 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoMosaic-Bench: Evaluating Multi-Source Information Seeking in Tool-Augmented Agents
Oct 02, 2025Information seeking is a fundamental requirement for humans. However, existing LLM agents rely heavily on open-web search, which exposes two fundamental weaknesses: online content is noisy and unreliable, and many real-world tasks require precise, domain-specific knowledge unavailable from the web. The emergence of the Model Context Protocol (MCP) now allows agents to interface with thousands of specialized tools, seemingly resolving this limitation. Yet it remains unclear whether agents can effectively leverage such tools -- and more importantly, whether they can integrate them with general-purpose search to solve complex tasks. Therefore, we introduce InfoMosaic-Bench, the first benchmark dedicated to multi-source information seeking in tool-augmented agents. Covering six representative domains (medicine, finance, maps, video, web, and multi-domain integration), InfoMosaic-Bench requires agents to combine general-purpose search with domain-specific tools. Tasks are synthesized with InfoMosaic-Flow, a scalable pipeline that grounds task conditions in verified tool outputs, enforces cross-source dependencies, and filters out shortcut cases solvable by trivial lookup. This design guarantees both reliability and non-triviality. Experiments with 14 state-of-the-art LLM agents reveal three findings: (i) web information alone is insufficient, with GPT-5 achieving only 38.2% accuracy and 67.5% pass rate; (ii) domain tools provide selective but inconsistent benefits, improving some domains while degrading others; and (iii) 22.4% of failures arise from incorrect tool usage or selection, highlighting that current LLMs still struggle with even basic tool handling.
Differentially Private Federated Clustering with Random Rebalancing
Aug 08, 2025Federated clustering aims to group similar clients into clusters and produce one model for each cluster. Such a personalization approach typically improves model performance compared with training a single model to serve all clients, but can be more vulnerable to privacy leakage. Directly applying client-level differentially private (DP) mechanisms to federated clustering could degrade the utilities significantly. We identify that such deficiencies are mainly due to the difficulties of averaging privacy noise within each cluster (following standard privacy mechanisms), as the number of clients assigned to the same clusters is uncontrolled. To this end, we propose a simple and effective technique, named RR-Cluster, that can be viewed as a light-weight add-on to many federated clustering algorithms. RR-Cluster achieves reduced privacy noise via randomly rebalancing cluster assignments, guaranteeing a minimum number of clients assigned to each cluster. We analyze the tradeoffs between decreased privacy noise variance and potentially increased bias from incorrect assignments and provide convergence bounds for RR-Clsuter. Empirically, we demonstrate the RR-Cluster plugged into strong federated clustering algorithms results in significantly improved privacy/utility tradeoffs across both synthetic and real-world datasets.
Uncovering inequalities in new knowledge learning by large language models across different languages
Mar 06, 2025As large language models (LLMs) gradually become integral tools for problem solving in daily life worldwide, understanding linguistic inequality is becoming increasingly important. Existing research has primarily focused on static analyses that assess the disparities in the existing knowledge and capabilities of LLMs across languages. However, LLMs are continuously evolving, acquiring new knowledge to generate up-to-date, domain-specific responses. Investigating linguistic inequalities within this dynamic process is, therefore, also essential. In this paper, we explore inequalities in new knowledge learning by LLMs across different languages and four key dimensions: effectiveness, transferability, prioritization, and robustness. Through extensive experiments under two settings (in-context learning and fine-tuning) using both proprietary and open-source models, we demonstrate that low-resource languages consistently face disadvantages across all four dimensions. By shedding light on these disparities, we aim to raise awareness of linguistic inequalities in LLMs' new knowledge learning, fostering the development of more inclusive and equitable future LLMs.
Provably Efficient Action-Manipulation Attack Against Continuous Reinforcement Learning
Nov 20, 2024



Manipulating the interaction trajectories between the intelligent agent and the environment can control the agent's training and behavior, exposing the potential vulnerabilities of reinforcement learning (RL). For example, in Cyber-Physical Systems (CPS) controlled by RL, the attacker can manipulate the actions of the adopted RL to other actions during the training phase, which will lead to bad consequences. Existing work has studied action-manipulation attacks in tabular settings, where the states and actions are discrete. As seen in many up-and-coming RL applications, such as autonomous driving, continuous action space is widely accepted, however, its action-manipulation attacks have not been thoroughly investigated yet. In this paper, we consider this crucial problem in both white-box and black-box scenarios. Specifically, utilizing the knowledge derived exclusively from trajectories, we propose a black-box attack algorithm named LCBT, which uses the Monte Carlo tree search method for efficient action searching and manipulation. Additionally, we demonstrate that for an agent whose dynamic regret is sub-linearly related to the total number of steps, LCBT can teach the agent to converge to target policies with only sublinear attack cost, i.e., $O\left(\mathcal{R}(T) + MH^3K^E\log (MT)\right)(0<E<1)$, where $H$ is the number of steps per episode, $K$ is the total number of episodes, $T=KH$ is the total number of steps, $M$ is the number of subspaces divided in the state space, and $\mathcal{R}(T)$ is the bound of the RL algorithm's regret. We conduct our proposed attack methods on three aggressive algorithms: DDPG, PPO, and TD3 in continuous settings, which show a promising attack performance.
