 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral-to-Specific Transfer Labeling for Domain Adaptable Keyphrase Generation
Aug 20, 2022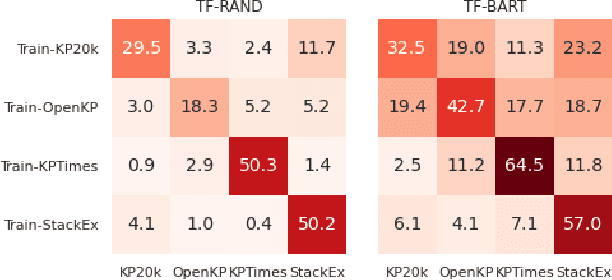
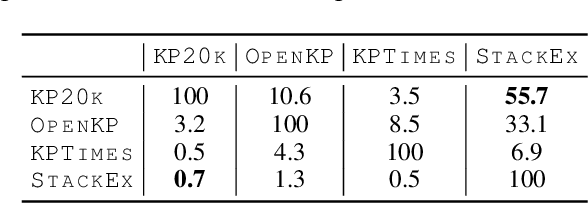
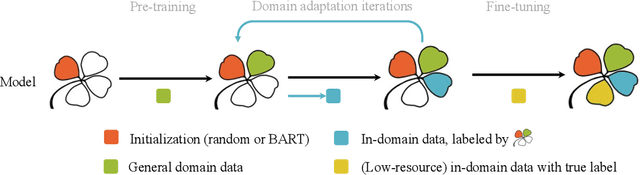
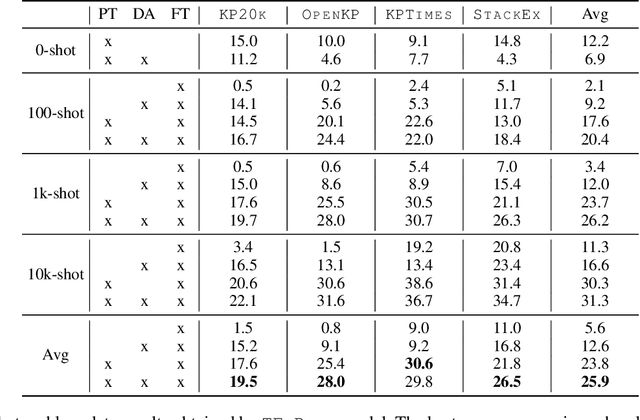
Training keyphrase generation (KPG) models requires a large amount of annotated data, which can be prohibitively expensive and often limited to specific domains. In this study, we first demonstrate that large distribution shifts among different domains severely hinder the transferability of KPG models. We then propose a three-stage pipeline, which gradually guides KPG models' learning focus from general syntactical features to domain-related semantics, in a data-efficient manner. With Domain-general Phrase pre-training, we pre-train Sequence-to-Sequence models with generic phrase annotations that are widely available on the web, which enables the models to generate phrases in a wide range of domains. The resulting model is then applied in the Transfer Labeling stage to produce domain-specific pseudo keyphrases, which help adapt models to a new domain. Finally, we fine-tune the model with limited data with true labels to fully adapt it to the target domain. Our experiment results show that the proposed process can produce good quality keyphrases in new domains and achieve consistent improvements after adaptation with limited in-domain annotated data.
