 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the power of foundation models
Nov 29, 2022With infinitely many high-quality data points, infinite computational power, an infinitely large foundation model with a perfect training algorithm and guaranteed zero generalization error on the pretext task, can the model be used for everything? This question cannot be answered by the existing theory of representation, optimization or generalization, because the issues they mainly investigate are assumed to be nonexistent here. In this paper, we show that category theory provides powerful machinery to answer this question. We have proved three results. The first one limits the power of prompt-based learning, saying that the model can solve a downstream task with prompts if and only if the task is representable. The second one says fine tuning does not have this limit, as a foundation model with the minimum power (up to symmetry) can theoretically solve downstream tasks with fine tuning and enough resources. Our final result can be seen as a new type of generalization theorem, showing that the foundation model can generate unseen objects from the target category (e.g., images) using the structural information from the source category (e.g., texts). Along the way, we provide a categorical framework for supervised and self-supervised learning, which might be of independent interest.
Consistent and Truthful Interpretation with Fourier Analysis
Oct 31, 2022



For many interdisciplinary fields, ML interpretations need to be consistent with what-if scenarios related to the current case, i.e., if one factor changes, how does the model react? Although the attribution methods are supported by the elegant axiomatic systems, they mainly focus on individual inputs, and are generally inconsistent. To support what-if scenarios, we introduce a new notion called truthful interpretation, and apply Fourier analysis of Boolean functions to get rigorous guarantees. Experimental results show that for neighborhoods with various radii, our method achieves 2x - 50x lower interpretation error compared with the other methods.
Predictive Inference with Feature Conformal Prediction
Oct 01, 2022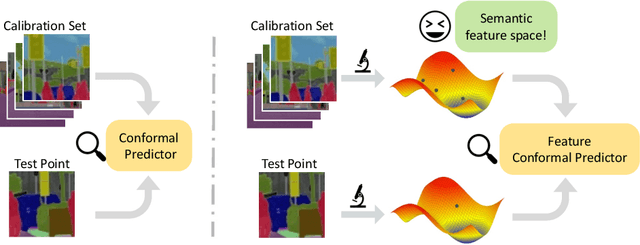

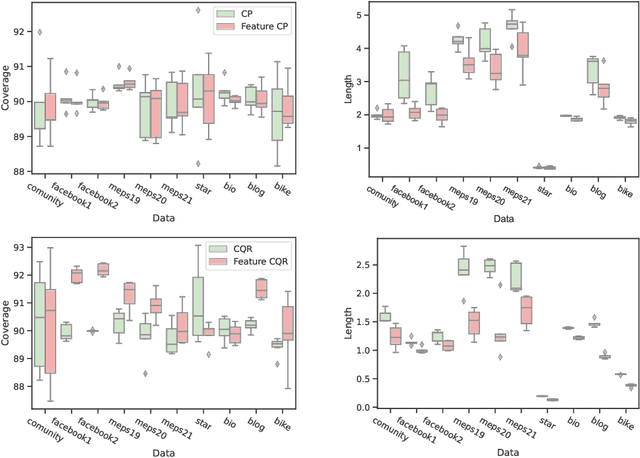
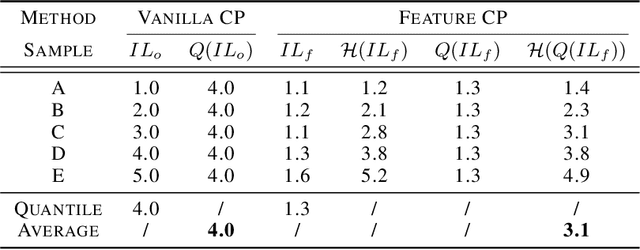
Conformal prediction is a distribution-free technique for establishing valid prediction intervals. Although conventionally people conduct conformal prediction in the output space, this is not the only possibility. In this paper, we propose feature conformal prediction, which extends the scope of conformal prediction to semantic feature spaces by leveraging the inductive bias of deep representation learning. From a theoretical perspective, we demonstrate that feature conformal prediction provably outperforms regular conformal prediction under mild assumptions. Our approach could be combined with not only vanilla conformal prediction, but also other adaptive conformal prediction methods. Experiments on various predictive inference tasks corroborate the efficacy of our method.
