 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Knowledge Enhancement for Zero-Shot and Multi-Domain Recommendation in an AI Assistant Application
Jun 09, 2023Recommender systems have found significant commercial success but still struggle with integrating new users. Since users often interact with content in different domains, it is possible to leverage a user's interactions in previous domains to improve that user's recommendations in a new one (multi-domain recommendation). A separate research thread on knowledge graph enhancement uses external knowledge graphs to improve single domain recommendations (knowledge graph enhancement). Both research threads incorporate related information to improve predictions in a new domain. We propose in this work to unify these approaches: Using information from interactions in other domains as well as external knowledge graphs to make predictions in a new domain that would be impossible with either information source alone. We apply these ideas to a dataset derived from millions of users' requests for content across three domains (videos, music, and books) in a live virtual assistant application. We demonstrate the advantage of combining knowledge graph enhancement with previous multi-domain recommendation techniques to provide better overall recommendations as well as for better recommendations on new users of a domain.
KG-ECO: Knowledge Graph Enhanced Entity Correction for Query Rewriting
Feb 22, 2023



Query Rewriting (QR) plays a critical role in large-scale dialogue systems for reducing frictions. When there is an entity error, it imposes extra challenges for a dialogue system to produce satisfactory responses. In this work, we propose KG-ECO: Knowledge Graph enhanced Entity COrrection for query rewriting, an entity correction system with corrupt entity span detection and entity retrieval/re-ranking functionalities. To boost the model performance, we incorporate Knowledge Graph (KG) to provide entity structural information (neighboring entities encoded by graph neural networks) and textual information (KG entity descriptions encoded by RoBERTa). Experimental results show that our approach yields a clear performance gain over two baselines: utterance level QR and entity correction without utilizing KG information. The proposed system is particularly effective for few-shot learning cases where target entities are rarely seen in training or there is a KG relation between the target entity and other contextual entities in the query.
Robust Regularized Low-Rank Matrix Models for Regression and Classification
May 14, 2022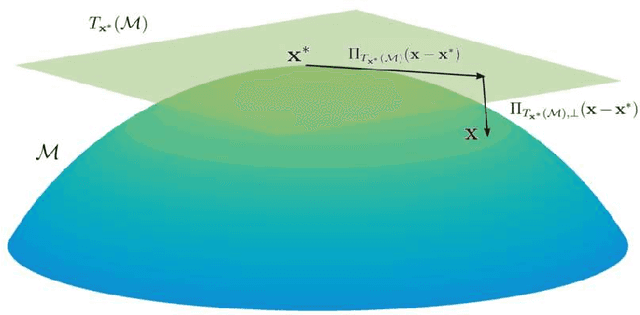
