 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTusom2021: A Phonetically Transcribed Speech Dataset from an Endangered Language for Universal Phone Recognition Experiments
Apr 02, 2021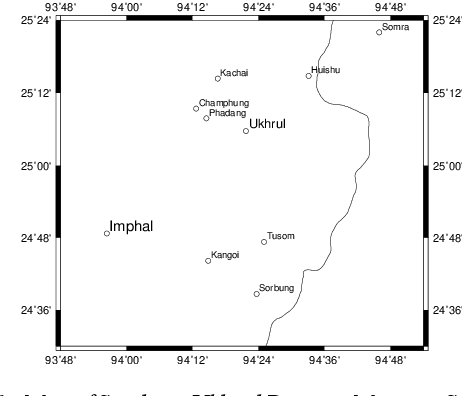
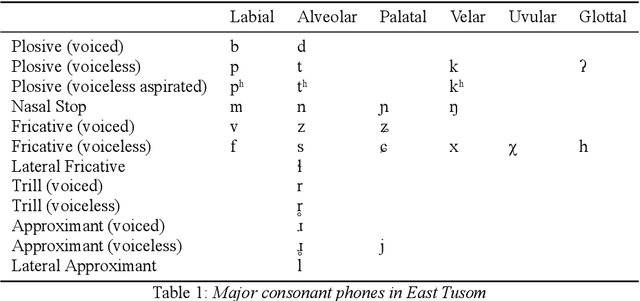
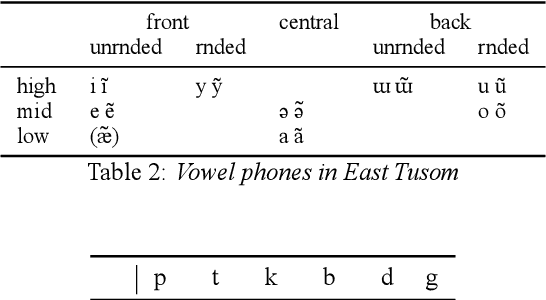
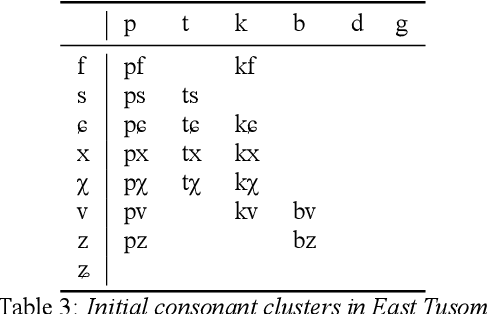
There is growing interest in ASR systems that can recognize phones in a language-independent fashion. There is additionally interest in building language technologies for low-resource and endangered languages. However, there is a paucity of realistic data that can be used to test such systems and technologies. This paper presents a publicly available, phonetically transcribed corpus of 2255 utterances (words and short phrases) in the endangered Tangkhulic language East Tusom (no ISO 639-3 code), a Tibeto-Burman language variety spoken mostly in India. Because the dataset is transcribed in terms of phones, rather than phonemes, it is a better match for universal phone recognition systems than many larger (phonemically transcribed) datasets. This paper describes the dataset and the methodology used to produce it. It further presents basic benchmarks of state-of-the-art universal phone recognition systems on the dataset as baselines for future experiments.