Asking for Knowledge: Training RL Agents to Query External Knowledge Using Language
May 12, 2022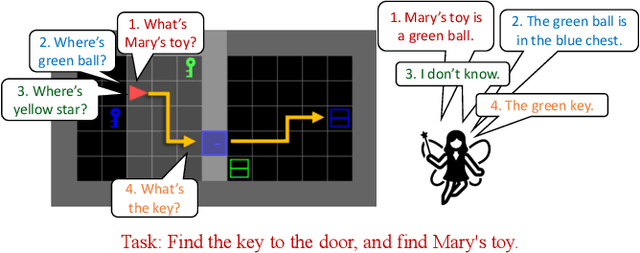
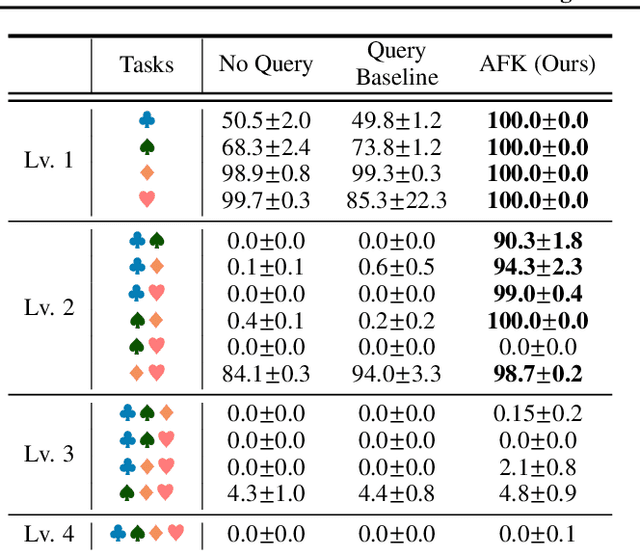


To solve difficult tasks, humans ask questions to acquire knowledge from external sources. In contrast, classical reinforcement learning agents lack such an ability and often resort to exploratory behavior. This is exacerbated as few present-day environments support querying for knowledge. In order to study how agents can be taught to query external knowledge via language, we first introduce two new environments: the grid-world-based Q-BabyAI and the text-based Q-TextWorld. In addition to physical interactions, an agent can query an external knowledge source specialized for these environments to gather information. Second, we propose the "Asking for Knowledge" (AFK) agent, which learns to generate language commands to query for meaningful knowledge that helps solve the tasks. AFK leverages a non-parametric memory, a pointer mechanism and an episodic exploration bonus to tackle (1) a large query language space, (2) irrelevant information, (3) delayed reward for making meaningful queries. Extensive experiments demonstrate that the AFK agent outperforms recent baselines on the challenging Q-BabyAI and Q-TextWorld environments.
One-Shot Learning from a Demonstration with Hierarchical Latent Language
Mar 09, 2022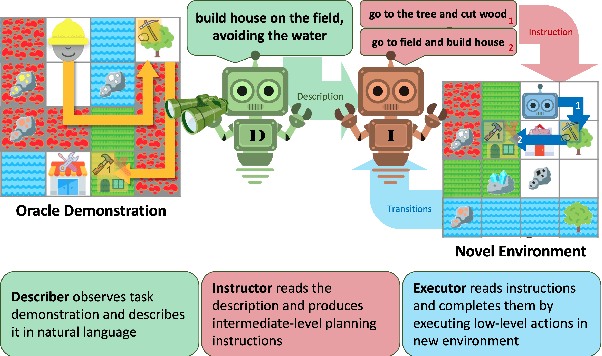
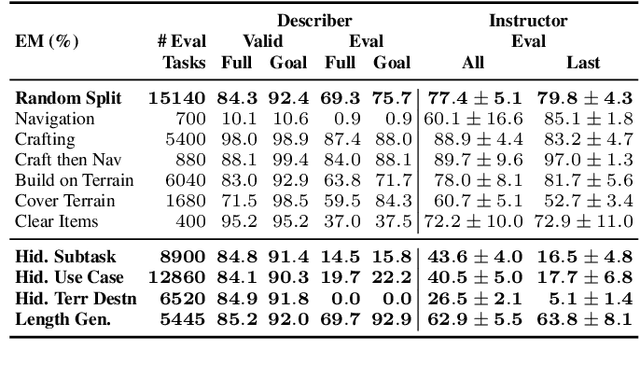
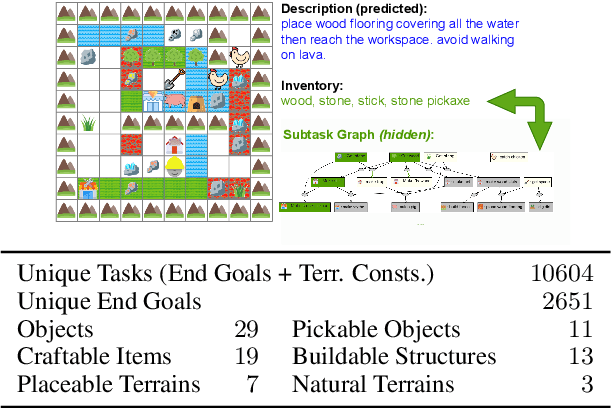
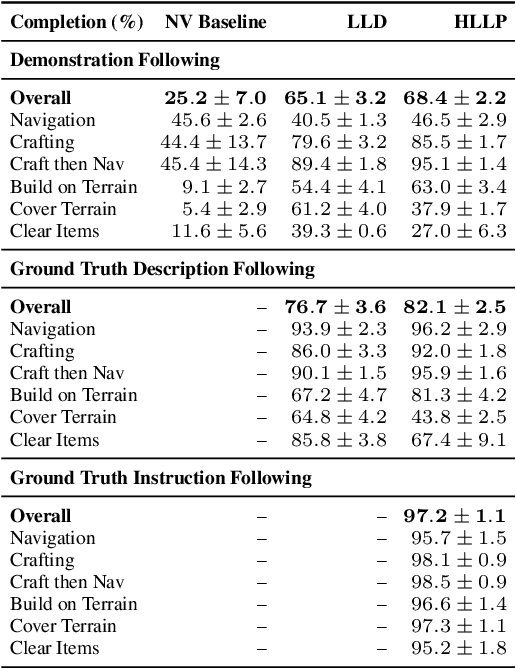