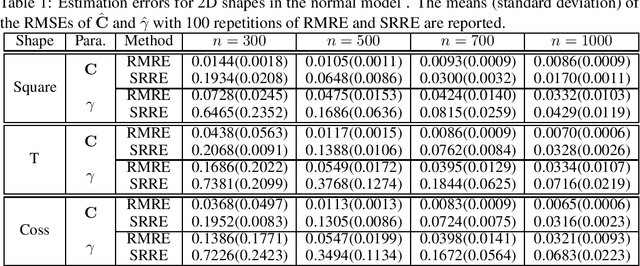
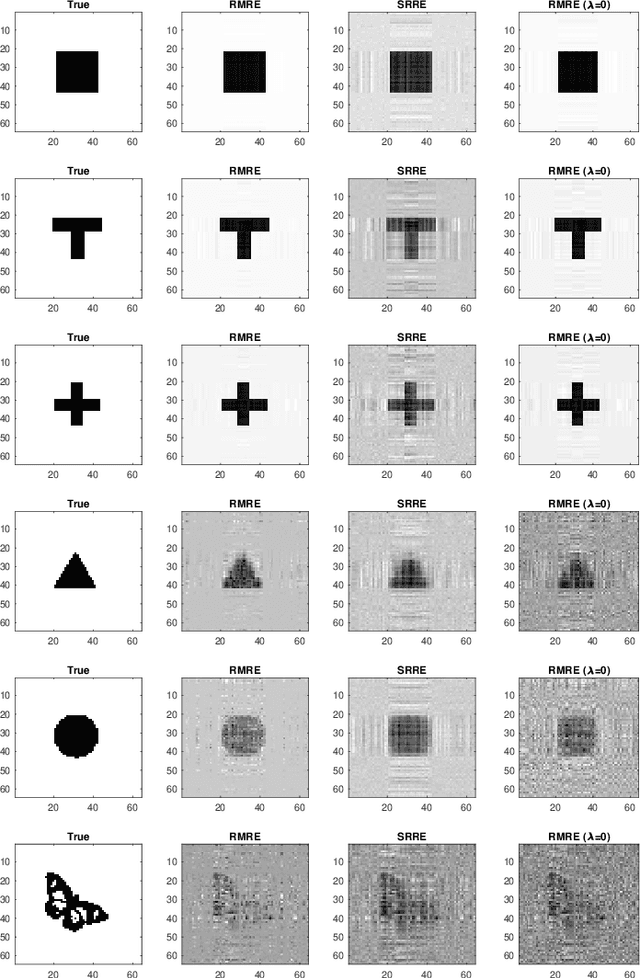
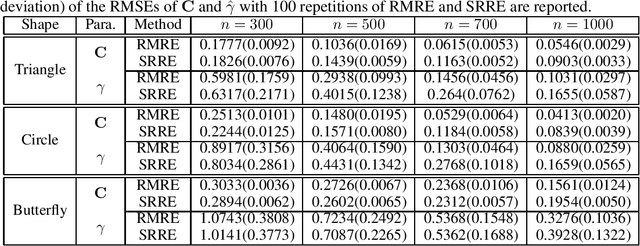
While matrix variate regression models have been studied in many existing works, classical statistical and computational methods for the analysis of the regression coefficient estimation are highly affected by high dimensional and noisy matrix-valued predictors. To address these issues, this paper proposes a framework of matrix variate regression models based on a rank constraint, vector regularization (e.g., sparsity), and a general loss function with three special cases considered: ordinary matrix regression, robust matrix regression, and matrix logistic regression. We also propose an alternating projected gradient descent algorithm. Based on analyzing our objective functions on manifolds with bounded curvature, we show that the algorithm is guaranteed to converge, all accumulation points of the iterates have estimation errors in the order of $O(1/\sqrt{n})$ asymptotically and substantially attaining the minimax rate. Our theoretical analysis can be applied to general optimization problems on manifolds with bounded curvature and can be considered an important technical contribution to this work. We validate the proposed method through simulation studies and real image data examples.
Learning to Selectively Learn for Weakly-supervised Paraphrase Generation
Sep 25, 2021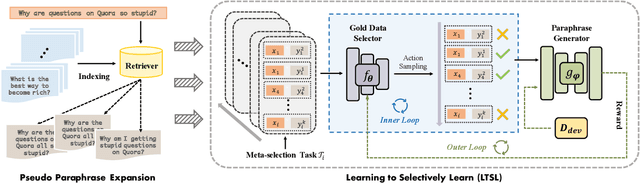
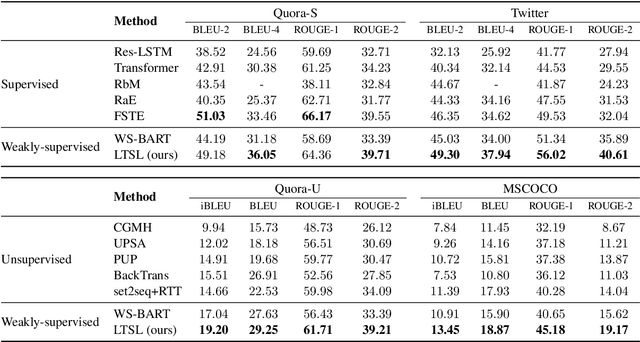
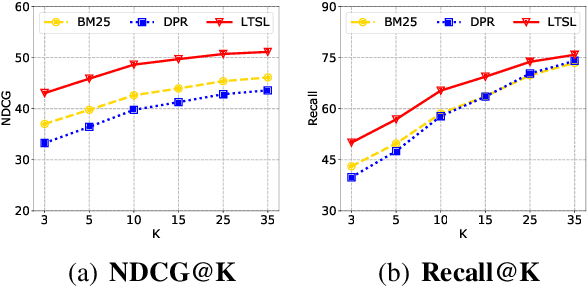
Paraphrase generation is a longstanding NLP task that has diverse applications for downstream NLP tasks. However, the effectiveness of existing efforts predominantly relies on large amounts of golden labeled data. Though unsupervised endeavors have been proposed to address this issue, they may fail to generate meaningful paraphrases due to the lack of supervision signals. In this work, we go beyond the existing paradigms and propose a novel approach to generate high-quality paraphrases with weak supervision data. Specifically, we tackle the weakly-supervised paraphrase generation problem by: (1) obtaining abundant weakly-labeled parallel sentences via retrieval-based pseudo paraphrase expansion; and (2) developing a meta-learning framework to progressively select valuable samples for fine-tuning a pre-trained language model, i.e., BART, on the sentential paraphrasing task. We demonstrate that our approach achieves significant improvements over existing unsupervised approaches, and is even comparable in performance with supervised state-of-the-arts.