Anomaly Detection with Test Time Augmentation and Consistency Evaluation
Jun 06, 2022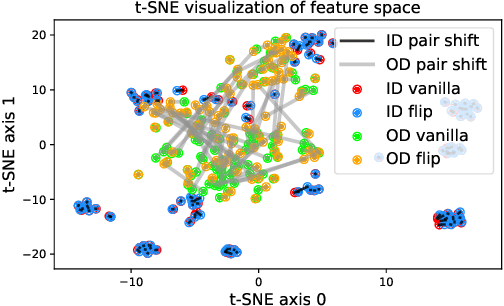
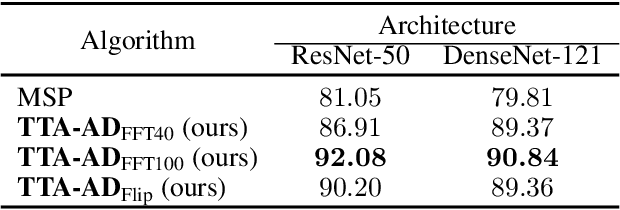

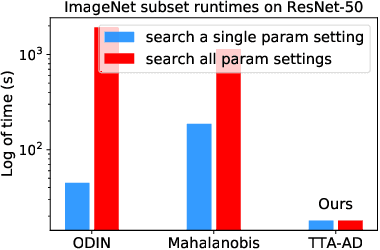
Deep neural networks are known to be vulnerable to unseen data: they may wrongly assign high confidence stcores to out-distribuion samples. Recent works try to solve the problem using representation learning methods and specific metrics. In this paper, we propose a simple, yet effective post-hoc anomaly detection algorithm named Test Time Augmentation Anomaly Detection (TTA-AD), inspired by a novel observation. Specifically, we observe that in-distribution data enjoy more consistent predictions for its original and augmented versions on a trained network than out-distribution data, which separates in-distribution and out-distribution samples. Experiments on various high-resolution image benchmark datasets demonstrate that TTA-AD achieves comparable or better detection performance under dataset-vs-dataset anomaly detection settings with a 60%~90\% running time reduction of existing classifier-based algorithms. We provide empirical verification that the key to TTA-AD lies in the remaining classes between augmented features, which has long been partially ignored by previous works. Additionally, we use RUNS as a surrogate to analyze our algorithm theoretically.
Towards Understanding Generalization via Decomposing Excess Risk Dynamics
Jun 11, 2021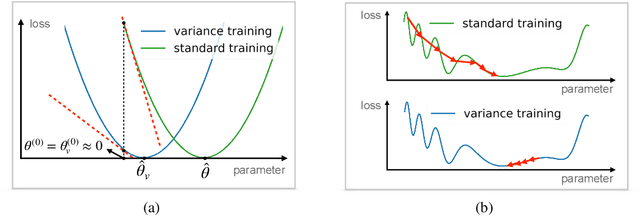
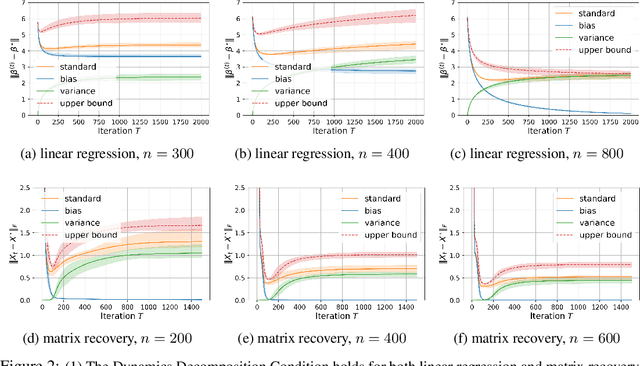
Generalization is one of the critical issues in machine learning. However, traditional methods like uniform convergence are not powerful enough to fully explain generalization because they may yield vacuous bounds even in overparameterized linear regression regimes. An alternative solution is to analyze the generalization dynamics to derive algorithm-dependent bounds, e.g., stability. Unfortunately, the stability-based bound is still far from explaining the remarkable generalization ability of neural networks due to the coarse-grained analysis of the signal and noise. Inspired by the observation that neural networks show a slow convergence rate when fitting noise, we propose decomposing the excess risk dynamics and applying stability-based bound only on the variance part (which measures how the model performs on pure noise). We provide two applications for the framework, including a linear case (overparameterized linear regression with gradient descent) and a non-linear case (matrix recovery with gradient flow). Under the decomposition framework, the new bound accords better with the theoretical and empirical evidence compared to the stability-based bound and uniform convergence bound.