Humans have the capability, aided by the expressive compositionality of their language, to learn quickly by demonstration. They are able to describe unseen task-performing procedures and generalize their execution to other contexts. In this work, we introduce DescribeWorld, an environment designed to test this sort of generalization skill in grounded agents, where tasks are linguistically and procedurally composed of elementary concepts. The agent observes a single task demonstration in a Minecraft-like grid world, and is then asked to carry out the same task in a new map. To enable such a level of generalization, we propose a neural agent infused with hierarchical latent language--both at the level of task inference and subtask planning. Our agent first generates a textual description of the demonstrated unseen task, then leverages this description to replicate it. Through multiple evaluation scenarios and a suite of generalization tests, we find that agents that perform text-based inference are better equipped for the challenge under a random split of tasks.
Interactive Machine Comprehension with Dynamic Knowledge Graphs
Aug 31, 2021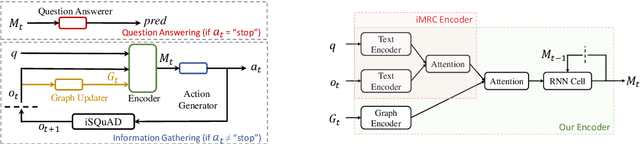
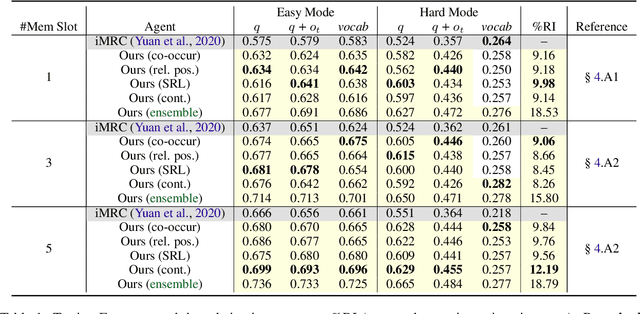
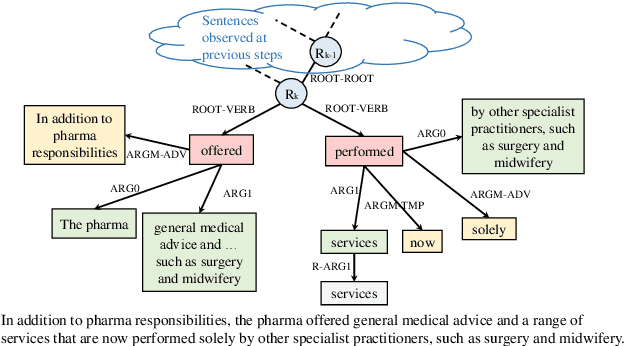
Interactive machine reading comprehension (iMRC) is machine comprehension tasks where knowledge sources are partially observable. An agent must interact with an environment sequentially to gather necessary knowledge in order to answer a question. We hypothesize that graph representations are good inductive biases, which can serve as an agent's memory mechanism in