ALMA: Alternating Minimization Algorithm for Clustering Mixture Multilayer Network
Mar 08, 2021
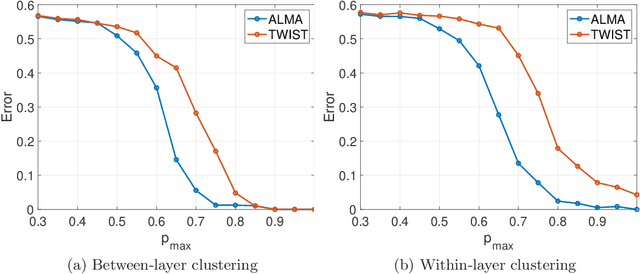
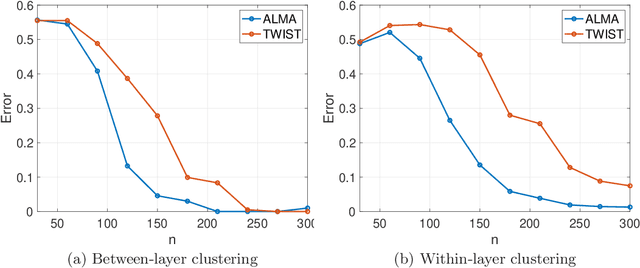
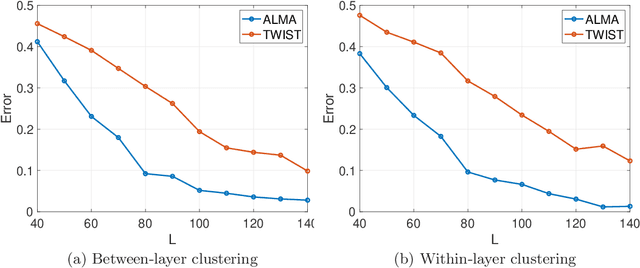
The paper considers a Mixture Multilayer Stochastic Block Model (MMLSBM), where layers can be partitioned into groups of similar networks, and networks in each group are equipped with a distinct Stochastic Block Model. The goal is to partition the multilayer network into clusters of similar layers, and to identify communities in those layers. Jing et al. (2020) introduced the MMLSBM and developed a clustering methodology, TWIST, based on regularized tensor decomposition. The present paper proposes a different technique, an alternating minimization algorithm (ALMA), that aims at simultaneous recovery of the layer partition, together with estimation of the matrices of connection probabilities of the distinct layers. Compared to TWIST, ALMA achieves higher accuracy both theoretically and numerically.
Pattern-aware Data Augmentation for Query Rewriting in Voice Assistant Systems
Dec 21, 2020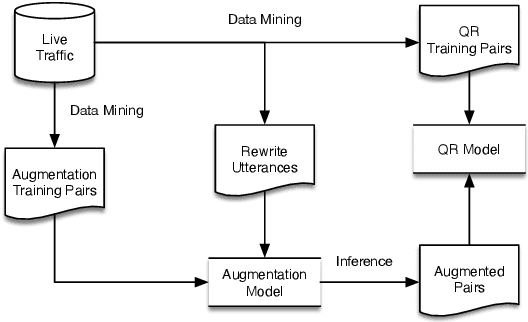
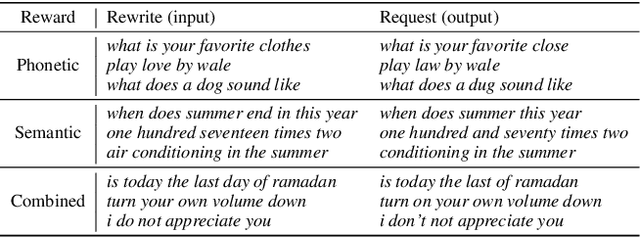
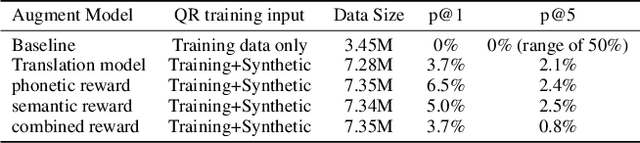
Query rewriting (QR) systems are widely used to reduce the friction caused by errors in a spoken language understanding pipeline. However, the underlying supervised models require a large number of labeled pairs, and these pairs are hard and costly to be collected. Therefore, We propose an augmentation framework that learns patterns from existing training pairs and generates rewrite candidates from rewrite labels inversely to compensate for insufficient QR training data. The proposed framework casts the augmentation problem as a sequence-to-sequence generation task and enforces the optimization process with a policy gradient technique for controllable rewarding. This approach goes beyond the traditional heuristics or rule-based augmentation methods and is not constrained to generate predefined patterns of swapping/replacing words. Our experimental results show its effectiveness compared with a fully trained QR baseline and demonstrate its potential application in boosting the QR performance on low-resource domains or locales.