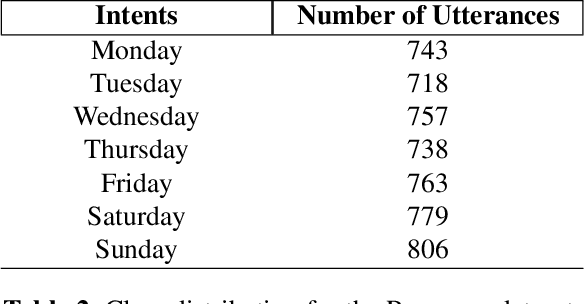
Acoustics Based Intent Recognition Using Discovered Phonetic Units for Low Resource Languages
Nov 07, 2020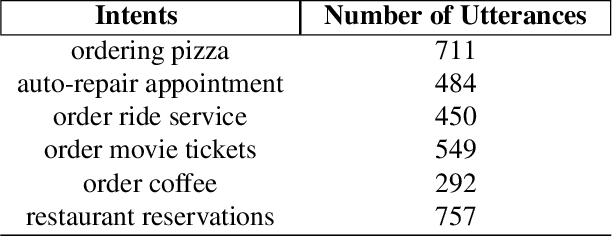

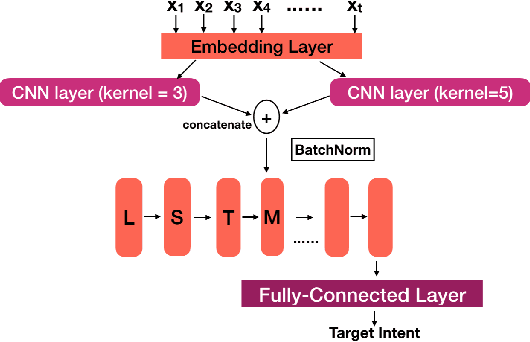
With recent advancements in language technologies, humansare now interacting with technology through speech. To in-crease the reach of these technologies, we need to build suchsystems in local languages. A major bottleneck here are theunderlying data-intensive parts that make up such systems,including automatic speech recognition (ASR) systems thatrequire large amounts of labelled data. With the aim of aidingdevelopment of dialog systems in low resourced languages,we propose a novel acoustics based intent recognition systemthat uses discovered phonetic units for intent classification.The system is made up of two blocks - the first block gen-erates a transcript of discovered phonetic units for the inputaudio, and the second block which performs intent classifi-cation from the generated phonemic transcripts. Our workpresents results for such a system for two languages families- Indic languages and Romance languages, for two differentintent recognition tasks. We also perform multilingual train-ing of our intent classifier and show improved cross-lingualtransfer and performance on an unknown language with zeroresources in the same language family.
Revisiting Factorizing Aggregated Posterior in Learning Disentangled Representations
Sep 12, 2020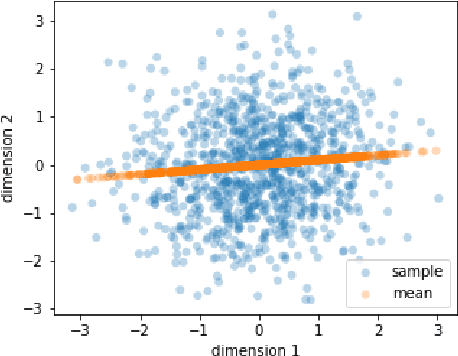



In the problem of learning disentangled representations, one of the promising methods is to factorize aggregated posterior by penalizing the total correlation of sampled latent variables. However, this well-motivated strategy has a blind spot: there is a disparity between the sampled latent representation and its corresponding mean representation. In this paper, we provide a theoretical explanation that low total correlation of sampled representation cannot guarantee low total correlation of the mean representation. Indeed, we prove that for the multivariate normal distributions, the mean representation with arbitrarily high total correlation can have a corresponding sampled representation with bounded total correlation. We also propose a method to eliminate this disparity. Experiments show that our model can learn a mean representation with much lower total correlation, hence a factorized mean representation. Moreover, we offer a detailed explanation of the limitations of factorizing aggregated posterior -- factor disintegration. Our work indicates a potential direction for future research of disentangled learning.
