 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVicinity-Guided Discriminative Latent Diffusion for Privacy-Preserving Domain Adaptation
Oct 01, 2025Recent work on latent diffusion models (LDMs) has focused almost exclusively on generative tasks, leaving their potential for discriminative transfer largely unexplored. We introduce Discriminative Vicinity Diffusion (DVD), a novel LDM-based framework for a more practical variant of source-free domain adaptation (SFDA): the source provider may share not only a pre-trained classifier but also an auxiliary latent diffusion module, trained once on the source data and never exposing raw source samples. DVD encodes each source feature's label information into its latent vicinity by fitting a Gaussian prior over its k-nearest neighbors and training the diffusion network to drift noisy samples back to label-consistent representations. During adaptation, we sample from each target feature's latent vicinity, apply the frozen diffusion module to generate source-like cues, and use a simple InfoNCE loss to align the target encoder to these cues, explicitly transferring decision boundaries without source access. Across standard SFDA benchmarks, DVD outperforms state-of-the-art methods. We further show that the same latent diffusion module enhances the source classifier's accuracy on in-domain data and boosts performance in supervised classification and domain generalization experiments. DVD thus reinterprets LDMs as practical, privacy-preserving bridges for explicit knowledge transfer, addressing a core challenge in source-free domain adaptation that prior methods have yet to solve.
What Has Been Overlooked in Contrastive Source-Free Domain Adaptation: Leveraging Source-Informed Latent Augmentation within Neighborhood Context
Dec 18, 2024Source-free domain adaptation (SFDA) involves adapting a model originally trained using a labeled dataset ({\em source domain}) to perform effectively on an unlabeled dataset ({\em target domain}) without relying on any source data during adaptation. This adaptation is especially crucial when significant disparities in data distributions exist between the two domains and when there are privacy concerns regarding the source model's training data. The absence of access to source data during adaptation makes it challenging to analytically estimate the domain gap. To tackle this issue, various techniques have been proposed, such as unsupervised clustering, contrastive learning, and continual learning. In this paper, we first conduct an extensive theoretical analysis of SFDA based on contrastive learning, primarily because it has demonstrated superior performance compared to other techniques. Motivated by the obtained insights, we then introduce a straightforward yet highly effective latent augmentation method tailored for contrastive SFDA. This augmentation method leverages the dispersion of latent features within the neighborhood of the query sample, guided by the source pre-trained model, to enhance the informativeness of positive keys. Our approach, based on a single InfoNCE-based contrastive loss, outperforms state-of-the-art SFDA methods on widely recognized benchmark datasets.
Contrastive Adversarial Training for Unsupervised Domain Adaptation
Jul 17, 2024



Domain adversarial training has shown its effective capability for finding domain invariant feature representations and been successfully adopted for various domain adaptation tasks. However, recent advances of large models (e.g., vision transformers) and emerging of complex adaptation scenarios (e.g., DomainNet) make adversarial training being easily biased towards source domain and hardly adapted to target domain. The reason is twofold: relying on large amount of labelled data from source domain for large model training and lacking of labelled data from target domain for fine-tuning. Existing approaches widely focused on either enhancing discriminator or improving the training stability for the backbone networks. Due to unbalanced competition between the feature extractor and the discriminator during the adversarial training, existing solutions fail to function well on complex datasets. To address this issue, we proposed a novel contrastive adversarial training (CAT) approach that leverages the labeled source domain samples to reinforce and regulate the feature generation for target domain. Typically, the regulation forces the target feature distribution being similar to the source feature distribution. CAT addressed three major challenges in adversarial learning: 1) ensure the feature distributions from two domains as indistinguishable as possible for the discriminator, resulting in a more robust domain-invariant feature generation; 2) encourage target samples moving closer to the source in the feature space, reducing the requirement for generalizing classifier trained on the labeled source domain to unlabeled target domain; 3) avoid directly aligning unpaired source and target samples within mini-batch. CAT can be easily plugged into existing models and exhibits significant performance improvements.
