 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Deep Learning Models Against Semantic-Preserving Adversarial Attack
Apr 08, 2023



Deep learning models can be fooled by small $l_p$-norm adversarial perturbations and natural perturbations in terms of attributes. Although the robustness against each perturbation has been explored, it remains a challenge to address the robustness against joint perturbations effectively. In this paper, we study the robustness of deep learning models against joint perturbations by proposing a novel attack mechanism named Semantic-Preserving Adversarial (SPA) attack, which can then be used to enhance adversarial training. Specifically, we introduce an attribute manipulator to generate natural and human-comprehensible perturbations and a noise generator to generate diverse adversarial noises. Based on such combined noises, we optimize both the attribute value and the diversity variable to generate jointly-perturbed samples. For robust training, we adversarially train the deep learning model against the generated joint perturbations. Empirical results on four benchmarks show that the SPA attack causes a larger performance decline with small $l_{\infty}$ norm-ball constraints compared to existing approaches. Furthermore, our SPA-enhanced training outperforms existing defense methods against such joint perturbations.
MiniRBT: A Two-stage Distilled Small Chinese Pre-trained Model
Apr 03, 2023



In natural language processing, pre-trained language models have become essential infrastructures. However, these models often suffer from issues such as large size, long inference time, and challenging deployment. Moreover, most mainstream pre-trained models focus on English, and there are insufficient studies on small Chinese pre-trained models. In this paper, we introduce MiniRBT, a small Chinese pre-trained model that aims to advance research in Chinese natural language processing. MiniRBT employs a narrow and deep student model and incorporates whole word masking and two-stage distillation during pre-training to make it well-suited for most downstream tasks. Our experiments on machine reading comprehension and text classification tasks reveal that MiniRBT achieves 94% performance relative to RoBERTa, while providing a 6.8x speedup, demonstrating its effectiveness and efficiency.
Multi-Objective Archiving
Mar 16, 2023Most multi-objective optimisation algorithms maintain an archive explicitly or implicitly during their search. Such an archive can be solely used to store high-quality solutions presented to the decision maker, but in many cases may participate in the search process (e.g., as the population in evolutionary computation). Over the last two decades, archiving, the process of comparing new solutions with previous ones and deciding how to update the archive/population, stands as an important issue in evolutionary multi-objective optimisation (EMO). This is evidenced by constant efforts from the community on developing various effective archiving methods, ranging from conventional Pareto-based methods to more recent indicator-based and decomposition-based ones. However, the focus of these efforts is on empirical performance comparison in terms of specific quality indicators; there is lack of systematic study of archiving methods from a general theoretical perspective. In this paper, we attempt to conduct a systematic overview of multi-objective archiving, in the hope of paving the way to understand archiving algorithms from a holistic perspective of theory and practice, and more importantly providing a guidance on how to design theoretically desirable and practically useful archiving algorithms. In doing so, we also present that archiving algorithms based on weakly Pareto compliant indicators (e.g., epsilon-indicator), as long as designed properly, can achieve the same theoretical desirables as archivers based on Pareto compliant indicators (e.g., hypervolume indicator). Such desirables include the property limit-optimal, the limit form of the possible optimal property that a bounded archiving algorithm can have with respect to the most general form of superiority between solution sets.
Gradient-based Intra-attention Pruning on Pre-trained Language Models
Dec 15, 2022



Pre-trained language models achieve superior performance, but they are computationally expensive due to their large size. Techniques such as pruning and knowledge distillation (KD) have been developed to reduce their size and latency. In most structural pruning methods, the pruning units, such as attention heads and feed-forward hidden dimensions, only span a small model structure space and limit the structures that the pruning algorithm can explore. In this work, we propose Gradient-based Intra-attention pruning (GRAIN), which inspects fine intra-attention structures, and allows different heads to have different sizes. Intra-attention pruning greatly expands the searching space of model structures and yields highly heterogeneous structures. We further propose structure regularization to encourage generating more regular structures, which achieves higher speedups than heterogeneous ones. We also integrate KD into the pruning process with a gradient separation strategy to reduce the interference of KD with the pruning process. GRAIN is evaluated on a variety of tasks. Results show that it notably outperforms other methods at the same or similar model size. Even under extreme compression where only $3\%$ weights in transformers remain, the pruned model is still competitive.
