 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Interpretable Classification
Feb 06, 2023



How to interpret a data mining model has received much attention recently, because people may distrust a black-box predictive model if they do not understand how the model works. Hence, it will be trustworthy if a model can provide transparent illustrations on how to make the decision. Although many rule-based interpretable classification algorithms have been proposed, all these existing solutions cannot directly construct an interpretable model to provide personalized prediction for each individual test sample. In this paper, we make a first step towards formally introducing personalized interpretable classification as a new data mining problem to the literature. In addition to the problem formulation on this new issue, we present a greedy algorithm called PIC (Personalized Interpretable Classifier) to identify a personalized rule for each individual test sample. To demonstrate the necessity, feasibility and advantages of such a personalized interpretable classification method, we conduct a series of empirical studies on real data sets. The experimental results show that: (1) The new problem formulation enables us to find interesting rules for test samples that may be missed by existing non-personalized classifiers. (2) Our algorithm can achieve the same-level predictive accuracy as those state-of-the-art (SOTA) interpretable classifiers. (3) On a real data set for predicting breast cancer metastasis, such a personalized interpretable classifier can outperform SOTA methods in terms of both accuracy and interpretability.
D$^3$ETR: Decoder Distillation for Detection Transformer
Nov 17, 2022While various knowledge distillation (KD) methods in CNN-based detectors show their effectiveness in improving small students, the baselines and recipes for DETR-based detectors are yet to be built. In this paper, we focus on the transformer decoder of DETR-based detectors and explore KD methods for them. The outputs of the transformer decoder lie in random order, which gives no direct correspondence between the predictions of the teacher and the student, thus posing a challenge for knowledge distillation. To this end, we propose MixMatcher to align the decoder outputs of DETR-based teachers and students, which mixes two teacher-student matching strategies, i.e., Adaptive Matching and Fixed Matching. Specifically, Adaptive Matching applies bipartite matching to adaptively match the outputs of the teacher and the student in each decoder layer, while Fixed Matching fixes the correspondence between the outputs of the teacher and the student with the same object queries, with the teacher's fixed object queries fed to the decoder of the student as an auxiliary group. Based on MixMatcher, we build \textbf{D}ecoder \textbf{D}istillation for \textbf{DE}tection \textbf{TR}ansformer (D$^3$ETR), which distills knowledge in decoder predictions and attention maps from the teachers to students. D$^3$ETR shows superior performance on various DETR-based detectors with different backbones. For example, D$^3$ETR improves Conditional DETR-R50-C5 by $\textbf{7.8}/\textbf{2.4}$ mAP under $12/50$ epochs training settings with Conditional DETR-R101-C5 as the teacher.
DSLOB: A Synthetic Limit Order Book Dataset for Benchmarking Forecasting Algorithms under Distributional Shift
Nov 17, 2022In electronic trading markets, limit order books (LOBs) provide information about pending buy/sell orders at various price levels for a given security. Recently, there has been a growing interest in using LOB data for resolving downstream machine learning tasks (e.g., forecasting). However, dealing with out-of-distribution (OOD) LOB data is challenging since distributional shifts are unlabeled in current publicly available LOB datasets. Therefore, it is critical to build a synthetic LOB dataset with labeled OOD samples serving as a testbed for developing models that generalize well to unseen scenarios. In this work, we utilize a multi-agent market simulator to build a synthetic LOB dataset, named DSLOB, with and without market stress scenarios, which allows for the design of controlled distributional shift benchmarking. Using the proposed synthetic dataset, we provide a holistic analysis on the forecasting performance of three different state-of-the-art forecasting methods. Our results reflect the need for increased researcher efforts to develop algorithms with robustness to distributional shifts in high-frequency time series data.