T-SCI: A Two-Stage Conformal Inference Algorithm with Guaranteed Coverage for Cox-MLP
Mar 08, 2021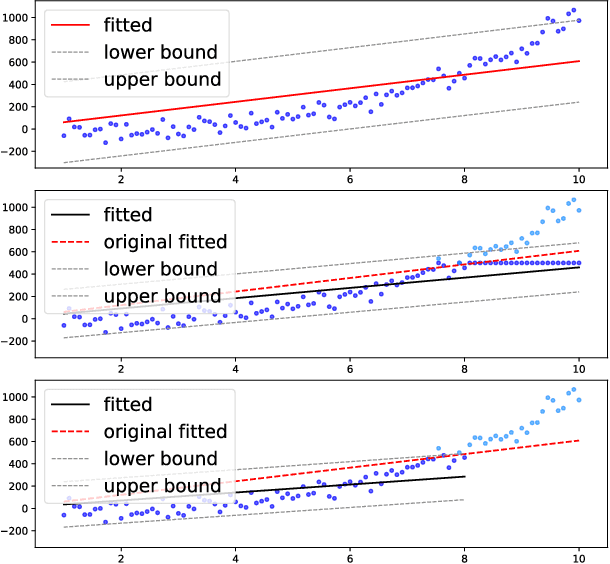
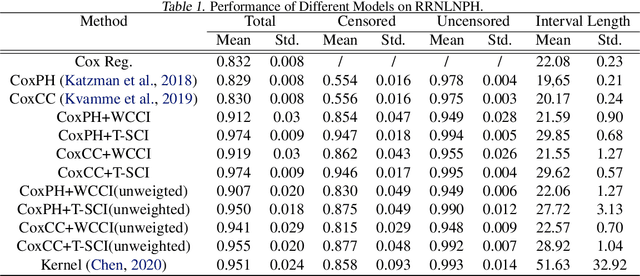

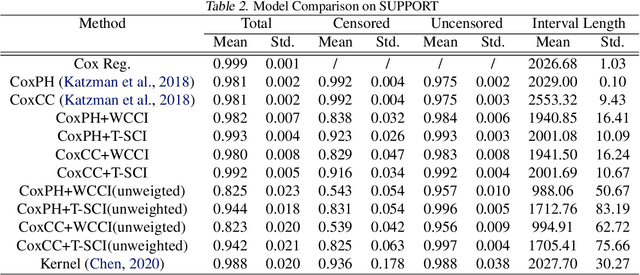
It is challenging to deal with censored data, where we only have access to the incomplete information of survival time instead of its exact value. Fortunately, under linear predictor assumption, people can obtain guaranteed coverage for the confidence band of survival time using methods like Cox Regression. However, when relaxing the linear assumption with neural networks (e.g., Cox-MLP \citep{katzman2018deepsurv,kvamme2019time}), we lose the guaranteed coverage. To recover the guaranteed coverage without linear assumption, we propose two algorithms based on conformal inference. In the first algorithm \emph{WCCI}, we revisit weighted conformal inference and introduce a new non-conformity score based on partial likelihood. We then propose a two-stage algorithm \emph{T-SCI}, where we run WCCI in the first stage and apply quantile conformal inference to calibrate the results in the second stage. Theoretical analysis shows that T-SCI returns guaranteed coverage under milder assumptions than WCCI. We conduct extensive experiments on synthetic data and real data using different methods, which validate our analysis.