Cross-Spectrum Dual-Subspace Pairing for RGB-infrared Cross-Modality Person Re-Identification
Feb 29, 2020

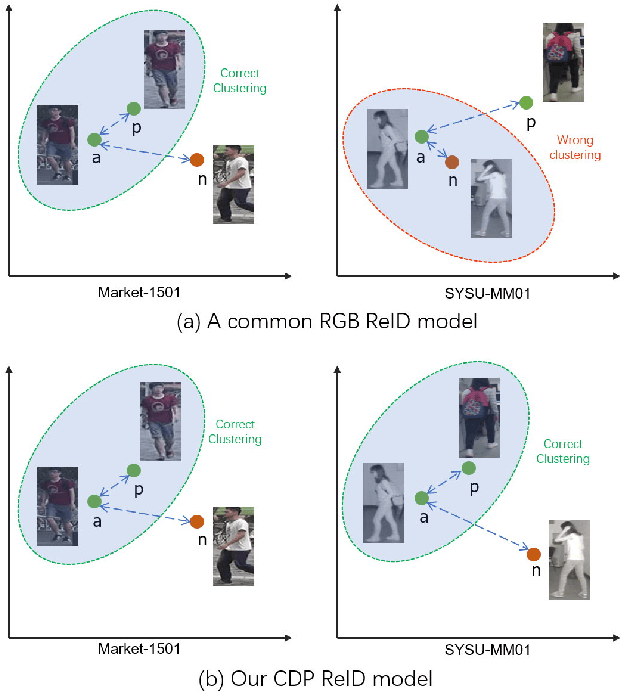

Due to its potential wide applications in video surveillance and other computer vision tasks like tracking, person re-identification (ReID) has become popular and been widely investigated. However, conventional person re-identification can only handle RGB color images, which will fail at dark conditions. Thus RGB-infrared ReID (also known as Infrared-Visible ReID or Visible-Thermal ReID) is proposed. Apart from appearance discrepancy in traditional ReID caused by illumination, pose variations and viewpoint changes, modality discrepancy produced by cameras of the different spectrum also exists, which makes RGB-infrared ReID more difficult. To address this problem, we focus on extracting the shared cross-spectrum features of different modalities. In this paper, a novel multi-spectrum image generation method is proposed and the generated samples are utilized to help the network to find discriminative information for re-identifying the same person across modalities. Another challenge of RGB-infrared ReID is that the intra-person (images from the same person) discrepancy is often larger than the inter-person (images from different persons) discrepancy, so a dual-subspace pairing strategy is proposed to alleviate this problem. Combining those two parts together, we also design a one-stream neural network combining the aforementioned methods to extract compact representations of person images, called Cross-spectrum Dual-subspace Pairing (CDP) model. Furthermore, during the training process, we also propose a Dynamic Hard Spectrum Mining method to automatically mine more hard samples from hard spectrum based on the current model state to further boost the performance. Extensive experimental results on two public datasets, SYSU-MM01 with RGB + near-infrared images and RegDB with RGB + far-infrared images, have demonstrated the efficiency and generality of our proposed method.