Fast Implicit Neural Representation Image Codec in Resource-limited Devices
Jan 23, 2024Displaying high-quality images on edge devices, such as augmented reality devices, is essential for enhancing the user experience. However, these devices often face power consumption and computing resource limitations, making it challenging to apply many deep learning-based image compression algorithms in this field. Implicit Neural Representation (INR) for image compression is an emerging technology that offers two key benefits compared to cutting-edge autoencoder models: low computational complexity and parameter-free decoding. It also outperforms many traditional and early neural compression methods in terms of quality. In this study, we introduce a new Mixed Autoregressive Model (MARM) to significantly reduce the decoding time for the current INR codec, along with a new synthesis network to enhance reconstruction quality. MARM includes our proposed Autoregressive Upsampler (ARU) blocks, which are highly computationally efficient, and ARM from previous work to balance decoding time and reconstruction quality. We also propose enhancing ARU's performance using a checkerboard two-stage decoding strategy. Moreover, the ratio of different modules can be adjusted to maintain a balance between quality and speed. Comprehensive experiments demonstrate that our method significantly improves computational efficiency while preserving image quality. With different parameter settings, our method can outperform popular AE-based codecs in constrained environments in terms of both quality and decoding time, or achieve state-of-the-art reconstruction quality compared to other INR codecs.
Ensemble diverse hypotheses and knowledge distillation for unsupervised cross-subject adaptation
Apr 15, 2022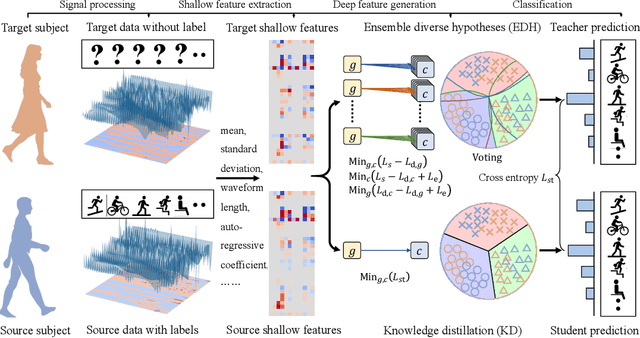
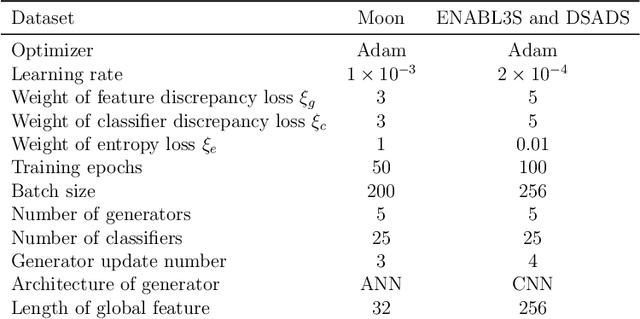
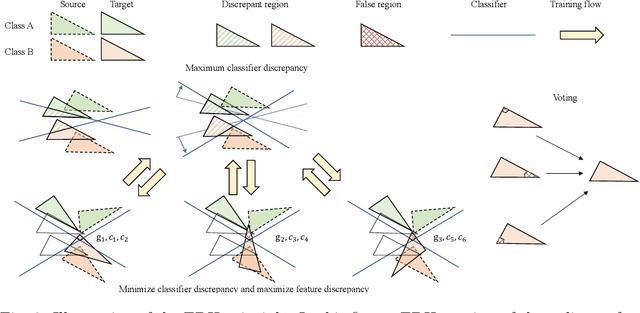
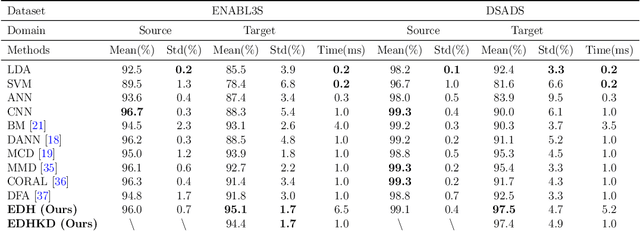
Recognizing human locomotion intent and activities is important for controlling the wearable robots while walking in complex environments. However, human-robot interface signals are usually user-dependent, which causes that the classifier trained on source subjects performs poorly on new subjects. To address this issue, this paper designs the ensemble diverse hypotheses and knowledge distillation (EDHKD) method to realize unsupervised cross-subject adaptation. EDH mitigates the divergence between labeled data of source subjects and unlabeled data of target subjects to accurately classify the locomotion modes of target subjects without labeling