Imbalance Robust Softmax for Deep Embeeding Learning
Nov 23, 2020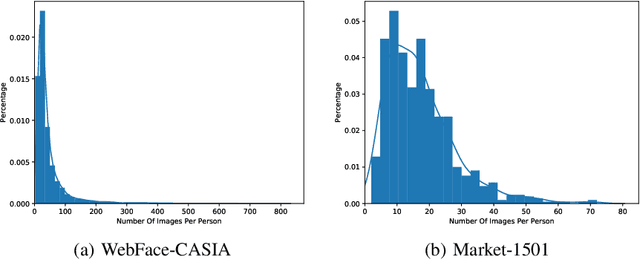
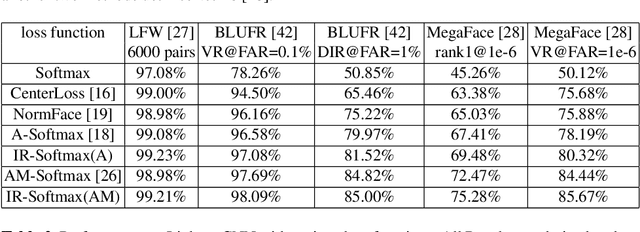
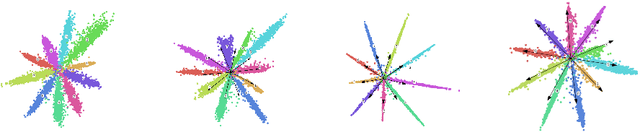
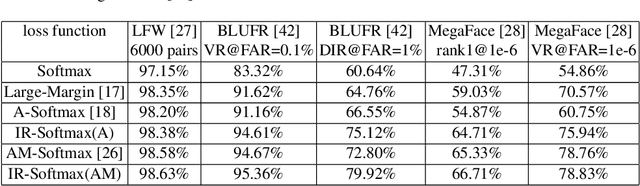
Deep embedding learning is expected to learn a metric space in which features have smaller maximal intra-class distance than minimal inter-class distance. In recent years, one research focus is to solve the open-set problem by discriminative deep embedding learning in the field of face recognition (FR) and person re-identification (re-ID). Apart from open-set problem, we find that imbalanced training data is another main factor causing the performance degradation of FR and re-ID, and data imbalance widely exists in the real applications. However, very little research explores why and how data imbalance influences the performance of FR and re-ID with softmax or its variants. In this work, we deeply investigate data imbalance in the perspective of neural network optimisation and feature distribution about softmax. We find one main reason of performance degradation caused by data imbalance is that the weights (from the penultimate fully-connected layer) are far from their class centers in feature space. Based on this investigation, we propose a unified framework, Imbalance-Robust Softmax (IR-Softmax), which can simultaneously solve the open-set problem and reduce the influence of data imbalance. IR-Softmax can generalise to any softmax and its variants (which are discriminative for open-set problem) by directly setting the weights as their class centers, naturally solving the data imbalance problem. In this work, we explicitly re-formulate two discriminative softmax (A-Softmax and AM-Softmax) under the framework of IR-Softmax. We conduct extensive experiments on FR databases (LFW, MegaFace) and re-ID database (Market-1501, Duke), and IR-Softmax outperforms many state-of-the-art methods.