Significance-Based Categorical Data Clustering
Nov 08, 2022



Although numerous algorithms have been proposed to solve the categorical data clustering problem, how to access the statistical significance of a set of categorical clusters remains unaddressed. To fulfill this void, we employ the likelihood ratio test to derive a test statistic that can serve as a significance-based objective function in categorical data clustering. Consequently, a new clustering algorithm is proposed in which the significance-based objective function is optimized via a Monte Carlo search procedure. As a by-product, we can further calculate an empirical $p$-value to assess the statistical significance of a set of clusters and develop an improved gap statistic for estimating the cluster number. Extensive experimental studies suggest that our method is able to achieve comparable performance to state-of-the-art categorical data clustering algorithms. Moreover, the effectiveness of such a significance-based formulation on statistical cluster validation and cluster number estimation is demonstrated through comprehensive empirical results.
Energy System Digitization in the Era of AI: A Three-Layered Approach towards Carbon Neutrality
Nov 02, 2022The transition towards carbon-neutral electricity is one of the biggest game changers in addressing climate change since it addresses the dual challenges of removing carbon emissions from the two largest sectors of emitters: electricity and transportation. The transition to a carbon-neutral electric grid poses significant challenges to conventional paradigms of modern grid planning and operation. Much of the challenge arises from the scale of the decision making and the uncertainty associated with the energy supply and demand. Artificial Intelligence (AI) could potentially have a transformative impact on accelerating the speed and scale of carbon-neutral transition, as many decision making processes in the power grid can be cast as classic, though challenging, machine learning tasks. We point out that to amplify AI's impact on carbon-neutral transition of the electric energy systems, the AI algorithms originally developed for other applications should be tailored in three layers of technology, markets, and policy.
Counterfactual Neural Temporal Point Process for Estimating Causal Influence of Misinformation on Social Media
Oct 14, 2022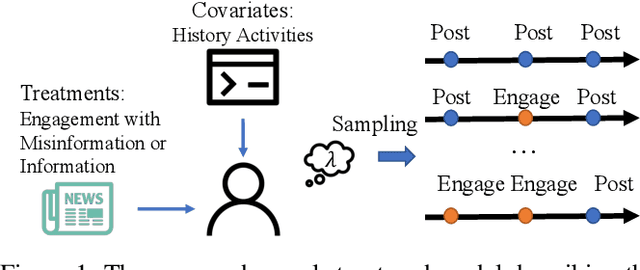

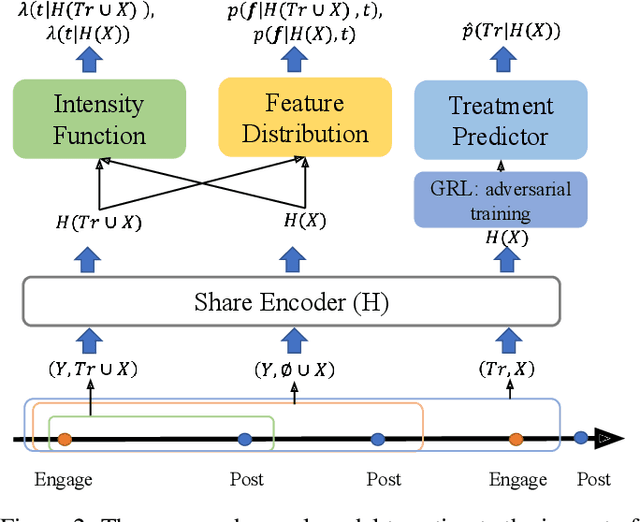
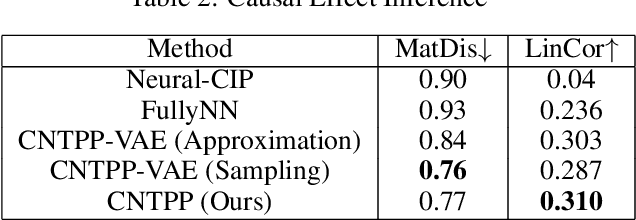
Recent years have witnessed the rise of misinformation campaigns that spread specific narratives on social media to manipulate public opinions on different areas, such as politics and healthcare. Consequently, an effective and efficient automatic methodology to estimate the influence of the misinformation on user beliefs and activities is needed. However, existing works on misinformation impact estimation either rely on small-scale psychological experiments or can only discover the correlation between user behaviour and misinformation. To address these issues, in this paper, we build up a causal framework that model the causal effect of misinformation from the perspective of temporal point process. To adapt the large-scale data, we design an efficient yet precise way to estimate the Individual Treatment Effect(ITE) via neural temporal point process and gaussian mixture models. Extensive experiments on synthetic dataset verify the effectiveness and efficiency of our model. We further apply our model on a real-world dataset of social media posts and engagements about COVID-19 vaccines. The experimental results indicate that our model recognized identifiable causal effect of misinformation that hurts people's subjective emotions toward the vaccines.