Differentiated Federated Reinforcement Learning for Dynamic and Heterogeneous Network
Dec 05, 2022



The modern dynamic and heterogeneous network brings differential environments with respective state transition probability to agents, which leads to the local strategy trap problem of traditional federated reinforcement learning (FRL) based network optimization algorithm. To solve this problem, we propose a novel Differentiated Federated Reinforcement Learning (DFRL), which evolves the global policy model integration and local inference with the global policy model in traditional FRL to a collaborative learning process with parallel global trends learning and differential local policy model learning. In the DFRL, the local policy learning model is adaptively updated with the global trends model and local environment and achieves better differentiated adaptation. We evaluate the outperformance of the proposal compared with the state-of-the-art FRL in a classical CartPole game with heterogeneous environments. Furthermore, we implement the proposal in the heterogeneous Space-air-ground Integrated Network (SAGIN) for the classical traffic offloading problem in network. The simulation result shows that the proposal shows better global performance and fairness than baselines in terms of throughput, delay, and packet drop rate.
A Data-Driven Evolutionary Transfer Optimization for Expensive Problems in Dynamic Environments
Nov 05, 2022Many real-world problems are usually computationally costly and the objective functions evolve over time. Data-driven, a.k.a. surrogate-assisted, evolutionary optimization has been recognized as an effective approach for tackling expensive black-box optimization problems in a static environment whereas it has rarely been studied under dynamic environments. This paper proposes a simple but effective transfer learning framework to empower data-driven evolutionary optimization to solve dynamic optimization problems. Specifically, it applies a hierarchical multi-output Gaussian process to capture the correlation between data collected from different time steps with a linearly increased number of hyperparameters. Furthermore, an adaptive source task selection along with a bespoke warm staring initialization mechanisms are proposed to better leverage the knowledge extracted from previous optimization exercises. By doing so, the data-driven evolutionary optimization can jump start the optimization in the new environment with a strictly limited computational budget. Experiments on synthetic benchmark test problems and a real-world case study demonstrate the effectiveness of our proposed algorithm against nine state-of-the-art peer algorithms.
A Survey on Heterogeneous Federated Learning
Oct 10, 2022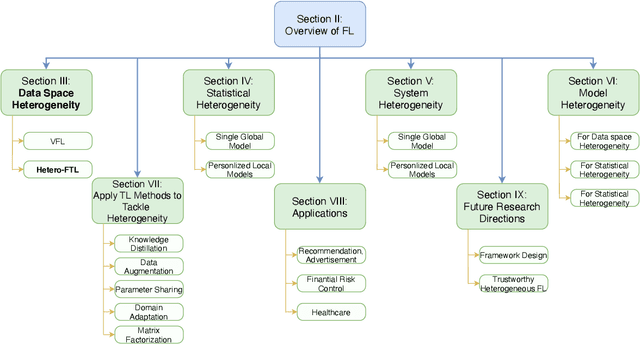
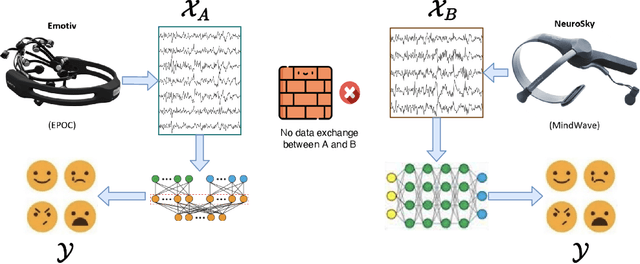
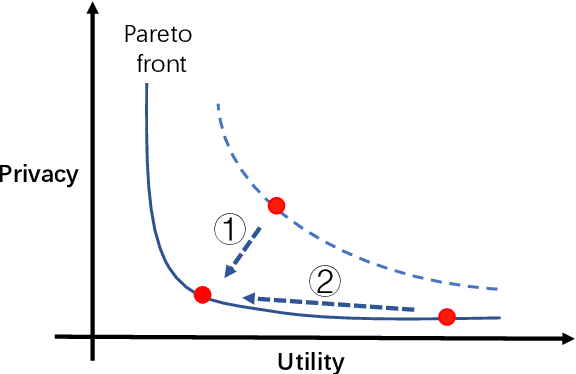
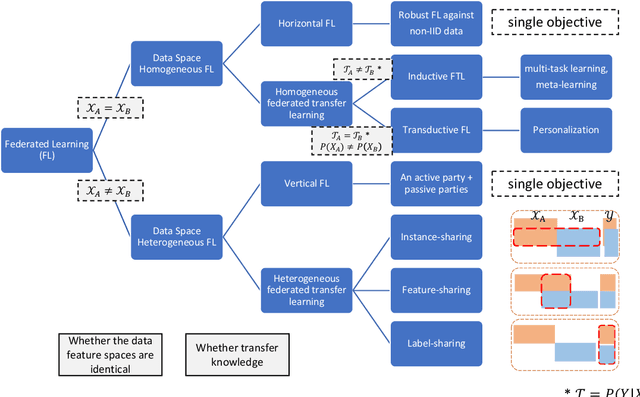