Secure Data Sharing With Flow Model
Sep 24, 2020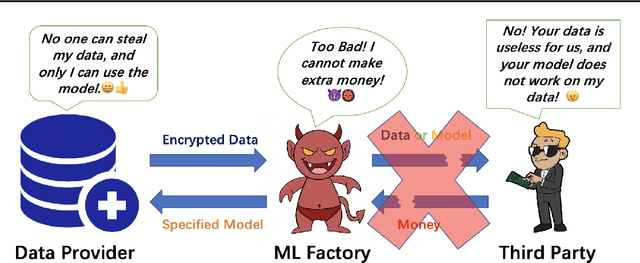
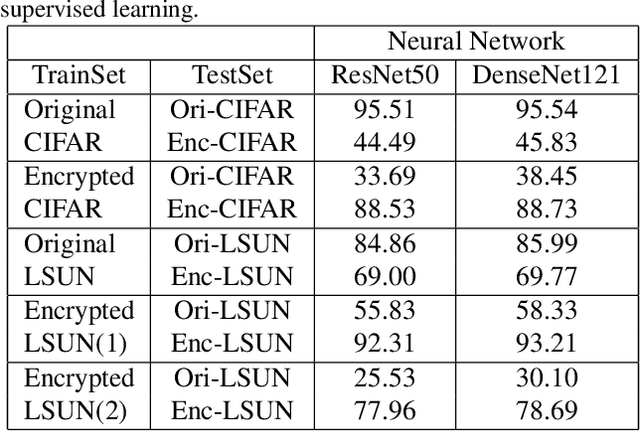
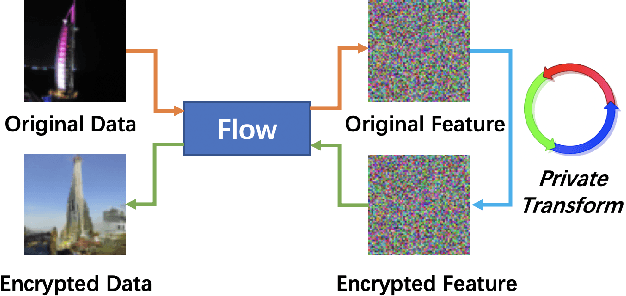
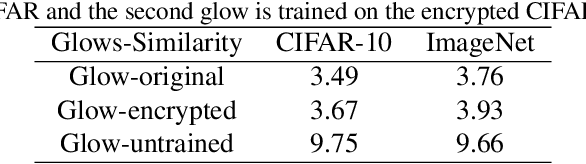
In the classical multi-party computation setting, multiple parties jointly compute a function without revealing their own input data. We consider a variant of this problem, where the input data can be shared for machine learning training purposes, but the data are also encrypted so that they cannot be recovered by other parties. We present a rotation based method using flow model, and theoretically justified its security. We demonstrate the effectiveness of our method in different scenarios, including supervised secure model training, and unsupervised generative model training. Our code is available at https://github.com/ duchenzhuang/flowencrypt.
Inject Machine Learning into Significance Test for Misspecified Linear Models
Jun 04, 2020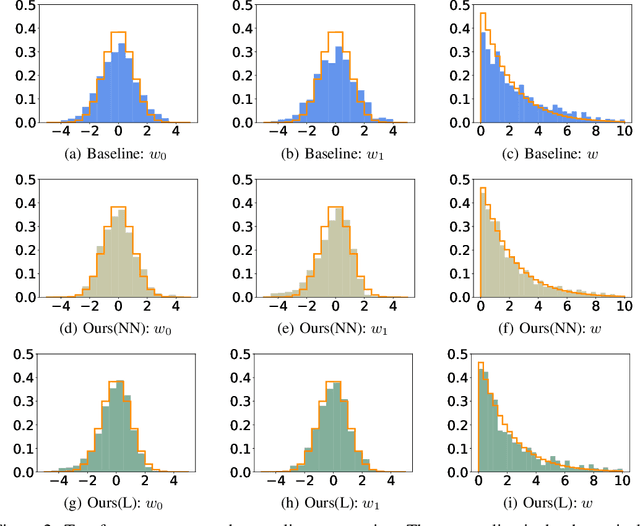
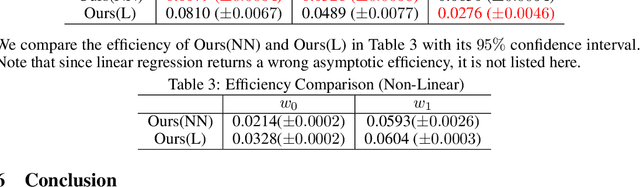
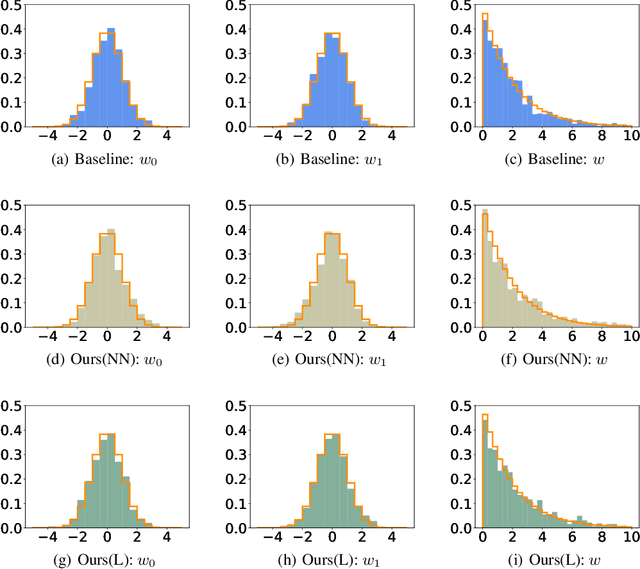

Due to its strong interpretability, linear regression is widely used in social science, from which significance test provides the significance level of models or coefficients in the traditional statistical inference. However, linear regression methods rely on the linear assumptions of the ground truth function, which do not necessarily hold in practice. As a result, even for simple non-linear cases, linear regression may fail to report the correct significance level. In this paper, we present a simple and effective