 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Jan 21, 2025



We present Hunyuan3D 2.0, an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets. This system includes two foundation components: a large-scale shape generation model -- Hunyuan3D-DiT, and a large-scale texture synthesis model -- Hunyuan3D-Paint. The shape generative model, built on a scalable flow-based diffusion transformer, aims to create geometry that properly aligns with a given condition image, laying a solid foundation for downstream applications. The texture synthesis model, benefiting from strong geometric and diffusion priors, produces high-resolution and vibrant texture maps for either generated or hand-crafted meshes. Furthermore, we build Hunyuan3D-Studio -- a versatile, user-friendly production platform that simplifies the re-creation process of 3D assets. It allows both professional and amateur users to manipulate or even animate their meshes efficiently. We systematically evaluate our models, showing that Hunyuan3D 2.0 outperforms previous state-of-the-art models, including the open-source models and closed-source models in geometry details, condition alignment, texture quality, and etc. Hunyuan3D 2.0 is publicly released in order to fill the gaps in the open-source 3D community for large-scale foundation generative models. The code and pre-trained weights of our models are available at: https://github.com/Tencent/Hunyuan3D-2
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
E-Sparse: Boosting the Large Language Model Inference through Entropy-based N:M Sparsity
Oct 24, 2023



Traditional pruning methods are known to be challenging to work in Large Language Models (LLMs) for Generative AI because of their unaffordable training process and large computational demands. For the first time, we introduce the information entropy of hidden state features into a pruning metric design, namely E-Sparse, to improve the accuracy of N:M sparsity on LLM. E-Sparse employs the information richness to leverage the channel importance, and further incorporates several novel techniques to put it into effect: (1) it introduces information entropy to enhance the significance of parameter weights and input feature norms as a novel pruning metric, and performs N:M sparsity without modifying the remaining weights. (2) it designs global naive shuffle and local block shuffle to quickly optimize the information distribution and adequately cope with the impact of N:M sparsity on LLMs' accuracy. E-Sparse is implemented as a Sparse-GEMM on FasterTransformer and runs on NVIDIA Ampere GPUs. Extensive experiments on the LLaMA family and OPT models show that E-Sparse can significantly speed up the model inference over the dense model (up to 1.53X) and obtain significant memory saving (up to 43.52%), with acceptable accuracy loss.
MKQ-BERT: Quantized BERT with 4-bits Weights and Activations
Mar 25, 2022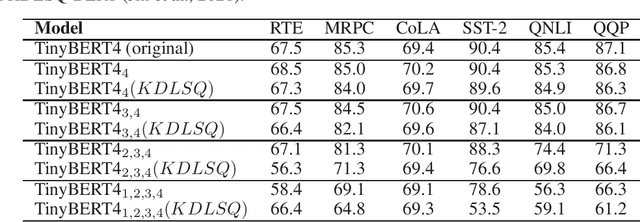
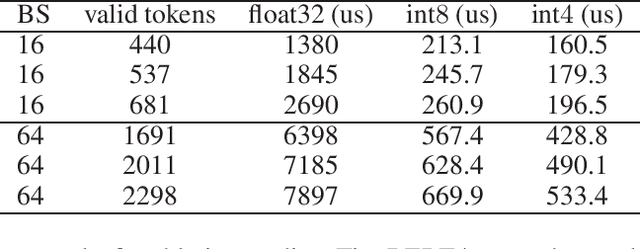

Recently, pre-trained Transformer based language models, such as BERT, have shown great superiority over the traditional methods in many Natural Language Processing (NLP) tasks. However, the computational cost for deploying these models is prohibitive on resource-restricted devices. One method to alleviate this computation overhead is to quantize the original model into fewer bits representation, and previous work has proved that we can at most quantize both weights and activations of BERT into 8-bits, without degrading its performance. In this work, we propose MKQ-BERT, which further improves the compression level and uses 4-bits for quantization. In MKQ-BERT, we propose a novel way for computing the gradient of the quantization scale, combined with an advanced distillation strategy. On the one hand, we prove that MKQ-BERT outperforms the existing BERT quantization methods for achieving a higher accuracy under the same compression level. On the other hand, we are the first work that successfully deploys the 4-bits BERT and achieves an end-to-end speedup for inference. Our results suggest that we could achieve 5.3x of bits reduction without degrading the model accuracy, and the inference speed of one int4 layer is 15x faster than a float32 layer in Transformer based model.