Federated learning (FL) has been proposed to protect data privacy and virtually assemble the isolated data silos by cooperatively training models among organizations without breaching privacy and security. However, FL faces heterogeneity from various aspects, including data space, statistical, and system heterogeneity. For example, collaborative organizations without conflict of interest often come from different areas and have heterogeneous data from different feature spaces. Participants may also want to train heterogeneous personalized local models due to non-IID and imbalanced data distribution and various resource-constrained devices. Therefore, heterogeneous FL is proposed to address the problem of heterogeneity in FL. In this survey, we comprehensively investigate the domain of heterogeneous FL in terms of data space, statistical, system, and model heterogeneity. We first give an overview of FL, including its definition and categorization. Then, We propose a precise taxonomy of heterogeneous FL settings for each type of heterogeneity according to the problem setting and learning objective. We also investigate the transfer learning methodologies to tackle the heterogeneity in FL. We further present the applications of heterogeneous FL. Finally, we highlight the challenges and opportunities and envision promising future research directions toward new framework design and trustworthy approaches.
How Good Is Neural Combinatorial Optimization?
Sep 22, 2022
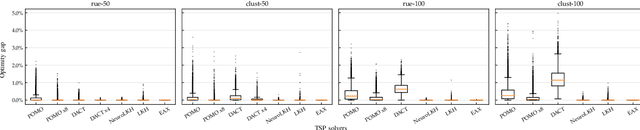
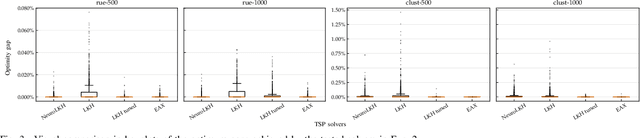
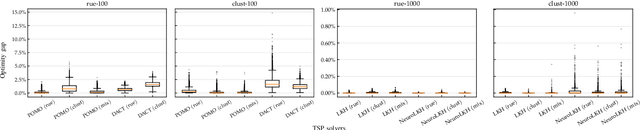
Traditional solvers for tackling combinatorial optimization (CO) problems are usually designed by human experts. Recently, there has been a surge of interest in utilizing Deep Learning, especially Deep Reinforcement Learning, to automatically learn effective solvers for CO. The resultant new paradigm is termed Neural Combinatorial Optimization (NCO). However, the advantages and disadvantages of NCO over other approaches have not been well studied empirically or theoretically. In this work, we present a comprehensive comparative study of NCO solvers and alternative solvers. Specifically, taking the Traveling Salesman Problem as the testbed problem, we assess the performance of the solvers in terms of five aspects, i.e., effectiveness, efficiency, stability, scalability and generalization ability. Our results show that in general the solvers learned by NCO approaches still fall short of traditional solvers in nearly all these aspects. A potential benefit of the former would be their superior time and energy efficiency on small-size problem instances when sufficient training instances are available. We hope this work would help better understand the strengths and weakness of NCO, and provide a comprehensive evaluation protocol for further benchmarking NCO approaches against other approaches.
