 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoT-Kinetics: A Theoretical Modeling Assessing LRM Reasoning Process
May 19, 2025Recent Large Reasoning Models significantly improve the reasoning ability of Large Language Models by learning to reason, exhibiting the promising performance in solving complex tasks. LRMs solve tasks that require complex reasoning by explicitly generating reasoning trajectories together with answers. Nevertheless, judging the quality of such an output answer is not easy because only considering the correctness of the answer is not enough and the soundness of the reasoning trajectory part matters as well. Logically, if the soundness of the reasoning part is poor, even if the answer is correct, the confidence of the derived answer should be low. Existing methods did consider jointly assessing the overall output answer by taking into account the reasoning part, however, their capability is still not satisfactory as the causal relationship of the reasoning to the concluded answer cannot properly reflected. In this paper, inspired by classical mechanics, we present a novel approach towards establishing a CoT-Kinetics energy equation. Specifically, our CoT-Kinetics energy equation formulates the token state transformation process, which is regulated by LRM internal transformer layers, as like a particle kinetics dynamics governed in a mechanical field. Our CoT-Kinetics energy assigns a scalar score to evaluate specifically the soundness of the reasoning phase, telling how confident the derived answer could be given the evaluated reasoning. As such, the LRM's overall output quality can be accurately measured, rather than a coarse judgment (e.g., correct or incorrect) anymore.
PRISM: Self-Pruning Intrinsic Selection Method for Training-Free Multimodal Data Selection
Feb 17, 2025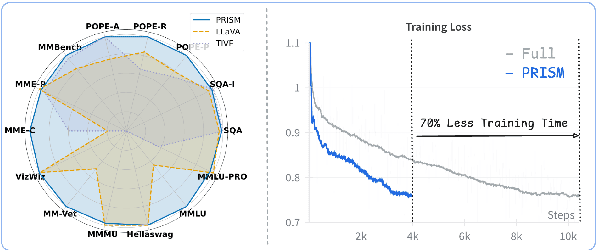
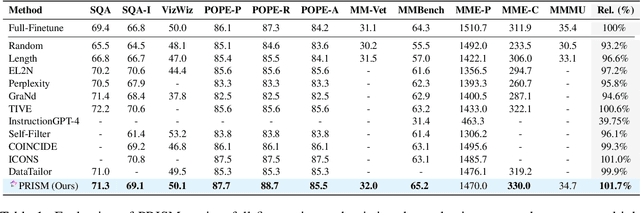

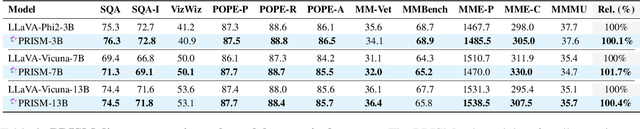
Visual instruction tuning refines pre-trained Multimodal Large Language Models (MLLMs) to enhance their real-world task performance. However, the rapid expansion of visual instruction datasets introduces significant data redundancy, leading to excessive computational costs. Existing data selection methods predominantly rely on proxy models or loss-based metrics, both of which impose substantial computational overheads due to the necessity of model inference and backpropagation. To address this challenge, we propose PRISM, a novel training-free approach for efficient multimodal data selection. Unlike existing methods, PRISM eliminates the reliance on proxy models, warm-up pretraining, and gradient-based optimization. Instead, it leverages Pearson correlation analysis to quantify the intrinsic visual encoding properties of MLLMs, computing a task-specific correlation score to identify high-value instances. This not only enbles data-efficient selection,but maintains the original performance. Empirical evaluations across multiple MLLMs demonstrate that PRISM reduces the overall time required for visual instruction tuning and data selection to just 30% of conventional methods, while surpassing fully fine-tuned models across eight multimodal and three language understanding benchmarks, achieving a 101.7% relative improvement in final performance.
D3PRefiner: A Diffusion-based Denoise Method for 3D Human Pose Refinement
Jan 08, 2024Three-dimensional (3D) human pose estimation using a monocular camera has gained increasing attention due to its ease of implementation and the abundance of data available from daily life. However, owing to the inherent depth ambiguity in images, the accuracy of existing monocular camera-based 3D pose estimation methods remains unsatisfactory, and the estimated 3D poses usually include much noise. By observing the histogram of this noise, we find each dimension of the noise follows a certain distribution, which indicates the possibility for a neural network to learn the mapping between noisy poses and ground truth poses. In this work, in order to obtain more accurate 3D poses, a Diffusion-based 3D Pose Refiner (D3PRefiner) is proposed to refine the output of any existing 3D pose estimator. We first introduce a conditional multivariate Gaussian distribution to model the distribution of noisy 3D poses, using paired 2D poses and noisy 3D poses as conditions to achieve greater accuracy. Additionally, we leverage the architecture of current diffusion models to convert the distribution of noisy 3D poses into ground truth 3D poses. To evaluate the effectiveness of the proposed method, two state-of-the-art sequence-to-sequence 3D pose estimators are used as basic 3D pose estimation models, and the proposed method is evaluated on different types of 2D poses and different lengths of the input sequence. Experimental results demonstrate the proposed architecture can significantly improve the performance of current sequence-to-sequence 3D pose estimators, with a reduction of at least 10.3% in the mean per joint position error (MPJPE) and at least 11.0% in the Procrustes MPJPE (P-MPJPE).
FreeMan: Towards Benchmarking 3D Human Pose Estimation in the Wild
Sep 12, 2023Estimating the 3D structure of the human body from natural scenes is a fundamental aspect of visual perception. This task carries great importance for fields like AIGC and human-robot interaction. In practice, 3D human pose estimation in real-world settings is a critical initial step in solving this problem. However, the current datasets, often collected under controlled laboratory conditions using complex motion capture equipment and unvarying backgrounds, are insufficient. The absence of real-world datasets is stalling the progress of this crucial task. To facilitate the development of 3D pose estimation, we present FreeMan, the first large-scale, real-world multi-view dataset. FreeMan was captured by synchronizing 8 smartphones across diverse scenarios. It comprises 11M frames from 8000 sequences, viewed from different perspectives. These sequences cover 40 subjects across 10 different scenarios, each with varying lighting conditions. We have also established an automated, precise labeling pipeline that allows for large-scale processing efficiently. We provide comprehensive evaluation baselines for a range of tasks, underlining the significant challenges posed by FreeMan. Further evaluations of standard indoor/outdoor human sensing datasets reveal that FreeMan offers robust representation transferability in real and complex scenes. FreeMan is now publicly available at https://wangjiongw.github.io/freeman.