data. Compared to previous domain adaptation methods based on the single learner, which may only learn a subset of features from input signals, EDH can learn diverse features by incorporating multiple diverse feature generators and thus increases the accuracy and decreases the variance of classifying target data, but it sacrifices the efficiency. To solve this problem, EDHKD (student) distills the knowledge from the EDH (teacher) to a single network to remain efficient and accurate. The performance of the EDHKD is theoretically proved and experimentally validated on a 2D moon dataset and two public human locomotion datasets. Experimental results show that the EDHKD outperforms all other methods. The EDHKD can classify target data with 96.9%, 94.4%, and 97.4% average accuracy on the above three datasets with a short computing time (1 ms). Compared to a benchmark (BM) method, the EDHKD increases 1.3% and 7.1% average accuracy for classifying the locomotion modes of target subjects. The EDHKD also stabilizes the learning curves. Therefore, the EDHKD is significant for increasing the generalization ability and efficiency of the human intent prediction and human activity recognition system, which will improve human-robot interactions.
Preserving Domain Private Representation via Mutual Information Maximization
Jan 09, 2022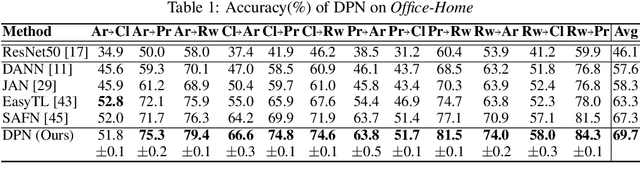
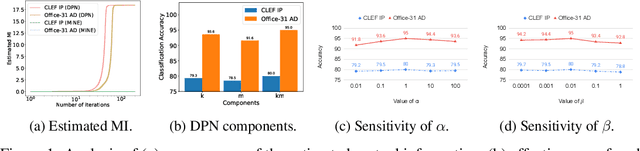
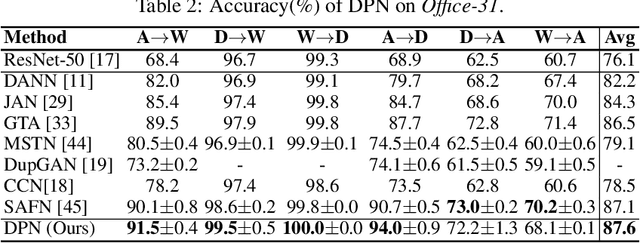
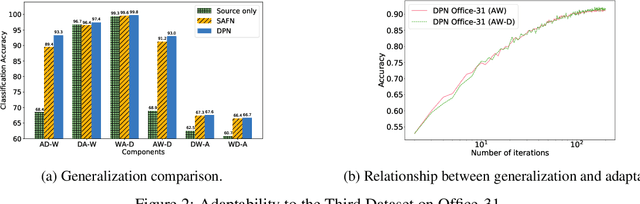
Recent advances in unsupervised domain adaptation have shown that mitigating the domain divergence by extracting the domain-invariant representation could significantly improve the generalization of a model to an unlabeled data domain. Nevertheless, the existing methods fail to effectively preserve the representation that is private to the label-missing domain, which could adversely affect the generalization. In this paper, we propose an approach to preserve such representation so that the latent distribution of the unlabeled domain could represent both the domain-invariant features and the individual characteristics that are private to the unlabeled domain. In particular, we demonstrate that maximizing the mutual information between the unlabeled domain and its latent space while mitigating the domain divergence can achieve such preservation. We also theoretically and empirically validate that preserving the representation that is private to the unlabeled domain is important and of necessity for the cross-domain generalization. Our approach outperforms state-of-the-art methods on several public datasets.