Pre-Training for Query Rewriting in A Spoken Language Understanding System
Feb 13, 2020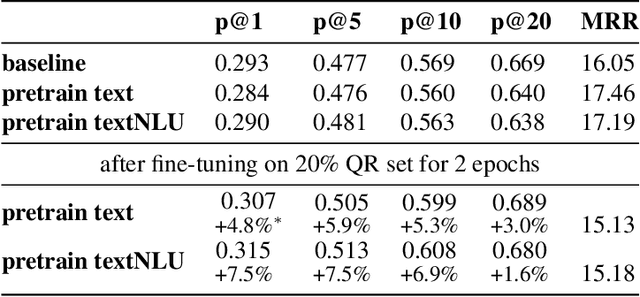
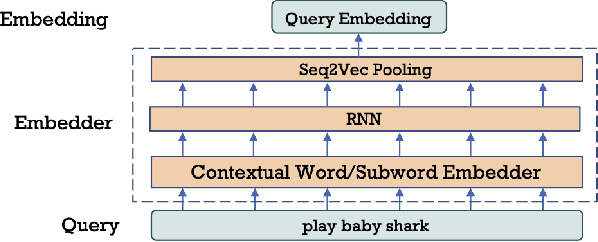
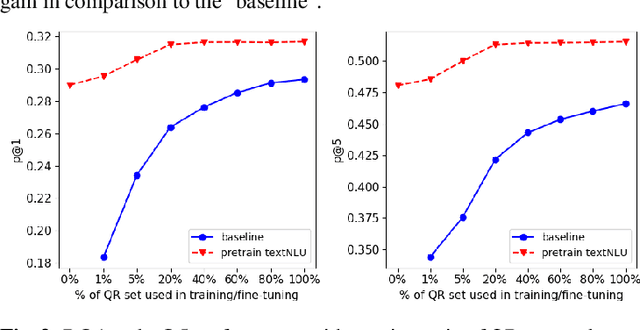
Query rewriting (QR) is an increasingly important technique to reduce customer friction caused by errors in a spoken language understanding pipeline, where the errors originate from various sources such as speech recognition errors, language understanding errors or entity resolution errors. In this work, we first propose a neural-retrieval based approach for query rewriting. Then, inspired by the wide success of pre-trained contextual language embeddings, and also as a way to compensate for insufficient QR training data, we propose a language-modeling (LM) based approach to pre-train query embeddings on historical user conversation data with a voice assistant. In addition, we propose to use the NLU hypotheses generated by the language understanding system to augment the pre-training. Our experiments show pre-training provides rich prior information and help the QR task achieve strong performance. We also show joint pre-training with NLU hypotheses has further benefit. Finally, after pre-training, we find a small set of rewrite pairs is enough to fine-tune the QR model to outperform a strong baseline by full training on all QR training data.
Knowledge Distillation from Internal Representations
Oct 08, 2019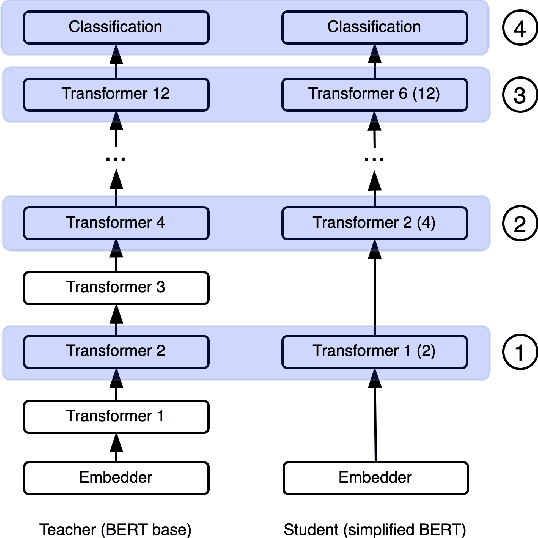
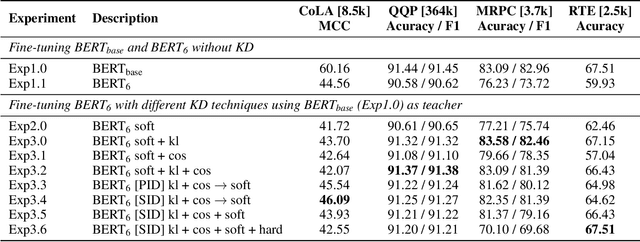
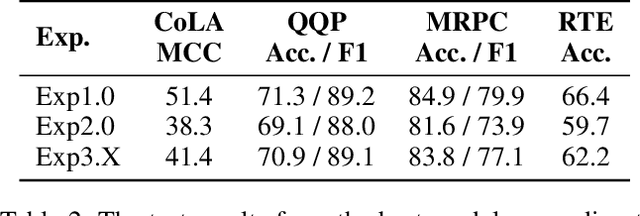
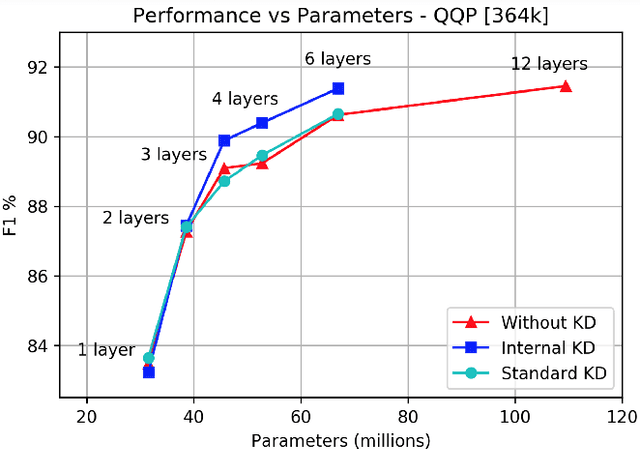
Knowledge distillation is typically conducted by training a small model (the student) to mimic a large and cumbersome model (the teacher). The idea is to compress the knowledge from the teacher by using its output probabilities as soft-labels to optimize the student. However, when the teacher is considerably large, there is no guarantee that the internal knowledge of the teacher will be transferred into the student; even if the student closely