Semi-Supervised Recognition under a Noisy and Fine-grained Dataset
Jun 18, 2020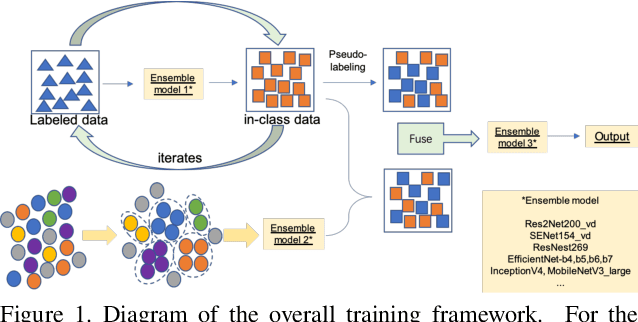
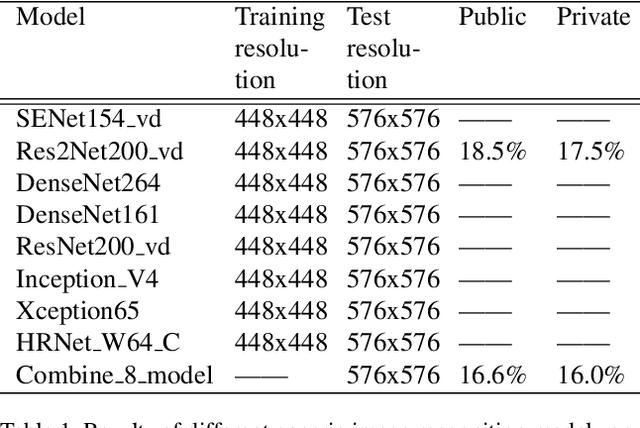
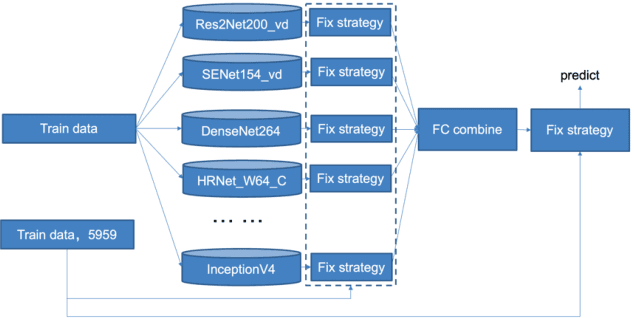
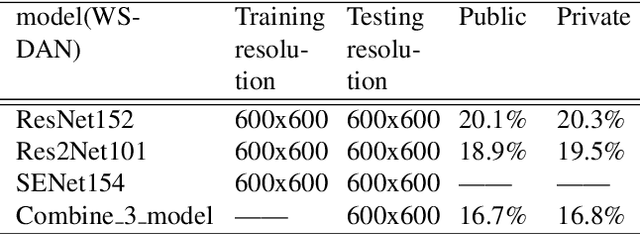
Simi-Supervised Recognition Challenge-FGVC7 is a challenging fine-grained recognition competition. One of the difficulties of this competition is how to use unlabeled data. We adopted pseudo-tag data mining to increase the amount of training data. The other one is how to identify similar birds with a very small difference, especially those have a relatively tiny main-body in examples. We combined generic image recognition and fine-grained image recognition method to solve the problem. All generic image recognition models were training using PaddleClas . Using the combination of two different ways of deep recognition models, we finally won the third place in the competition.
A Summary of the First Workshop on Language Technology for Language Documentation and Revitalization
Apr 27, 2020


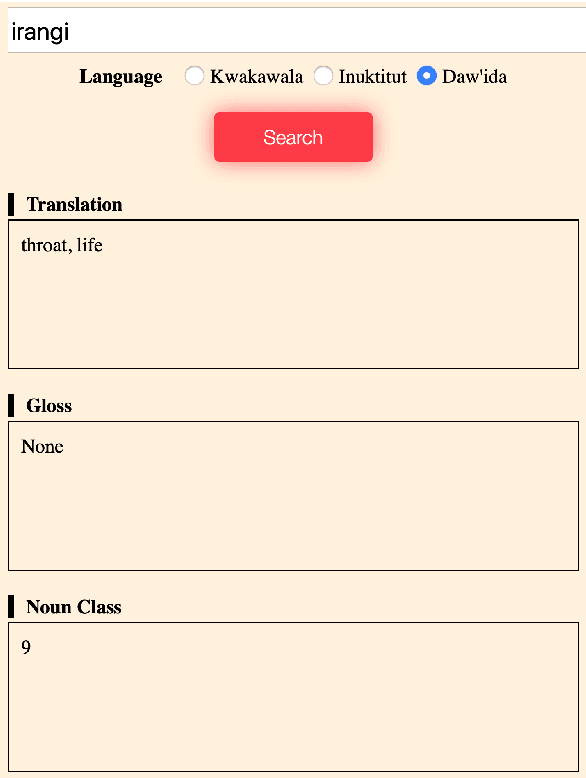
Despite recent advances in natural language processing and other language technology, the application of such technology to language documentation and conservation has been limited. In August 2019, a workshop was held at Carnegie Mellon University in Pittsburgh to attempt to bring together language community members, documentary linguists, and technologists to discuss how to bridge this gap and create prototypes of novel and practical language revitalization technologies. This paper reports the results of this workshop, including issues discussed, and various conceived and implemented technologies for nine languages: Arapaho, Cayuga, Inuktitut, Irish Gaelic, Kidaw'ida, Kwak'wala, Ojibwe, San Juan Quiahije Chatino, and Seneca.
