper into a top-performing framework and show evidence that harder negatives are needed to facilitate better and faster learning. Based on these observations, and motivated by the success of data mixing, we propose hard negative mixing strategies at the feature level, that can be computed on-the-fly with a minimal computational overhead. We exhaustively ablate our approach on linear classification, object detection and instance segmentation and show that employing our hard negative mixing procedure improves the quality of visual representations learned by a state-of-the-art self-supervised learning method.
Proceedings of the ICLR Workshop on Computer Vision for Agriculture 2020
May 17, 2020This is the proceedings of the Computer Vision for Agriculture (CV4A) Workshop that was held in conjunction with the International Conference on Learning Representations (ICLR) 2020. The Computer Vision for Agriculture (CV4A) 2020 workshop was scheduled to be held in Addis Ababa, Ethiopia, on April 26th, 2020. It was held virtually that same day due to the COVID-19 pandemic. The workshop was held in conjunction with the International Conference on Learning Representations (ICLR) 2020.
Decoupling Representation and Classifier for Long-Tailed Recognition
Oct 21, 2019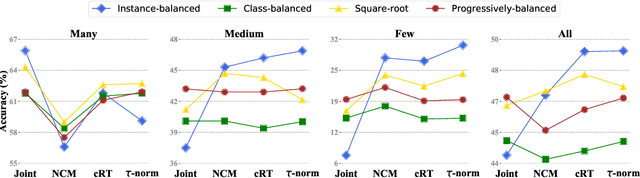
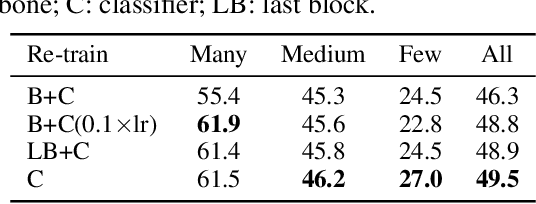
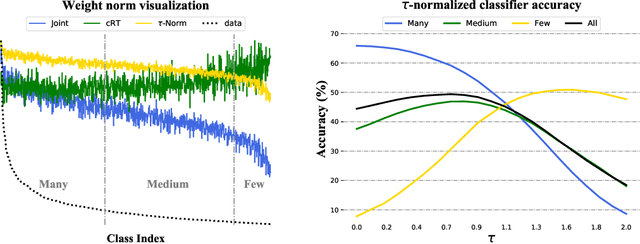
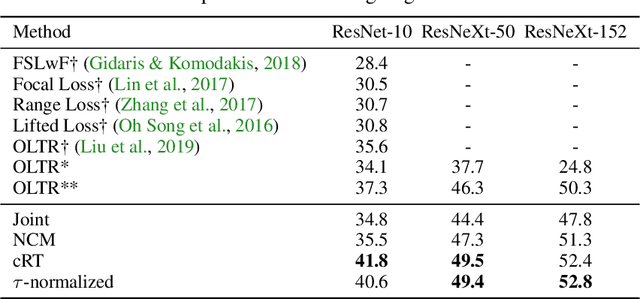
The long-tail distribution of the visual world poses great challenges for deep learning based classification models on how to handle the class imbalance problem. Existing solutions usually involve class-balancing strategies, e.g., by loss re-weighting, data re-sampling, or transfer learning from head- to tail-classes, but most of them adhere to the scheme of jointly learning representations and classifiers. In this work, we decouple the learning procedure into representation learning and classification, and systematically explore how different balancing strategies affect them for long-tailed recognition. The findings are surprising: (1) data imbalance might not be an issue in learning high-quality representations; (2) with representations learned with the simplest instance-balanced (natural) sampling, it is also possible to achieve strong long-tailed recognition ability at little cost by adjusting only the classifier. We conduct extensive experiments and set new state-of-the-art performance on common long-tailed benchmarks like ImageNet-LT, Places-LT and iNaturalist, showing that it is possible to outperform carefully designed losses, sampling strategies, even complex modules with memory, by using a straightforward approach that decouples representation and classification.