The Vision of Self-Evolving Computing Systems
Apr 14, 2022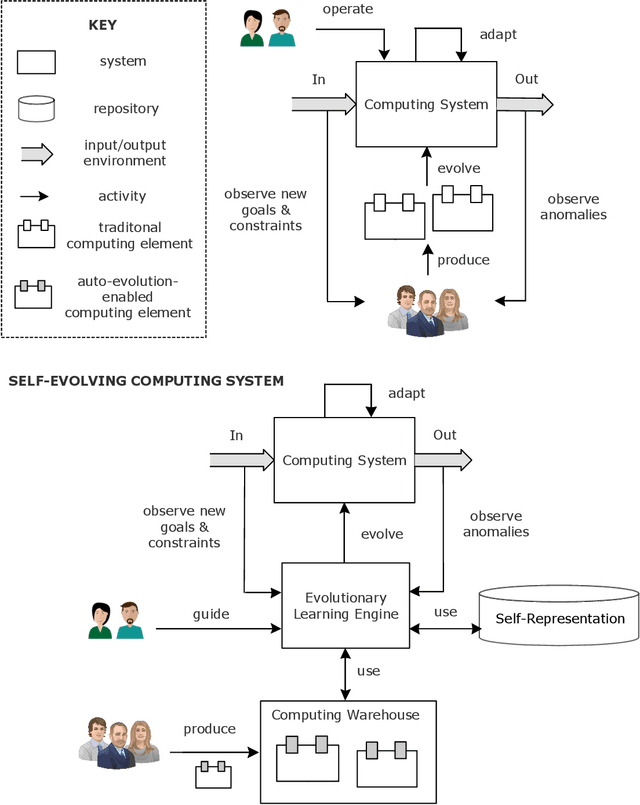
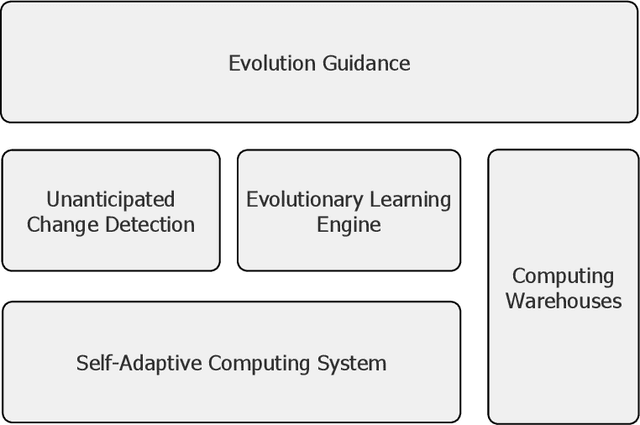
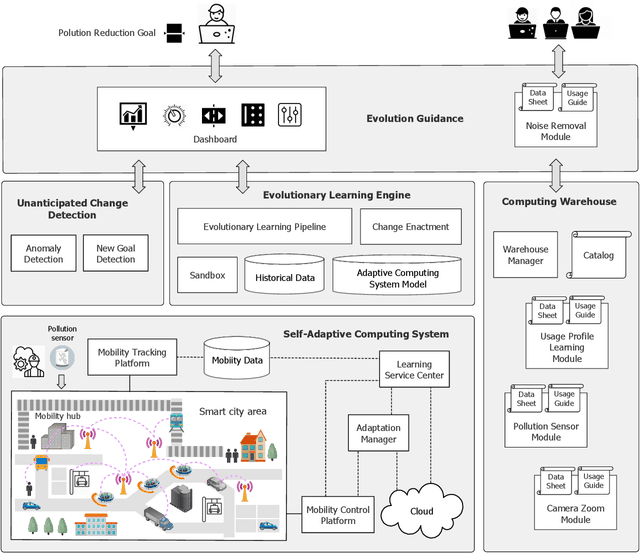
Computing systems are omnipresent; their sustainability has become crucial for our society. A key aspect of this sustainability is the ability of computing systems to cope with the continuous change they face, ranging from dynamic operating conditions, to changing goals, and technological progress. While we are able to engineer smart computing systems that autonomously deal with various types of changes, handling unanticipated changes requires system evolution, which remains in essence a human-centered process. This will eventually become unmanageable. To break through the status quo, we put forward an arguable opinion for the vision of self-evolving computing systems that are equipped with an evolutionary engine enabling them to evolve autonomously. Specifically, when a self-evolving computing system detects conditions outside its operational domain, such as an anomaly or a new goal, it activates an evolutionary engine that runs online experiments to determine how the system needs to evolve to deal with the changes, thereby evolving its architecture. During this process the engine can integrate new computing elements that are provided by computing warehouses. These computing elements provide specifications and procedures enabling their automatic integration. We motivate the need for self-evolving computing systems in light of the state of the art, outline a conceptual architecture of self-evolving computing systems, and illustrate the architecture for a future smart city mobility system that needs to evolve continuously with changing conditions. To conclude, we highlight key research challenges to realize the vision of self-evolving computing systems.