AlloVera: A Multilingual Allophone Database
Apr 17, 2020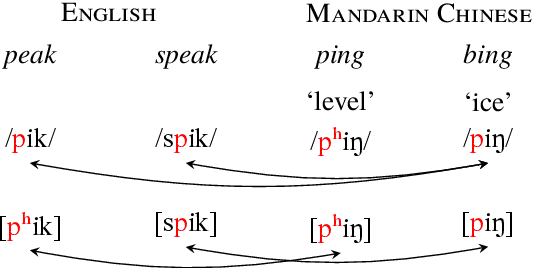
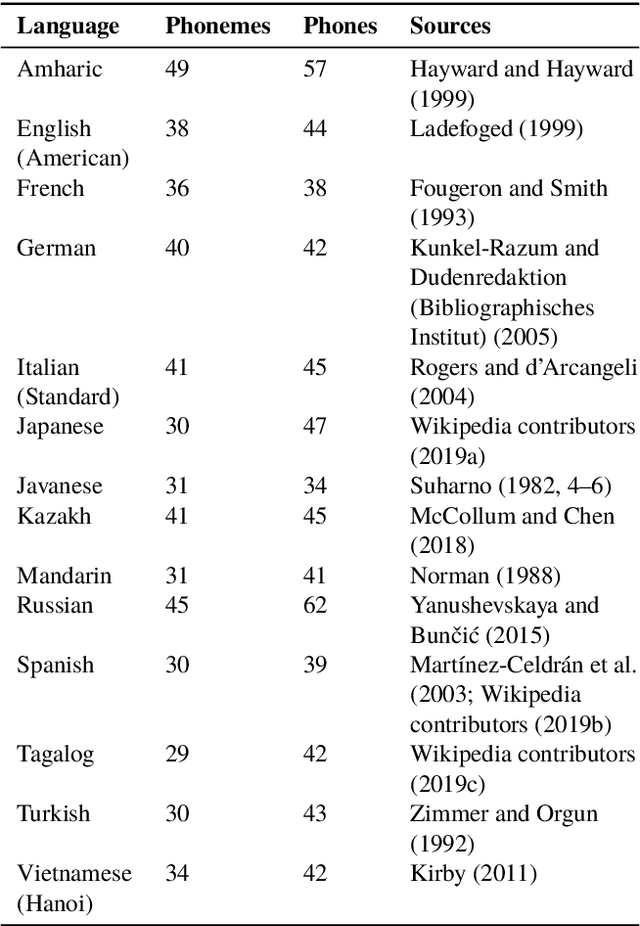


We introduce a new resource, AlloVera, which provides mappings from 218 allophones to phonemes for 14 languages. Phonemes are contrastive phonological units, and allophones are their various concrete realizations, which are predictable from phonological context. While phonemic representations are language specific, phonetic representations (stated in terms of (allo)phones) are much closer to a universal (language-independent) transcription. AlloVera allows the training of speech recognition models that output phonetic transcriptions in the International Phonetic Alphabet (IPA), regardless of the input language. We show that a "universal" allophone model, Allosaurus, built with AlloVera, outperforms "universal" phonemic models and language-specific models on a speech-transcription task. We explore the implications of this technology (and related technologies) for the documentation of endangered and minority languages. We further explore other applications for which AlloVera will be suitable as it grows, including phonological typology.