Transition to Adulthood for Young People with Intellectual or Developmental Disabilities: Emotion Detection and Topic Modeling
Sep 21, 2022Transition to Adulthood is an essential life stage for many families. The prior research has shown that young people with intellectual or development disabil-ities (IDD) have more challenges than their peers. This study is to explore how to use natural language processing (NLP) methods, especially unsupervised machine learning, to assist psychologists to analyze emotions and sentiments and to use topic modeling to identify common issues and challenges that young people with IDD and their families have. Additionally, the results were compared to those obtained from young people without IDD who were in tran-sition to adulthood. The findings showed that NLP methods can be very useful for psychologists to analyze emotions, conduct cross-case analysis, and sum-marize key topics from conversational data. Our Python code is available at https://github.com/mlaricheva/emotion_topic_modeling.
* Conference proceedings of 2022 SBP-BRiMS
Sparse Interaction Additive Networks via Feature Interaction Detection and Sparse Selection
Sep 19, 2022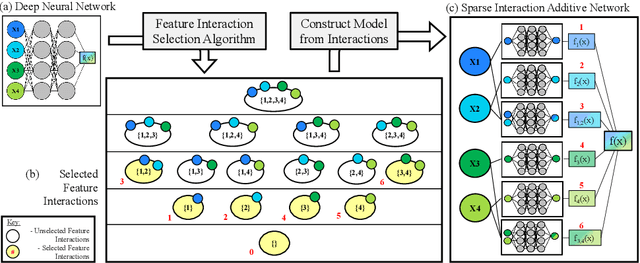
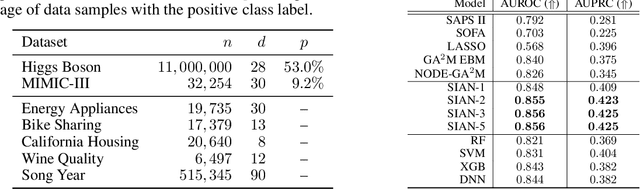
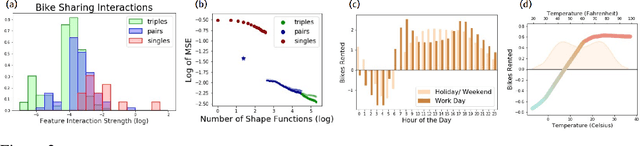
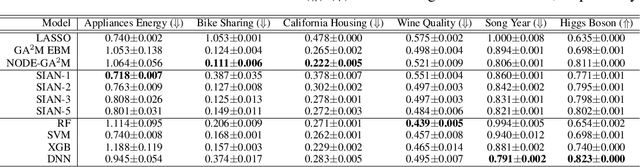
There is currently a large gap in performance between the statistically rigorous methods like linear regression or additive splines and the powerful deep methods using neural networks. Previous works attempting to close this gap have failed to fully investigate the exponentially growing number of feature combinations which deep networks consider automatically during training. In this work, we develop a tractable selection algorithm to efficiently identify the necessary feature combinations by leveraging techniques in feature interaction detection. Our proposed Sparse Interaction Additive Networks (SIAN) construct a bridge from these simple and interpretable models to fully connected neural networks. SIAN achieves competitive performance against state-of-the-art methods across multiple large-scale tabular datasets and consistently finds an optimal tradeoff between the modeling capacity of neural networks and the generalizability of simpler methods.