Data-driven Sensor Deployment for Spatiotemporal Field Reconstruction
Jan 02, 2022
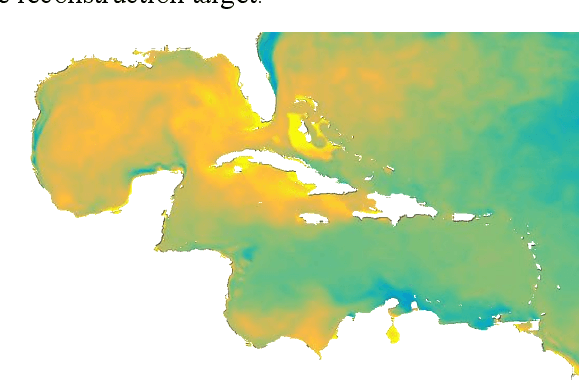
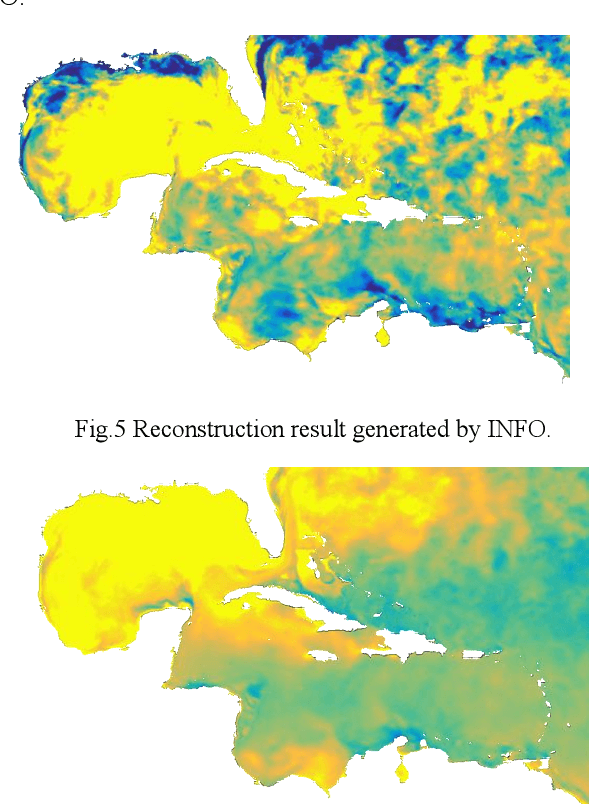
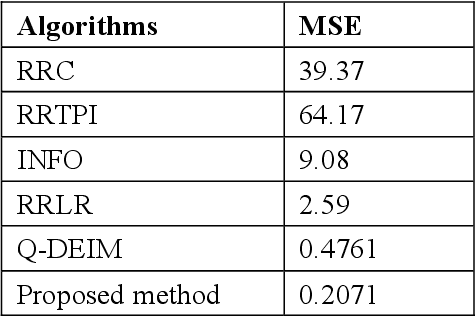
This paper concerns the data-driven sensor deployment problem in large spatiotemporal fields. Traditionally, sensor deployment strategies have been heavily dependent on model-based planning approaches. However, model-based approaches do not typically maximize the information gain in the field, which tends to generate less effective sampling locations and lead to high reconstruction error. In the present paper, a data-driven approach is developed to overcome the drawbacks of the model-based approach and improve the spatiotemporal field reconstruction accuracy. The proposed method can select the most informative sampling locations to represent the entire spatiotemporal field. To this end, the proposed method decomposes the spatiotemporal field using principal component analysis (PCA) and finds the top r essential entities of the principal basis. The corresponding sampling locations of the selected entities are regarded as the sensor deployment locations. The observations collected at the selected sensor deployment locations can then be used to reconstruct the spatiotemporal field, accurately. Results are demonstrated using a National Oceanic and Atmospheric Administration sea surface temperature dataset. In the present study, the proposed method achieved the lowest reconstruction error among all methods.