matches the soft-labels, its internal representations may be considerably different. This internal mismatch can undermine the generalization capabilities originally intended to be transferred from the teacher to the student. In this paper, we propose to distill the internal representations of a large model such as BERT into a simplified version of it. We formulate two ways to distill such representations and various algorithms to conduct the distillation. We experiment with datasets from the GLUE benchmark and consistently show that adding knowledge distillation from internal representations is a more powerful method than only using soft-label distillation.
STNReID : Deep Convolutional Networks with Pairwise Spatial Transformer Networks for Partial Person Re-identification
Mar 17, 2019
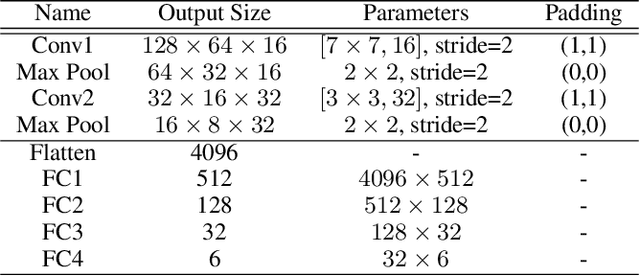
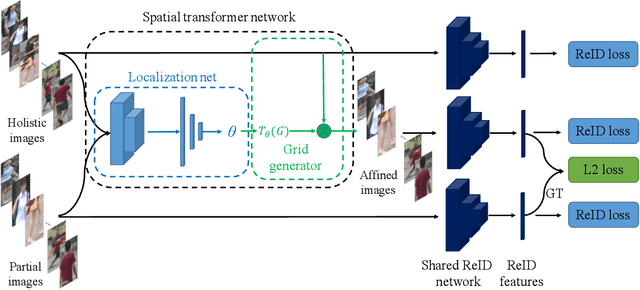
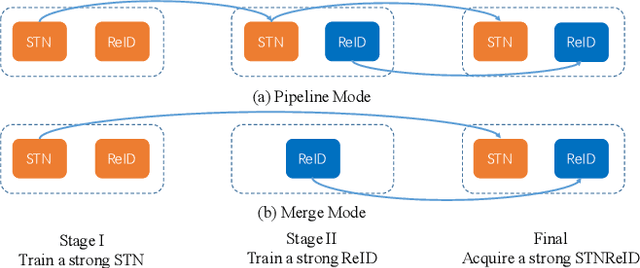
Partial person re-identification (ReID) is a challenging task because only partial information of person images is available for matching target persons. Few studies, especially on deep learning, have focused on matching partial person images with holistic person images. This study presents a novel deep partial ReID framework based on pairwise spatial transformer networks (STNReID), which can be trained on existing holistic person datasets. STNReID includes a spatial transformer network (STN) module and a ReID module. The STN module samples an affined image (a semantically corresponding patch) from the holistic image to match the partial image. The ReID module extracts the features of the holistic, partial, and affined images. Competition (or confrontation) is observed between the STN module and the ReID module, and two-stage training is applied to acquire a strong STNReID for partial ReID. Experimental results show that our STNReID obtains 66.7% and 54.6% rank-1 accuracies on partial ReID and partial iLIDS datasets, respectively. These values are at par with those obtained with state-of-the-art methods.