Universal Phone Recognition with a Multilingual Allophone System
Feb 26, 2020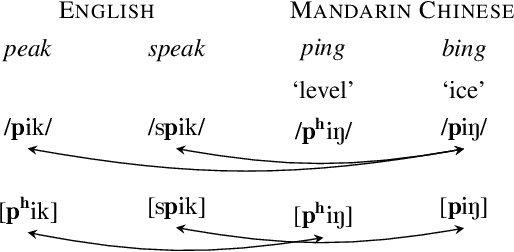

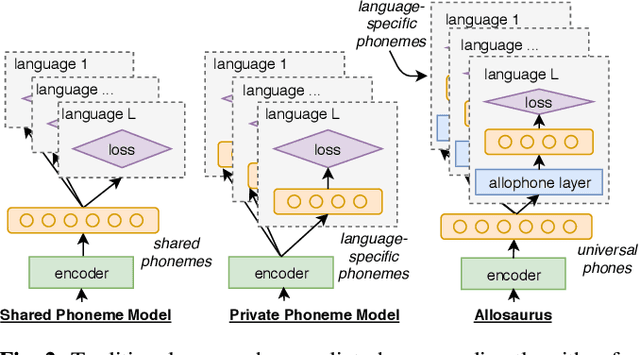

Multilingual models can improve language processing, particularly for low resource situations, by sharing parameters across languages. Multilingual acoustic models, however, generally ignore the difference between phonemes (sounds that can support lexical contrasts in a particular language) and their corresponding phones (the sounds that are actually spoken, which are language independent). This can lead to performance degradation when combining a variety of training languages, as identically annotated phonemes can actually correspond to several different underlying phonetic realizations. In this work, we propose a joint model of both language-independent phone and language-dependent phoneme distributions. In multilingual ASR experiments over 11 languages, we find that this model improves testing performance by 2% phoneme error rate absolute in low-resource conditions. Additionally, because we are explicitly modeling language-independent phones, we can build a (nearly-)universal phone recognizer that, when combined with the PHOIBLE large, manually curated database of phone inventories, can be customized into 2,000 language dependent recognizers. Experiments on two low-resourced indigenous languages, Inuktitut and Tusom, show that our recognizer achieves phone accuracy improvements of more than 17%, moving a step closer to speech recognition for all languages in the world.
Towards Zero-shot Learning for Automatic Phonemic Transcription
Feb 26, 2020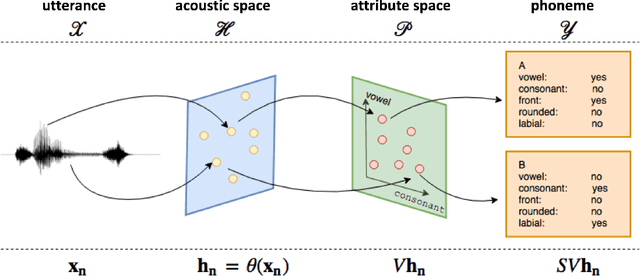
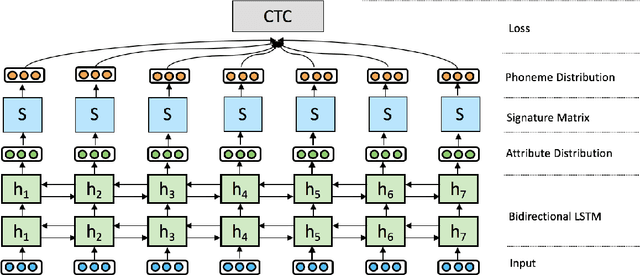
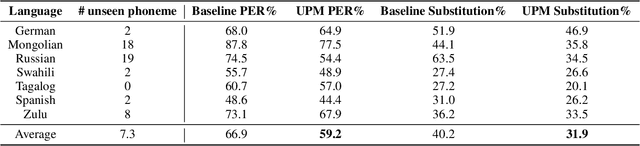
Automatic phonemic transcription tools are useful for low-resource language documentation. However, due to the lack of training sets, only a tiny fraction of languages have phonemic transcription tools. Fortunately, multilingual acoustic modeling provides a solution given limited audio training data. A more challenging problem is to build phonemic transcribers for languages with zero training data. The difficulty of this task is that phoneme inventories often differ between the training languages and the target language, making it infeasible to recognize unseen phonemes. In this work, we address this problem by adopting the idea of zero-shot learning. Our model is able to recognize unseen phonemes in the target language without any training data. In our model, we decompose phonemes into corresponding articulatory attributes such as vowel and consonant. Instead of predicting phonemes directly, we first predict distributions over articulatory attributes, and then compute phoneme distributions with a customized acoustic model. We evaluate our model by training it using 13 languages and testing it using 7 unseen languages. We find that it achieves 7.7% better phoneme error rate on average over a standard multilingual model.