Automated Utterance Labeling of Conversations Using Natural Language Processing
Aug 12, 2022
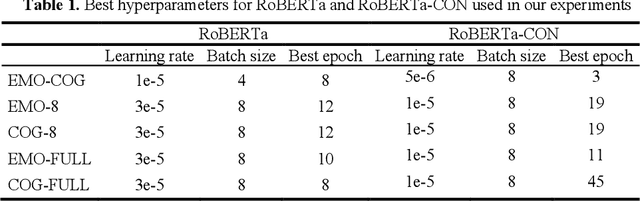
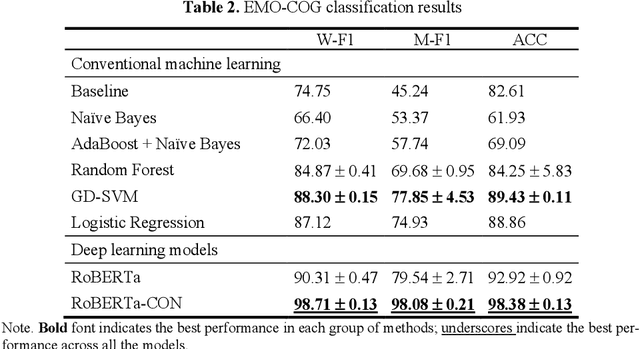
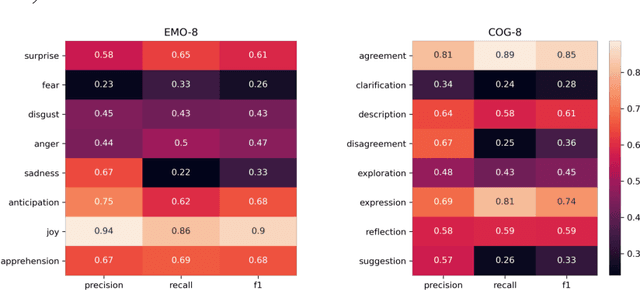
Conversational data is essential in psychology because it can help researchers understand individuals cognitive processes, emotions, and behaviors. Utterance labelling is a common strategy for analyzing this type of data. The development of NLP algorithms allows researchers to automate this task. However, psychological conversational data present some challenges to NLP researchers, including multilabel classification, a large number of classes, and limited available data. This study explored how automated labels generated by NLP methods are comparable to human labels in the context of conversations on adulthood transition. We proposed strategies to handle three common challenges raised in psychological studies. Our findings showed that the deep learning method with domain adaptation (RoBERTa-CON) outperformed all other machine learning methods; and the hierarchical labelling system that we proposed was shown to help researchers strategically analyze conversational data. Our Python code and NLP model are available at https://github.com/mlaricheva/automated_labeling.
SsaA: A Self-supervised auto-Annotation System for Online Visual Inspection and Manufacturing Automation
Aug 08, 2022


Recent trends in cloud computing technology effectively boosted the application of visual inspection. However, most of the available systems work in a human-in-the-loop manner and can not provide long-term support to the online application. To make a step forward, this paper outlines an automatic annotation system called SsaA, working in a self-supervised learning manner, for continuously making the online visual inspection in the manufacturing automation scenarios. Benefit from the self-supervised learning, SsaA is effective to establish a visual inspection application for the whole life-cycle of manufacturing. In the early stage, with only the anomaly-free data, the unsupervised algorithms are adopted to process the pretext task and generate coarse labels for the following data. Then supervised algorithms are trained for the downstream task. With user-friendly web-based interfaces, SsaA is very convenient to integrate and deploy both of the unsupervised and supervised algorithms. So far, the SsaA system has been adopted for some real-life industrial applications.