iMRC tasks. We explore four different categories of graphs that can capture text information at various levels. We describe methods that dynamically build and update these graphs during information gathering, as well as neural models to encode graph representations in RL agents. Extensive experiments on iSQuAD suggest that graph representations can result in significant performance improvements for RL agents.
Bringing Structure into Summaries: a Faceted Summarization Dataset for Long Scientific Documents
Jun 23, 2021
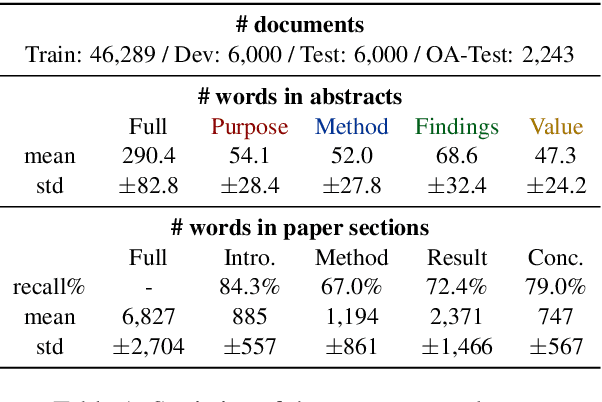

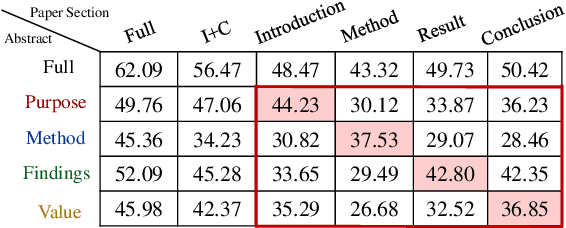
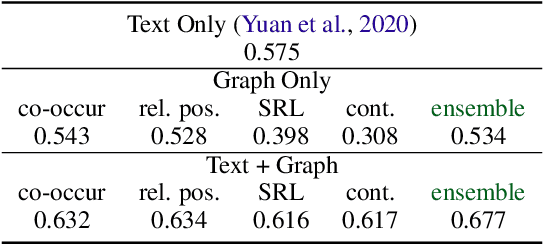
Faceted summarization provides briefings of a document from different perspectives. Readers can quickly comprehend the main points of a long document with the help of a structured outline. However, little research has been conducted on this subject, partially due to the lack of large-scale faceted summarization datasets. In this study, we present FacetSum, a faceted summarization benchmark built on Emerald journal articles, covering a diverse range of domains. Different from traditional document-summary pairs, FacetSum provides multiple summaries, each targeted at specific sections of a long document, including the purpose, method, findings, and value. Analyses and empirical results on our dataset reveal the importance of bringing structure into summaries. We believe FacetSum will spur further advances in summarization research and foster the development of NLP systems that can leverage the structured information in both long texts and summaries.