Learning Dynamic Context Augmentation for Global Entity Linking
Sep 04, 2019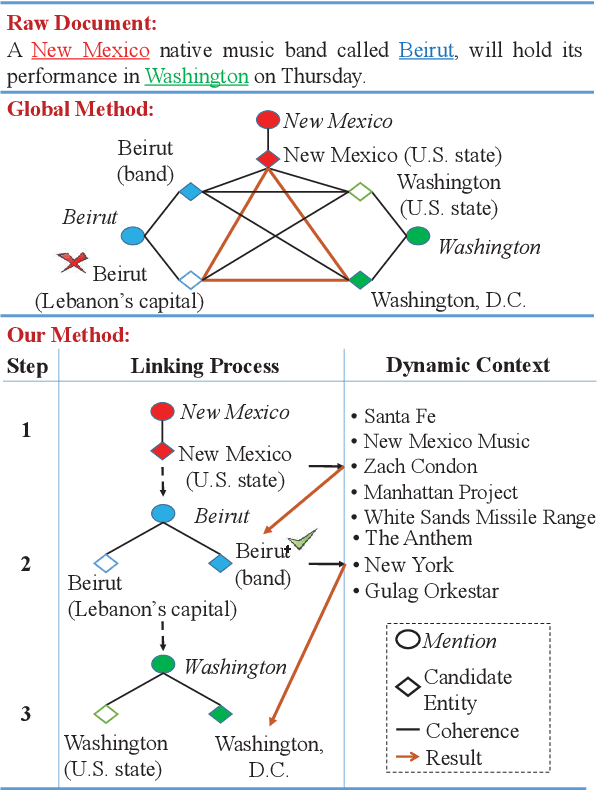
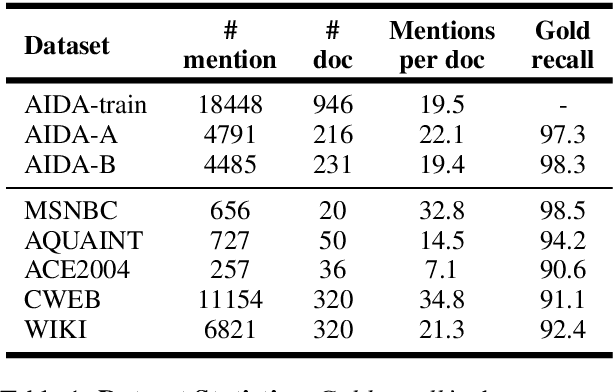
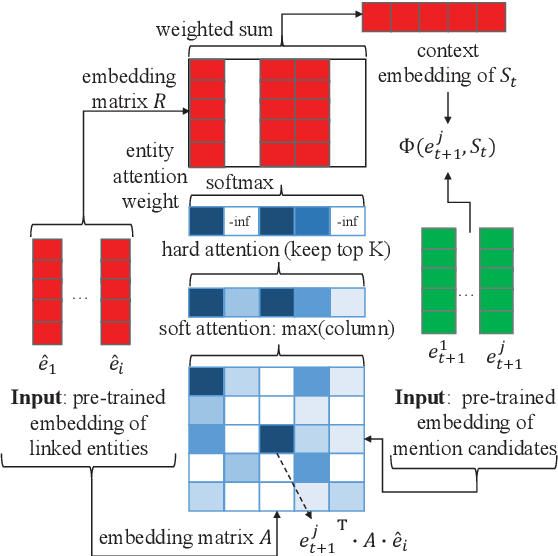
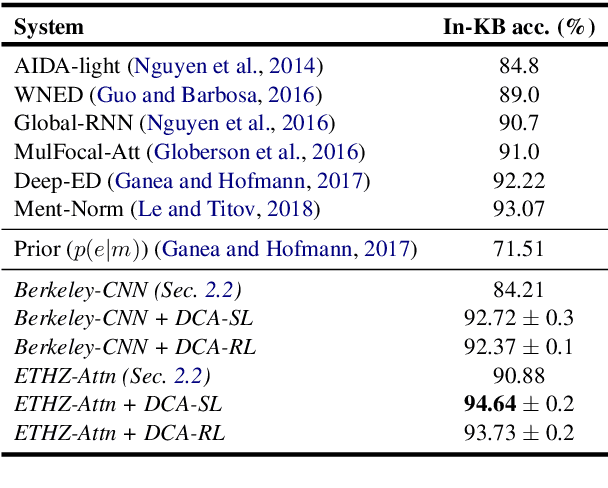
Despite of the recent success of collective entity linking (EL) methods, these "global" inference methods may yield sub-optimal results when the "all-mention coherence" assumption breaks, and often suffer from high computational cost at the inference stage, due to the complex search space. In this paper, we propose a simple yet effective solution, called Dynamic Context Augmentation (DCA), for collective EL, which requires only one pass through the mentions in a document. DCA sequentially accumulates context information to make efficient, collective inference, and can cope with different local EL models as a plug-and-enhance module. We explore both supervised and reinforcement learning strategies for learning the DCA model. Extensive experiments show the effectiveness of our model with different learning settings, base models, decision orders and attention mechanisms.