assumption-free method for linear approximation in both linear and non-linear scenarios. First, we apply a machine learning method to fit the ground truth function on the training set and calculate its linear approximation. Afterward, we get the estimator by adding adjustments based on the validation set. We prove the concentration inequalities and asymptotic properties of our estimator, which leads to the corresponding significance test. Experimental results show that our estimator significantly outperforms linear regression for non-linear ground truth functions, indicating that our estimator might be a better tool for the significance test.
Adversarial Data Encryption
Feb 11, 2020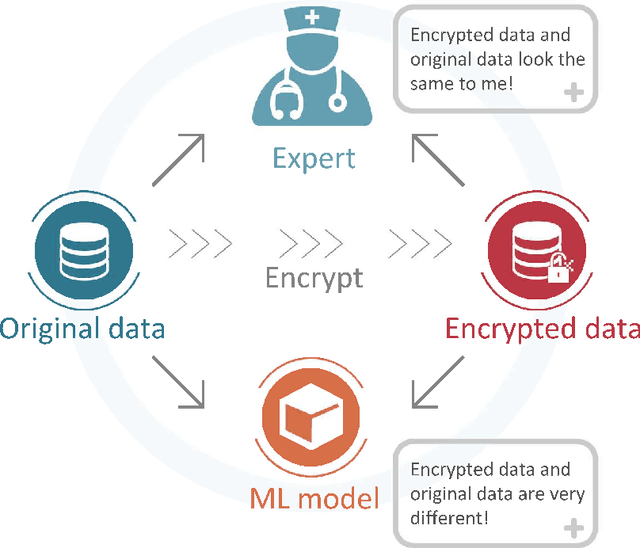

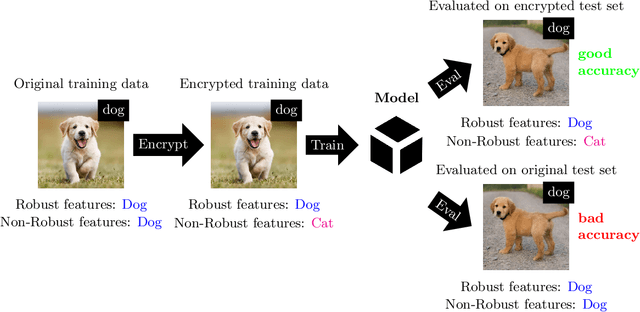

In the big data era, many organizations face the dilemma of data sharing. Regular data sharing is often necessary for human-centered discussion and communication, especially in medical scenarios. However, unprotected data sharing may also lead to data leakage. Inspired by adversarial attack, we propose a method for data encryption, so that for human beings the encrypted data look identical to the original version, but for machine learning methods they are misleading. To show the effectiveness of our method, we collaborate with the Beijing Tiantan Hospital, which has a world leading neurological center. We invite $3$ doctors to manually inspect our encryption method based on real world medical images. The results show that the encrypted images can be used for diagnosis by the doctors, but not by machine learning methods.