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Oct 08, 2020
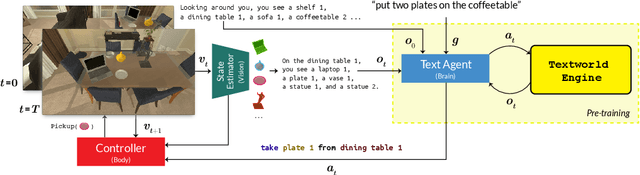

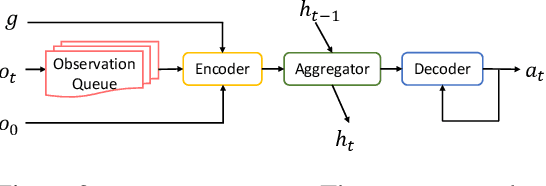
Given a simple request (e.g., Put a washed apple in the kitchen fridge), humans can reason in purely abstract terms by imagining action sequences and scoring their likelihood of success, prototypicality, and efficiency, all without moving a muscle. Once we see the kitchen in question, we can update our abstract plans to fit the scene. Embodied agents require the same abilities, but existing work does not yet provide the infrastructure necessary for both reasoning abstractly and executing concretely. We address this limitation by introducing ALFWorld, a simulator that enables agents to learn abstract, text-based policies in TextWorld (C\^ot\'e et al., 2018) and then execute goals from the ALFRED benchmark (Shridhar et al., 2020) in a rich visual environment. ALFWorld enables the creation of a new BUTLER agent whose abstract knowledge, learned in TextWorld, corresponds directly to concrete, visually grounded actions. In turn, as we demonstrate empirically, this fosters better agent generalization than training only in the visually grounded environment. BUTLER's simple, modular design factors the problem to allow researchers to focus on models for improving every piece of the pipeline (language understanding, planning, navigation, visual scene understanding, and so forth).
An Empirical Study on Neural Keyphrase Generation
Sep 22, 2020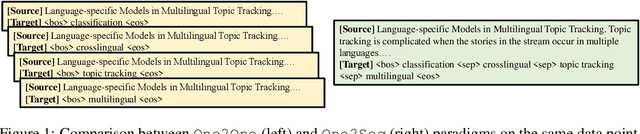
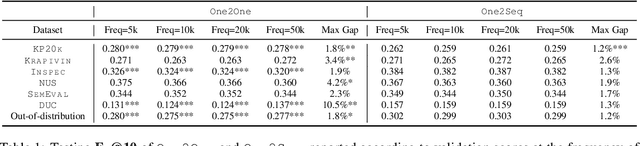
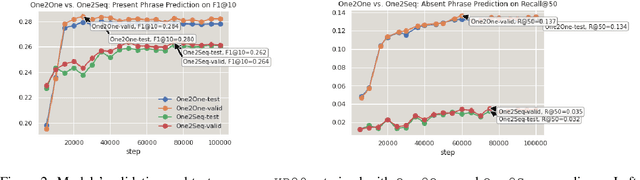
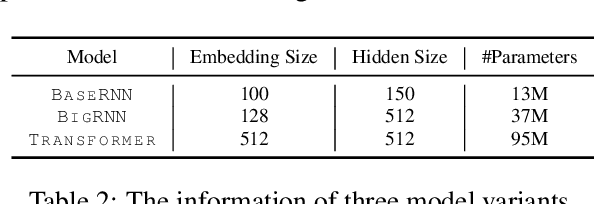
Recent years have seen a flourishing of neural keyphrase generation works, including the release of several large-scale datasets and a host of new models to tackle them. Model performance on keyphrase generation tasks has increased significantly with evolving deep learning research. However, there lacks a comprehensive comparison among models, and an investigation on related factors (e.g., architectural choice, decoding strategy) that may affect a keyphrase generation system's performance. In this empirical study, we aim to fill this gap by providing extensive experimental results and analyzing the most crucial factors impacting the performance of keyphrase generation models. We hope this study can help clarify some of the uncertainties surrounding the keyphrase generation task and facilitate future research on this topic.