Adversarial Music: Real World Audio Adversary Against Wake-word Detection System
Dec 06, 2019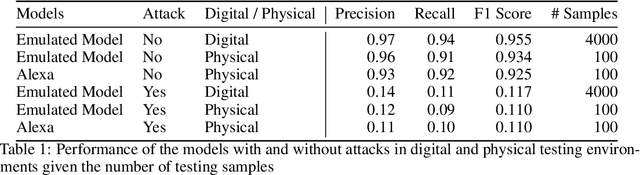
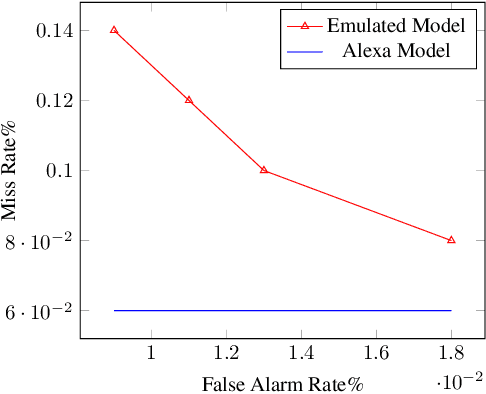

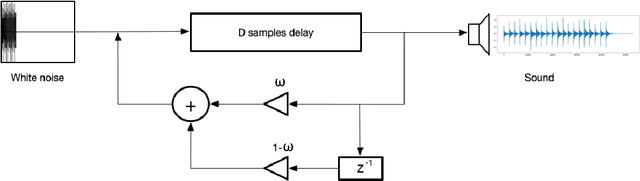
Voice Assistants (VAs) such as Amazon Alexa or Google Assistant rely on wake-word detection to respond to people's commands, which could potentially be vulnerable to audio adversarial examples. In this work, we target our attack on the wake-word detection system, jamming the model with some inconspicuous background music to deactivate the VAs while our audio adversary is present. We implemented an emulated wake-word detection system of Amazon Alexa based on recent publications. We validated our models against the real Alexa in terms of wake-word detection accuracy. Then we computed our audio adversaries with consideration of expectation over transform and we implemented our audio adversary with a differentiable synthesizer. Next, we verified our audio adversaries digitally on hundreds of samples of utterances collected from the real world. Our experiments show that we can effectively reduce the recognition F1 score of our emulated model from 93.4% to 11.0%. Finally, we tested our audio adversary over the air, and verified it works effectively against Alexa, reducing its F1 score from 92.5% to 11.0%.; We also verified that non-adversarial music does not disable Alexa as effectively as our music at the same sound level. To the best of our knowledge, this is the first real-world adversarial attack against a commercial-grade VA wake-word detection system. Our code and demo videos can be accessed at \url{https://www.junchengbillyli.com/AdversarialMusic}
* 9 pages, In Proceedings of NeurIPS 2019 Conference
SANTLR: Speech Annotation Toolkit for Low Resource Languages
Aug 02, 2019
While low resource speech recognition has attracted a lot of attention from the speech community, there are a few tools available to facilitate low resource speech collection. In this work, we present SANTLR: Speech Annotation Toolkit for Low Resource Languages. It is a web-based toolkit which allows researchers to easily collect and annotate a corpus of speech in a low resource language. Annotators may use this toolkit for two purposes: transcription or recording. In transcription, annotators would transcribe audio files provided by the researchers; in recording, annotators would record their voice by reading provided texts. We highlight two properties of this toolkit. First, SANTLR has a very user-friendly User Interface (UI). Both researchers and annotators may use this simple web interface to interact. There is no requirement for the annotators to have any expertise in audio or text processing. The toolkit would handle all preprocessing and postprocessing steps. Second, we employ a multi-step ranking mechanism facilitate the annotation process. In particular, the toolkit would give higher priority to utterances which are easier to annotate and are more beneficial to achieving the goal of the annotation, e.g. quickly training an acoustic model.