Learning to Generate Grounded Image Captions without Localization Supervision
Jun 01, 2019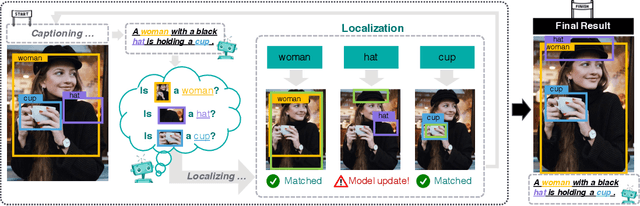
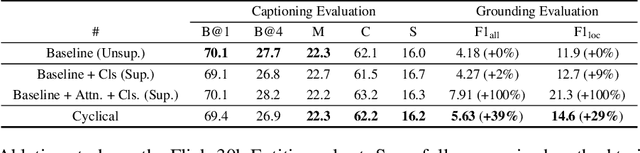
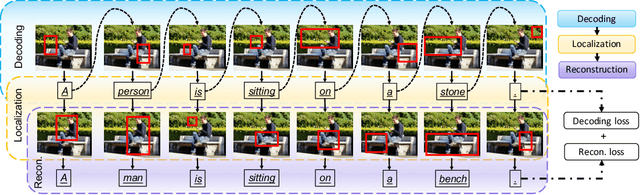
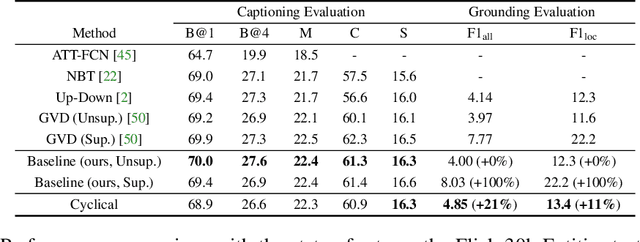
When generating a sentence description for an image, it frequently remains unclear how well the generated caption is grounded in the image or if the model hallucinates based on priors in the dataset and/or the language model. The most common way of relating image regions with words in caption models is through an attention mechanism over the regions that is used as input to predict the next word. The model must therefore learn to predict the attention without knowing the word it should localize. In this work, we propose a novel cyclical training regimen that forces the model to localize each word in the image after the sentence decoder generates it and then reconstruct the sentence from the localized image region(s) to match the ground-truth. The initial decoder and the proposed reconstructor share parameters during training and are learned jointly with the localizer, allowing the model to regularize the attention mechanism. Our proposed framework only requires learning one extra fully-connected layer (the localizer), a layer that can be removed at test time. We show that our model significantly improves grounding accuracy without relying on grounding supervision or introducing extra computation during inference.
Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks with Octave Convolution
Apr 30, 2019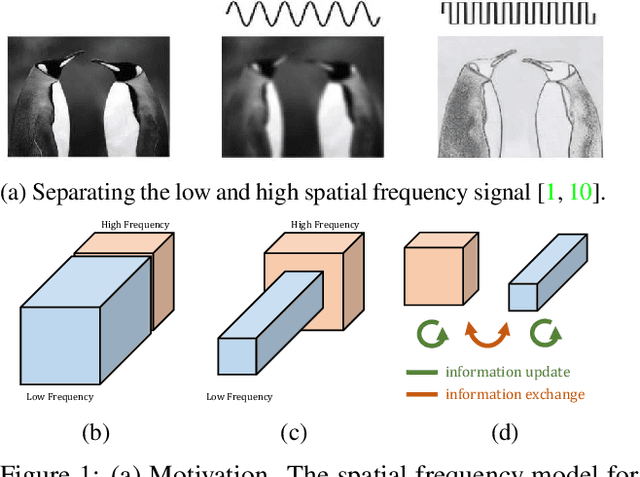

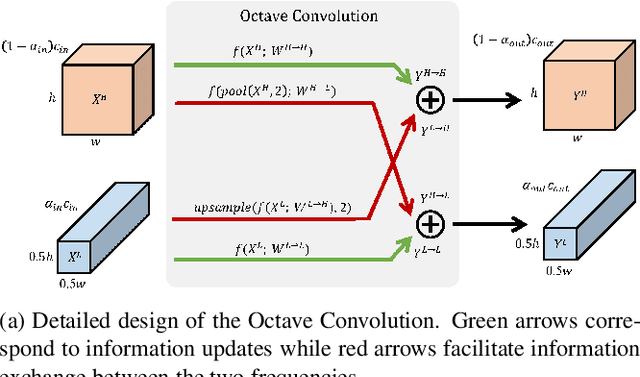
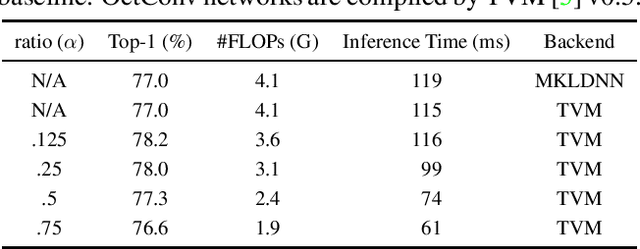
In natural images, information is conveyed at different frequencies where higher frequencies are usually encoded with fine details and lower frequencies are usually encoded with global structures. Similarly, the output feature maps of a convolution layer can also be seen as a mixture of information at different frequencies. In this work, we propose to factorize the mixed feature maps by their frequencies and design a novel Octave Convolution (OctConv) operation to store and process feature maps that vary spatially "slower" at a lower spatial resolution reducing both memory and computation cost. Unlike existing multi-scale meth-ods, OctConv is formulated as a single, generic, plug-and-play convolutional unit that can be used as a direct replacement of (vanilla) convolutions without any adjustments in the network architecture. It is also orthogonal and complementary to methods that suggest better topologies or reduce channel-wise redundancy like group or depth-wise convolutions. We experimentally show that by simply replacing con-volutions with OctConv, we can consistently boost accuracy for both image and video recognition tasks, while reducing memory and computational cost. An OctConv-equipped ResNet-152 can achieve 82.9% top-1 classification accuracy on ImageNet with merely 22.2 GFLOPs.