Graph Policy Network for Transferable Active Learning on Graphs
Jun 24, 2020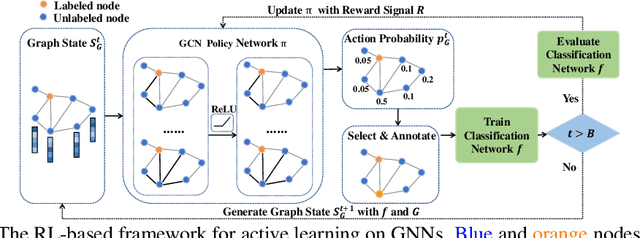
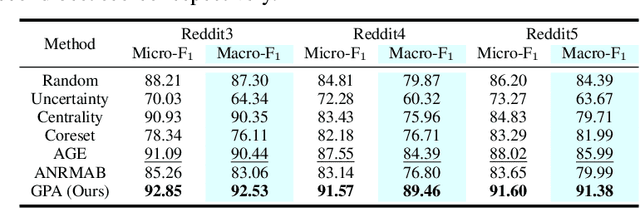
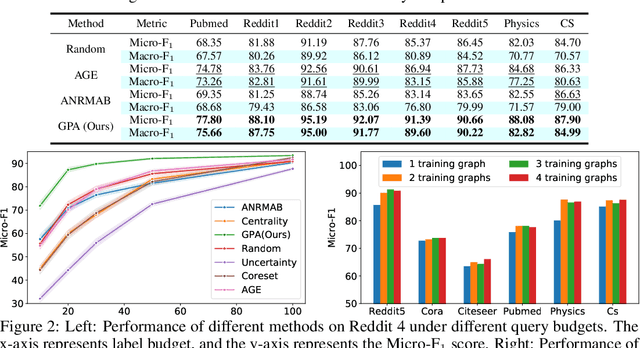

Graph neural networks (GNNs) have been attracting increasing popularity due to their simplicity and effectiveness in a variety of fields. However, a large number of labeled data is generally required to train these networks, which could be very expensive to obtain in some domains. In this paper, we study active learning for GNNs, i.e., how to efficiently label the nodes on a graph to reduce the annotation cost of training GNNs. We formulate the problem as a sequential decision process on graphs and train a GNN-based policy network with reinforcement learning to learn the optimal query strategy. By jointly optimizing over several source graphs with full labels, we learn a transferable active learning policy which can directly generalize to unlabeled target graphs under a zero-shot transfer setting. Experimental results on multiple graphs from different domains prove the effectiveness of our proposed approach in both settings of transferring between graphs in the same domain and across different domains.
Role-Wise Data Augmentation for Knowledge Distillation
Apr 19, 2020
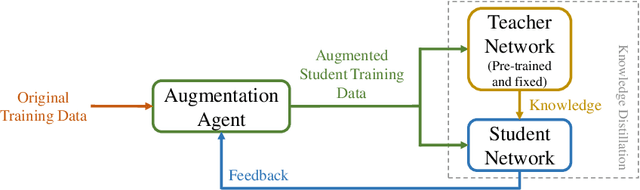
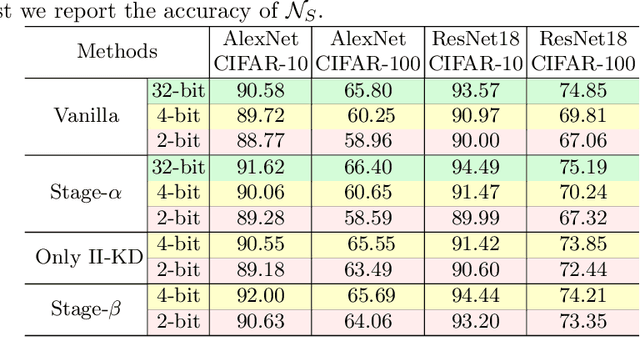

Knowledge Distillation (KD) is a common method for transferring the ``knowledge'' learned by one machine learning model (the \textit{teacher}) into another model (the \textit{student}), where typically, the teacher has a greater capacity (e.g., more parameters or higher bit-widths). To our knowledge, existing methods overlook the fact that although the student absorbs extra knowledge from the teacher, both models share the same input data -- and this data is the only medium by which the teacher's knowledge can be demonstrated. Due to the difference in model capacities, the student may not benefit fully from the same data points on which the teacher is trained. On the other hand, a human teacher may demonstrate a piece of knowledge with