Discriminative Feature Alignment: Improving Transferability of Unsupervised Domain Adaptation by Gaussian-guided Latent Alignment
Jul 16, 2020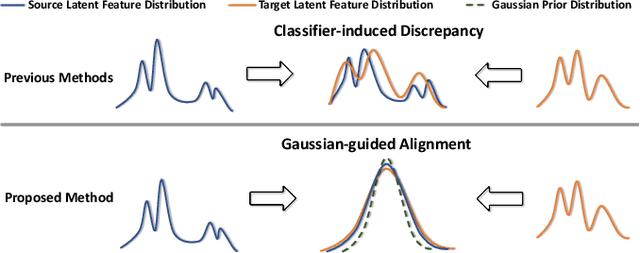
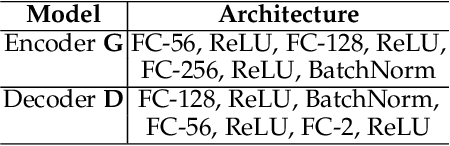
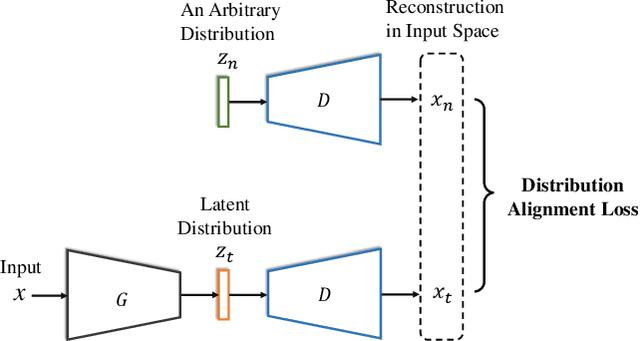
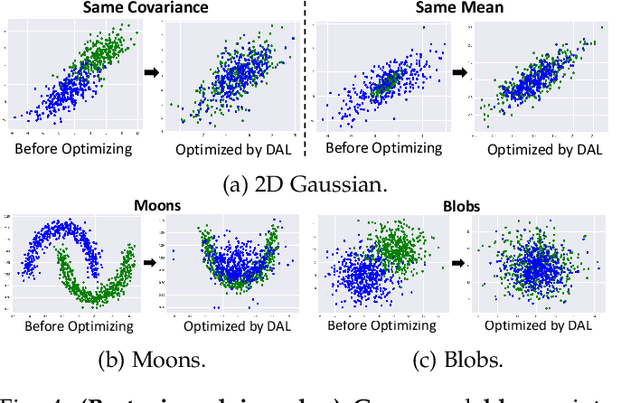
In this study, we focus on the unsupervised domain adaptation problem where an approximate inference model is to be learned from a labeled data domain and expected to generalize well to an unlabeled data domain. The success of unsupervised domain adaptation largely relies on the cross-domain feature alignment. Previous work has attempted to directly align latent features by the classifier-induced discrepancies. Nevertheless, a common feature space cannot always be learned via this direct feature alignment especially when a large domain gap exists. To solve this problem, we introduce a Gaussian-guided latent alignment approach to align the latent feature distributions of the two domains under the guidance of the prior distribution. In such an indirect way, the distributions over the samples from the two domains will be constructed on a common feature space, i.e., the space of the prior, which promotes better feature alignment. To effectively align the target latent distribution with this prior distribution, we also propose a novel unpaired L1-distance by taking advantage of the formulation of the encoder-decoder. The extensive evaluations on nine benchmark datasets validate the superior knowledge transferability through outperforming state-of-the-art methods and the versatility of the proposed method by improving the existing work significantly.