Reproducibility and Baseline Reporting for Dynamic Multi-objective Benchmark Problems
Apr 08, 2022
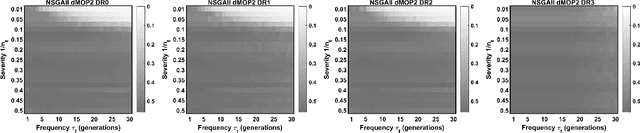
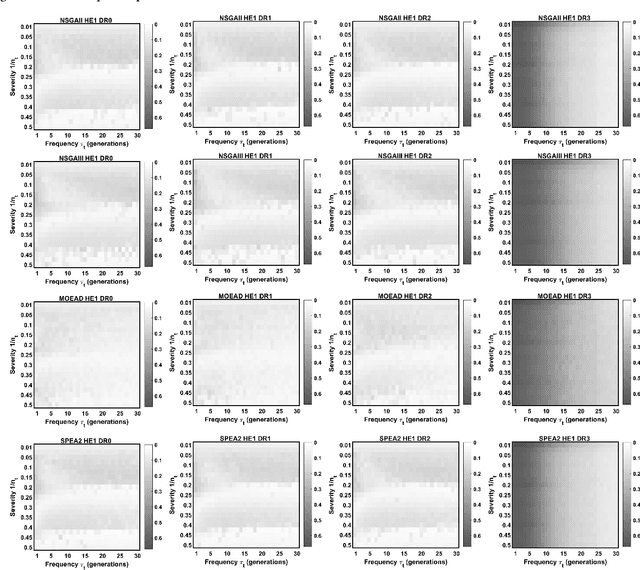
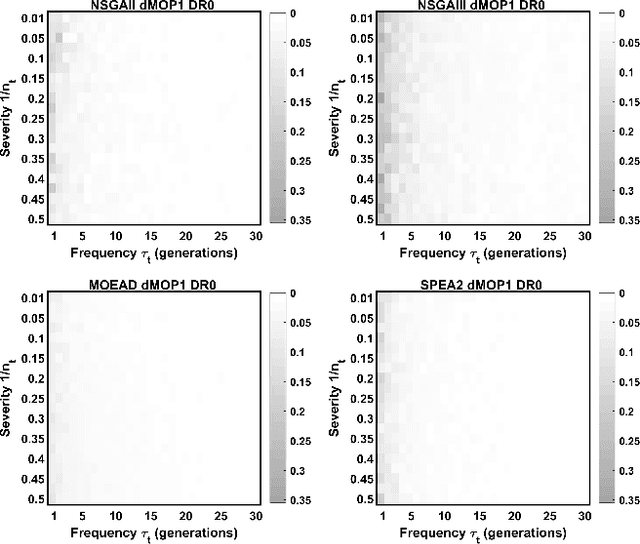
Dynamic multi-objective optimization problems (DMOPs) are widely accepted to be more challenging than stationary problems due to the time-dependent nature of the objective functions and/or constraints. Evaluation of purpose-built algorithms for DMOPs is often performed on narrow selections of dynamic instances with differing change magnitude and frequency or a limited selection of problems. In this paper, we focus on the reproducibility of simulation experiments for parameters of DMOPs. Our framework is based on an extension of PlatEMO, allowing for the reproduction of results and performance measurements across a range of dynamic settings and problems. A baseline schema for dynamic algorithm evaluation is introduced, which provides a mechanism to interrogate performance and optimization behaviours of well-known evolutionary algorithms that were not designed specifically for DMOPs. Importantly, by determining the maximum capability of non-dynamic multi-objective evolutionary algorithms, we can establish the minimum capability required of purpose-built dynamic algorithms to be useful. The simplest modifications to manage dynamic changes introduce diversity. Allowing non-dynamic algorithms to incorporate mutated/random solutions after change events determines the improvement possible with minor algorithm modifications. Future expansion to include current dynamic algorithms will enable reproduction of their results and verification of their abilities and performance across DMOP benchmark space.