individualized examples adapted to a particular student, for instance, in terms of her cultural background and interests. Inspired by this behavior, we design data augmentation agents with distinct roles to facilitate knowledge distillation. Our data augmentation agents generate distinct training data for the teacher and student, respectively. We find empirically that specially tailored data points enable the teacher's knowledge to be demonstrated more effectively to the student. We compare our approach with existing KD methods on training popular neural architectures and demonstrate that role-wise data augmentation improves the effectiveness of KD over strong prior approaches. The code for reproducing our results can be found at https://github.com/bigaidream-projects/role-kd
Learning Dynamic Knowledge Graphs to Generalize on Text-Based Games
Feb 21, 2020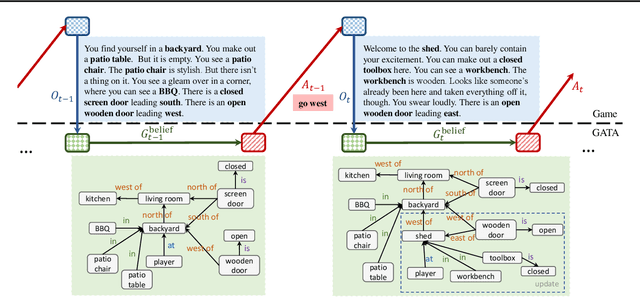

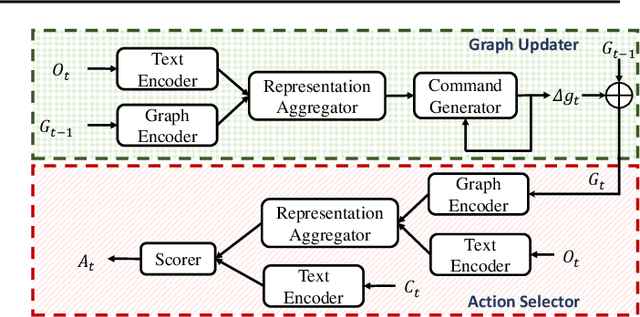
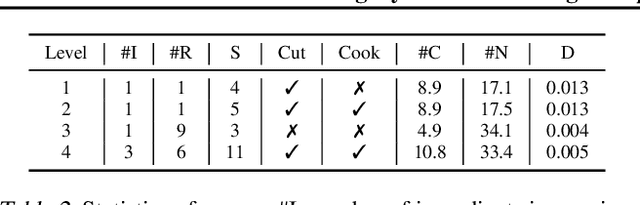
Playing text-based games requires skill in processing natural language and in planning. Although a key goal for agents solving this task is to generalize across multiple games, most previous work has either focused on solving a single game or has tackled generalization with rule-based heuristics. In this work, we investigate how structured information in the form of a knowledge graph (KG) can facilitate effective planning and generalization. We introduce a novel transformer-based sequence-to-sequence model that constructs a "belief" KG from raw text observations of the environment, dynamically updating this belief graph at every game step as it receives new observations. To train this model to build useful graph representations, we introduce and analyze a set of graph-related pre-training tasks. We demonstrate empirically that KG-based representations from our model help agents to converge faster to better policies for multiple text-based games, and further, enable stronger zero-shot performance on unseen games. Experiments on unseen games show that our best agent outperforms text-based baselines by 21.6%.